Difference between revisions of "Explainable / Interpretable AI"
m |
m |
||
| (40 intermediate revisions by the same user not shown) | |||
| Line 2: | Line 2: | ||
|title=PRIMO.ai | |title=PRIMO.ai | ||
|titlemode=append | |titlemode=append | ||
| − | |keywords=artificial, intelligence, machine, learning, models | + | |keywords=ChatGPT, artificial, intelligence, machine, learning, NLP, NLG, NLC, NLU, models, data, singularity, moonshot, Sentience, AGI, Emergence, Moonshot, Explainable, TensorFlow, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Hugging Face, OpenAI, Tensorflow, OpenAI, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Meta, LLM, metaverse, assistants, agents, digital twin, IoT, Transhumanism, Immersive Reality, Generative AI, Conversational AI, Perplexity, Bing, You, Bard, Ernie, prompt Engineering LangChain, Video/Image, Vision, End-to-End Speech, Synthesize Speech, Speech Recognition, Stanford, MIT |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools |
| − | |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | + | |
| + | <!-- Google tag (gtag.js) --> | ||
| + | <script async src="https://www.googletagmanager.com/gtag/js?id=G-4GCWLBVJ7T"></script> | ||
| + | <script> | ||
| + | window.dataLayer = window.dataLayer || []; | ||
| + | function gtag(){dataLayer.push(arguments);} | ||
| + | gtag('js', new Date()); | ||
| + | |||
| + | gtag('config', 'G-4GCWLBVJ7T'); | ||
| + | </script> | ||
}} | }} | ||
| − | [ | + | [https://www.youtube.com/results?search_query=Explainable+Interpretable+AI YouTube] |
| − | [ | + | [https://www.quora.com/search?q=Explainable%20Interpretable%20AI ... Quora] |
| + | [https://www.google.com/search?q=Explainable+Interpretable+AI ...Google search] | ||
| + | [https://news.google.com/search?q=Explainable+Interpretable+AI ...Google News] | ||
| + | [https://www.bing.com/news/search?q=Explainable+Interpretable+AI&qft=interval%3d%228%22 ...Bing News] | ||
| − | * [[ | + | * [[Artificial General Intelligence (AGI) to Singularity]] ... [[Inside Out - Curious Optimistic Reasoning| Curious Reasoning]] ... [[Emergence]] ... [[Moonshots]] ... [[Explainable / Interpretable AI|Explainable AI]] ... [[Algorithm Administration#Automated Learning|Automated Learning]] |
| − | ** [[Government Services]] | + | * [[Predictive Analytics]] ... [[Operations & Maintenance|Predictive Maintenance]] ... [[Forecasting]] ... [[Market Trading]] ... [[Sports Prediction]] ... [[Marketing]] ... [[Politics]] ... [[Excel#Excel - Forecasting|Excel]] |
| − | * | + | * [[Cybersecurity]] ... [[Open-Source Intelligence - OSINT |OSINT]] ... [[Cybersecurity Frameworks, Architectures & Roadmaps | Frameworks]] ... [[Cybersecurity References|References]] ... [[Offense - Adversarial Threats/Attacks| Offense]] ... [[National Institute of Standards and Technology (NIST)|NIST]] ... [[U.S. Department of Homeland Security (DHS)| DHS]] ... [[Screening; Passenger, Luggage, & Cargo|Screening]] ... [[Law Enforcement]] ... [[Government Services|Government]] ... [[Defense]] ... [[Joint Capabilities Integration and Development System (JCIDS)#Cybersecurity & Acquisition Lifecycle Integration| Lifecycle Integration]] ... [[Cybersecurity Companies/Products|Products]] ... [[Cybersecurity: Evaluating & Selling|Evaluating]] |
| − | * [[ | + | * [[Risk, Compliance and Regulation]] ... [[Ethics]] ... [[Privacy]] ... [[Law]] ... [[AI Governance]] ... [[AI Verification and Validation]] |
| − | * | + | * [[Policy]] ... [[Policy vs Plan]] ... [[Constitutional AI]] ... [[Trust Region Policy Optimization (TRPO)]] ... [[Policy Gradient (PG)]] ... [[Proximal Policy Optimization (PPO)]] |
| − | + | * [[Strategy & Tactics]] ... [[Project Management]] ... [[Best Practices]] ... [[Checklists]] ... [[Project Check-in]] ... [[Evaluation]] | |
| − | + | ** [[Evaluation - Measures#Accuracy|Accuracy]] | |
| − | + | ** [[Evaluation - Measures#Precision & Recall (Sensitivity)|Precision & Recall (Sensitivity)]] | |
| + | ** [[Evaluation - Measures#Specificity|Specificity]] | ||
** [[Benchmarks]] | ** [[Benchmarks]] | ||
** [[Bias and Variances]] | ** [[Bias and Variances]] | ||
** [[Train, Validate, and Test]] | ** [[Train, Validate, and Test]] | ||
** [[Algorithm Administration#Model Monitoring|Model Monitoring]] | ** [[Algorithm Administration#Model Monitoring|Model Monitoring]] | ||
| − | * [[Visualization]] | + | * [[Analytics]] ... [[Visualization]] ... [[Graphical Tools for Modeling AI Components|Graphical Tools]] ... [[Diagrams for Business Analysis|Diagrams]] & [[Generative AI for Business Analysis|Business Analysis]] ... [[Requirements Management|Requirements]] ... [[Loop]] ... [[Bayes]] ... [[Network Pattern]] |
| − | * [[ | + | * [[Perspective]] ... [[Context]] ... [[In-Context Learning (ICL)]] ... [[Transfer Learning]] ... [[Out-of-Distribution (OOD) Generalization]] |
| − | + | * [[Causation vs. Correlation]] ... [[Autocorrelation]] ...[[Convolution vs. Cross-Correlation (Autocorrelation)]] | |
| − | * [[Causation vs. Correlation]] | + | * [[Large Language Model (LLM)]] ... [[Large Language Model (LLM)#Multimodal|Multimodal]] ... [[Foundation Models (FM)]] ... [[Generative Pre-trained Transformer (GPT)|Generative Pre-trained]] ... [[Transformer]] ... [[Attention]] ... [[Generative Adversarial Network (GAN)|GAN]] ... [[Bidirectional Encoder Representations from Transformers (BERT)|BERT]] |
| − | * [[ | + | * [[RETRO]] | [[Google | DeepMind]] ... see what the AI has learned by examining the database rather than by studying the [[Neural Network]] |
| − | * [[ | + | * [[Creatives]] ... [[History of Artificial Intelligence (AI)]] ... [[Neural Network#Neural Network History|Neural Network History]] ... [[Rewriting Past, Shape our Future]] ... [[Archaeology]] ... [[Paleontology]] |
| − | * [[ | + | * [[Development]] ... [[Notebooks]] ... [[Development#AI Pair Programming Tools|AI Pair Programming]] ... [[Codeless Options, Code Generators, Drag n' Drop|Codeless]] ... [[Hugging Face]] ... [[Algorithm Administration#AIOps/MLOps|AIOps/MLOps]] ... [[Platforms: AI/Machine Learning as a Service (AIaaS/MLaaS)|AIaaS/MLaaS]] |
| − | * [ | + | * [https://towardsdatascience.com/python-libraries-for-interpretable-machine-learning-c476a08ed2c7 Python Libraries for Interpretable Machine Learning | Rebecca Vickery - Towards Data Science] |
* Tools: | * Tools: | ||
** [[Python#LIME|LIME]] (Local Interpretable Model-agnostic Explanations) explains the prediction of any classifier | ** [[Python#LIME|LIME]] (Local Interpretable Model-agnostic Explanations) explains the prediction of any classifier | ||
| Line 34: | Line 47: | ||
** [[Python#yellowbrick|yellowbrick]] the visualiser objects, the core interface, are scikit-learn estimators | ** [[Python#yellowbrick|yellowbrick]] the visualiser objects, the core interface, are scikit-learn estimators | ||
** [[Python#MLxtend|MLxtend]] the visualiser objects, the core interface, scikit-learn estimators | ** [[Python#MLxtend|MLxtend]] the visualiser objects, the core interface, scikit-learn estimators | ||
| − | ** [ | + | ** [https://github.com/tensorflow/lucid#notebooks Lucid Notebooks | GitHub] ... a collection of infrastructure and tools for research in neural network interpretability. |
