|
|
| (20 intermediate revisions by the same user not shown) |
| Line 2: |
Line 2: |
| | |title=PRIMO.ai | | |title=PRIMO.ai |
| | |titlemode=append | | |titlemode=append |
| − | |keywords=artificial, intelligence, machine, learning, models, algorithms, data, singularity, moonshot, Tensorflow, Google, Nvidia, Microsoft, Azure, Amazon, AWS | + | |keywords=ChatGPT, artificial, intelligence, machine, learning, GPT-4, GPT-5, NLP, NLG, NLC, NLU, models, data, singularity, moonshot, Sentience, AGI, Emergence, Moonshot, Explainable, TensorFlow, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Hugging Face, OpenAI, Tensorflow, OpenAI, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Meta, LLM, metaverse, assistants, agents, digital twin, IoT, Transhumanism, Immersive Reality, Generative AI, Conversational AI, Perplexity, Bing, You, Bard, Ernie, prompt Engineering LangChain, Video/Image, Vision, End-to-End Speech, Synthesize Speech, Speech Recognition, Stanford, MIT |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools |
| − | |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | + | |
| | + | <!-- Google tag (gtag.js) --> |
| | + | <script async src="https://www.googletagmanager.com/gtag/js?id=G-4GCWLBVJ7T"></script> |
| | + | <script> |
| | + | window.dataLayer = window.dataLayer || []; |
| | + | function gtag(){dataLayer.push(arguments);} |
| | + | gtag('js', new Date()); |
| | + | |
| | + | gtag('config', 'G-4GCWLBVJ7T'); |
| | + | </script> |
| | }} | | }} |
| − | [http://www.youtube.com/results?search_query=Technical+Assessment+Evaluation+Performance+artificial+intelligence+Deep+Machine+Learning YouTube search...] | + | [http://www.youtube.com/results?search_query=ML+Test+Score+artificial+intelligence+Deep+Machine+Learning YouTube search...] |
| − | [http://www.google.com/search?q=Technical+Assessment+Evaluation+Performance+artificial+intelligence+Deep+Machine+Learning ...Google search] | + | [http://www.google.com/search?q=ML+Test+Score+artificial+intelligence+Deep+Machine+Learning ...Google search] |
| | | | |
| − | * Evaluation | + | * [[Strategy & Tactics]] ... [[Project Management]] ... [[Best Practices]] ... [[Checklists]] ... [[Project Check-in]] ... [[Evaluation]] ... [[Evaluation - Measures|Measures]] |
| − | ** [[Evaluation - Measures]]
| + | ** [[Evaluation - Measures#Accuracy|Accuracy]] |
| − | *** [[Evaluation - Measures#Accuracy|Accuracy]]
| + | ** [[Evaluation - Measures#Precision & Recall (Sensitivity)|Precision & Recall (Sensitivity)]] |
| − | *** [[Evaluation - Measures#Precision & Recall (Sensitivity)|Precision & Recall (Sensitivity)]]
| + | ** [[Evaluation - Measures#Specificity|Specificity]] |
| − | *** [[Evaluation - Measures#Specificity|Specificity]]
| + | ** [[Benchmarks]] |
| − | *** [[Benchmarks]]
| |
| | ** [[Bias and Variances]] | | ** [[Bias and Variances]] |
| − | ** [[Explainable Artificial Intelligence (XAI)]] | + | ** [[Algorithm Administration#Model Monitoring|Model Monitoring]] |
| − | ** [[Train, Validate, and Test]] | + | * [[AI Solver]] ... [[Algorithms]] ... [[Algorithm Administration|Administration]] ... [[Model Search]] ... [[Discriminative vs. Generative]] ... [[Train, Validate, and Test]] |
| − | ** [[AI Verification and Validation]] | + | * [[Risk, Compliance and Regulation]] ... [[Ethics]] ... [[Privacy]] ... [[Law]] ... [[AI Governance]] ... [[AI Verification and Validation]] |
| − | ** [[Model Monitoring]] | + | * [[Artificial General Intelligence (AGI) to Singularity]] ... [[Inside Out - Curious Optimistic Reasoning| Curious Reasoning]] ... [[Emergence]] ... [[Moonshots]] ... [[Explainable / Interpretable AI|Explainable AI]] ... [[Algorithm Administration#Automated Learning|Automated Learning]] |
| | * [[Cybersecurity: Evaluating & Selling]] | | * [[Cybersecurity: Evaluating & Selling]] |
| − | * [[Strategy & Tactics]] | + | * [[Data Science]] ... [[Data Governance|Governance]] ... [[Data Preprocessing|Preprocessing]] ... [[Feature Exploration/Learning|Exploration]] ... [[Data Interoperability|Interoperability]] ... [[Algorithm Administration#Master Data Management (MDM)|Master Data Management (MDM)]] ... [[Bias and Variances]] ... [[Benchmarks]] ... [[Datasets]] |
| − | * [[Checklists]]
| |
| − | * [[AI Governance]]
| |
| − | ** [[Data Governance]]
| |
| − | *** [[Data Science]]
| |
| − | *** [[Master Data Management (MDM) / Feature Store / Data Lineage / Data Catalog]]
| |
| | * [[Automated Scoring]] | | * [[Automated Scoring]] |
