Algorithms
YouTube search... ...Google search
- AI Solver ... Algorithms ... Administration ... Model Search ... Discriminative vs. Generative ... Train, Validate, and Test
- Backpropagation ... FFNN ... Forward-Forward ... Activation Functions ...Softmax ... Loss ... Boosting ... Gradient Descent ... Hyperparameter ... Manifold Hypothesis ... PCA
- Strategy & Tactics ... Project Management ... Best Practices ... Checklists ... Project Check-in ... Evaluation ... Measures
- Google DeepMind AlphaGo Zero
- Google AIY Projects Program
- A guide to machine learning algorithms and their applications
- Outline of machine learning | Wikipedia
- How to choose algorithms for Microsoft Azure Machine Learning | Microsoft
- Machine learning models for AIY kits | AIY
- Monte Carlo (MC) Method
- Architectures for AI ... Generative AI Stack ... Enterprise Architecture (EA) ... Enterprise Portfolio Management (EPM) ... Architecture and Interior Design
- Perspective ... Context ... In-Context Learning (ICL) ... Transfer Learning ... Out-of-Distribution (OOD) Generalization
- Causation vs. Correlation ... Autocorrelation ...Convolution vs. Cross-Correlation (Autocorrelation)
- Artificial Intelligence (AI) ... Generative AI ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Conversational AI ... ChatGPT | OpenAI ... Bing/Copilot | Microsoft ... Gemini | Google ... Claude | Anthropic ... Perplexity ... You ... phind ... Ernie | Baidu
- Training (Fitting) Machine Learning Models - Jupyter Notebooks | Jon Tupitza
- 14 Different Types of Learning in Machine Learning | Jason Brownlee - Machine Learning Mastery
- Machine Learning for Everyone | vas3k
...machine learning is a class of methods for automatically creating models from data. Machine learning algorithms are the engines of machine learning, meaning it is the algorithms that turn a data set into a model. Which kind of algorithm works best (supervised, unsupervised, classification, Regression, etc.) depends on the kind of problem you’re solving, the computing resources available, and the nature of the data. Ordinary programming algorithms tell the computer what to do in a straightforward way. For example, sorting algorithms turn unordered data into data ordered by some criteria, often the numeric or alphabetical order of one or more fields in the data. Machine learning algorithms explained | Martin Heller - InfoWorld
- Linear Regression algorithms fit a straight line, or another function that is linear in its parameters such as a polynomial, to numeric data, typically by performing matrix inversions to minimize the squared error between the line and the data. Squared error is used as the metric because you don’t care whether the Regression line is above or below the data points; you only care about the distance between the line and the points.
- Nonlinear Regression algorithms, which fit curves that are not linear in their parameters to data, are a little more complicated, because, unlike linear Regression problems, they can’t be solved with a deterministic method. Instead, the nonlinear Regression algorithms implement some kind of iterative minimization process, often some variation on the method of steepest descent.
