Inside Out - Curious Optimistic Reasoning
YouTube ... Quora ...Google search ...Google News ...Bing News
- Artificial General Intelligence (AGI) to Singularity ... Curious Reasoning ... Emergence ... Moonshots ... Explainable AI ... Automated Learning
- Immersive Reality ... Metaverse ... Omniverse ... Transhumanism ... Religion
- Life~Meaning ... Consciousness ... Creating Consciousness ... Quantum Biology ... Orch-OR ... TAME ... Proteins
- Can Meaning Exist in Artificial Systems? ... Explore the condition that separates simulation from Meaning
- Telecommunications ... Computer Networks ... 5G ... Satellite Communications ... Quantum Communications ... Communication Agents ... Smart Cities ... Digital Twin ... Internet of Things (IoT)
- Large Language Model (LLM) ... Multimodal ... Foundation Models (FM) ... Generative Pre-trained ... Transformer ... Attention ... GAN ... BERT
- Apprenticeship Learning - Inverse Reinforcement Learning (IRL)
- Generative Query Network (GQN)
- Artificial Intelligence (AI) ... Generative AI ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Conversational AI ... ChatGPT | OpenAI ... Bing/Copilot | Microsoft ... Gemini | Google ... Claude | Anthropic ... Perplexity ... You ... phind ... Ernie | Baidu
- Attention Mechanism ... Transformer ... Generative Pre-trained Transformer (GPT) ... GAN ... BERT
- Neuroscience
- Video/Image ... Vision ... Enhancement ... Fake ... Reconstruction ... Colorize ... Occlusions ... Predict image ... Image/Video Transfer Learning
- Memory Networks
- Creatives ... History of Artificial Intelligence (AI) ... Neural Network History ... Rewriting Past, Shape our Future ... Archaeology ... Paleontology
- Deep Curiosity Search (DeepCS): Intra-Life Exploration Improves Performance on Challenging Deep Reinforcement Learning Problem | Stanton C., Clune J., 1 Jun 2018
- An architectural review of Inside Out | RTF - Rethinking The Future
- Inside Out’s Take on the Brain: A Neuroscientist’s Perspective | Blake Porter
- Frontiers | The Embodiment of Architectural Experience: A Methodological Perspective on Neuro-Architecture | S. Wang, G. de Oliveira1, Z.Djebbara1, & K. Gramann - Frontiers
The brain has an “Inside Out” architecture where it generates an internal mental model to perform predictions. This Inside Out architecture is being recognized as being a paradigm shift in neuroscience where the more conventional stimulus-response paradigm has been the dominant conceptual framework. The Emergence of Inside Out Architectures in Deep Learning | Carlos E. Perez
In his article, Perez argues that deep learning architectures are evolving from a stimulus-response paradigm, where the input determines the output, to an Inside Out paradigm, where the output is generated by an internal representation of the world that is updated by the input. He cites examples such as GANs, Variational Autoencoder (VAE)s, and Transformers as models that follow this paradigm.
If the “Inside Out” architecture were proven to be true, it would mean that the brain generates an internal mental model of the world that is constantly updated by sensory input and used to perform predictions and actions. This would imply that the brain is not a passive receiver of information, but an active constructor of reality. It would also imply that the brain is not a static or fixed structure, but a dynamic and adaptive system that can change over time.
Some possible details of the “Inside Out” architecture are:
- The brain consists of multiple levels of representation, from low-level sensory features to high-level concepts and abstractions. These representations are encoded by neural populations that fire in synchrony or coherence.
- The brain uses generative models to infer the causes of sensory input and to generate predictions about future input. These models are probabilistic and hierarchical, meaning that they can account for uncertainty and complexity.
- The brain uses predictive coding to compare the predictions of the generative models with the actual sensory input and to update the models accordingly. Predictive coding minimizes the prediction error or surprise by adjusting the top-down and bottom-up signals between different levels of representation.
- The brain uses Attention to modulate the predictive coding process and to focus on the most relevant or salient aspects of the input. Attention can be driven by external stimuli (exogenous) or by internal goals (endogenous) and can enhance or suppress neural activity.