| − | * [[ | + | * [[Singularity]] ... [[Artificial Consciousness / Sentience|Sentience]] ... [[Artificial General Intelligence (AGI)| AGI]] ... [[Inside Out - Curious Optimistic Reasoning| Curious Reasoning]] ... [[Emergence]] ... [[Moonshots]] ... [[Explainable / Interpretable AI|Explainable AI]] ... [[Algorithm Administration#Automated Learning|Automated Learning]] |
| − | + | * [https://ico.org.uk/for-organisations/guide-to-data-protection/key-data-protection-themes/explaining-decisions-made-with-artificial-intelligence/ Explaining decisions made with AI | Information Commisioner's Office (ICO) and The Alan Turing Institute] | |
| − | * [ | + | * [https://arxiv.org/abs/1802.07623 Explanations] based on the Missing: Towards Contrastive Explanations with Pertinent Negatives - [[IBM]] |
| − | * [ | + | * [https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2903469 Why a right to explanation of automated decision-making does not exist in the General Data Protection Regulation | Wachter. S, Mittelstadt, B., Florida, L - University of Oxford], 28 Dec 2016 |
| − | * [ | + | * [https://thenewstack.io/deep-learning-neural-networks-google-deep-dream/ This is What Happens When Deep Learning Neural Networks Hallucinate | Kimberley Mok] |
| − | * [ | + | * [https://docs.h2o.ai/driverless-ai/latest-stable/docs/booklets/MLIBooklet.pdf H2O Machine Learning Interpretability with H2O Driverless AI] |
| − | * [ | + | * [https://www.quantamagazine.org/been-kim-is-building-a-translator-for-artificial-intelligence-20190110/ A New Approach to Understanding How Machines Think | John Pavus] |
| − | * [ | + | * [https://github.com/ModelOriented/DrWhy DrWhy | GitHub] collection of tools for Explainable AI (XAI) |
| − | * [ | + | * [https://arxiv.org/ftp/arxiv/papers/1901/1901.06622.pdf Mixed Formal Learning - A Path to Transparent Machine Learning | Sandra Carrico] |
| − | + | * [https://devops.com/take-advantage-of-open-source-trusted-ai-packages-in-ibm-cloud-pak-for-data/ Take advantage of open source trusted AI packages in IBM Cloud Pak for Data | Deborah Schalm - DevOps.com] | |
| − | * [ | + | * [https://arxiv.org/abs/2109.01401CX-ToM: Counterfactual Explanations with Theory-of-Mind for Enhancing Human Trust in Image Recognition Models | Arjun R. Akula, Keze Wang, Changsong Liu, Sari Saba-Sadiya, Hongjing Lu, Sinisa Todorovic, Joyce Chai, Song-Chun Zhu] |
| − | * [ | + | * [https://theconversation.com/ai-will-soon-become-impossible-for-humans-to-comprehend-the-story-of-neural-networks-tells-us-why-199456 AI will soon become impossible for humans to comprehend – the story of neural networks tells us why | David Beer - The Conversation] |
| − | * [ | + | * [https://www.nist.gov/topics/artificial-intelligence/ai-foundational-research-explainability AI Foundational Research - Exp lainability | NIST] ...[https://www.nist.gov/system/files/documents/2020/08/17/NIST%20Explainable%20AI%20Draft%20NISTIR8312%20%281%29.pdf Four Principles of Explainable Artificial Intelligence | P. J. Phillips, C. Hahn, P. Fontana, D. Broniatowski, and M. Przybocki - NIST] |
| − | * [ | ||
** <b>Explanation</b>: Systems deliver accompanying evidence or reason(s) for all outputs. | ** <b>Explanation</b>: Systems deliver accompanying evidence or reason(s) for all outputs. | ||
** <b>Meaningful</b>: Systems provide explanations that are understandable to individual users. | ** <b>Meaningful</b>: Systems provide explanations that are understandable to individual users. | ||
** <b>Explanation Accuracy</b>: The explanation correctly reflects the system’s process for generating the output. | ** <b>Explanation Accuracy</b>: The explanation correctly reflects the system’s process for generating the output. | ||
** <b>Knowledge Limits</b>: The system only operates under conditions for which it was designed or when the system reaches a sufficient confidence in its output. | ** <b>Knowledge Limits</b>: The system only operates under conditions for which it was designed or when the system reaches a sufficient confidence in its output. | ||
| + | * [https://www.linkedin.com/pulse/collection-recommendable-papers-articles-explainable-ai-murat-durmus/ A collection of recommendable papers and articles on Explainable AI (XAI) | Murat Durmus - LinkedIn] | ||
| + | |||
= Explainable Artificial Intelligence (XAI) = | = Explainable Artificial Intelligence (XAI) = | ||
| − | AI system produces results with an account of the path the system took to derive the solution/prediction - transparency of interpretation, rationale and justification. 'If you have a good causal model of the world you are dealing with, you can generalize even in unfamiliar situations. That’s crucial. We humans are able to project ourselves into situations that are very different from our day-to-day experience. Machines are not, because they don’t have these causal models. We can hand-craft them but that’s not enough. We need machines that can discover causal models. To some extend it’s never going to be perfect. We don’t have a perfect causal model of the reality, that’s why we make a lot of mistakes. But we are much better off at doing this than other animals.' [ | + | AI system produces results with an account of the path the system took to derive the solution/prediction - transparency of interpretation, rationale and justification. 'If you have a good causal model of the world you are dealing with, you can generalize even in unfamiliar situations. That’s crucial. We humans are able to project ourselves into situations that are very different from our day-to-day experience. Machines are not, because they don’t have these causal models. We can hand-craft them but that’s not enough. We need machines that can discover causal models. To some extend it’s never going to be perfect. We don’t have a perfect causal model of the reality, that’s why we make a lot of mistakes. But we are much better off at doing this than other animals.' [https://www.technologyreview.com/s/612434/one-of-the-fathers-of-ai-is-worried-about-its-future/ Yoshua Benjio] |
| + | |||
| + | Progress made with XAI: | ||
| + | * <b>Explainable AI Techniques</b>: There are now off-the-shelf explainable AI techniques that developers can use to incorporate explainable AI techniques into their workflows as part of their modeling operations. These techniques help to disclose the program's strengths and weaknesses, the specific criteria the program uses to arrive at a decision, and why a program makes a particular decision, as opposed to alternatives. | ||
| + | * <b>Model Explainability</b>: is essential for high-stakes domains such as healthcare, finance, the legal system, and other critical industrial sectors. Explainable AI (XAI) is a subfield of AI that aims to develop AI systems that can provide clear and understandable explanations of their decision-making processes to humans. The goal of XAI is to make AI more transparent, trustworthy, responsible, and ethical | ||
