Difference between revisions of "Data Science"
m |
m |
||
| (62 intermediate revisions by the same user not shown) | |||
| Line 2: | Line 2: | ||
|title=PRIMO.ai | |title=PRIMO.ai | ||
|titlemode=append | |titlemode=append | ||
| − | |keywords=artificial, intelligence, machine, learning, models | + | |keywords=ChatGPT, artificial, intelligence, machine, learning, GPT-4, GPT-5, NLP, NLG, NLC, NLU, models, data, singularity, moonshot, Sentience, AGI, Emergence, Moonshot, Explainable, TensorFlow, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Hugging Face, OpenAI, Tensorflow, OpenAI, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Meta, LLM, metaverse, assistants, agents, digital twin, IoT, Transhumanism, Immersive Reality, Generative AI, Conversational AI, Perplexity, Bing, You, Bard, Ernie, prompt Engineering LangChain, Video/Image, Vision, End-to-End Speech, Synthesize Speech, Speech Recognition, Stanford, MIT |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools |
| − | |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | + | |
| + | <!-- Google tag (gtag.js) --> | ||
| + | <script async src="https://www.googletagmanager.com/gtag/js?id=G-4GCWLBVJ7T"></script> | ||
| + | <script> | ||
| + | window.dataLayer = window.dataLayer || []; | ||
| + | function gtag(){dataLayer.push(arguments);} | ||
| + | gtag('js', new Date()); | ||
| + | |||
| + | gtag('config', 'G-4GCWLBVJ7T'); | ||
| + | </script> | ||
}} | }} | ||
| − | [ | + | [https://www.youtube.com/results?search_query=ai+Data+Science YouTube] |
| − | [ | + | [https://www.quora.com/search?q=ai%20Data%20Science ... Quora] |
| + | [https://www.google.com/search?q=ai+Data+Science ...Google search] | ||
| + | [https://news.google.com/search?q=ai+Data+Science ...Google News] | ||
| + | [https://www.bing.com/news/search?q=ai+Data+Science&qft=interval%3d%228%22 ...Bing News] | ||
| + | |||
| + | * [[Data Science]] ... [[Data Governance|Governance]] ... [[Data Preprocessing|Preprocessing]] ... [[Feature Exploration/Learning|Exploration]] ... [[Data Interoperability|Interoperability]] ... [[Algorithm Administration#Master Data Management (MDM)|Master Data Management (MDM)]] ... [[Bias and Variances]] ... [[Benchmarks]] ... [[Datasets]] | ||
| + | * [[Data Quality]] ...[[AI Verification and Validation|validity]], [[Evaluation - Measures#Accuracy|accuracy]], [[Data Quality#Data Cleaning|cleaning]], [[Data Quality#Data Completeness|completeness]], [[Data Quality#Data Consistency|consistency]], [[Data Quality#Data Encoding|encoding]], [[Data Quality#Zero Padding|padding]], [[Data Quality#Data Augmentation, Data Labeling, and Auto-Tagging|augmentation, labeling, auto-tagging]], [[Data Quality#Batch Norm(alization) & Standardization| normalization, standardization]], and [[Data Quality#Imbalanced Data|imbalanced data]] | ||
| + | * [[Strategy & Tactics]] ... [[Project Management]] ... [[Best Practices]] ... [[Checklists]] ... [[Project Check-in]] ... [[Evaluation]] ... [[Evaluation - Measures|Measures]] | ||
| + | * [[What is Artificial Intelligence (AI)? | Artificial Intelligence (AI)]] ... [[Machine Learning (ML)]] ... [[Deep Learning]] ... [[Neural Network]] ... [[Reinforcement Learning (RL)|Reinforcement]] ... [[Learning Techniques]] | ||
| + | * [[Risk, Compliance and Regulation]] ... [[Ethics]] ... [[Privacy]] ... [[Law]] ... [[AI Governance]] ... [[AI Verification and Validation]] | ||
| + | * [[Excel]] ... [[LangChain#Documents|Documents]] ... [[Database|Database; Vector & Relational]] ... [[Graph]] ... [[LlamaIndex]] | ||
| + | * [[Backpropagation]] ... [[Feed Forward Neural Network (FF or FFNN)|FFNN]] ... [[Forward-Forward]] ... [[Activation Functions]] ...[[Softmax]] ... [[Loss]] ... [[Boosting]] ... [[Gradient Descent Optimization & Challenges|Gradient Descent]] ... [[Algorithm Administration#Hyperparameter|Hyperparameter]] ... [[Manifold Hypothesis]] ... [[Principal Component Analysis (PCA)|PCA]] | ||
| + | * [[Analytics]] ... [[Visualization]] ... [[Graphical Tools for Modeling AI Components|Graphical Tools]] ... [[Diagrams for Business Analysis|Diagrams]] & [[Generative AI for Business Analysis|Business Analysis]] ... [[Requirements Management|Requirements]] ... [[Loop]] ... [[Bayes]] ... [[Network Pattern]] | ||
