Generative AI Stack
YouTube ... Quora ...Google search ...Google News ...Bing News
- Architectures for AI ... Generative AI Stack ... Enterprise Architecture (EA) ... Enterprise Portfolio Management (EPM) ... Architecture and Interior Design
- Artificial Intelligence (AI) ... Generative AI ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Large Language Model (LLM) ... Multimodal ... Foundation Models (FM) ... Generative Pre-trained ... Transformer ... Attention ... GAN ... BERT
- The Modern AI Stack: Design Principles for the Future of Enterprise AI Architectures - Menlo Ventures
Excerpt from... Emerging Architectures for LLM Applications | Matt Bornstein & Rajko Radovanovic - andreessen horowitz ... Large language models are a powerful new primitive for building software. But since they are so new—and behave so differently from normal computing resources—it’s not always obvious how to use them. At a very high level, the workflow can be divided into three stages:
Data preprocessing / embedding: This stage involves storing private data (legal documents, in our example) to be retrieved later. Typically, the documents are broken into chunks, passed through an embedding model, then stored in a specialized database called a vector database.
- Contextual data Contextual data for LLM apps can come in a variety of formats, including text documents, PDFs, CSVs, and SQL tables.
- Data pipelines Data pipelines with LLMs are a way to use large language models (LLMs) to process and analyze large amounts of data. LLMs can be used to extract information from text, translate languages, and answer questions.
- Databricks ... direct file access and direct native support for Python, data science and AI frameworks
- Airflow ... an open-source project that lets you programmatically author, schedule, and monitor your data pipelines using Python
- Unstructured ... is data that does not have a predefined schema, such as text documents, images, and audio files.
- Embedding model
- OpenAI ... called text-embedding-ada-002, 2nd generation embedding model
- Cohere ... a large language model (LLM) that is trained on a massive dataset of text and code. It can be used to represent the meaning of text as a list of numbers, which is useful for comparing text for similarity, clustering text, and classifying text.
- Hugging Face
- Vector database
- Pinecone ... provide long-term memory for storing and query vector embeddings, a type of data that represents semantic information
- Weaviate ... open source vector database that allows storing and retrieving data objects based on their semantic properties by indexing them with vectors
- ChromaDB ... the open-source embedding database, build Python or JavaScript LLM apps with memory
- Data pipelines Data pipelines with LLMs are a way to use large language models (LLMs) to process and analyze large amounts of data. LLMs can be used to extract information from text, translate languages, and answer questions.
Prompt construction / retrieval: When a user submits a query (a legal question, in this case), the application constructs a series of prompts to submit to the language model. A compiled prompt typically combines a prompt template hard-coded by the developer; examples of valid outputs called few-shot examples; any necessary information retrieved from external APIs; and a set of relevant documents retrieved from the vector database.
- Prompt Few-shot examples Most developers start new projects by experimenting with simple prompts, consisting of direct instructions (zero-shot prompting) or possibly some example outputs (few-shot prompting).
- Playground
- OpenAI ... a web-based tool that makes it easy to test prompts and get familiar with how the API works.
- nat.dev ... An LLM playground you can run on your laptop; Use any model from OpenAI, Anthropic, Cohere, Forefront, HuggingFace, Aleph Alpha, Replicate, Banana and llama.cpp. Open Playground - GitHub
- Humanloop ... use the playground to experiment with new prompts, collect model generated data and user feedback, and finetune models
- Orchestration
- LangChain ... chain together different components to create more advanced use cases around LLMs
- LlamaIndex ... data framework that allows users to connect custom data sources to Large Language Model (LLM)s. It provides tools to structure data, offers data connectors to ingest existing data sources and data formats (APIs, PDFs, docs, SQL, etc.), and provides an advanced retrieval/query interface over the data.
- ChatGPT ... creates chat-based applications.
- APIs/plugins
- Playground
Prompt execution / inference: Once the prompts have been compiled, they are submitted to a pre-trained LLM for inference—including both proprietary model APIs and open-source or self-trained models. Some developers also add operational systems like logging, caching, and validation at this stage.
- LLM cache
- Redis ... (remote dictionary server) provides an adaptive prompt creation mechanism based on the current context, which helps overcome the context length limitations of LLMs
- SQLite ... disk-based storage to cache LLM prompts and responses for LangChain
- GPTCache ... uses different storage backends, such as Redis, SQLite, or MinIO, to cache LLM prompts
- Logging/LLMops
- Weights & Biases (W&B) ... improve prompt engineering with visually interactive evaluation loops.
- MLflow
- PromptLayer
- Helicone
- Validation
- Guardrails
- Rebuff
- Microsoft Guidance
- LMQL
- App hosting
- Vercel
- Steamship
- Streamlit
- Modal
- LM APIs (proprietary)
- LLM APIs (open)
- Cloud providers
- AWS
- GCP
- Azure
- CoreWeave
- Opinionated clouds
- Databricks
- Anyscale
- Mosaic
- Modal
- RunPod