| − | * [[Risk, Compliance and Regulation]] | + | * [[Development]] ... [[Notebooks]] ... [[Development#AI Pair Programming Tools|AI Pair Programming]] ... [[Codeless Options, Code Generators, Drag n' Drop|Codeless]] ... [[Hugging Face]] ... [[Algorithm Administration#AIOps/MLOps|AIOps/MLOps]] ... [[Platforms: AI/Machine Learning as a Service (AIaaS/MLaaS)|AIaaS/MLaaS]] |
| − | * [[AIOps / MLOps]]
| |
| − | * [[Libraries & Frameworks]]
| |
| − | * [http://ico.org.uk/media/about-the-ico/consultations/2617219/guidance-on-the-ai-auditing-framework-draft-for-consultation.pdf Guidance on the AI auditing framework | Information Commissioner's Office (ICO)]
| |
| − | * [http://www.gao.gov/products/GAO-20-48G Technology Readiness Assessments (TRA) Guide | US GAO] ...used to evaluate the maturity of technologies and whether they are developed enough to be incorporated into a system without too much risk.
| |
| − | * [http://dodcio.defense.gov/Portals/0/Documents/Cyber/2019%20Cybersecurity%20Resource%20and%20Reference%20Guide_DoD-CIO_Final_2020FEB07.pdf Cybersecurity Reference and Resource Guide | DOD]
| |
| − | * [http://recruitingdaily.com/five-ways-to-evaluate-ai-systems/ Five ways to evaluate AI systems | Felix Wetzel - Recruiting Daily]
| |
| − | * [http://github.com/cisagov/cset/releases Cyber Security Evaluation Tool (CSET®)] ...provides a systematic, disciplined, and repeatable approach for evaluating an organization’s security posture.
| |
| − | * [http://towardsdatascience.com/3-common-technical-debts-in-machine-learning-and-how-to-avoid-them-17f1d7e8a428 3 Common Technical Debts in Machine Learning and How to Avoid Them | Derek Chia - Towards Data Science]
| |
| − | * [http://ai.facebook.com/blog/new-code-completeness-checklist-and-reproducibility-updates/ New code completeness checklist and reproducibility updates |] [[Facebook]] AI
| |
| − | * [http://www.oreilly.com/radar/why-you-should-care-about-debugging-machine-learning-models/ Why you should care about debugging machine learning models | Patrick Hall and Andrew Burt - O'reilly]
| |
| − | | |
| − | Many products today leverage artificial intelligence for a wide range of industries, from healthcare to marketing. However, most business leaders who need to make strategic and procurement decisions about these technologies have no formal AI background or academic training in data science. The purpose of this article is to give business people with no AI expertise a general guideline on how to assess an AI-related product to help decide whether it is potentially relevant to their business. [http://emerj.com/ai-sector-overviews/how-to-assess-an-artificial-intelligence-product-or-solution-for-non-experts/ How to Assess an Artificial Intelligence Product or Solution (Even if You’re Not an AI Expert) | Daniel Faggella - Emerj]
| |
| − | | |
| − | Nature of risks inherent to AI applications: We believe that the challenge in governing AI is less about dealing with completely new types of risk and more about existing risks either being harder to identify in an effective and timely manner, given the complexity and speed of AI solutions, or manifesting themselves in unfamiliar ways. As such, firms do not require completely new processes for dealing with AI, but they will need to enhance existing ones to take into account AI and fill the necessary gaps. The likely impact on the level of resources required, as well as on roles and responsibilities, will also need to be addressed. [http://www2.deloitte.com/content/dam/Deloitte/nl/Documents/innovatie/deloitte-nl-innovate-lu-ai-and-risk-management.pdf AI and risk management: Innovating with confidence | Deloitte]
| |
| − | | |
| − | | |
| − | <hr>
| |
| − | | |
| − | <center><b> Assessment Questions </b>- Artificial Intelligence (AI) / Machine Learning (ML) / Machine Intelligence (MI) </center>
| |
| − | | |
| − | <hr>
| |
| − | | |
| − | | |
| − | * What challenge does the AI investment solve?
| |
| − | ** Is the intent of AI to increase performance (detection), reduce costs (predictive maintenance, reduce inventory) , decrease response time, or other outcome(s)?
| |
| − | ** How does the AI investment meet the challenge?
| |
| − | ** What analytics are being implemented? [[What is AI? | Descriptive (what happened?), Diagnostic (why did it happen?), Predictive/Preventive (what could happen?), Prescriptive (what should happen?), Cognitive (what steps should be taken?)]]