| + | * <b>Concept-Based Explanations</b>: There has been progress in using concept-based explanations to explain deep neural networks. TCAV (Testing with Concept Activation Vectors) is a technique developed by Google AI that uses concept-based explanations to explain deep neural networks. This technique helps to make AI more transparent, trustworthy, responsible, and ethical. | ||
| + | * <b>Interpretable and Inclusive AI</b>: There has been progress in building interpretable and inclusive AI systems from the ground up with tools designed to help detect and resolve bias, drift, and other gaps in data and models. AI Explanations in AutoML Tables, Vertex AI Predictions, and Notebooks provide data scientists with the insight needed to improve datasets or model architecture and debug model performance. | ||
<youtube>OvId1rhhBJk</youtube> | <youtube>OvId1rhhBJk</youtube> | ||
| Line 84: | Line 104: | ||
== Explainable Computer Vision with Grad-CAM == | == Explainable Computer Vision with Grad-CAM == | ||
| − | * [ | + | * [https://github.com/ramprs/grad-cam/ Grad-CAM: Gradient-weighted Class Activation Mapping | R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra - ramprs/grad-cam] |
| − | ...[ | + | ...[https://gradcam.cloudcv.org/ try demonstrations] |
| − | * [ | + | * [https://github.com/FairyOnIce/FairyOnIce.github.io FairyOnIce's Grad-CAM code | GitHub] |
| − | * [ | + | * [https://github.com/jacobgil/keras-grad-cam Grad-CAM implementation in Keras | Jacob Gildenblat - jacobgil/keras-grad-cam] |
| − | * [ | + | * [https://gradcam.cloudcv.org/ Grad-CAM Demo | modified by] [[Creatives#Siraj Raval|Siraj Raval]] |
| − | We propose a technique for producing "visual explanations" for decisions from a large class of [[(Deep) Convolutional Neural Network (DCNN/CNN)|CNN]]-based models, making them more transparent. Our approach - Gradient-weighted Class Activation Mapping (Grad-CAM), uses the gradients of any target concept, flowing into the final convolutional layer to produce a coarse localization map highlighting important regions in the image for predicting the concept. Grad-CAM is applicable to a wide variety of [[(Deep) Convolutional Neural Network (DCNN/CNN)|CNN]] model-families: (1) [[(Deep) Convolutional Neural Network (DCNN/CNN)|CNN]]s with fully-connected layers, (2) [[(Deep) Convolutional Neural Network (DCNN/CNN)|CNN]]s used for structured outputs, (3) [[(Deep) Convolutional Neural Network (DCNN/CNN)|CNN]]s used in tasks with multimodal inputs or reinforcement learning, without any architectural changes or re-training. We combine Grad-CAM with fine-grained visualizations to create a high-resolution class-discriminative visualization and apply it to off-the-shelf image classification, captioning, and visual question answering (VQA) models, including [[(Deep) Residual Network (DRN) - ResNet|ResNet]]-based architectures. In the context of image classification models, our visualizations (a) lend insights into their failure modes, (b) are robust to adversarial images, (c) outperform previous methods on localization, (d) are more faithful to the underlying model and (e) help achieve generalization by identifying dataset bias. For captioning and VQA, we show that even non-attention based models can localize inputs. We devise a way to identify important neurons through Grad-CAM and combine it with neuron names to provide textual explanations for model decisions. Finally, we design and conduct human studies to measure if Grad-CAM helps users establish appropriate trust in predictions from models and show that Grad-CAM helps untrained users successfully discern a 'stronger' nodel from a 'weaker' one even when both make identical predictions. [ | + | We propose a technique for producing "visual explanations" for decisions from a large class of [[(Deep) Convolutional Neural Network (DCNN/CNN)|CNN]]-based models, making them more transparent. Our approach - Gradient-weighted Class Activation Mapping (Grad-CAM), uses the gradients of any target concept, flowing into the final convolutional layer to produce a coarse localization map highlighting important regions in the image for predicting the concept. Grad-CAM is applicable to a wide variety of [[(Deep) Convolutional Neural Network (DCNN/CNN)|CNN]] model-families: (1) [[(Deep) Convolutional Neural Network (DCNN/CNN)|CNN]]s with fully-connected layers, (2) [[(Deep) Convolutional Neural Network (DCNN/CNN)|CNN]]s used for structured outputs, (3) [[(Deep) Convolutional Neural Network (DCNN/CNN)|CNN]]s used in tasks with multimodal inputs or reinforcement learning, without any architectural changes or re-training. We combine Grad-CAM with fine-grained visualizations to create a high-resolution class-discriminative visualization and apply it to off-the-shelf image classification, captioning, and visual question answering (VQA) models, including [[(Deep) Residual Network (DRN) - ResNet|ResNet]]-based architectures. In the [[context]] of image classification models, our visualizations (a) lend insights into their failure modes, (b) are robust to adversarial images, (c) outperform previous methods on localization, (d) are more faithful to the underlying model and (e) help achieve generalization by identifying dataset bias. For captioning and VQA, we show that even non-attention based models can localize inputs. We devise a way to identify important neurons through Grad-CAM and combine it with neuron names to provide textual explanations for model decisions. Finally, we design and conduct human studies to measure if Grad-CAM helps users establish appropriate trust in predictions from models and show that Grad-CAM helps untrained users successfully discern a 'stronger' nodel from a 'weaker' one even when both make identical predictions. [https://arxiv.org/abs/1610.02391 Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization | R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra] |
Building powerful Computer Vision-based apps without deep expertise has become possible for more people due to easily accessible tools like Python, Colab, Keras, PyTorch, and Tensorflow. But why does a computer classify an image the way that it does? This is a question that is critical when it comes to AI applied to diagnostics, driving, or any other form of critical decision making. In this episode, I'd like to raise awareness around one technique in particular that I found called "Grad-Cam" or Gradient Class Activation Mappings. It allows you to generate a heatmap that helps detail what your model thinks the most relevant features in an image are that cause it to make its predictions. I'll be explaining the math behind it and demoing a code sample by fairyonice to help you understand it. I hope that after this video, you'll be able to implement it in your own project. Enjoy! | [[Creatives#Siraj Raval|Siraj Raval]] | Building powerful Computer Vision-based apps without deep expertise has become possible for more people due to easily accessible tools like Python, Colab, Keras, PyTorch, and Tensorflow. But why does a computer classify an image the way that it does? This is a question that is critical when it comes to AI applied to diagnostics, driving, or any other form of critical decision making. In this episode, I'd like to raise awareness around one technique in particular that I found called "Grad-Cam" or Gradient Class Activation Mappings. It allows you to generate a heatmap that helps detail what your model thinks the most relevant features in an image are that cause it to make its predictions. I'll be explaining the math behind it and demoing a code sample by fairyonice to help you understand it. I hope that after this video, you'll be able to implement it in your own project. Enjoy! | [[Creatives#Siraj Raval|Siraj Raval]] | ||