| + | * [[Development]] ... [[Notebooks]] ... [[Development#AI Pair Programming Tools|AI Pair Programming]] ... [[Codeless Options, Code Generators, Drag n' Drop|Codeless]] ... [[Hugging Face]] ... [[Algorithm Administration#AIOps/MLOps|AIOps/MLOps]] ... [[Platforms: AI/Machine Learning as a Service (AIaaS/MLaaS)|AIaaS/MLaaS]] | ||
| + | * [[AI Solver]] ... [[Algorithms]] ... [[Algorithm Administration|Administration]] ... [[Model Search]] ... [[Discriminative vs. Generative]] ... [[Train, Validate, and Test]] | ||
| + | * [https://en.wikipedia.org/wiki/Data_science Data Science | Wikipedia] | ||
| + | * [https://towardsdatascience.com/introduction-to-statistics-e9d72d818745 Data science concepts you need to know! Part 1 | Michael Barber - Towards Data Science] | ||
| + | * [https://www.datasciencecentral.com/profiles/blogs/data-fallacies-to-avoid-an-illustrated-collection-of-mistakes Data Fallacies to Avoid - An Illustrated Collection of Mistakes People Often Make When Analyzing Data - Tom Bransby] | ||
| + | |||
| + | |||
| + | <img src="ihttps://miro.medium.com/v2/resize:fit:828/format:webp/1*r1JLOQJ-MvuwxlLYfX0pvg.png" width="600"> | ||
| + | |||
| + | |||
| + | = Data Strategy = | ||
| + | |||
| + | <youtube>yqmiViOXlk8</youtube> | ||
| + | <youtube>WrJWXxcxguc</youtube> | ||
| + | |||
| + | = <span id="People, Process, Product... and Data"></span>People, Process, Product... and Data = | ||
| + | [https://www.youtube.com/results?search_query=ai+People+Proces+Product+Data YouTube search...] | ||
| + | [https://www.google.com/search?q=ai+People+Proces+Product+Data ...Google search] | ||
| + | |||
| + | * [https://marcuslemonis.com/business/3ps-of-business Marcus Lemonis Business Learning Center] | ||
| + | |||
| + | Marcus Lemonis businessman, television personality, and philanthropist, popularized the concept of the "Three P's of Business Success": People, Process, and Product. According to Lemonis, these three elements are the cornerstone of everything inside a business, and managing them effectively is critical to growing and succeeding in business. By focusing on these three key areas, businesses can improve their chances of success and growth. Marcus Lemonis uses these principles in his reality television show "The Profit," where he invests his own cash in struggling businesses and helps them turn around and succeed. Here's a breakdown of each of the Three P's: | ||
| + | |||
| + | * <b>People</b>: the employees, customers, and other stakeholders involved in the business. Managing people effectively involves hiring the right people, training them well, and creating a positive work environment that fosters productivity and innovation. | ||
| + | * <b>Process</b>: the systems and procedures that a business uses to create and deliver its products or services. Managing processes effectively involves streamlining operations, eliminating waste, and continuously improving efficiency and quality. | ||
| + | * <b>Product</b>: the goods or services that a business offers to its customers. Managing products effectively involves developing high-quality products that meet customer needs and preferences, and continuously innovating to stay ahead of the competition. | ||
| + | |||
| + | |||
| + | <hr><center><b> | ||
| + | |||
| + | ... and Data | ||
| + | |||
| + | </b></center><hr> | ||
| + | |||
| + | |||
| + | As businesses increasingly rely on data and AI technologies to drive growth and innovation, Marcus Lemonis' strategy can be enhanced by incorporating a stronger focus on data-driven decision-making and AI integration. Here's how his Three P's framework can be adapted to this new landscape: | ||
| + | |||
| + | * <b>People</b>: In addition to understanding and managing employees and customers, businesses should also focus on leveraging <i>data</i> to gain insights into customer behavior, preferences, and trends. This can help in personalizing marketing efforts, improving customer experiences, and driving customer loyalty | ||