| |
| − | ** Is AI being used for [[Cybersecurity]]? Is AI used protect the AI investment against targeted attacks, often referred to as [http://link.springer.com/article/10.1007/s11416-016-0273-3 advanced targeted attacks (ATAs)] or [http://link.springer.com/chapter/10.1007/978-3-662-44885-4_5 advanced persistent threats (APTs)]?
| |
| − | * Is the organization using the AI investment to gain better capability in the future?
| |
| − | ** Is the right [[Evaluation#Leadership| Leadership]] in place?
| |
| − | ** Is [[Evaluation#Leadership| Leadership]]'s [[Strategy & Tactics | AI strategy]] documented and articulated well?
| |
| − | ** Does the AI investment strategy align with the organization's overall strategy and values?
| |
| − | ** Is the AI investment properly resourced? budgeted, trained staff with key positions filled?
| |
| − | ** Responsibility clearly defined and communicated for AI research, performing data science, applied machine intelligence engineering, qualitative assurance, software development, implementing foundational capabilities, user experience, change management, configuration management, security, backup/contingency, domain expertise, and project management
| |
| − | ** Is the organization positioned or positioning to scale its current state with AI?
| |
| − | * Does the AI reside in a [[Evaluation#Procuring| procured item/application/solution or developed in house]]?
| |
| − | ** If the AI is [[Evaluation#Buying| procured]], e.g. embedded in sensor product, what items are included in the contract to future proof the solution?
| |
| − | ** Contract items to protect organization reuse data rights?
| |
| − | * Are [[Evaluation#Best Practices| Best Practices]] being followed? Is the team trained in the [[Evaluation#Best Practices| Best Practices]]?
| |
| − | * What is the [[Evaluation#Return on Investment (ROI)| Return on Investment (ROI)]]? Is the AI investment on track with original ROI target?
| |
| − | ** What is the clear and realistic way of measuring the success of the AI investment?
| |
| − | * What are the significant [[Evaluation - Measures| measures]] that indicate the AI investment is achieving success?
| |
| − | ** What [[Evaluation - Measures]] are documented? Are the [[Evaluation - Measures|Measures]] being used correctly?
| |
| − | ** How would you be able to tell if the AI investment was working properly?
| |
| − | ** How perfect does AI have to be to trust it? What is the inference/prediction rate performance metric for the AI investment?
| |
| − | ** What is the current inference/prediction/[[Evaluation - Measures#Receiver Operating Characteristic (ROC) | True Positive Rate (TPR)]]?
| |
| − | ** What is the [[Evaluation - Measures#Receiver Operating Characteristic (ROC) | False Positive Rate (FPR)]]? How does AI reduce false-positives without increasing false negatives?
| |
| − | ** Is there a [[Evaluation - Measures#Receiver Operating Characteristic (ROC) |Receiver Operating Characteristic (ROC) curve]]; plotting the [[Evaluation - Measures#Receiver Operating Characteristic (ROC) | True Positive Rate (TPR)]] against the [[Evaluation - Measures#Receiver Operating Characteristic (ROC) | False Positive Rate (FPR)]]?
| |
| − | ** When the AI model is updated, how is it determined that the performance was indeed increased for the better?
| |
| − | ** Are response plans, procedures and training in place to address AI attack or failure incidents? How are AI investment’s models audited for security vulnerabilities?
| |
| − | * What is the [[Evaluation#ML Test Score| ML Test Score?]]
| |
| − | * Does [[Data Governance]] treat data as a first-class asset?
| |
| − | ** Is [[Master Data Management (MDM) / Feature Store / Data Lineage / Data Catalog | Master Data Management (MDM)]] in place?
| |
| − | ** Is there data management plan(ning)? Does data planning address metadata for dataflows and data transitions? data quality?
| |
| − | ** Has the data been identified for current AI investment? For future use AI investment(s)?
| |
| − | ** Are the internal data resources available and accessible? For external data resources, are contracts in place to make the data available and accessible?
| |
| − | ** Are permissions in place to use the data, with privacy constraints considered and mitigated?
| |
| − | ** Is the data labelled, or require manual labeling?
| |
| − | ** What is the quality of the data; skewed, gaps, clean?
| |
| − | ** Is there sufficient amount of data available?
| |
| − | ** Have the key features to be used in the AI model been identified? If needed, what are the algorithms used to combine AI features? What is the approximate number of features used?
| |
| − | ** How are the [[Datasets|dataset(s)]] used for AI training, testing and Validation managed? Are logs kept on which data is used for different executions/training so that the information used is traceable?
| |
| − | ** How is the access to the information guaranteed? Are the [[Datasets|dataset(s)]] for AI published (repo, marketplace) for reuse, if so where?
| |
| − | * What [[AI Governance]] is in place?
