Discriminative vs. Generative
YouTube search... ...Google search
- AI Solver ... Algorithms ... Administration ... Model Search ... Discriminative vs. Generative ... Train, Validate, and Test
- Feature Exploration/Learning
- Artificial Intelligence (AI) ... Generative AI ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Conversational AI ... ChatGPT | OpenAI ... Bing/Copilot | Microsoft ... Gemini | Google ... Claude | Anthropic ... Perplexity ... You ... phind ... Ernie | Baidu
Application-specific details ultimately dictate the suitability of selecting a discriminative versus generative model. Model Contrasts...
- Discriminative
- learn the (hard or soft) boundary between classes
- providing classification splits (probabilistic or non-probabilistic manner)
- allow you to classify points, without providing a model of how the points are actually generated
- don't have generative properties
- make few assumptions of the model structure
- less tied to a particular structure
- better performance with lots of example data; higher accuracy, which mostly leads to better learning result
- discriminative models can yield superior performance (in part because they have fewer variables to compute)
- saves calculation resource
- can outperform generative if assumptions are not satisfied (real world is messy and assumptions are rarely perfectly satisfied)
- not designed to use unlabeled data; are inherently supervised and cannot easily support unsupervised learning
- do not generally function for outlier detection
- do not offer such clear representations of relations between features and classes in the dataset
- yields representations of boundaries (more than generative)
- do not allow one to generate samples from the joint distribution of observed and target variables
- generates lower asymptotic errors
- Generative AI
- requires less training samples
- model the distribution of individual classes
- provides a model of how the data is actually generated
- learn the underlying structure of the data
- have discriminative properties
- make some kind of structure assumptions on your model
- decision boundary: where one model becomes more likely
- often outperform discriminative models on smaller datasets because their generative assumptions place some structure on your model that prevent overfitting
- natural use of unlabeled data
- takes all data into consideration, which could result in slower processing as a disadvantage
- generally function for outlier detection
- typically specified as probabilistic graphical models, which offer rich representations of the independence relations in the dataset
- more straightforward to detect distribution changes and update a generative model
- takes the joint probability and predicts the most possible known label
- typically more flexible in expressing dependencies in complex learning tasks
- a flexible framework that could easily cooperate with other needs of the application
- results in higher asymptotic errors faster
- training method usually requires multiple numerical optimization techniques
- will need the combination of multiple subtasks for a solving complex real-world problem
Generative model takes the joint probability, where x is the input and y is the label, and predicts the most possible known label for the unknown variable using Bayes' Theorem
Discriminative models, as opposed to Generative models, do not allow one to generate samples from the joint distribution of observed and target variables. However, for tasks such as machine learning classification and Regression analysis that do not require the joint distribution, discriminative models can yield superior performance (in part because they have fewer variables to compute). On the other hand, generative models are typically more flexible than discriminative models in expressing dependencies in complex learning tasks. In addition, most discriminative models are inherently supervised and cannot easily support unsupervised learning. Application-specific details ultimately dictate the suitability of selecting a discriminative versus generative model.
Discriminative models and Generative models also differ in introducing the Posterior probability. To maintain the least expected loss, the minimization of result's misclassification should be acquired. In the discriminative model, the posterior probabilities, P(y|x), is inferred from a parametric model, where the parameters come from the training data. Points of estimation of the parameters are obtained from the maximization of likelihood or distribution computation over the parameters. On the other hand, considering that the generative models focus on the joint probability, the class posterior possibility P(k) is considered in Bayes' Theorem. Discriminative Modeling - Wikipedia

Snorkel
- Stanford Snorkel - MC.ai ...a Python library to help you label data for supervised machine learning tasks
- snorkel.org
- Snorkel and The Dawn of Weakly Supervised Machine Learning | A. Ratner, S. Bach, H. Ehrenberg, and C. Ré Stanford DAWN
- Snorkel Flow | Snorkel ...serve as a replacement of armies of human labelers which at the moment do it by hand
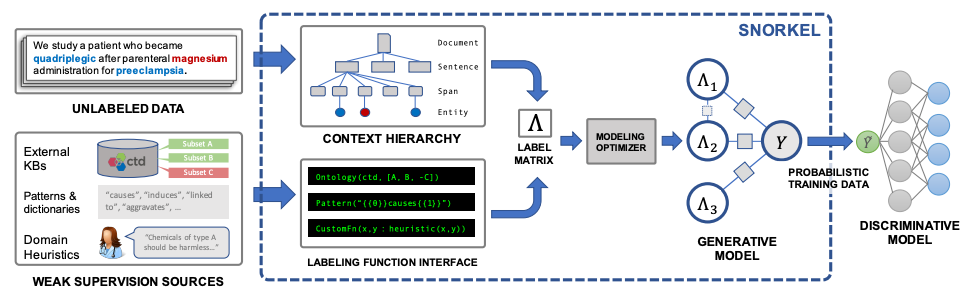
Snorkel system is noteworthy here and has been gaining a lot of traction. As part of DAWN project, Snorkel enables users to train models without hand labeling any training data. The users define labeling functions using arbitrary heuristics. Snorkel denoises their outputs without access to ground truth by incorporating the first end-to-end implementation of their recently proposed machine learning paradigm, data programming. In a Snorkel system Subject Matter Experts write labeling functions (LFs) that express weak supervision sources like distant supervision, patterns, and heuristics. Snorkel applies the LFs over unlabeled data and learns a generative model to combine the LFs’ outputs into probabilistic labels. Snorkel uses these labels to train a discriminative classification model, such as a deep neural network. Ground Truth Gold — Intelligent data labeling and annotation | Mohan Reddy - The Hive - Medium
|
|