| + | * <b>Process</b>: <i>Data</i> can play a crucial role in optimizing business processes. By collecting and analyzing <i>data</i>, businesses can identify bottlenecks, inefficiencies, and areas for improvement. AI technologies can be used to automate repetitive tasks, streamline operations, and enhance overall efficiency | ||
| + | * <b>Product</b>: <i>Data</i> and AI can be used to inform product development and innovation. By analyzing market trends, customer feedback, and competitor insights, businesses can identify new product opportunities, optimize existing offerings, and stay ahead of the competition | ||
| + | |||
| + | <youtube>u2q-QF8TDGA</youtube> | ||
| + | |||
| + | = What is Data Science = | ||
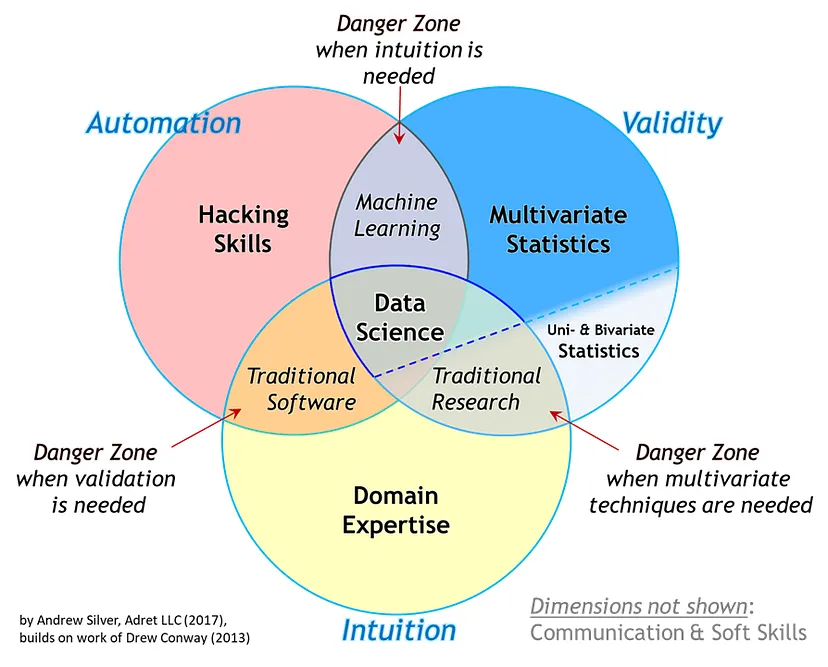
| + | * [https://towardsdatascience.com/the-essential-data-science-venn-diagram-35800c3bef40 The Essential Data Science Venn Diagram | Andrew Silver - Medium] | ||
| + | |||
| + | <img src="https://miro.medium.com/v2/resize:fit:828/format:webp/1*WvOnZ27TdPUbJfa9q21QJw.png" width="500"> | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
{|<!-- T --> | {|<!-- T --> | ||
| Line 66: | Line 108: | ||
<youtube>r-uOLxNrNk8</youtube> | <youtube>r-uOLxNrNk8</youtube> | ||
<b>Data Analysis with Python - Full Course for Beginners (Numpy, Pandas, Matplotlib, Seaborn) | <b>Data Analysis with Python - Full Course for Beginners (Numpy, Pandas, Matplotlib, Seaborn) | ||
| − | </b><br>Learn Data Analysis with Python in this comprehensive tutorial for beginners, with exercises included! Data Analysis has been around for a long time, but up until a few years ago, it was practiced using closed, expensive and limited tools like Excel or Tableau. Python, SQL and other open libraries have changed Data Analysis forever. In this tutorial you'll learn the whole process of Data Analysis: reading data from multiple sources (CSVs, SQL, Excel, etc), processing them using NumPy and Pandas, visualize them using Matplotlib and Seaborn and clean and process it to create reports. Additionally, we've included a thorough Jupyter Notebook tutorial, and a quick Python reference to refresh your programming skills. Check out all Data Science courses from RMOTR: https://rmotr.com | + | </b><br>Learn Data Analysis with Python in this comprehensive tutorial for beginners, with exercises included! Data Analysis has been around for a long time, but up until a few years ago, it was practiced using closed, expensive and limited tools like Excel or Tableau. Python, SQL and other open libraries have changed Data Analysis forever. In this tutorial you'll learn the whole process of Data Analysis: reading data from multiple sources (CSVs, SQL, Excel, etc), processing them using NumPy and Pandas, visualize them using Matplotlib and Seaborn and [[Data Quality#Data Cleaning|clean]] and process it to create reports. Additionally, we've included a thorough Jupyter Notebook tutorial, and a quick Python reference to refresh your programming skills. Check out all Data Science courses from RMOTR: https://rmotr.com |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 75: | Line 117: | ||
<youtube>Wj5ole72Q9g</youtube> | <youtube>Wj5ole72Q9g</youtube> | ||
<b>Data Science in 60 Minutes | What Is Data Science | Neural Networks | Great Learning | <b>Data Science in 60 Minutes | What Is Data Science | Neural Networks | Great Learning | ||
| − | </b><br>Data science is the most popular domain. All the companies are using the Data Science technique as it helps them to use their data and get insights from them. It has also become the most demanding job of the 21st century. Every organization is looking for candidates with knowledge of data science. Understanding all of this, we have come up with this 'Data Science in 60 Minutes' Tutorial. Data Science is the area of study which involves extracting insights from vast amounts of data by the use of various scientific methods, algorithms, and processes. It helps you to discover hidden patterns from the raw data. The term Data Science has emerged because of the evolution of mathematical statistics, data analysis, and big data. It is an interdisciplinary field that allows you to extract knowledge from structured or unstructured data. Data science enables you to translate a business problem into a research project and then translate it