| |
| − | ** What are the [[Enterprise Architecture (EA)|AI architecture]] specifics, e.g. [[Ensemble Learning]] methods used, [[Graph Convolutional Network (GCN), Graph Neural Networks (Graph Nets), Geometric Deep Learning|graph network]], or [[Distributed]] learning?
| |
| − | ** What AI model type(s) are used? [[Regression]], [[K-Nearest Neighbors (KNN)]], [[Graph Convolutional Network (GCN), Graph Neural Networks (Graph Nets), Geometric Deep Learning|Graph Neural Networks], [[Reinforcement Learning (RL)]], [[Association Rule Learning]], etc.
| |
| − | ** Is [[Transfer Learning]] used? If so, which AI models are used? What mission specific [[Datasets|dataset(s)]] are used to tune the AI model?
| |
| − | ** Are the AI models published (repo, marketplace) for reuse, if so where?
| |
| − | ** Is the AI model reused from a repository (repo, marketplace)? If so, which one? How are you notified of updates? How often is the repository checked for updates?
| |
| − | ** Are AI service(s) are used for inference/prediction?
| |
| − | ** What AI languages, [[Libraries & Frameworks]], scripting, are implemented? [[Python]], [[Javascript]], [[PyTorch]] etc.
| |
| − | ** What optimizers are used? Is augmented machine learning (AugML) or automated machine learning (AutoML) used?
| |
| − | ** What [[Benchmarks|benchmark]] standard(s) are the AI model compared/scored? e.g. [[Global Vectors for Word Representation (GloVe)]]
| |
| − | ** How often is the deployed AI process [[Model Monitoring | monitored or measures re-evaluated]]?
| |
| − | ** How is bias accounted for in the AI process? How are the [[Datasetsdataset(s)]] used are assured to represent the problem space? What is the process of the removal of features/data that is believed are not relevant? What assurance is provided that the model (algorithm) is not biased?
| |
| − | ** Is the model [[Explainable Artificial Intelligence (XAI)| (implemented or to be implemented) explainable? Interpretable?]] How so?
| |
| − | ** Has role/job displacement due to automation and/or AI implementation being addressed?
| |
| − | ** Are User and [http://en.wikipedia.org/wiki/User_behavior_analytics | Entity Behavior Analytics (UEBA)] and AI used to help to create a baseline for trusted workload access?
| |
| − | * What foundational capabilities are defined or in place for the AI investment? infrastructure platform, cloud resources?
| |
| − | * Is the AI investment implementing an [[AIOps / MLOps]] pipeline/toolchain?
| |
| − | ** What tools are used for the [[AIOps / MLOps]]? Please identify those on-premises and online services?
| |
| − | ** Are the AI languages, libraries, scripting, and [[AIOps / MLOps]] applications registered in the organization?
| |
| − | ** Does the AI investment depict the [[AIOps / MLOps]] pipeline/toolchain applications in their tech stack?
| |
| − | ** Is the AI investment identifies in the [[AIOps / MLOps| SecDevOps]] architecture?
| |
| − | ** Does [[Master Data Management (MDM) / Feature Store / Data Lineage / Data Catalog | data management]] reflected in the [[AIOps / MLOps]] pipeline/toolchain processes/architecture?
| |
| − | ** Are the end-to-end visibility and bottleneck risks for [[AIOps / MLOps]] pipeline/toolchain reflected in the risk register with mitigation strategy for each risk?
| |
| − | | |
| − | | |
| − | {|<!-- T -->
| |
| − | | valign="top" |
| |
| − | {| class="wikitable" style="width: 550px;"
| |
| − | ||
| |
| − | <youtube>7CcSm0PAr-Y</youtube>
| |
| − | <b>How Should We Evaluate Machine Learning for AI?: Percy Liang
| |
| − | </b><br>Machine learning has undoubtedly been hugely successful in driving progress in AI, but it implicitly brings with it the train-test evaluation paradigm. This standard evaluation only encourages behavior that is good on average; it does not ensure robustness as demonstrated by adversarial examples, and it breaks down for tasks such as dialogue that are interactive or do not have a correct answer. In this talk, I will describe alternative evaluation paradigms with a focus on natural language understanding tasks, and discuss ramifications for guiding progress in AI in meaningful directions. Percy Liang is an Assistant Professor of Computer Science at Stanford University (B.S. from MIT, 2004; Ph.D. from UC Berkeley, 2011). His research spans machine learning and natural language processing, with the goal of developing trustworthy agents that can communicate effectively with people and improve over time through interaction. Specific topics include question answering, dialogue, program induction, interactive learning, and reliable machine learning. His awards include the IJCAI Computers and Thought Award (2016), an NSF CAREER Award (2016), a Sloan Research Fellowship (2015), and a Microsoft Research Faculty Fellowship (2014).