| − | + | https://github.com/jacobgil/keras-grad-cam/raw/master/examples/cat_dog.png | |
| − | + | https://github.com/jacobgil/keras-grad-cam/raw/master/examples/cat_dog_242_gradcam.jpg | |
| − | + | https://github.com/jacobgil/keras-grad-cam/raw/master/examples/cat_dog_242_guided_gradcam.jpg | |
<youtube>s8hJ_SwCVI4</youtube> | <youtube>s8hJ_SwCVI4</youtube> | ||
| Line 104: | Line 124: | ||
= <span id="Interpretable"></span>Interpretable = | = <span id="Interpretable"></span>Interpretable = | ||
| − | [ | + | [https://www.youtube.com/results?search_query=Interpretable+Artificial+Intelligence+deep+machine+learning Youtube search...] |
| − | [ | + | [https://www.google.com/search?q=Interpretable+Artificial+Intelligence+deep+machine+learning ...Google search] |
| − | Please Stop Doing "Explainable" ML: There has been an increasing trend in healthcare and criminal justice to leverage machine learning (ML) for high-stakes prediction applications that deeply impact human lives. Many of the ML models are black boxes that do not explain their predictions in a way that humans can understand. The lack of transparency and accountability of predictive models can have (and has already had) severe consequences; there have been cases of people incorrectly denied parole, poor bail decisions leading to the release of dangerous criminals, ML-based pollution models stating that highly polluted air was safe to breathe, and generally poor use of limited valuable resources in criminal justice, medicine, energy reliability, finance, and in other domains. Rather than trying to create models that are inherently interpretable, there has been a recent explosion of work on “Explainable ML,” where a second (posthoc) model is created to explain the first black box model. This is problematic. Explanations are often not reliable, and can be misleading, as we discuss below. If we instead use models that are inherently interpretable, they provide their own explanations, which are faithful to what the model actually computes. [ | + | Please Stop Doing "Explainable" ML: There has been an increasing trend in healthcare and criminal justice to leverage machine learning (ML) for high-stakes prediction applications that deeply impact human lives. Many of the ML models are black boxes that do not explain their predictions in a way that humans can understand. The lack of transparency and accountability of [[Predictive Analytics|predictive models]] can have (and has already had) severe consequences; there have been cases of people incorrectly denied parole, poor bail decisions leading to the release of dangerous criminals, ML-based pollution models stating that highly polluted air was safe to breathe, and generally poor use of limited valuable resources in criminal justice, medicine, energy reliability, finance, and in other domains. Rather than trying to create models that are inherently interpretable, there has been a recent explosion of work on “Explainable ML,” where a second (posthoc) model is created to explain the first black box model. This is problematic. Explanations are often not reliable, and can be misleading, as we discuss below. If we instead use models that are inherently interpretable, they provide their own explanations, which are faithful to what the model actually computes. [https://arxiv.org/pdf/1811.10154.pdf Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead | Cynthia Rudin - Duke University] |
<youtube>I0yrJz8uc5Q</youtube> | <youtube>I0yrJz8uc5Q</youtube> | ||
| Line 124: | Line 144: | ||
== <span id="Accuracy & Interpretability Trade-Off"></span>Accuracy & Interpretability Trade-Off == | == <span id="Accuracy & Interpretability Trade-Off"></span>Accuracy & Interpretability Trade-Off == | ||
| − | [ | + | [https://www.youtube.com/results?search_query=Interpretable+Accuracy+tradeoff+Artificial+Intelligence+deep+machine+learning Youtube search...] |
| − | [ | + | [https://www.google.com/search?q=Interpretable+Accuracy+tradeoff+Artificial+Intelligence+deep+machine+learning ...Google search] |
| − | * [ | + | * [https://machinelearningmastery.com/model-prediction-versus-interpretation-in-machine-learning/ Model Prediction Accuracy Versus Interpretation in Machine Learning | Jason Brownlee - Machine Learning Mastery] |
| − | * [ | + | * [https://towardsdatascience.com/the-balance-accuracy-vs-interpretability-1b3861408062 The balance: Accuracy vs. Interpretability | Sharayu Rane - Towards Data Science] |
{|<!-- T --> | {|<!-- T --> | ||
| Line 139: | Line 159: | ||
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| + | |||
| + | == <span id="Weirder Than You Thought"></span>Weirder Than You Thought == | ||
| + | * [https://www.anthropic.com/research/tracing-thoughts-language-model Tracing the thoughts of a large language model | ][[Anthropic]] | ||
| + | * [https://transformer-circuits.pub/2025/attribution-graphs/biology.html On the Biology of a Large Language Model | ][https://transformer-circuits.pub/ Transformer Circuits Thread] | ||
| + | * [https://www.pcgamer.com/software/ai/anthropic-has-developed-an-ai-brain-scanner-to-understand-how-llms-work-and-it-turns-out-the-reason-why-chatbots-are-terrible-at-simple-math-and-hallucinate-is-weirder-than-you-thought/ Anthropic has developed an AI 'brain scanner' to understand how LLMs work and it turns out the reason why chatbots are terrible at simple math and hallucinate is weirder than you thought | Jeremy Laird - PC GAMER] | ||
| + | |||
| + | With two new papers, [[Anthropic]]'s researchers have taken significant steps towards understanding the circuits that underlie an AI model’s thoughts. In one example from the paper, we find evidence that [[Claude]] will plan what it will say many words ahead, and write to get to that destination. We show this in the realm of poetry, where it thinks of possible rhyming words in advance and writes each line to get there. This is powerful evidence that, even though models are trained to output one word at a time, they may think on much longer horizons to do so. | ||
| + | |||
| + | <youtube>Bj9BD2D3DzA</youtube> | ||
= <span id="Trust"></span>Trust = | = <span id="Trust"></span>Trust = | ||