Parameters These are numerical values that define a model's structure and behavior, learned during training. They are used to determine output likelihood, more parameters mean more complexity and accuracy but require more computational power. e.g. language models
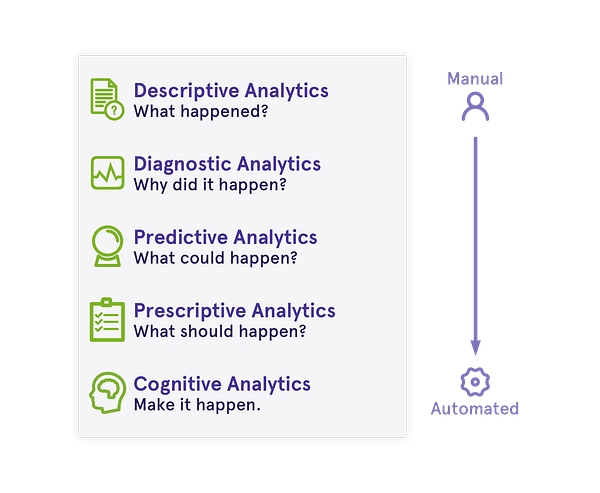 Predictive and Preventive | Vinay Mehendiratta - KDnuggets
Predictive and Preventive | Vinay Mehendiratta - KDnuggets
