Difference between revisions of "Algorithm Administration"
m |
m |
||
| Line 23: | Line 23: | ||
*** [[Data Interoperability]] | *** [[Data Interoperability]] | ||
*** [[Excel - Data Analysis]] | *** [[Excel - Data Analysis]] | ||
| − | |||
* [[Graphical Tools for Modeling AI Components]] | * [[Graphical Tools for Modeling AI Components]] | ||
* [[Algorithm Administration#Hyperparameter|Hyperparameter]]s | * [[Algorithm Administration#Hyperparameter|Hyperparameter]]s | ||
| Line 34: | Line 33: | ||
* [[Train, Validate, and Test]] | * [[Train, Validate, and Test]] | ||
* NLP [[Natural Language Processing (NLP)#Workbench / Pipeline | Workbench / Pipeline]] | * NLP [[Natural Language Processing (NLP)#Workbench / Pipeline | Workbench / Pipeline]] | ||
| − | * [[Development]] | + | * [[Development]] ...[[Development#AI Pair Programming Tools|AI Pair Programming Tools]] ... [[Analytics]] ... [[Visualization]] ... [[Diagrams for Business Analysis]] |
* [[Building Your Environment]] | * [[Building Your Environment]] | ||
* [[Service Capabilities]] | * [[Service Capabilities]] | ||
* [[AI Marketplace & Toolkit/Model Interoperability]] | * [[AI Marketplace & Toolkit/Model Interoperability]] | ||
| − | |||
* [[Directed Acyclic Graph (DAG)]] - programming pipelines | * [[Directed Acyclic Graph (DAG)]] - programming pipelines | ||
* [[Containers; Docker, Kubernetes & Microservices]] | * [[Containers; Docker, Kubernetes & Microservices]] | ||
| Line 465: | Line 463: | ||
<youtube>HwZlGQuCTj4</youtube> | <youtube>HwZlGQuCTj4</youtube> | ||
<b>DevOps for AI - [[Microsoft]] | <b>DevOps for AI - [[Microsoft]] | ||
| − | </b><br>DOES18 Las Vegas — Because the AI field is young compared to traditional software development, best practices and solutions around life cycle management for these AI systems have yet to solidify. This talk will discuss how we did this at [[Microsoft]] in different departments (one of them being Bing). DevOps for AI - [[Microsoft]] | + | </b><br>DOES18 Las Vegas — Because the AI field is young compared to traditional software [[development]], best practices and solutions around life cycle management for these AI systems have yet to solidify. This talk will discuss how we did this at [[Microsoft]] in different departments (one of them being Bing). DevOps for AI - [[Microsoft]] |
Gabrielle Davelaar, Data Platform Solution Architect/A.I., [[Microsoft]] Jordan Edwards, Senior Program Manager, [[Microsoft]] Gabrielle Davelaar is a Data Platform Solution Architect specialized in Artificial Intelligence solutions at [[Microsoft]]. She was originally trained as a computational neuroscientist. Currently she helps [[Microsoft]]’s top 15 Fortune 500 customers build trustworthy and scalable platforms able to create the next generation of A.I. applications. While helping customers with their digital A.I. transformation, she started working with engineering to tackle one key issue: A.I. maturity. The demand for this work is high, and Gabrielle is now working on bringing together the right people to create a full offering. Her aspirations are to be a technical leader in the healthcare digital transformation. Empowering people to find new treatments using A.I. while insuring privacy and taking data governance in consideration. Jordan Edwards is a Senior Program Manager on the Azure AI Platform team. He has worked on a number of highly performant, globally distributed systems across Bing, Cortana and [[Microsoft]] Advertising and is currently working on CI/CD experiences for the next generation of Azure Machine Learning. Jordan has been a key driver of dev-ops modernization in AI+R, including but not limited to: moving to Git, moving the organization at large to CI/CD, packaging and build language modernization, movement from monolithic services to microservice platforms and driving for a culture of friction free devOps and flexible engineering culture. His passion is to continue driving [[Microsoft]] towards a culture which enables our engineering talent to do and achieve more. DOES18 Las Vegas DOES 2018 US DevOps Enterprise Summit 2018 https://events.itrevolution.com/us/ | Gabrielle Davelaar, Data Platform Solution Architect/A.I., [[Microsoft]] Jordan Edwards, Senior Program Manager, [[Microsoft]] Gabrielle Davelaar is a Data Platform Solution Architect specialized in Artificial Intelligence solutions at [[Microsoft]]. She was originally trained as a computational neuroscientist. Currently she helps [[Microsoft]]’s top 15 Fortune 500 customers build trustworthy and scalable platforms able to create the next generation of A.I. applications. While helping customers with their digital A.I. transformation, she started working with engineering to tackle one key issue: A.I. maturity. The demand for this work is high, and Gabrielle is now working on bringing together the right people to create a full offering. Her aspirations are to be a technical leader in the healthcare digital transformation. Empowering people to find new treatments using A.I. while insuring privacy and taking data governance in consideration. Jordan Edwards is a Senior Program Manager on the Azure AI Platform team. He has worked on a number of highly performant, globally distributed systems across Bing, Cortana and [[Microsoft]] Advertising and is currently working on CI/CD experiences for the next generation of Azure Machine Learning. Jordan has been a key driver of dev-ops modernization in AI+R, including but not limited to: moving to Git, moving the organization at large to CI/CD, packaging and build language modernization, movement from monolithic services to microservice platforms and driving for a culture of friction free devOps and flexible engineering culture. His passion is to continue driving [[Microsoft]] towards a culture which enables our engineering talent to do and achieve more. DOES18 Las Vegas DOES 2018 US DevOps Enterprise Summit 2018 https://events.itrevolution.com/us/ | ||
|} | |} | ||
| Line 544: | Line 542: | ||
<youtube>VCUDo9umKEQ</youtube> | <youtube>VCUDo9umKEQ</youtube> | ||