back into a practical solution. It also uses the most powerful hardware, programming systems, and most efficient algorithms to solve the data-related problems. It is the future of artificial intelligence. In this tutorial, we have covered all the important topics such as What is Data Science, What are its features, When to use this technique, and much more. Visit Great Learning Academy, to get access to 80+ free courses with 1000+ hours of content on Data Science, Data Analytics, Artificial Intelligence, Big Data, Cloud, Management, Cybersecurity and many more. These are supplemented with free projects, assignments, datasets, quizzes. You can earn a certificate of completion at the end of the course for free. https://glacad.me/3duVMLE Get the free Great Learning App for a seamless experience, enrol for free courses and watch them offline by downloading them. | + | </b><br>Data science is the most popular domain. All the companies are using the Data Science technique as it helps them to use their data and get insights from them. It has also become the most demanding job of the 21st century. Every organization is looking for candidates with knowledge of data science. Understanding all of this, we have come up with this 'Data Science in 60 Minutes' Tutorial. Data Science is the area of study which involves extracting insights from vast amounts of data by the use of various scientific methods, algorithms, and processes. It helps you to discover hidden patterns from the raw data. The term Data Science has emerged because of the evolution of mathematical statistics, data analysis, and big data. It is an interdisciplinary field that allows you to extract knowledge from structured or unstructured data. Data science enables you to translate a business problem into a research project and then translate it back into a practical solution. It also uses the most powerful hardware, programming systems, and most efficient algorithms to solve the data-related problems. It is the future of artificial intelligence. In this tutorial, we have covered all the important topics such as What is Data Science, What are its features, When to use this technique, and much more. Visit Great Learning Academy, to get access to 80+ free courses with 1000+ hours of content on Data Science, Data Analytics, Artificial Intelligence, Big Data, Cloud, Management, Cybersecurity and many more. These are supplemented with free projects, assignments, datasets, quizzes. You can earn a certificate of completion at the end of the course for free. https://glacad.me/3duVMLE Get the free Great Learning App for a seamless experience, enrol for free courses and watch them offline by downloading them. https://glacad.me/3cSKlNl |
|} | |} | ||
|<!-- M --> | |<!-- M --> | ||
| Line 83: | Line 125: | ||
<youtube>D0B1JZMCMLo</youtube> | <youtube>D0B1JZMCMLo</youtube> | ||
<b>Data Science in 30 Minutes: Predicting Content Demand with Machine Learning | <b>Data Science in 30 Minutes: Predicting Content Demand with Machine Learning | ||
| − | </b><br>Netflix is well-known for its data-driven recommendations that seek to customize the user experience for every subscriber. But data science at Netflix extends far beyond that - from optimizing streaming and content caching to informing decisions about the TV shows and films available on the service. The talk covered work done by Becky and the Content Data Science team at Netflix, which seeks to evaluate where Netflix should spend their next content dollar using machine learning and predictive models. The Data Incubator is a data science education company based in NYC, DC, and SF with both corporate training as well as recruiting services. For data science corporate training, we offer customized, in-house corporate training solutions in data and analytics. For data science hiring, we run a free 8 week fellowship training PhDs to become data scientists. The fellowship selects 2% of its 2000+ quarterly applicants and is free for Fellows. Hiring companies (including EBay, Capital One, Pfizer) pay a recruiting fee only if they successfully hire. You can read about us on Harvard Business Review, VentureBeat, or The Next Web, or read about our