- The brain uses emotions to evaluate the outcomes of the predictive coding process and to guide action selection. Emotions are not separate from cognition, but integrated with it. Emotions reflect the value or significance of events for the organism and influence learning, memory, and decision making.
Curiosity
- Curiosity-driven Exploration by Self-supervised Prediction
- TensorFlow code for Curiosity-driven Exploration for Deep Reinforcement Learning
MERLIN
DeepMind’s MERLIN paper by Greg Wayne et. al. explores this very idea in much greater detail. The MERLIN architecture efficiently learns new policies by playing back from a memory system. MERLIN employs an Inside Out architecture as the basis of performing predictions. This Inside Out architecture is a form of optimistic reasoning (think optimistic transaction). The usual paradigm of stimulus-response is to bake into it a mechanism for incorporating uncertain information. This is what motivates the use of probabilistic methods. However, in an optimistic approach, observations are assumed to be certain and the compensation is performed only when a discrepancy is detected. Unsupervised Predictive Memory in a Goal-Directed Agent | Google DeepMind' MERLIN
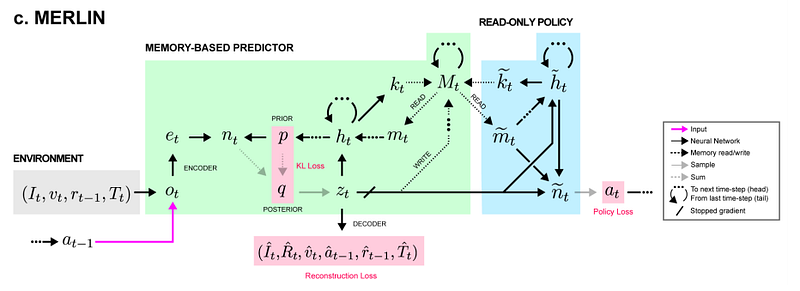
- The purpose of our predictive engine is to ensure that we have the essential internal self models to know how to stay alive. There is a subtle but significant difference in architecture when you go from just stimulus response to hallucinate a response. It’s as least the difference from an insect brain to that of a mammalian brain. All animals have an ability to react and adjust to the environment. Although mammals have inherited the brains of reptiles to drive its instinctive behavior. Mammals have in addition have a more advanced brain that is able to respond at a more intelligent level. The key development in mammals is the Neocortext that is responsible for higher order functions. The neurons in the Neocortext have evolved to specifically implement an Inside Out architecture.
- One benefit of an Inside Out design is that it is able to react quickly to an environment. It is primed when a context is identified and proceeds to hallucinate the subsequent sequential behavior. Divergence of input from the expected is rapidly recognized and a new context is instantiated to compensate for the unexpected inputs. Given that there is a bottleneck in its input receptors (i.e. five senses), it needs to be able to learn how to comprehend its environment with the minimal amount of input. This requires an internal context to be available that is aligns with the environmental context. The task requires information from both input and context. This permits the efficient sampling of an environment leveraging the internal contextual model.
In deep learning, this is the driving thesis behind external, key-value-based memory stores. This idea is not new; Neural Turing Machines, one of the first and favorite papers I ever read, augmented neural nets with a differentiable, external memory store accessible via vector-valued “read” and “write” heads to specific locations. We can easily imagine this being extended into RL, where at any given time-step, an agent is given both its environment observation and memories relevant to its current state. That’s exactly what the recent MERLIN architecture extends upon. MERLIN has 2 components: a memory-based predictor (MBP), and a policy network. The MBP is responsible for compressing observations into useful, low-dimensional “state variables” to store directly into a key-value memory matrix. It is also responsible for passing relevant memories to the policy, which uses those memories and the current state to output actions.... MERLIN is not the only Deep Reinforcement Learning (DRL) to use external memory stores — all the way back in 2016, researchers were already applying this idea in an MQN, or memory Q-Network Beyond DQN/A3C: A Survey in Advanced Reinforcement Learning | Joyce Xu - Towards Data Science