| |
| − | |} | |
| − | | |
| − | = <span id="ML Test Score"></span>ML Test Score =
| |
| | * [http://research.google/pubs/pub43146/ Machine Learning: The High Interest Credit Card of Technical Debt | | D. Sculley, G Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, and M. Young -] [[Google]] Research | | * [http://research.google/pubs/pub43146/ Machine Learning: The High Interest Credit Card of Technical Debt | | D. Sculley, G Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, and M. Young -] [[Google]] Research |
| | * [http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf Hidden Technical Debt in Machine Learning Systems D. Sculley, G Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, J. Crespo, and D. Dennison -] [[Google]] Research | | * [http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf Hidden Technical Debt in Machine Learning Systems D. Sculley, G Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, J. Crespo, and D. Dennison -] [[Google]] Research |
| | | | |
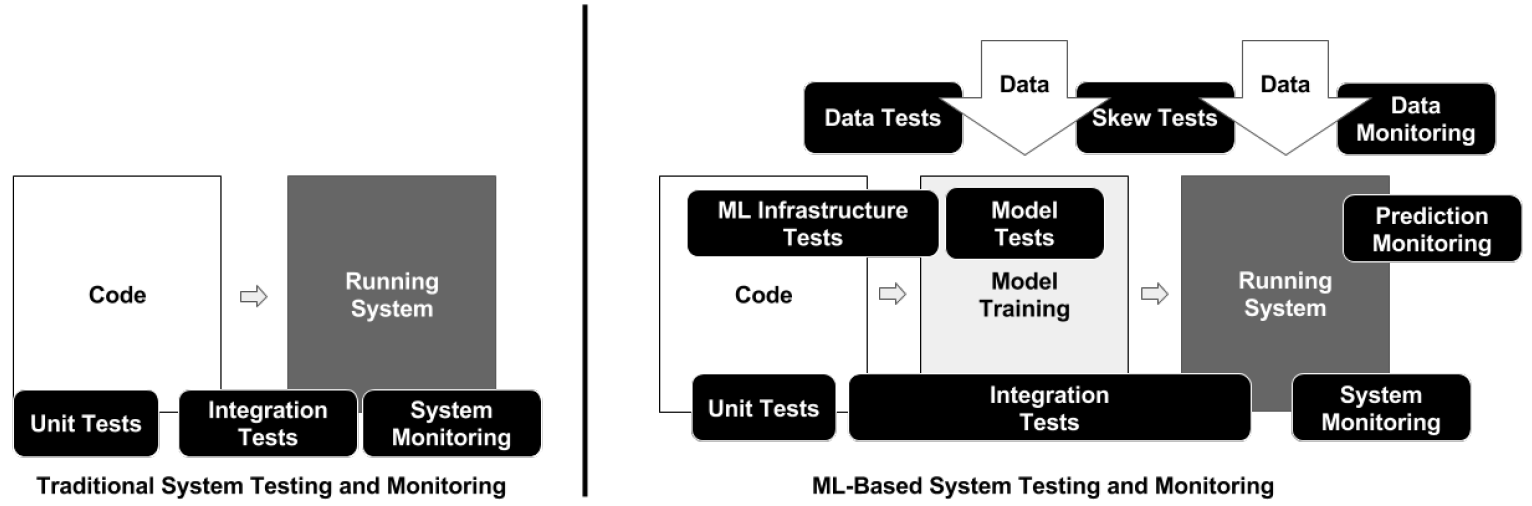
| | Creating reliable, production-level machine learning systems brings on a host of concerns not found in small toy examples or even large offline research experiments. Testing and monitoring are key considerations for ensuring the production-readiness of an ML system, and for reducing technical debt of ML systems. But it can be difficult to formulate specific tests, given that the actual prediction behavior of any given model is difficult to specify a priori. In this paper, we present 28 specific tests and monitoring needs, drawn from experience with a wide range of production ML systems to help quantify these issues and present an easy to follow road-map to improve production readiness and pay down ML technical debt. [http://research.google/pubs/pub46555/ The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction | E. Breck, S. Cai, E. Nielsen, M. Salib, and D. Sculley -] [[Google]] Research Full Stack Deep Learning | | Creating reliable, production-level machine learning systems brings on a host of concerns not found in small toy examples or even large offline research experiments. Testing and monitoring are key considerations for ensuring the production-readiness of an ML system, and for reducing technical debt of ML systems. But it can be difficult to formulate specific tests, given that the actual prediction behavior of any given model is difficult to specify a priori. In this paper, we present 28 specific tests and monitoring needs, drawn from experience with a wide range of production ML systems to help quantify these issues and present an easy to follow road-map to improve production readiness and pay down ML technical debt. [http://research.google/pubs/pub46555/ The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction | E. Breck, S. Cai, E. Nielsen, M. Salib, and D. Sculley -] [[Google]] Research Full Stack Deep Learning |
| | + | |
| | + | |
| | + | http://millengustavo.github.io/assets/images/ml_test_production/systems_comparison.PNG |
| | | | |
| | {|<!-- T --> | | {|<!-- T --> |
| Line 150: |
Line 58: |
| | |}<!-- B --> | | |}<!-- B --> |
| | | | |
| − | = <span id="Procuring"></span>Procuring =
| |
| − | * [http://c3.ai/wp-content/uploads/2020/06/Enterprise-AI-Buyers-Guide.pdf Enterprise AI Buyer’s Guide | C3.ai]
| |
| − | * [http://www3.weforum.org/docs/WEF_AI_Procurement_in_a_Box_AI_Government_Procurement_Guidelines_2020.pdf AI Procurement in a Box: AI Government Procurement Guidelines - Toolkit | World Economic Forum]
| |
| − | * [http://www.gov.uk/government/publications/guidelines-for-ai-procurement/guidelines-for-ai-procurement Guidance Guidelines for AI procurement | Gov.UK]
| |
| − | * [http://devops.com/a-buyers-guide-to-ai-and-machine-learning/ A Buyer’s Guide to AI and Machine Learning | Erik Fogg - DevOps.com]
| |
| − | * [http://www.nhsx.nhs.uk/key-tools-and-info/data-driven-health-and-care-technology/a-buyers-checklist-for-ai-in-health-and-care/ A Buyer’s Checklist for AI in Health and Care | NHSX]
| |
| − | * [http://static1.squarespace.com/static/5a8f9198f79392a0212ecb6e/t/5ebb0437563107184e6074b3/1589314616571/Buyers+Guide+V2.pdf Buyers Guide to Intelligent Virtual Agents and Chatbots | Liz Osborn]