| − | [ | + | [https://www.youtube.com/results?search_query=Trust+fair+artificial+intelligence+Deep+Machine+Learning YouTube search...] |
| − | [ | + | [https://www.google.com/search?q=Trust+fair+artificial+intelligence+Deep+Machine+Learning ...Google search] |
* [[Cybersecurity Frameworks, Architectures & Roadmaps]] | * [[Cybersecurity Frameworks, Architectures & Roadmaps]] | ||
| − | * [ | + | * [https://fairlearn.github.io/ Fairlearn] ...a toolkit to assess and improve the fairness of machine learning models. Use common fairness metrics and an interactive dashboard to assess which groups of people may be negatively impacted. |
| − | * [ | + | * [https://link.springer.com/article/10.1007/s13347-019-00378-3 In AI We Trust Incrementally: a Multi-layer Model of Trust to Analyze Human-Artificial Intelligence Interactions | A. Ferrario, M. Loi and E. Viganò - DOI.org] |
| − | * [ | + | * [https://www.capgemini.com/service/perform-ai/trusted-ai/ Trusted AI | Capgemini] |
| − | * [ | + | * [https://www.militaryaerospace.com/computers/article/14181248/trusted-computing-artificial-intelligence-software BAE Systems delivers trusted computing MindfuL software to help humans believe artificial intelligence (AI) - Military & Aerospace Electronics] |
| − | * [ | + | * [https://www.sciencedaily.com/releases/2020/08/200827105937.htm How to make AI trustworthy | University of Southern California - ScienceDaily] |
| − | * [ | + | * [https://federalnewsnetwork.com/defense-main/2020/08/building-trust-in-ai-is-key-to-autonomous-drones-flying-cars/ Building trust in AI is key to autonomous drones, flying cars | David Thorton - Federal News Network] |
| − | * [ | + | * [https://www.consultancy.asia/news/3469/governments-should-close-the-ai-trust-gap-with-businesses Governments should close the AI trust gap with businesses | Consultancy.asia] |
| − | * [ | + | * [https://link.springer.com/article/10.1007/s43154-020-00029-y Trust in Robots: Challenges and Opportunities | Bing Cai Kok and Harold Soh - SpringerLink] |
| − | * [ | + | * [https://www.technologyreview.com/2020/09/23/1008757/interview-winner-million-dollar-ai-prize-cancer-healthcare-regulation/?itm_source=parsely-api We’re not ready for AI, says the winner of a new $1m AI prize | Will Douglas Heaven - MIT Technology Review] ...Regina Barzilay, the first winner of the Squirrel AI Award, on why the pandemic should be a wake-up call. |
<hr> | <hr> | ||
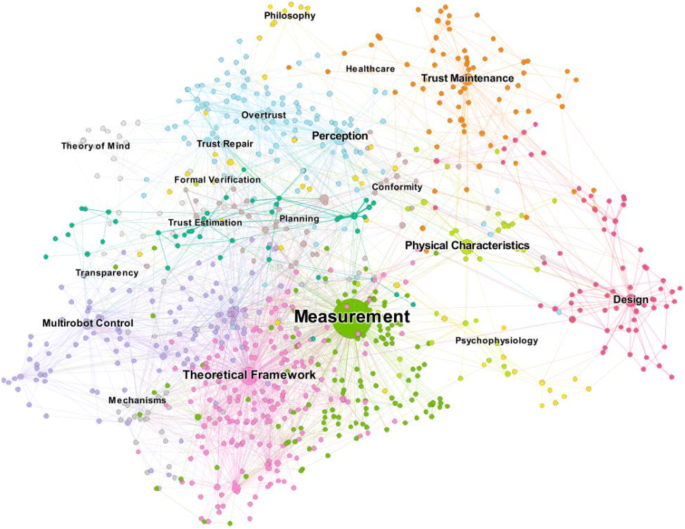
| − | [[Evaluation - Measures|Measurement]] and [ | + | [[Evaluation - Measures|Measurement]] and [https://en.wikipedia.org/wiki/Transparency Transparency] are key to trusted AI |
<hr> | <hr> | ||
| − | <img src=" | + | <img src="https://media.springernature.com/lw685/springer-static/image/art%3A10.1007%2Fs43154-020-00029-y/MediaObjects/43154_2020_29_Fig2_HTML.png" width="1100"> |
{|<!-- T --> | {|<!-- T --> | ||
| Line 171: | Line 200: | ||
<youtube>YzKh7wgRGpQ</youtube> | <youtube>YzKh7wgRGpQ</youtube> | ||
<b>How can you trust artificial intelligence and machine learning systems? | <b>How can you trust artificial intelligence and machine learning systems? | ||
| − | </b><br>[[Creatives#Raj Ramesh|Raj Ramesh]] Trust is always a big challenge with AI systems because we don’t often know how to interpret what is going on “in its head,” if you will. This is an active area of research, including the challenge of being able to explain how an AI system comes to the conclusion that it did. In this video, I simplify the concepts of trust so a business manager can understand how to look consider and build trusted AI within the context of their environment. | + | </b><br>[[Creatives#Raj Ramesh|Raj Ramesh]] Trust is always a big challenge with AI systems because we don’t often know how to interpret what is going on “in its head,” if you will. This is an active area of research, including the challenge of being able to explain how an AI system comes to the conclusion that it did. In this video, I simplify the concepts of trust so a business manager can understand how to look consider and build trusted AI within the [[context]] of their environment. |
|} | |} | ||
|<!-- M --> | |<!-- M --> | ||
| Line 179: | Line 208: | ||
<youtube>6Ei8rPVtCf8</youtube> | <youtube>6Ei8rPVtCf8</youtube> | ||
<b>Demo: Trust and Transparency for AI on the [[IBM]] Cloud | <b>Demo: Trust and Transparency for AI on the [[IBM]] Cloud | ||
| − | </b><br>See a demo of the new trust and transparency features for AI being made available in [[IBM]] Cloud. Explore the main features of the tooling using examples based on fraud detection and loan approval workflows. Learn more at | + | </b><br>See a demo of the new trust and transparency features for AI being made available in [[IBM]] Cloud. Explore the main features of the tooling using examples based on fraud detection and loan approval workflows. Learn more at https://ibm.co/2xmpQFM |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 188: | Line 217: | ||
<youtube>_tvAUQyf5_8</youtube> | <youtube>_tvAUQyf5_8</youtube> | ||
<b>Modeling the Interplay of Trust and Attention in HRI: an Autonomous Vehicle Study | <b>Modeling the Interplay of Trust and Attention in HRI: an Autonomous Vehicle Study | ||
| − | </b><br>Indu P. Bodala, Bing Cai Kok, Weicong Sng, Harold Soh HRI'20: ACM/IEEE International Conference on Human-Robot Interaction Session: Late Breaking Reports In this work, we study and model how two factors of human cognition, trust and attention, affect the way humans interact with autonomous vehicles. We develop a probabilistic model that succinctly captures how trust and attention evolve across time to drive behavior, and present results from a human-subjects experiment where participants interacted with a simulated autonomous vehicle while engaging with a secondary task. Our main findings suggest that trust affects attention, which in turn affects the human's decision to intervene with the autonomous vehicle. DOI:: | + | </b><br>Indu P. Bodala, Bing Cai Kok, Weicong Sng, Harold Soh HRI'20: ACM/IEEE International Conference on Human-Robot Interaction Session: Late Breaking Reports In this work, we study and model how two factors of human cognition, trust and attention, affect the way humans interact with autonomous vehicles. We develop a probabilistic model that succinctly captures how trust and attention evolve across time to drive behavior, and present results from a human-subjects experiment where participants interacted with a simulated autonomous vehicle while engaging with a secondary task. Our main findings suggest that trust affects attention, which in turn affects the human's decision to intervene with the autonomous vehicle. DOI:: https://doi.org/10.1145/3371382.3378262 WEB:: https://humanrobotinteraction.org/2020/ Companion program for the ACM/IEEE International Conference on Human-Robot Interaction 2020 |
|} | |} | ||
|<!-- M --> | |<!-- M --> | ||
| Line 196: | Line 225: | ||
<youtube>r9sO1Dedhr0</youtube> | <youtube>r9sO1Dedhr0</youtube> | ||