'https://i0.wp.com/a16z.com/wp-content/uploads/2023/06/2657-Emerging-LLM-App-Stack-R2-1-of-4-2.png'
Contents
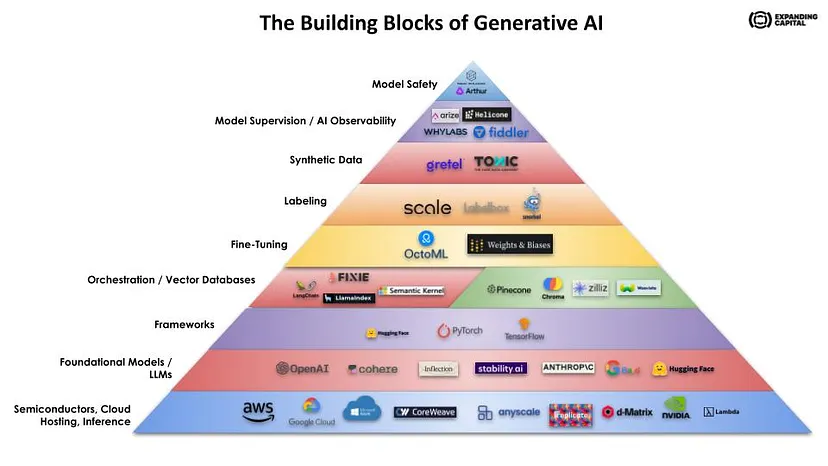
The Building Blocks of Generative AI
'https://miro.medium.com/v2/resize:fit:828/format:webp/1*HGK_A6g9EuQqQENdPP_e_g.jpeg'
Analyzing Layers and Players

'https://media.licdn.com/dms/image/D5612AQHe75n0tww_eA/article-cover_image-shrink_600_2000/0/1677813607702?e=1700697600&v=beta&t=WQtreRkX1abXMbXXf5To_45ij8Rj1OKqm5JHzEHEZCA'
The Missing Link in Generative AI

'https://global-uploads.webflow.com/5e069c660d37a18c17207c29/6488b386000b9dfa5245ddf3_the-new-generative-ai-stack-1.png'
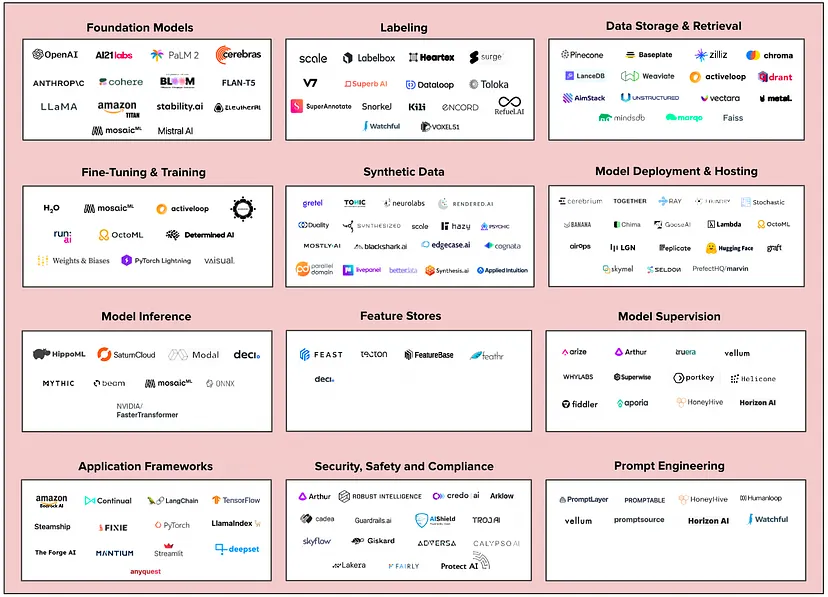
The New Infrastructure Stack for Generative AI
'https://miro.medium.com/v2/resize:fit:828/format:webp/1*Wx3APBj_i6P385EMmY4_Mg.png'