alumni at LinkedIn, Palantir or the NYTimes. About the speakers: | + | </b><br>Netflix is well-known for its data-driven recommendations that seek to customize the user experience for every subscriber. But data science at Netflix extends far beyond that - from optimizing streaming and content caching to informing decisions about the TV shows and films available on the service. The talk covered work done by Becky and the Content Data Science team at Netflix, which seeks to evaluate where Netflix should spend their next content dollar using machine learning and [[Predictive Analytics|predictive models]]. The Data Incubator is a data science education company based in NYC, DC, and SF with both corporate training as well as recruiting services. For data science corporate training, we offer customized, in-house corporate training solutions in data and analytics. For data science hiring, we run a free 8 week fellowship training PhDs to become data scientists. The fellowship selects 2% of its 2000+ quarterly applicants and is free for Fellows. Hiring companies (including EBay, Capital One, Pfizer) pay a recruiting fee only if they successfully hire. You can read about us on Harvard Business Review, VentureBeat, or The Next Web, or read about our alumni at LinkedIn, [[Palantir]] or the NYTimes. About the speakers: Dr. Becky Tucker is a Senior Data Scientist at Netflix, a streaming media and entertainment company based in Los Gatos, CA. She holds a PhD in Physics from Caltech. At Netflix, Becky works on models that predict the demand for TV shows and movies. Michael Li founded The Data Incubator, a New York-based training program that turns talented PhDs from academia into workplace-ready data scientists and quants. The program is free to Fellows, employers engage with the Incubator as hiring partners. |
| − | Dr. Becky Tucker is a Senior Data Scientist at Netflix, a streaming media and entertainment company based in Los Gatos, CA. She holds a PhD in Physics from Caltech. At Netflix, Becky works on models that predict the demand for TV shows and movies. | + | |} |
| − | Michael Li founded The Data Incubator, a New York-based training program that turns talented PhDs from academia into workplace-ready data scientists and quants. The program is free to Fellows, employers engage with the Incubator as hiring partners. | + | |}<!-- B --> |
| + | |||
| + | = <span id="Analyzing Data with [[ChatGPT]]"></span>Data Analysis using ChatGPT = | ||
| + | [https://www.youtube.com/results?search_query=Data+Analysis+AI+artificial+intelligence YouTube search...] | ||
| + | [https://www.google.com/search?q=Data+Analysis+AI+artificial+intelligence ...Google search] | ||
| + | |||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>Dw0irOIJYnA</youtube> | ||
| + | <b>Analysing Data with ChatGPT (Data Analysis and ML ) | ||
| + | </b><br>In this tutorial we will see how to analyse a given dataset using ChatGPT. | ||
| + | |||
| + | * Code:[https://github.com/jcharis https://github.com/jcharis] | ||
| + | * Blog:[https://blog.jcharistech.com https://blog.jcharistech.com] | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>C75TROiiEa0</youtube> | ||
| + | <b>ChatGPT for Data Analysts | Best Use Cases + Analyzing a Dataset | ||
| + | </b><br>ChatGPT has a lot of use cases for Data Analysts! In this video we walk through my favorite things to use ChatGPT and we also take a look at how it can help us analyze data. | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>j35rgDPp1mM</youtube> | ||
| + | <b>Analysing Data with [[ChatGPT]] (Data Analysis and ML ) | ||
| + | </b><br>In this video, we'll see some applications [[ChatGPT]] has in data science and data analysis. We'll explore how to solve coding questions, create SQL queries, translate Python code to R, web scraping, text classification and how to make visualization with [[ChatGPT]]. | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>j35rgDPp1mM</youtube> | ||
| + | <b>Automate Data Science Tasks with [[ChatGPT]]: SQL Queries, Python, R, Web Scraping, and more! | ||