<b>Juiced and Ready to Predict Private Information in Deep Cooperative Reinforcement Learning | <b>Juiced and Ready to Predict Private Information in Deep Cooperative Reinforcement Learning | ||
| − | </b><br>Eugene Lim, Bing Cai Kok, Songli Wang, Joshua Lee, Harold Soh HRI'20: ACM/IEEE International Conference on Human-Robot Interaction In human-robot collaboration settings, each agent often has access to private information (PI) that is unavailable to others. Examples include task preferences, objectives, and beliefs. Here, we focus on the human-robot dyadic scenarios where the human has private information, but is unable to directly convey it to the robot. We present Q-Network with Private Information and Cooperation (Q-PICo), a method for training robots that can interactively assist humans with PI. In contrast to existing approaches, we explicitly model PI prediction, leading to a more interpretable network architecture. We also contribute Juiced, an environment inspired by the popular video game [ | + | </b><br>Eugene Lim, Bing Cai Kok, Songli Wang, Joshua Lee, Harold Soh HRI'20: ACM/IEEE International Conference on Human-Robot Interaction In human-robot collaboration settings, each [[Agents|agent]] often has access to private information (PI) that is unavailable to others. Examples include task preferences, objectives, and beliefs. Here, we focus on the human-robot dyadic scenarios where the human has private information, but is unable to directly convey it to the robot. We present Q-Network with Private Information and Cooperation (Q-PICo), a method for training robots that can interactively assist humans with PI. In contrast to existing approaches, we explicitly model PI prediction, leading to a more interpretable network architecture. We also contribute Juiced, an environment inspired by the popular video game [https://en.wikipedia.org/wiki/Overcooked_2 Overcooked], to test Q-PICo and other related methods for human-robot collaboration. Our initial experiments in Juiced show that the [[agents]] trained with Q-PICo can accurately predict PI and exhibit collaborative behavior. DOI: https://doi.org/10.1145/3371382.3378308 WEB:: http4s://humanrobotinteraction.org/2020/ Companion program for the ACM/IEEE International Conference on Human-Robot Interaction 2020 |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 222: | Line 251: | ||
<youtube>qFzYhceT_nk</youtube> | <youtube>qFzYhceT_nk</youtube> | ||
<b>Should you trust what AI says? | Elisa Celis | TEDxProvidence | <b>Should you trust what AI says? | Elisa Celis | TEDxProvidence | ||
| − | </b><br>Yale Professor Elisa Celis worked to create AI technology to better the world, only to find out that it has a problem. A big one. AI that is designed to serve all of us, in fact, excludes most of us. Learn why this happens, what can be fixed, and if that is really enough. Elisa Celis is an Assistant Professor of Statistics and Data Science at Yale University. Elisa’s research focuses on problems that arise at the interface of computation and machine learning and its societal ramifications. Specifically, she studies the manifestation of social and economic biases in our online lives via the algorithms that encode and perpetuate them. Her work spans multiple areas including social computing and crowd-sourcing, data science, and algorithm design with a current emphasis on fairness and diversity in artificial intelligence and machine learning. This talk was given at a TEDx event using the TED conference format but independently organized by a local community. Learn more at | + | </b><br>Yale Professor Elisa Celis worked to create AI technology to better the world, only to find out that it has a problem. A big one. AI that is designed to serve all of us, in fact, excludes most of us. Learn why this happens, what can be fixed, and if that is really enough. Elisa Celis is an Assistant Professor of Statistics and Data Science at Yale University. Elisa’s research focuses on problems that arise at the interface of computation and machine learning and its societal ramifications. Specifically, she studies the manifestation of social and economic biases in our online lives via the algorithms that encode and perpetuate them. Her work spans multiple areas including social computing and crowd-sourcing, data science, and algorithm design with a current emphasis on fairness and diversity in artificial intelligence and machine learning. This talk was given at a TEDx event using the TED conference format but independently organized by a local community. Learn more at https://www.ted.com/tedx |
|} | |} | ||
|<!-- M --> | |<!-- M --> | ||
| Line 239: | Line 268: | ||
* [[Government Services]] | * [[Government Services]] | ||
AI AND TRUSTWORTHINESS -- Increasing trust in AI technologies is a key element in accelerating their adoption for economic growth and future innovations that can benefit society. Today, the ability to understand and analyze the decisions of AI systems and measure their trustworthiness is limited. Among the characteristics that relate to trustworthy AI technologies are accuracy, reliability, resiliency, objectivity, security, explainability, | AI AND TRUSTWORTHINESS -- Increasing trust in AI technologies is a key element in accelerating their adoption for economic growth and future innovations that can benefit society. Today, the ability to understand and analyze the decisions of AI systems and measure their trustworthiness is limited. Among the characteristics that relate to trustworthy AI technologies are accuracy, reliability, resiliency, objectivity, security, explainability, | ||
| − | safety, and accountability. Ideally, these aspects of AI should be considered early in the design process and tested during the development and use of AI technologies. AI standards and related tools, along with AI risk management strategies, can help to address this limitation and spur innovation. ... It is important for those participating in AI standards development to be aware of, and to act consistently with, U.S. government policies and principles, including those that address societal and ethical issues, governance, and [[privacy]]. While there is broad agreement that these issues must factor into AI standards, it is not clear how that should be done and whether there is yet sufficient scientific and technical basis to develop those standards provisions. [ | + | safety, and accountability. Ideally, these aspects of AI should be considered early in the design process and tested during the [[development]] and use of AI technologies. AI standards and related tools, along with AI risk management strategies, can help to address this limitation and spur innovation. ... It is important for those participating in AI standards [[development]] to be aware of, and to act consistently with, U.S. government policies and principles, including those that address societal and ethical issues, governance, and [[privacy]]. While there is broad agreement that these issues must factor into AI standards, it is not clear how that should be done and whether there is yet sufficient scientific and technical basis to develop those standards provisions. [https://www.nist.gov/news-events/news/2019/08/plan-outlines-priorities-federal-agency-engagement-ai-standards-development Plan Outlines Priorities for Federal Agency Engagement in AI Standards Development;] |