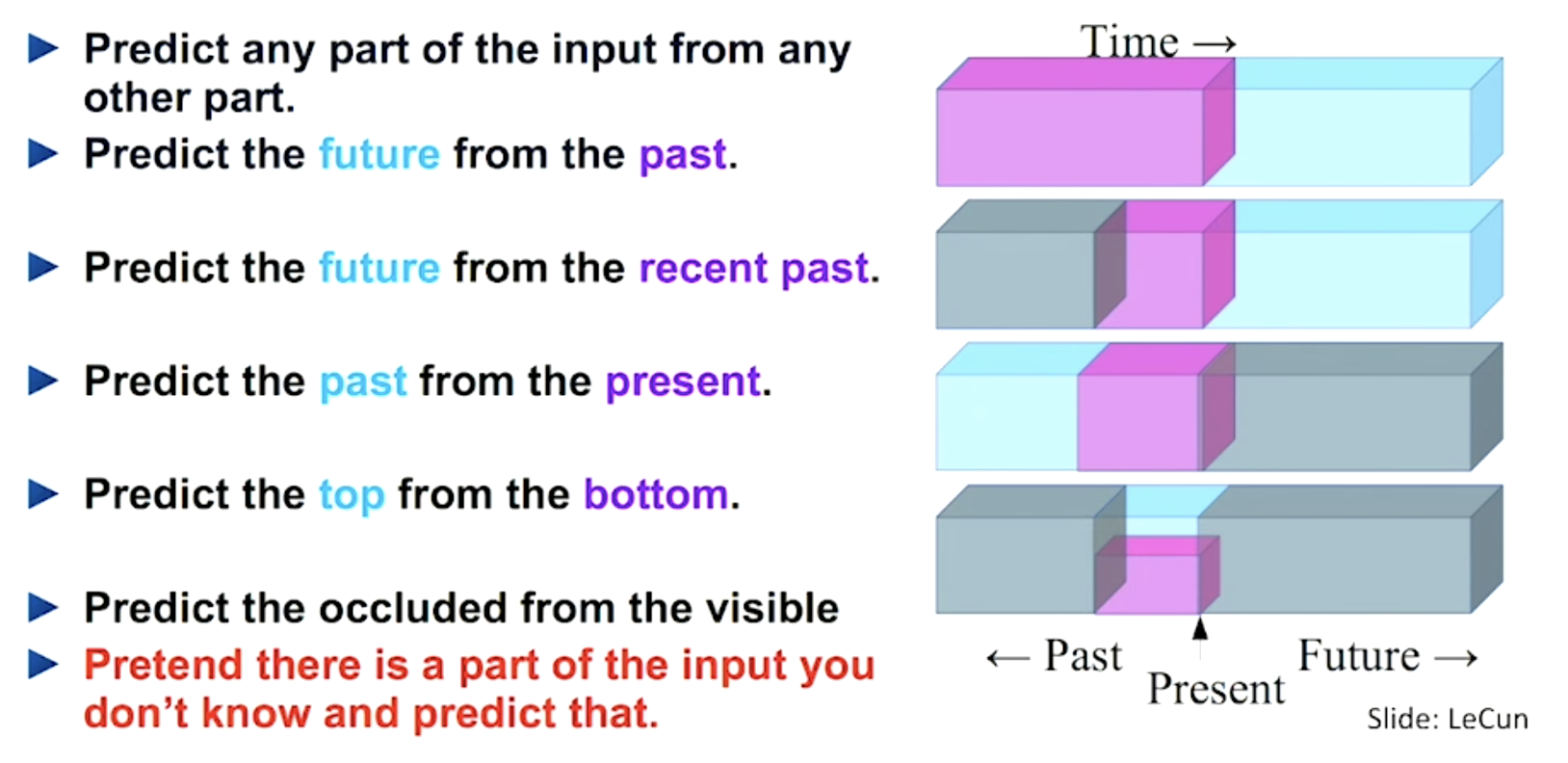
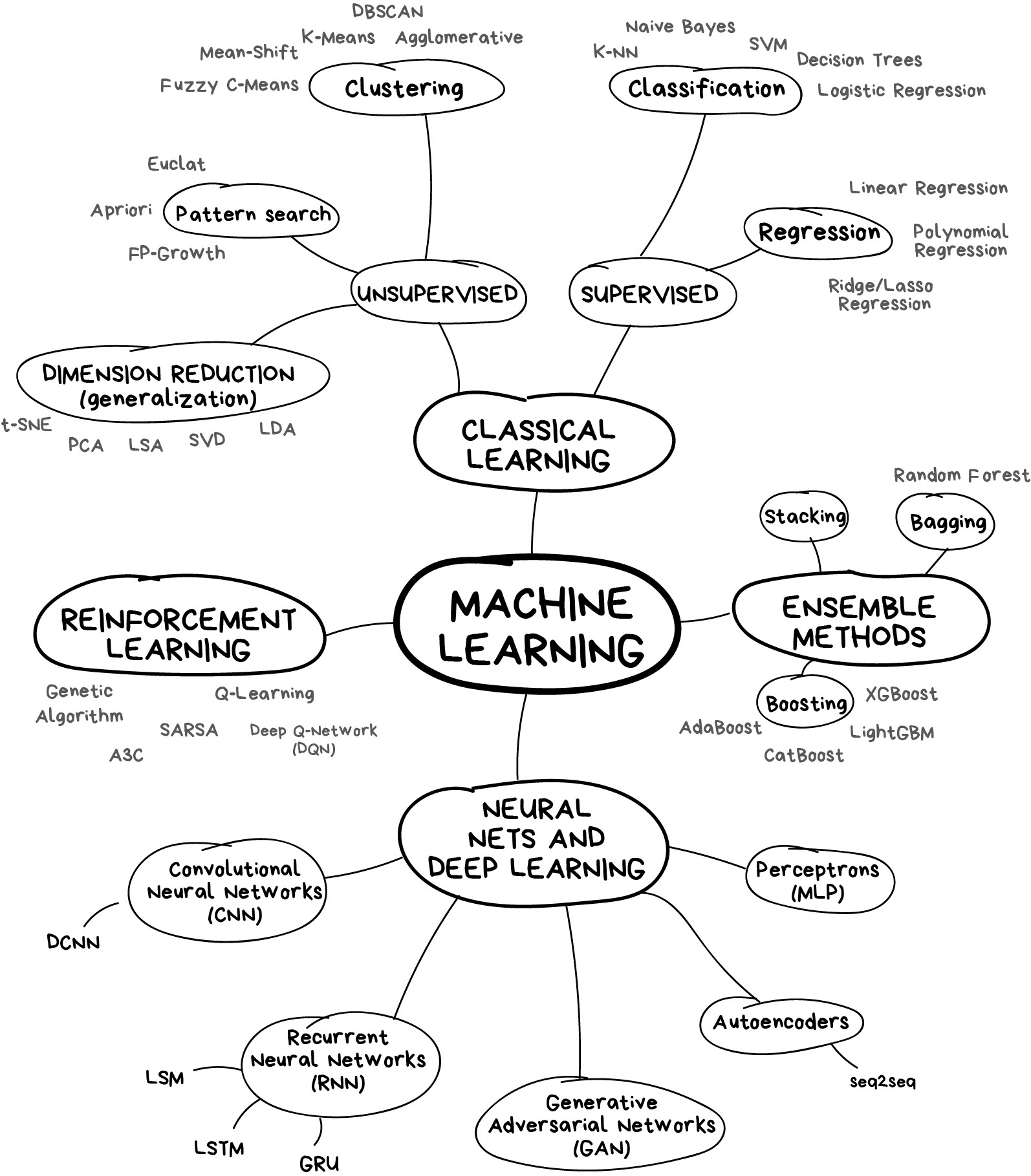
Contents
Artificial Intelligence - Machine Learning - Deep Learning
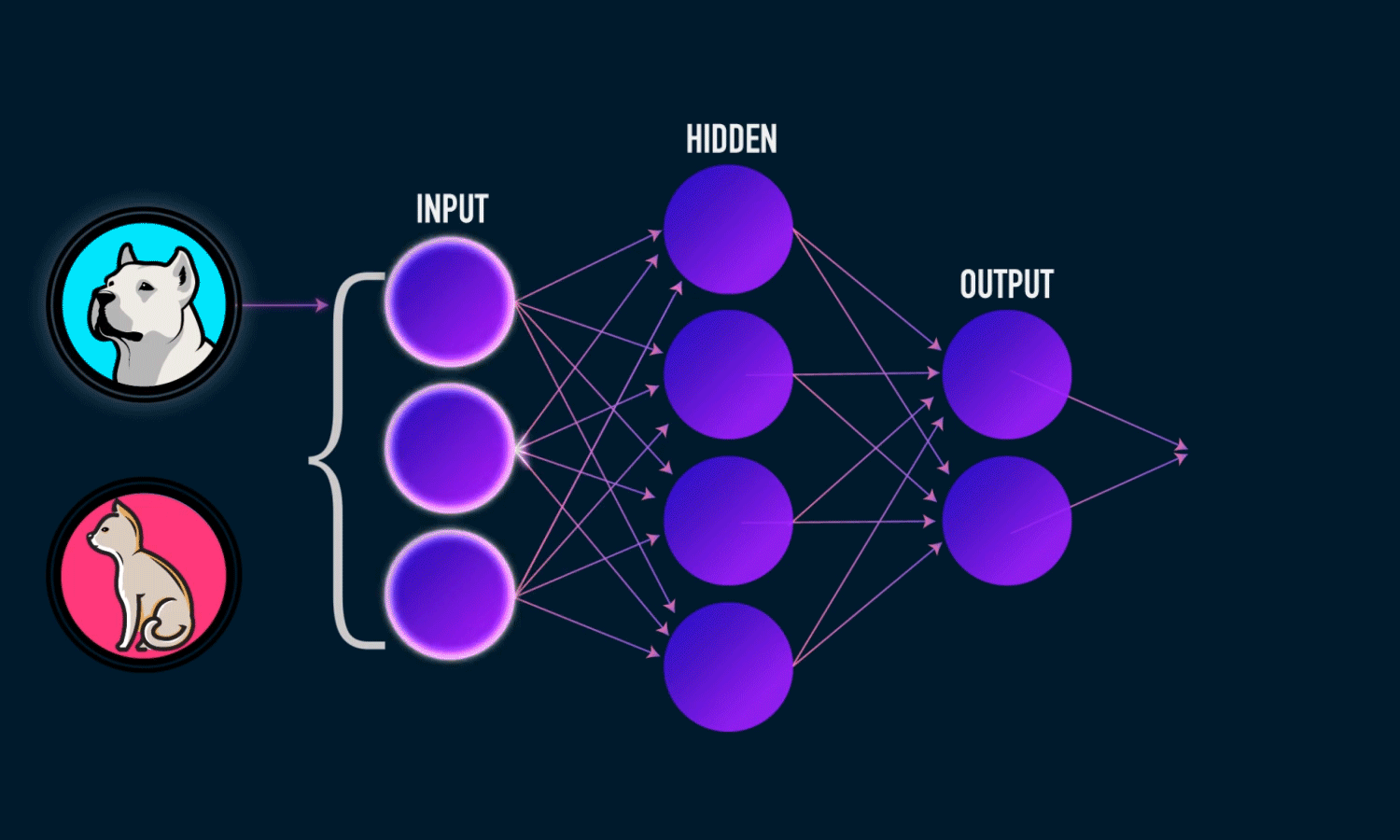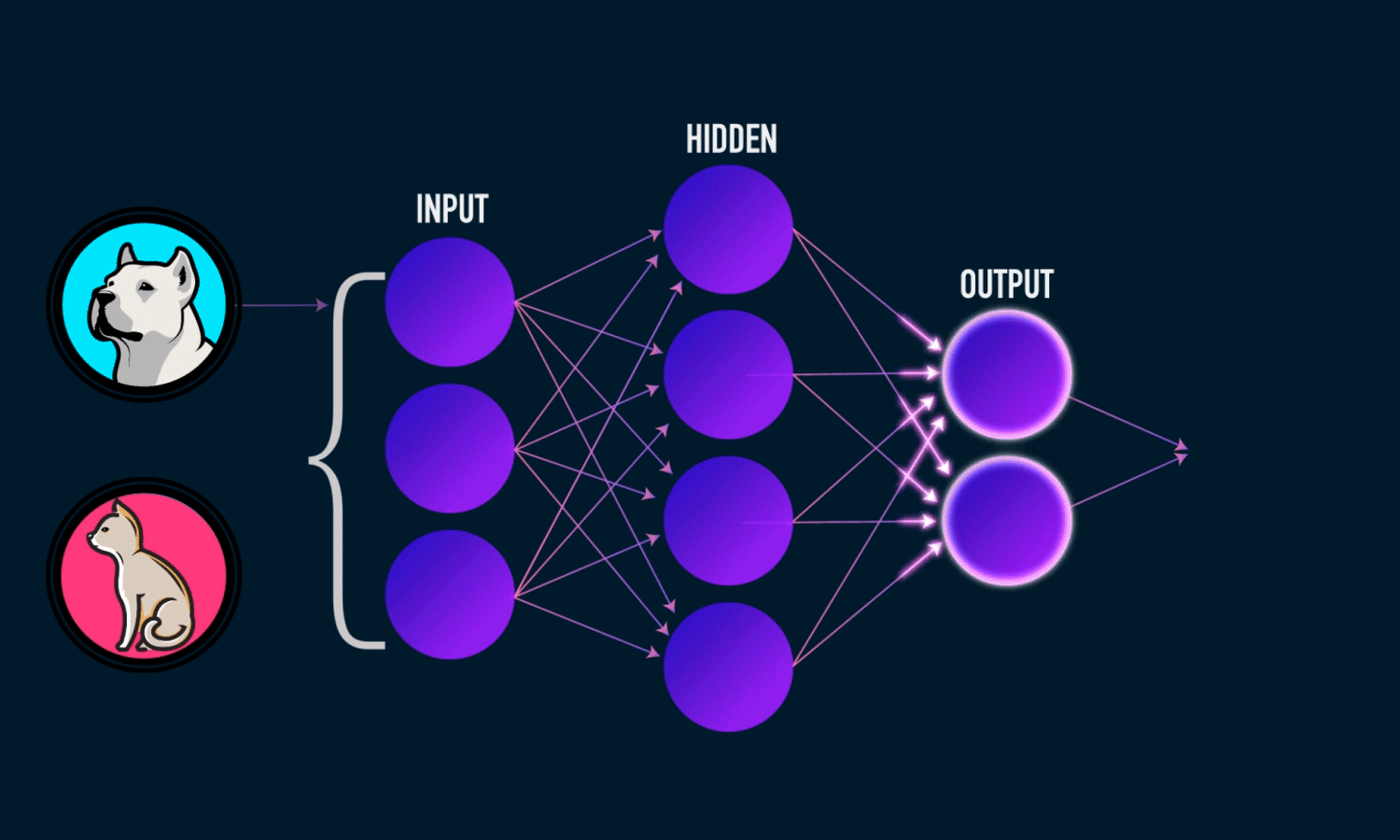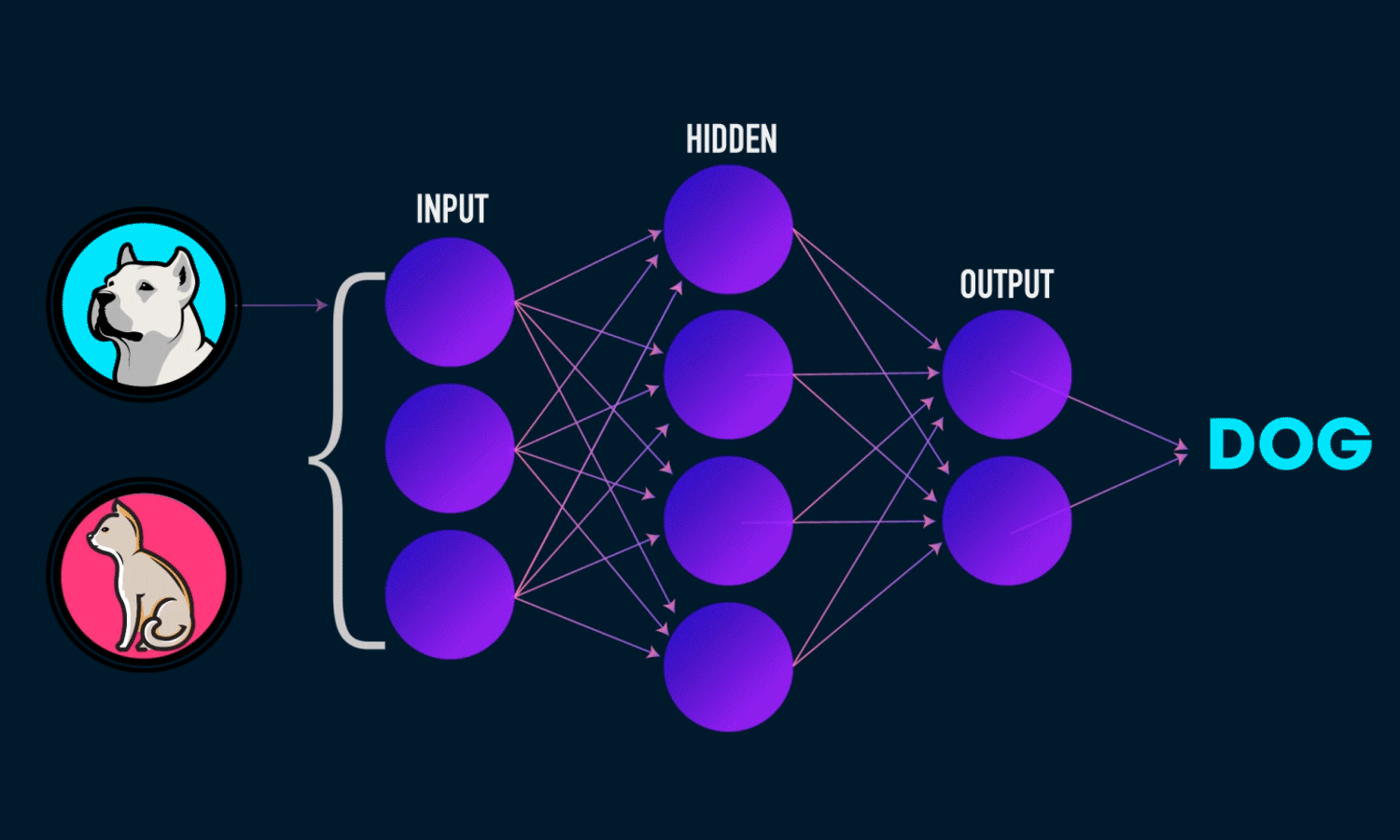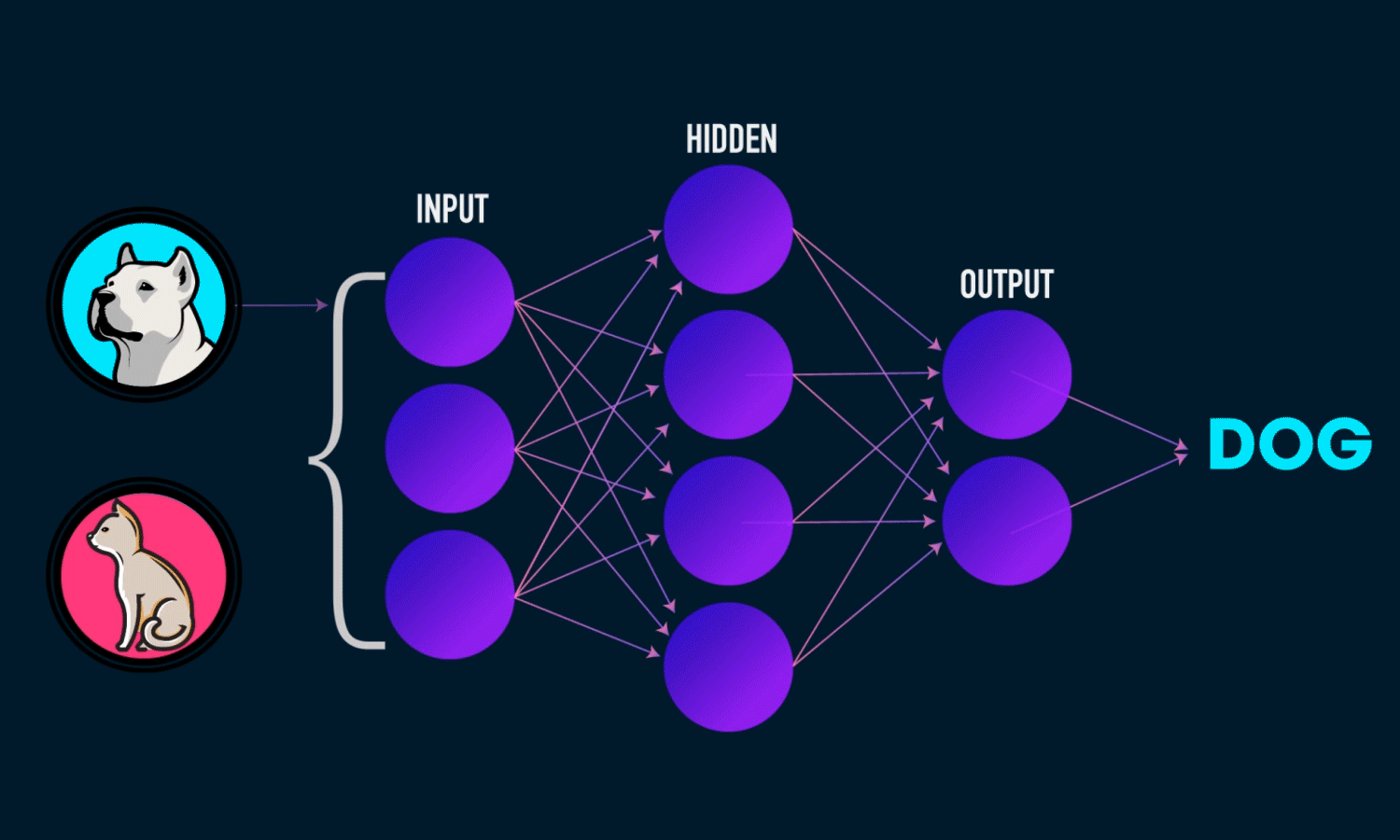
Neural Networks



Top Algorithms
AI Knowledge Map: How To Classify AI Technologies | Francesco Corea - KDnuggets