| + | </b><br>In this video, we'll see some applications [[ChatGPT]] has in data science and data analysis. We'll explore how to solve coding questions, create SQL queries, translate Python code to R, web scraping, text classification and how to make visualization with [[ChatGPT]]. | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| + | |||
| + | = <span id="Structured, Semi-Structured, and Unstructured"></span>Structured, Semi-Structured, and Unstructured = | ||
| + | [https://www.youtube.com/results?search_query=Structured+Semi-Structured+Unstructured+Data+artificial+intelligence YouTube search...] | ||
| + | [https://www.google.com/search?q=Structured+Semi-Structured+Unstructured+Data+artificial+intelligence ...Google search] | ||
| + | |||
| + | * [https://www.forbes.com/sites/bernardmarr/2019/10/18/whats-the-difference-between-structured-semi-structured-and-unstructured-data/#e46c89b2b4d3 What’s The Difference Between Structured, Semi-Structured And Unstructured Data? | Bernard Marr - Forbes] | ||
| + | * [https://www.geeksforgeeks.org/difference-between-structured-semi-structured-and-unstructured-data/ Difference between Structured, Semi-structured and Unstructured data | Ashish Vishwakarma - GeeksForGeeks] | ||
| + | |||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>dK4aGzeBPkk</youtube> | ||
| + | <b>What is Big Data | Big Data Types | Types of Data | Structured Data | Unstructured Data | Semi-Structured Data | ||
| + | </b><br>What is Big Data? https://www.knowledgehut.com/ | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>M0ukNp5oJUo</youtube> | ||
| + | <b>Analyzing semi-structured data… Like a boss | ||
| + | </b><br>With the increasing adoption of Big Data systems as the de facto standard for data storage, and the proliferation of web and mobile applications, APIs and IoT devices (all of which adopt non-tabular data models), it becomes immensely important for Tableau to enable users to connect to, and visualize data, that are in formats like JSON. In other words, semi-structured data. Join us as we breakdown what semi-structured data are, where and how they're being used, what Tableau does today to connect and use them, and what the handling of semi-structured data looks like in the future for Tableau. | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>-xxCY6WHfRY</youtube> | ||
| + | <b>Types of Data Under Big data | ||
| + | </b><br>Lecture By: Mr. Arnab Chakraborty, Tutorials Point India Private Limited | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>m7CRqUaWGgw</youtube> | ||
| + | <b>Chandra Bhagavatula: Adding Structure to Unstructured and Semi-structured data | ||
| + | </b><br>Chandra Sekhar Bhagavatula Abstract: In this talk, I will describe two systems designed to extract structured knowledge from unstructured and semi-structured data. First, I'll present an entity linking system for Web tables. Next, I'll talk about a key phrase extraction system that extracts a set of key concepts from a research article. Towards the end of the talk, I will briefly introduce an underlying common problem which connects these two seemingly distinct tasks. I will also present an approach, based on topic modeling, to solve this common underlying problem. | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| + | |||
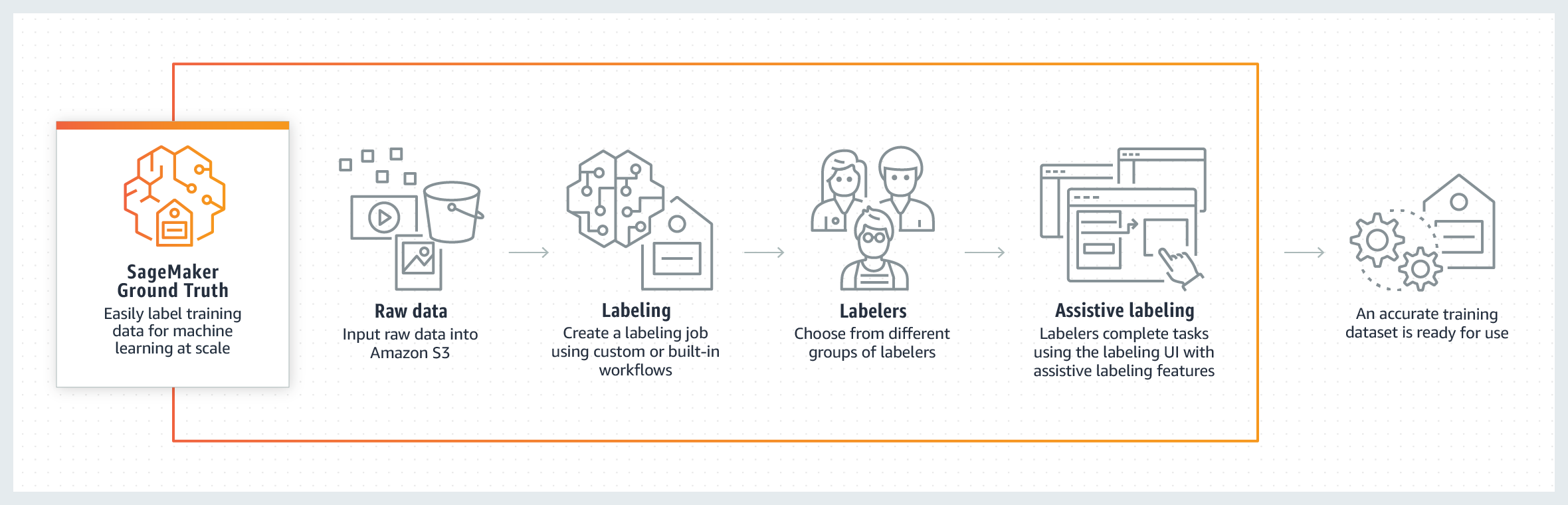
| + | = <span id="Ground Truth"></span>Ground Truth = | ||
| + | [https://www.youtube.com/results?search_query=ground+truth+artificial+intelligence+ai YouTube search...] | ||
| + | [https://www.google.com/search?q=ground+truth+artificial+intelligence+ai ...Google search] | ||
| + | |||
| + | * [https://medium.com/hivedata/ground-truth-gold-intelligent-data-labeling-and-annotation-632f63d9662f Ground Truth Gold — Intelligent data labeling and annotation | The Hive - Medium] | ||
| + | * [https://aws.amazon.com/sagemaker/groundtruth/ Ground Truth | SageMaker -] [[Amazon]] | ||
| + | |||
| + | Ground truth is a term used in various fields to refer to information provided by direct observation (i.e. empirical evidence) as opposed to information provided by [https://en.wikipedia.org/wiki/Inference inference]. "Ground truth" may be seen as a conceptual term relative to the knowledge of the truth concerning a specific question. It is the ideal expected result. [https://en.wikipedia.org/wiki/Ground_truth Wikipedia] | ||