| − | |||
<youtube>YSsYXAn_L00</youtube> | <youtube>YSsYXAn_L00</youtube> | ||
Latest revision as of 10:27, 28 May 2025
YouTube ... Quora ...Google search ...Google News ...Bing News
- Artificial General Intelligence (AGI) to Singularity ... Curious Reasoning ... Emergence ... Moonshots ... Explainable AI ... Automated Learning
- Predictive Analytics ... Predictive Maintenance ... Forecasting ... Market Trading ... Sports Prediction ... Marketing ... Politics ... Excel
- Cybersecurity ... OSINT ... Frameworks ... References ... Offense ... NIST ... DHS ... Screening ... Law Enforcement ... Government ... Defense ... Lifecycle Integration ... Products ... Evaluating
- Risk, Compliance and Regulation ... Ethics ... Privacy ... Law ... AI Governance ... AI Verification and Validation
- Policy ... Policy vs Plan ... Constitutional AI ... Trust Region Policy Optimization (TRPO) ... Policy Gradient (PG) ... Proximal Policy Optimization (PPO)
- Strategy & Tactics ... Project Management ... Best Practices ... Checklists ... Project Check-in ... Evaluation
- Analytics ... Visualization ... Graphical Tools ... Diagrams & Business Analysis ... Requirements ... Loop ... Bayes ... Network Pattern
- Perspective ... Context ... In-Context Learning (ICL) ... Transfer Learning ... Out-of-Distribution (OOD) Generalization
- Causation vs. Correlation ... Autocorrelation ...Convolution vs. Cross-Correlation (Autocorrelation)
- Large Language Model (LLM) ... Multimodal ... Foundation Models (FM) ... Generative Pre-trained ... Transformer ... Attention ... GAN ... BERT
- RETRO | DeepMind ... see what the AI has learned by examining the database rather than by studying the Neural Network
- Creatives ... History of Artificial Intelligence (AI) ... Neural Network History ... Rewriting Past, Shape our Future ... Archaeology ... Paleontology
- Development ... Notebooks ... AI Pair Programming ... Codeless ... Hugging Face ... AIOps/MLOps ... AIaaS/MLaaS
- Python Libraries for Interpretable Machine Learning | Rebecca Vickery - Towards Data Science
- Tools:
- LIME (Local Interpretable Model-agnostic Explanations) explains the prediction of any classifier
- ELI5 debug machine learning classifiers and explain their predictions & inspect black-box models
- SHAP debug machine learning classifiers and explain their predictions & inspect black-box models
- yellowbrick the visualiser objects, the core interface, are scikit-learn estimators
- MLxtend the visualiser objects, the core interface, scikit-learn estimators
- Lucid Notebooks | GitHub ... a collection of infrastructure and tools for research in neural network interpretability.
- Singularity ... Sentience ... AGI ... Curious Reasoning ... Emergence ... Moonshots ... Explainable AI ... Automated Learning
- Explaining decisions made with AI | Information Commisioner's Office (ICO) and The Alan Turing Institute
- Explanations based on the Missing: Towards Contrastive Explanations with Pertinent Negatives - IBM
- Why a right to explanation of automated decision-making does not exist in the General Data Protection Regulation | Wachter. S, Mittelstadt, B., Florida, L - University of Oxford, 28 Dec 2016
- This is What Happens When Deep Learning Neural Networks Hallucinate | Kimberley Mok
- H2O Machine Learning Interpretability with H2O Driverless AI
- A New Approach to Understanding How Machines Think | John Pavus
- DrWhy | GitHub collection of tools for Explainable AI (XAI)
- Mixed Formal Learning - A Path to Transparent Machine Learning | Sandra Carrico
- Take advantage of open source trusted AI packages in IBM Cloud Pak for Data | Deborah Schalm - DevOps.com
- Counterfactual Explanations with Theory-of-Mind for Enhancing Human Trust in Image Recognition Models | Arjun R. Akula, Keze Wang, Changsong Liu, Sari Saba-Sadiya, Hongjing Lu, Sinisa Todorovic, Joyce Chai, Song-Chun Zhu
- AI will soon become impossible for humans to comprehend – the story of neural networks tells us why | David Beer - The Conversation
- AI Foundational Research - Exp lainability | NIST ...Four Principles of Explainable Artificial Intelligence | P. J. Phillips, C. Hahn, P. Fontana, D. Broniatowski, and M. Przybocki - NIST
- Explanation: Systems deliver accompanying evidence or reason(s) for all outputs.
- Meaningful: Systems provide explanations that are understandable to individual users.
- Explanation Accuracy: The explanation correctly reflects the system’s process for generating the output.
- Knowledge Limits: The system only operates under conditions for which it was designed or when the system reaches a sufficient confidence in its output.
- A collection of recommendable papers and articles on Explainable AI (XAI) | Murat Durmus - LinkedIn
Contents
Explainable Artificial Intelligence (XAI)
AI system produces results with an account of the path the system took to derive the solution/prediction - transparency of interpretation, rationale and justification. 'If you have a good causal model of the world you are dealing with, you can generalize even in unfamiliar situations. That’s crucial. We humans are able to project ourselves into situations that are very different from our day-to-day experience. Machines are not, because they don’t have these causal models. We can hand-craft them but that’s not enough. We need machines that can discover causal models. To some extend it’s never going to be perfect. We don’t have a perfect causal model of the reality, that’s why we make a lot of mistakes. But we are much better off at doing this than other animals.' Yoshua Benjio
Progress made with XAI:
- Explainable AI Techniques: There are now off-the-shelf explainable AI techniques that developers can use to incorporate explainable AI techniques into their workflows as part of their modeling operations. These techniques help to disclose the program's strengths and weaknesses, the specific criteria the program uses to arrive at a decision, and why a program makes a particular decision, as opposed to alternatives.
- Model Explainability: is essential for high-stakes domains such as healthcare, finance, the legal system, and other critical industrial sectors. Explainable AI (XAI) is a subfield of AI that aims to develop AI systems that can provide clear and understandable explanations of their decision-making processes to humans. The goal of XAI is to make AI more transparent, trustworthy, responsible, and ethical
- Concept-Based Explanations: There has been progress in using concept-based explanations to explain deep neural networks. TCAV (Testing with Concept Activation Vectors) is a technique developed by Google AI that uses concept-based explanations to explain deep neural networks. This technique helps to make AI more transparent, trustworthy, responsible, and ethical.