| |
| − | {|<!-- T -->
| |
| − | | valign="top" |
| |
| − | {| class="wikitable" style="width: 550px;"
| |
| − | ||
| |
| − | <youtube>cRpuJcALfkA</youtube>
| |
| − | <b>Build or buy AI? You're asking the wrong question
| |
| − | </b><br>Evan Kohn, chief business officer and head of marketing at Pypestream, talks with Tonya Hall about why companies need to turn to staffing for AI and building data sets.
| |
| − | |}
| |
| − | |<!-- M -->
| |
| − | | valign="top" |
| |
| − | {| class="wikitable" style="width: 550px;"
| |
| − | ||
| |
| − | <youtube>b2Yvf7poKbM</youtube>
| |
| − | <b>Why you should Buy Open-Source AI
| |
| − | </b><br>Considering an AI assistant in your home? Before you auto-buy that pretty picture in front of you, be sure to check out the open-source offerings as well.
| |
| − | |}
| |
| − | |}<!-- B -->
| |
| | | | |
| − | = <span id="Best Practices"></span>Best Practices =
| |
| − | * [http://developers.google.com/machine-learning/guides/rules-of-ml Rules of Machine Learning: Best Practices for ML Engineering | Martin Zinkevich - ][[Google]]
| |
| | {|<!-- T --> | | {|<!-- T --> |
| | | valign="top" | | | | valign="top" | |
| | {| class="wikitable" style="width: 550px;" | | {| class="wikitable" style="width: 550px;" |
| | || | | || |
| − | <youtube>VfcY0edoSLU</youtube>
| + | http://millengustavo.github.io/assets/images/ml_test_production/data.PNG |
| − | <b>Rules of ML
| |
| − | </b><br>[[Google]] research scientist Martin Zinkevich
| |
| | |} | | |} |
| | |<!-- M --> | | |<!-- M --> |
| Line 189: |
Line 69: |
| | {| class="wikitable" style="width: 550px;" | | {| class="wikitable" style="width: 550px;" |
| | || | | || |
| − | <youtube>N6tN48hCnE4</youtube>
| + | http://millengustavo.github.io/assets/images/ml_test_production/model.PNG |
| − | <b>Best Practices of In-Platform AI/ML Webinar
| |
| − | </b><br>Productive use of machine learning and artificial intelligence technologies is impossible without a platform that allows autonomous functioning of AI/ML mechanisms. In-platform AI/ML has a number of advantages that can be obtained via best practices by InterSystems. On this webinar, we will present: • MLOps as the natural paradigm for in-platform AI/ML
| |
| − | • A full cycle of AI/ML content development and in-platform deployment (including bidirectional integration of Jupyter with InterSystems IRIS)
| |
| − | • New toolset added to ML Toolkit: integration and orchestration for Julia mathematical modeling environment
| |
| − | • Automated AI/ML model selection and parameter determination via an SQL query
| |
| − | • Cloud-enhanced ML
| |
| − | • Featured use case demo: hospital readmission prediction (addresses running in InterSystems IRIS of the models trained outside the platform's control)
| |
| | |} | | |} |
| | |}<!-- B --> | | |}<!-- B --> |
| − |
| |
| − |
| |
| − | = <span id="Leadership"></span>Leadership =
| |
| − | * [[Creatives]]
| |
| | {|<!-- T --> | | {|<!-- T --> |
| | | valign="top" | | | | valign="top" | |
| | {| class="wikitable" style="width: 550px;" | | {| class="wikitable" style="width: 550px;" |
| | || | | || |
| − | <youtube>--lkFfBOYHE</youtube>
| + | http://millengustavo.github.io/assets/images/ml_test_production/infra.PNG |
| − | <b>Artificial Intelligence: New Challenges for Leadership and Management
| |
| − | </b><br>The Future of Management in an Artificial Intelligence-Based World For more info about the conference: https://bit.ly/2J30TD3 -Dario Gil, Vice President of Science and Solutions, [[IBM]] Research -Tomo Noda, Founder and Chair, Shizenkan University Graduate School of Leadership and Innovation, Japan Moderator: Sandra Sieber, Professor, IESE
| |
| | |} | | |} |
| | |<!-- M --> | | |<!-- M --> |
| Line 215: |
Line 82: |
| | {| class="wikitable" style="width: 550px;" | | {| class="wikitable" style="width: 550px;" |
| | || | | || |
| − | <youtube>qRYiyDGpNLo</youtube>
| + | http://millengustavo.github.io/assets/images/ml_test_production/monitor.PNG |
| − | <b>Herminia Ibarra: What Will Leadership Look Like In The Age of AI?