| + | |||
| + | You might have heard the term “ground truth” rolling around the ML/AI space, but what does it mean? Newsflash: Ground truth isn’t true. It’s an ideal expected result (according to the people in charge). In other words, it’s a way to boil down the opinions of project owners by creating a set of examples with output labels that those owners found palatable. It might involve hand-labeling example datapoints or putting sensors “on the ground” (in a curated real-world location) to collect desirable answer data for training your system. [https://towardsdatascience.com/in-ai-the-objective-is-subjective-4614795d179b What is “Ground Truth” in AI? (A warning.) | Cassie Kozyrkov - Towards Data Science] | ||
| + | |||
| + | <img src="https://d1.awsstatic.com/architecture-diagrams/ArchitectureDiagrams/groundtruth-how-it-works-new.33182120507a8375154ad142117ee840b2122a2e.png" width="1100"> | ||
| + | |||
| + | |||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>8J7y513oSsE</youtube> | ||
| + | <b>Accurately Automating Dataset Labelling Using [[Amazon]] SageMaker GroundTruth (Level 200) | ||
| + | </b><br>Learn more about AWS Innovate Online Conference at – https://amzn.to/2WEdJhy | ||
| + | Successful machine learning models are built on high-quality training datasets. Labeling raw data to get accurate training dataset involves a lot of time and effort, because sophisticated models can require thousands of labeled examples to learn from, before they produce good results. Typically, the task of labeling is distributed across large number of humans, adding significant overheads and costs. In this session, learn how [[Amazon]] SageMaker Ground Truth can solve data labeling problems, build highly-accurate training datasets, and achieve automated labeling. Speaker: Will Badr, Senior Technical Account Manager, AWS Enterprise Support, ANZ | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>htgVJ5Qh7uA</youtube> | ||
| + | <b>Week 6: Ground Truth | ||
| + | </b><br>Ryan Baker discusses ground truth for week 6 of DALMOOC | ||
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
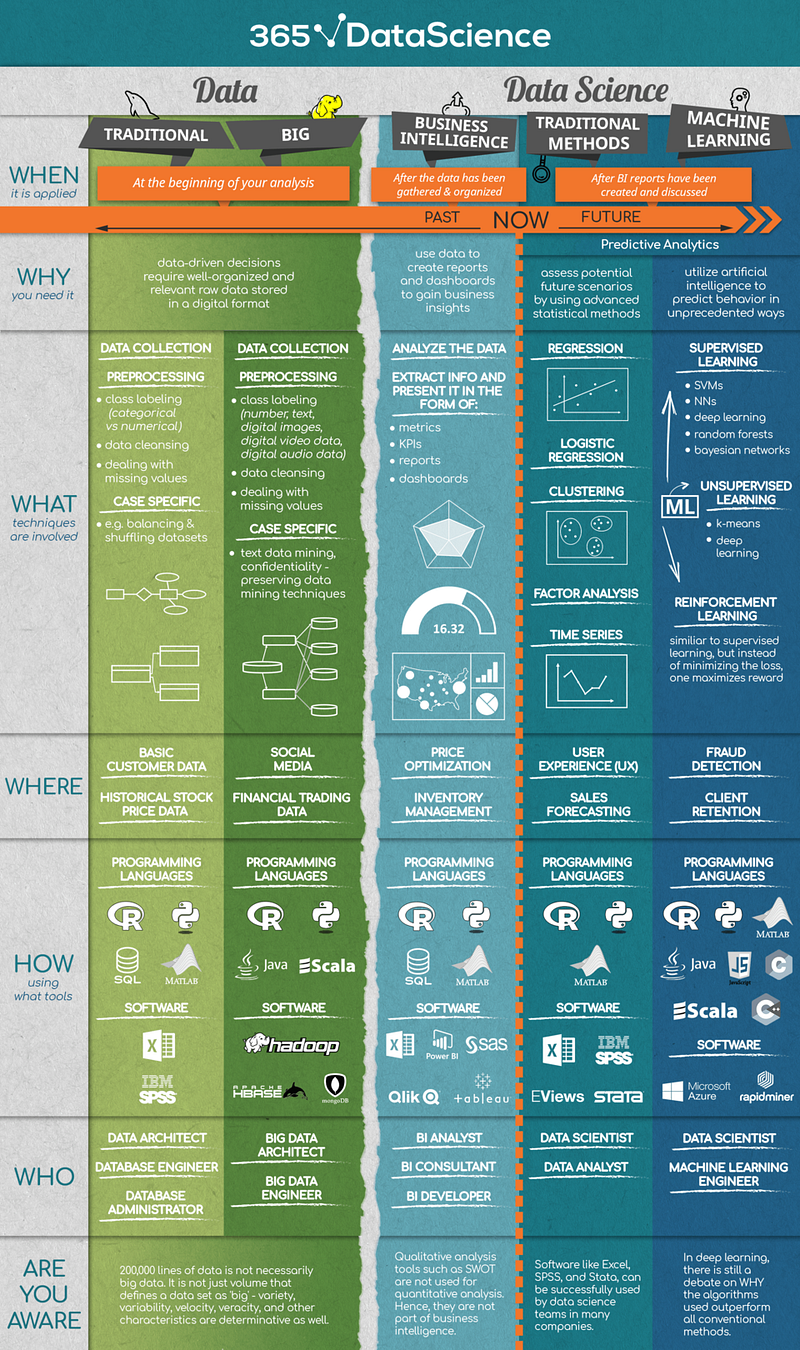
| − | [ | + | [https://towardsdatascience.com/the-what-where-and-how-of-data-science-6dda1af98671 The What, Where and How of Data Science | Iliya Valchanov] |
| − | <img src=" | + | <img src="https://cdn-images-1.medium.com/max/800/1*z5VIYRsdFI-b8WPVyFPeWQ.png" width="1000"> |
Latest revision as of 21:50, 26 April 2024
YouTube ... Quora ...Google search ...Google News ...Bing News
- Data Science ... Governance ... Preprocessing ... Exploration ... Interoperability ... Master Data Management (MDM) ... Bias and Variances ... Benchmarks ... Datasets
- Data Quality ...validity, accuracy, cleaning, completeness, consistency, encoding, padding, augmentation, labeling, auto-tagging, normalization, standardization, and imbalanced data
- Strategy & Tactics ... Project Management ... Best Practices ... Checklists ... Project Check-in ... Evaluation ... Measures
- Artificial Intelligence (AI) ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Risk, Compliance and Regulation ... Ethics ... Privacy ... Law ... AI Governance ... AI Verification and Validation
- Excel ... Documents ... Database; Vector & Relational ... Graph ... LlamaIndex
- Backpropagation ... FFNN ... Forward-Forward ... Activation Functions ...Softmax ... Loss ... Boosting ... Gradient Descent ... Hyperparameter ... Manifold Hypothesis ... PCA
- Analytics ... Visualization ... Graphical Tools ... Diagrams & Business Analysis ... Requirements ... Loop ... Bayes ... Network Pattern
- Development ... Notebooks ... AI Pair Programming ... Codeless ... Hugging Face ... AIOps/MLOps ... AIaaS/MLaaS
- AI Solver ... Algorithms ... Administration ... Model Search ... Discriminative vs. Generative ... Train, Validate, and Test
- Data Science | Wikipedia
- Data science concepts you need to know! Part 1 | Michael Barber - Towards Data Science
- Data Fallacies to Avoid - An Illustrated Collection of Mistakes People Often Make When Analyzing Data - Tom Bransby
Contents
Data Strategy
People, Process, Product... and Data