- Interpretable and Inclusive AI: There has been progress in building interpretable and inclusive AI systems from the ground up with tools designed to help detect and resolve bias, drift, and other gaps in data and models. AI Explanations in AutoML Tables, Vertex AI Predictions, and Notebooks provide data scientists with the insight needed to improve datasets or model architecture and debug model performance.
Explainable Computer Vision with Grad-CAM
- FairyOnIce's Grad-CAM code | GitHub
- Grad-CAM implementation in Keras | Jacob Gildenblat - jacobgil/keras-grad-cam
- Grad-CAM Demo | modified by Siraj Raval
We propose a technique for producing "visual explanations" for decisions from a large class of CNN-based models, making them more transparent. Our approach - Gradient-weighted Class Activation Mapping (Grad-CAM), uses the gradients of any target concept, flowing into the final convolutional layer to produce a coarse localization map highlighting important regions in the image for predicting the concept. Grad-CAM is applicable to a wide variety of CNN model-families: (1) CNNs with fully-connected layers, (2) CNNs used for structured outputs, (3) CNNs used in tasks with multimodal inputs or reinforcement learning, without any architectural changes or re-training. We combine Grad-CAM with fine-grained visualizations to create a high-resolution class-discriminative visualization and apply it to off-the-shelf image classification, captioning, and visual question answering (VQA) models, including ResNet-based architectures. In the context of image classification models, our visualizations (a) lend insights into their failure modes, (b) are robust to adversarial images, (c) outperform previous methods on localization, (d) are more faithful to the underlying model and (e) help achieve generalization by identifying dataset bias. For captioning and VQA, we show that even non-attention based models can localize inputs. We devise a way to identify important neurons through Grad-CAM and combine it with neuron names to provide textual explanations for model decisions. Finally, we design and conduct human studies to measure if Grad-CAM helps users establish appropriate trust in predictions from models and show that Grad-CAM helps untrained users successfully discern a 'stronger' nodel from a 'weaker' one even when both make identical predictions. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization | R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra
Building powerful Computer Vision-based apps without deep expertise has become possible for more people due to easily accessible tools like Python, Colab, Keras, PyTorch, and Tensorflow. But why does a computer classify an image the way that it does? This is a question that is critical when it comes to AI applied to diagnostics, driving, or any other form of critical decision making. In this episode, I'd like to raise awareness around one technique in particular that I found called "Grad-Cam" or Gradient Class Activation Mappings. It allows you to generate a heatmap that helps detail what your model thinks the most relevant features in an image are that cause it to make its predictions. I'll be explaining the math behind it and demoing a code sample by fairyonice to help you understand it. I hope that after this video, you'll be able to implement it in your own project. Enjoy! | Siraj Raval



Interpretable
Youtube search... ...Google search
Please Stop Doing "Explainable" ML: There has been an increasing trend in healthcare and criminal justice to leverage machine learning (ML) for high-stakes prediction applications that deeply impact human lives. Many of the ML models are black boxes that do not explain their predictions in a way that humans can understand. The lack of transparency and accountability of predictive models can have (and has already had) severe consequences; there have been cases of people incorrectly denied parole, poor bail decisions leading to the release of dangerous criminals, ML-based pollution models stating that highly polluted air was safe to breathe, and generally poor use of limited valuable resources in criminal justice, medicine, energy reliability, finance, and in other domains. Rather than trying to create models that are inherently interpretable, there has been a recent explosion of work on “Explainable ML,” where a second (posthoc) model is created to explain the first black box model. This is problematic. Explanations are often not reliable, and can be misleading, as we discuss below. If we instead use models that are inherently interpretable, they provide their own explanations, which are faithful to what the model actually computes. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead | Cynthia Rudin - Duke University
Accuracy & Interpretability Trade-Off
Youtube search... ...Google search
- Model Prediction Accuracy Versus Interpretation in Machine Learning | Jason Brownlee - Machine Learning Mastery
- The balance: Accuracy vs. Interpretability | Sharayu Rane - Towards Data Science
|
Weirder Than You Thought
- Tracing the thoughts of a large language model | Anthropic
- On the Biology of a Large Language Model | Transformer Circuits Thread
- Anthropic has developed an AI 'brain scanner' to understand how LLMs work and it turns out the reason why chatbots are terrible at simple math and hallucinate is weirder than you thought | Jeremy Laird - PC GAMER
With two new papers, Anthropic's researchers have taken significant steps towards understanding the circuits that underlie an AI model’s thoughts. In one example from the paper, we find evidence that Claude will plan what it will say many words ahead, and write to get to that destination. We show this in the realm of poetry, where it thinks of possible rhyming words in advance and writes each line to get there. This is powerful evidence that, even though models are trained to output one word at a time, they may think on much longer horizons to do so.
Trust
YouTube search... ...Google search
- Cybersecurity Frameworks, Architectures & Roadmaps
- Fairlearn ...a toolkit to assess and improve the fairness of machine learning models. Use common fairness metrics and an interactive dashboard to assess which groups of people may be negatively impacted.
- In AI We Trust Incrementally: a Multi-layer Model of Trust to Analyze Human-Artificial Intelligence Interactions | A. Ferrario, M. Loi and E. Viganò - DOI.org
- Trusted AI | Capgemini
- BAE Systems delivers trusted computing MindfuL software to help humans believe artificial intelligence (AI) - Military & Aerospace Electronics
- How to make AI trustworthy | University of Southern California - ScienceDaily
- Building trust in AI is key to autonomous drones, flying cars | David Thorton - Federal News Network
- Governments should close the AI trust gap with businesses | Consultancy.asia
- Trust in Robots: Challenges and Opportunities | Bing Cai Kok and Harold Soh - SpringerLink
- We’re not ready for AI, says the winner of a new $1m AI prize | Will Douglas Heaven - MIT Technology Review ...Regina Barzilay, the first winner of the Squirrel AI Award, on why the pandemic should be a wake-up call.
Measurement and Transparency are key to trusted AI
|
|
|
|
|
|
|
|
Domains
Government
AI AND TRUSTWORTHINESS -- Increasing trust in AI technologies is a key element in accelerating their adoption for economic growth and future innovations that can benefit society. Today, the ability to understand and analyze the decisions of AI systems and measure their trustworthiness is limited. Among the characteristics that relate to trustworthy AI technologies are accuracy, reliability, resiliency, objectivity, security, explainability, safety, and accountability. Ideally, these aspects of AI should be considered early in the design process and tested during the development and use of AI technologies. AI standards and related tools, along with AI risk management strategies, can help to address this limitation and spur innovation. ... It is important for those participating in AI standards development to be aware of, and to act consistently with, U.S. government policies and principles, including those that address societal and ethical issues, governance, and privacy. While there is broad agreement that these issues must factor into AI standards, it is not clear how that should be done and whether there is yet sufficient scientific and technical basis to develop those standards provisions. Plan Outlines Priorities for Federal Agency Engagement in AI Standards Development;
Healthcare
Interpretable Machine Learning for Healthcare