| |
| − | </b><br>Herminia Ibarra, the Charles Handy professor of organisational behaviour at the London Business School, delves into what talent looks like in the age of artificial intelligence. Leaders are people who move a company, organisation, or institution from its current to – ideally – something better. In the age of artificial intelligence and smart technologies, this means being able to actually make use of the vast technological capability that is out there, but is wildly under-used.
| |
| − | |}
| |
| − | |}<!-- B -->
| |
| − | {|<!-- T -->
| |
| − | | valign="top" |
| |
| − | {| class="wikitable" style="width: 550px;"
| |
| − | ||
| |
| − | <youtube>uBxM0RTHd28</youtube>
| |
| − | <b>Who Makes AI Projects Successful
| |
| − | </b><br>Business leaders often have high expectations of AI/ML projects, and are sorely disappointed when things don't work out. AI implementations are more than just solving the technology problem. There are many other aspects to consider, and you'll need someone who has strong knowledge and background in business, technology (especially AI/ML), and data to guide the business on projects to take on, strategic direction, updates, and many other aspects. In this video, I call out the need for such a role because the underlying paradigm of software development is shifting. Here's what I can do to help you. I speak on the topics of architecture and AI, help you integrate AI into your organization, educate your team on what AI can or cannot do, and make things simple enough that you can take action from your new knowledge. I work with your organization to understand the nuances and challenges that you face, and together we can understand, frame, analyze, and address challenges in a systematic way so you see improvement in your overall business, is aligned with your strategy, and most importantly, you and your organization can incrementally change to transform and thrive in the future. If any of this sounds like something you might need, please reach out to me at dr.raj.ramesh@topsigma.com, and we'll get back in touch within a day. Thanks for watching my videos and for subscribing. www.topsigma.com www.linkedin.com/in/rajramesh
| |
| − | |}
| |
| − | |<!-- M -->
| |
| − | | valign="top" |
| |
| − | {| class="wikitable" style="width: 550px;"
| |
| − | ||
| |
| − | <youtube>PhQYmbNOut8</youtube>
| |
| − | <b>Lecture 2.7 Working with an AI team — [AI For Everyone | Andrew Ng]
| |
| − | </b><br>AI For Everyone lectures by Andrew Ng and our own Learning Notes.
| |
| − | |}
| |
| − | |}<!-- B -->
| |
| − | = <span id="Return on Investment (ROI)"></span>Return on Investment (ROI) =
| |
| − | {|<!-- T -->
| |
| − | | valign="top" |
| |
| − | {| class="wikitable" style="width: 550px;"
| |
| − | ||
| |
| − | <youtube>1JPifm2tHGM</youtube>
| |
| − | <b>How to compute the ROI on AI projects?
| |
| − | </b><br>Figuring out the ROI on AI implementations can be challenging. We offer some guidance on how to do that in this video. You can use this framework to make sure that you consider the many aspects of ROI that are especially required for AI projects. Contact the authors at: mehran.irdmousa@mziaviation.com, dr.raj.ramesh@gmail.com
| |
| − | | |
| − | |}
| |
| − | |<!-- M -->
| |
| − | | valign="top" |
| |
| − | {| class="wikitable" style="width: 550px;"
| |
| − | ||
| |
| − | <youtube>a36SWnObD-s</youtube>
| |
| − | <b>Getting to AI ROI: Finding Value in Your Unstructured Content
| |
| − | </b><br>Artificial Intelligence is definitely having its moment, but if you’re like most companies, you haven’t yet been able to capture ROI from these exciting technologies. It seems complicated, expensive, requires specialized talent, crazy data requirements, and more. Your boss may have dropped a vague missive onto your desk asking you to “figure out how AI can help enhance our business.” You have piles and piles of unstructured content—contracts, documents, feedback, but you haven’t been able to drive value from your data. Where to even start?