How often do data scientist jobs require data scientists to develop machine learning models from scratch?
Models? All the time. But you probably meant machine learning algorithms. In that case, the answer is almost never.
It is very rare that entirely new algorithms show up at all. How many significant breakthroughs did we see in this decade? Generative Adversarial Network (GAN) is one that comes to mind. The attention mechanism in neural machine translation is another one (as suggested by Sathvik Udupa). Both were innovations that came from academia.
In industry, DeepMind has come up with some interesting work, like Deep Q-learning, Monte Carlo Tree Search and Neural Turing Machines, but these were mostly based on previous research.
Very few data scientists are working on new algorithms. This is something that happens almost exclusively in industrial R&D labs. Not many companies in the world can afford the luxury of working on something as fundamental as new machine learning algorithms. It’s a big investment for a tiny chance that something useful materializes.
Data scientists solve real-world problems, and are subjected to time and cost constraints. There’s also something called the “no free lunch” theorem. Basically, it means that no optimization algorithm can outperform others when averaged over all problems. Although a very specific algorithm could potentially outperform standard algorithms on a very specific problem, it’s just not worth the time and effort to invest in it. Even if the team by some miracle manages to outperform standard algorithms, it’s almost certainly going to be a small incremental gain and not revolutionary. Håkon Hapnes Strand - LinkedIn


