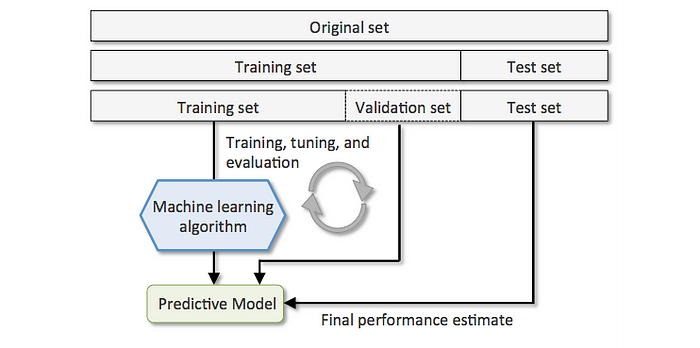
Train, Validate, and Test
YouTube search... ...Google search
- AI Solver ... Algorithms ... Administration ... Model Search ... Discriminative vs. Generative ... Train, Validate, and Test
- Strategy & Tactics ... Project Management ... Best Practices ... Checklists ... Project Check-in ... Evaluation ... Measures
- AI Verification and Validation
- Objective vs. Cost vs. Loss vs. Error Function
- Overfitting Challenge
- Data Science essentials: Why train-validation-test data? | Sagar Patel - Medium
- About Train, Validation and Test Sets in Machine Learning | Tarang Shah - Towards Data Science
- What is the Difference Between Test and Validation Datasets? | Jason Brownlee - Machine Learning Mastery
- Training Dataset: The sample of data used to fit the model.
- Validation Dataset: The sample of data used to provide an unbiased evaluation of a model fit on the training dataset while tuning model hyperparameters. The evaluation becomes more biased as skill on the validation dataset is incorporated into the model configuration.
- Test Dataset: The sample of data used to provide an unbiased evaluation of a final model fit on the training dataset.
- CalypsoAI Validating vision ML models via tests: brightness, contrast, saturation, pixilation, compression, blurring, random noise
- Landing AI ...LandingLens platform includes a wide array of features to help teams develop and deploy reliable and repeatable inspection systems
|
|
If you have an training accuracy of 90%, and you are not happy with that, what do you do? Collect more data? Try other algorithms? Collect more diverse data? How to decide what to do?
CONTENT FROM:
Structuring Machine Learning Projects; Course 3 | Andrew Ng's Deep Learning Series
Chain of assumptions in Machine Learning (ML)
- Fit training set well on cost function If this is not happening, try bigger network, or different optimization algorithm. You should achieve human level performance here.
- Fit dev set well on cost function If this is not happening, it means you are overfitting training set. Try Regularization, or train on a bigger training set. Or a different neural network (NN) architecture.
- Fit test set well on cost function If fit on test set is much worse than fit on dev set, it means you have overfit the dev set. You should get a bigger dev set. Or try a different neural network (NN) architecture.
- Perform well in the real world If performance on dev/test set is good, but performance in real world is bad, check if cost function is really what you care about.
Andrew Ng does not like early stopping because it affects fit on both training and dev sets, which leads to confusion.
Single real number evaluation metric
Have a single real number metric to compare various algorithms.
You may combined precision and recall (say by using harmonic mean of the two).
Some metrics could be 'satisficing', e.g. running time of classification should be within a threshold. Others would be optimizing.
Train/dev/test set distributions
Dev and test set should come from the same distribution and should reflect the data you want to do well on.
When data was less abundant, 60/20/20 would be good training/dev/test was good split. In data abundant neural net scenario, 98/1/1 is good distribution. Test set should be just good enough to give high confidence in overall performance of system. Some people just omit test set too.
Sometimes you may wish to change metric mid way. While building cat vs no cat image, may be in a "better" classfier, pornographic images are classified as cat images. So, you need to change cost function to penalizing this misclassification heavily.
Human level performance
For perception problems, human level performance is close to bayes' error. You should try to consider the best human level performance possible. Eg. in radiology an expert radiologist could be better than average radiologist and team of experts may better than a single expert. You should consider the way which gives lowest possible error.
Difference between 0 and human level performance is bayes' error Difference between human level performance and training error is avoidable bias Difference between training error and dev error is variance Difference between dev error and test error is overfitting to dev set You should compute all these errors and that will help you decide how to improve your algorithm.
Tasks where machines can outperform humans: online ads, loan approvals, product recommendations, logistics. (Structured data, not natural perception problems)
Also, in some Speech Recognition, image recognition and radiology tasks, computers surpass single human performance.
Error Analysis
When training error is not good enough, you manually examine mispredictions. You should examine a subset of mispredictions and examine manually the reason for errors. Is it that dogs are being mislabeled as cats? Or is it that lion/cheetah are mislabeled as cats? Or is it that blurry images are mislabeled as cats? Figure out prominent reason and try to solve that. If lots of dogs are being mislabeled as cats, make sense to put more dog images in training set.
Sometimes data could have mislabeled examples. Some mislabels in training set are okay, because NN algos are robust to that, as long as errors are random. In dev/test you should first estimate how much boost you would get by correcting the labels, and then correct the labels if you find that will give you a boost. If you fix dev set, fix test set too. You should ideally fix the examples that your algo got right because of misprediction. But it is not easy for accurate algos, as there would be large number of items to examine.
Build first, then iterate
You understand data and challenges only when you iterate. Build first system quickly and use bias/variance analysis to prioritize next steps.
Mismatched training and dev/test set
DL algos are data hungry. Teams want to shove in as much as data as they can get hold of. For example, you can get images from internet, or you can purchase data. You can use data from various sources to train, but dev/test set data should only contain the examples which are representative of your use case.
When your training and dev set are from different distributions, training error and dev error difference may not reflect [[Bias and Variances|variance]. It may just be that training test is easy. To catch this difference, you can have training dev set carved out of training set. Now:
Difference between training and training dev is the variance. Difference between training dev and dev is a measure of mismatch between training and test data. What if you have data mismatch problem? Perform manual inspection. May be lot of dev/test are noisy (in a Speech Recognition system). In that case you can add noise in training set. But be careful: if you have 10K hour worth of training data, you should add 10K hour worth of noise too. If you just repeat 1 hour worth of noise, you will overfit. Note that to human ear all noise will appear the same, but machine will overfit. Similarly for computer vision, you can synthesize images with background cars etc.
|