| |
| − | |}
| |
| − | |}<!-- B -->
| |
| − | = Model Deployment Scoring =
| |
| − | {|<!-- T -->
| |
| − | | valign="top" |
| |
| − | {| class="wikitable" style="width: 550px;"
| |
| − | ||
| |
| − | <youtube>gB0bTH-L6DE</youtube>
| |
| − | <b>ML Model Deployment and Scoring on the Edge with Automatic ML & DF / Flink2Kafka
| |
| − | </b><br>recorded on June 18, 2020. Machine Learning Model Deployment and Scoring on the Edge with Automatic Machine Learning and Data Flow Deploying Machine Learning models to the edge can present significant ML/IoT challenges centered around the need for low latency and accurate scoring on minimal resource environments. H2O.ai's Driverless AI AutoML and Cloudera Data Flow work nicely together to solve this challenge. Driverless AI automates the building of accurate Machine Learning models, which are deployed as light footprint and low latency Java or C++ artifacts, also known as a MOJO (Model Optimized). And Cloudera Data Flow leverage Apache NiFi that offers an innovative data flow framework to host MOJOs to make predictions on data moving on the edge. Speakers: James Medel (H2O.ai - Technical Community Maker) Greg Keys (H2O.ai - Solution Engineer) Kafka 2 Flink - An Apache Love Story This project has heavily inspired by two existing efforts from Data In Motion's FLaNK Stack and Data Artisan's blog on stateful streaming applications. The goal of this project is to provide insight into connecting an Apache Flink applications to Apache Kafka. Speaker: Ian R Brooks, PhD (Cloudera - Senior Solutions Engineer & Data)
| |
| − | |}
| |
| − | |<!-- M -->
| |
| − | | valign="top" |
| |
| − | {| class="wikitable" style="width: 550px;"
| |
| − | ||
| |
| − | <youtube>q-VPALG6ogY</youtube>
| |
| − | <b>Shawn Scully: Production and Beyond: Deploying and Managing Machine Learning Models
| |
| − | </b><br>PyData NYC 2015 Machine learning has become the key component in building intelligence-infused applications. However, as companies increase the number of such deployments, the number of machine learning models that need to be created, maintained, monitored, tracked, and improved grow at a tremendous pace. This growth has lead to a huge (and well-documented) accumulation of technical debt. Developing a machine learning application is an iterative process that involves building multiple models over a dataset. The dataset itself evolves over time as new features and new data points are collected. Furthermore, once deployed, the models require updates over time. Changes in models and datasets become difficult to track over time, and one can quickly lose track of which version of the model used which data and why it was subsequently replaced. In this talk, we outline some of the key challenges in large-scale deployments of many interacting machine learning models. We then describe a methodology for management, monitoring, and optimization of such models in production, which helps mitigate the technical debt. In particular, we demonstrate how to: Track models and versions, and visualize their quality over time Track the provenance of models and datasets, and quantify how changes in data impact the models being served Optimize model ensembles in real time, based on changing data, and provide alerts when such ensembles no longer provide the desired accuracy.
| |
| | |} | | |} |
| | |}<!-- B --> | | |}<!-- B --> |
| | | | |
| − | = Using Historical Incident Data to Reduce Risks =
| + | http://millengustavo.github.io/assets/images/ml_test_production/score.PNG |
| − | * [http://www.cloudfabrix.com/cfxgenie/ cfxGenie | CloudFabrix] ...Find your IT blind spots, assess problem areas or gain new insights from a sampling of your IT incidents or tickets
| |
| − |
| |
| − | http://www.cloudfabrix.com/img/cfxgenie-diagram-1-1.png
| |
| − | {|<!-- T -->
| |
| − | | valign="top" |
| |
| − | {| class="wikitable" style="width: 550px;"
| |
| − | ||
| |
| − | <youtube>JXeQyzO6Als</youtube>
| |
| − | <b>CloudFabrix cfxGenie | Free IT Assessment Tool to Find Problem Areas & Accelerate AIOps Adoption
| |
| − | </b><br>CloudFabrix Software Inc Find your IT blind spots and accelerate AIOps adoption with cfxGenie - Map/Zone incidents into quadrants to identify problem areas for prioritization - Cluster incidents based on symptoms and features to understand key problem areas. Get started now with your AIOps transformation journey. Signup for free cfxGenie Cloud Access, visit http://www.cloudfabrix.com/cfxgenie/
| |
| − | |}
| |
| − | |}<!-- B -->
| |