YouTube search... ...Google search
Marcus Lemonis businessman, television personality, and philanthropist, popularized the concept of the "Three P's of Business Success": People, Process, and Product. According to Lemonis, these three elements are the cornerstone of everything inside a business, and managing them effectively is critical to growing and succeeding in business. By focusing on these three key areas, businesses can improve their chances of success and growth. Marcus Lemonis uses these principles in his reality television show "The Profit," where he invests his own cash in struggling businesses and helps them turn around and succeed. Here's a breakdown of each of the Three P's:
- People: the employees, customers, and other stakeholders involved in the business. Managing people effectively involves hiring the right people, training them well, and creating a positive work environment that fosters productivity and innovation.
- Process: the systems and procedures that a business uses to create and deliver its products or services. Managing processes effectively involves streamlining operations, eliminating waste, and continuously improving efficiency and quality.
- Product: the goods or services that a business offers to its customers. Managing products effectively involves developing high-quality products that meet customer needs and preferences, and continuously innovating to stay ahead of the competition.
... and Data
As businesses increasingly rely on data and AI technologies to drive growth and innovation, Marcus Lemonis' strategy can be enhanced by incorporating a stronger focus on data-driven decision-making and AI integration. Here's how his Three P's framework can be adapted to this new landscape:
- People: In addition to understanding and managing employees and customers, businesses should also focus on leveraging data to gain insights into customer behavior, preferences, and trends. This can help in personalizing marketing efforts, improving customer experiences, and driving customer loyalty
- Process: Data can play a crucial role in optimizing business processes. By collecting and analyzing data, businesses can identify bottlenecks, inefficiencies, and areas for improvement. AI technologies can be used to automate repetitive tasks, streamline operations, and enhance overall efficiency
- Product: Data and AI can be used to inform product development and innovation. By analyzing market trends, customer feedback, and competitor insights, businesses can identify new product opportunities, optimize existing offerings, and stay ahead of the competition
What is Data Science
|
|
|
|
|
|
Data Analysis using ChatGPT
YouTube search... ...Google search
|
|
|
|
Structured, Semi-Structured, and Unstructured
YouTube search... ...Google search
- What’s The Difference Between Structured, Semi-Structured And Unstructured Data? | Bernard Marr - Forbes
- Difference between Structured, Semi-structured and Unstructured data | Ashish Vishwakarma - GeeksForGeeks
|
|
|
|
Ground Truth
YouTube search... ...Google search
- Ground Truth Gold — Intelligent data labeling and annotation | The Hive - Medium
- Ground Truth | SageMaker - Amazon
Ground truth is a term used in various fields to refer to information provided by direct observation (i.e. empirical evidence) as opposed to information provided by inference. "Ground truth" may be seen as a conceptual term relative to the knowledge of the truth concerning a specific question. It is the ideal expected result. Wikipedia
You might have heard the term “ground truth” rolling around the ML/AI space, but what does it mean? Newsflash: Ground truth isn’t true. It’s an ideal expected result (according to the people in charge). In other words, it’s a way to boil down the opinions of project owners by creating a set of examples with output labels that those owners found palatable. It might involve hand-labeling example datapoints or putting sensors “on the ground” (in a curated real-world location) to collect desirable answer data for training your system. What is “Ground Truth” in AI? (A warning.) | Cassie Kozyrkov - Towards Data Science
|
|
The What, Where and How of Data Science | Iliya Valchanov