<b>Webinar: MLOps automation with Git Based CI/CD for ML | <b>Webinar: MLOps automation with Git Based CI/CD for ML | ||
| − | </b><br>Deploying AI/ML based applications is far from trivial. On top of the traditional DevOps challenges, you need to foster collaboration between multidisciplinary teams (data-scientists, data/ML engineers, software developers and DevOps), handle model and experiment versioning, data versioning, etc. Most ML/AI deployments involve significant manual work, but this is changing with the introduction of new frameworks that leverage cloud-native paradigms, Git and Kubernetes to automate the process of ML/AI-based application deployment. In this session we will explain how ML Pipelines work, the main challenges and the different steps involved in producing models and data products (data gathering, preparation, training/AutoML, validation, model deployment, drift monitoring and so on). We will demonstrate how the development and deployment process can be greatly simplified and automated. We’ll show how you can: a. maximize the efficiency and collaboration between the various teams, b. harness Git review processes to evaluate models, and c. abstract away the complexity of Kubernetes and DevOps. We will demo how to enable continuous delivery of machine learning to production using Git, CI frameworks (e.g. GitHub Actions) with hosted Kubernetes, Kubeflow, MLOps orchestration tools (MLRun), and [[Serverless]] functions (Nuclio) using real-world application examples. Presenter: Yaron Haviv, Co-Founder and CTO @Iguazio | + | </b><br>Deploying AI/ML based applications is far from trivial. On top of the traditional DevOps challenges, you need to foster collaboration between multidisciplinary teams (data-scientists, data/ML engineers, software developers and DevOps), handle model and experiment versioning, data versioning, etc. Most ML/AI deployments involve significant manual work, but this is changing with the introduction of new frameworks that leverage cloud-native paradigms, Git and Kubernetes to automate the process of ML/AI-based application deployment. In this session we will explain how ML Pipelines work, the main challenges and the different steps involved in producing models and data products (data gathering, preparation, training/AutoML, validation, model deployment, drift monitoring and so on). We will demonstrate how the [[development]] and deployment process can be greatly simplified and automated. We’ll show how you can: a. maximize the efficiency and collaboration between the various teams, b. harness Git review processes to evaluate models, and c. abstract away the complexity of Kubernetes and DevOps. We will demo how to enable continuous delivery of machine learning to production using Git, CI frameworks (e.g. GitHub Actions) with hosted Kubernetes, Kubeflow, MLOps orchestration tools (MLRun), and [[Serverless]] functions (Nuclio) using real-world application examples. Presenter: Yaron Haviv, Co-Founder and CTO @Iguazio |
|} | |} | ||
|<!-- M --> | |<!-- M --> | ||
| Line 552: | Line 550: | ||
<youtube>MSTYOOCg4bg</youtube> | <youtube>MSTYOOCg4bg</youtube> | ||
<b>How RealPage Leveraged Full Stack Visibility and Integrated AIOps for SaaS Innovation and Customer S | <b>How RealPage Leveraged Full Stack Visibility and Integrated AIOps for SaaS Innovation and Customer S | ||
| − | </b><br>Development and operation teams continue to struggle with having a unified view of their applications and infrastructure. | + | </b><br>[[Development]] and operation teams continue to struggle with having a unified view of their applications and infrastructure. |
| − | In this webinar, you'll learn how RealPage, the industry leader in SaaS-based Property Management Solutions, leverages an integrated AppDynamics and Virtana AIOps solution to deliver a superior customer experience by managing the performance of its applications as well as its infrastructure. RealPage must ensure its applications and infrastructure are always available and continuously performing, while constantly innovating to deliver new capabilities to sustain their market leadership. The combination of their Agile development process and highly virtualized infrastructure environment only adds to the complexity of managing both. To meet this challenge, RealPage is leveraging the visibility and AIOps capabilities delivered by the integrated solutions from AppDynamics and Virtana. | + | In this webinar, you'll learn how RealPage, the industry leader in SaaS-based Property Management Solutions, leverages an integrated AppDynamics and Virtana AIOps solution to deliver a superior customer experience by managing the performance of its applications as well as its infrastructure. RealPage must ensure its applications and infrastructure are always available and continuously performing, while constantly innovating to deliver new capabilities to sustain their market leadership. The combination of their Agile [[development]] process and highly virtualized infrastructure environment only adds to the complexity of managing both. To meet this challenge, RealPage is leveraging the visibility and AIOps capabilities delivered by the integrated solutions from AppDynamics and Virtana. |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 588: | Line 586: | ||
<b>PipelineAI: High Performance Distributed [[TensorFlow]] AI + GPU + Model Optimizing Predictions | <b>PipelineAI: High Performance Distributed [[TensorFlow]] AI + GPU + Model Optimizing Predictions | ||
</b><br>We will each build an end-to-end, continuous [[TensorFlow]] AI model training and deployment pipeline on our own GPU-based cloud instance. At the end, we will combine our cloud instances to create the LARGEST Distributed [[TensorFlow]] AI Training and Serving Cluster in the WORLD! Pre-requisites Just a modern browser and an internet connection. We'll provide the rest! Agenda Spark ML [[TensorFlow]] AI Storing and Serving Models with HDFS Trade-offs of CPU vs. *GPU, Scale Up vs. Scale Out | </b><br>We will each build an end-to-end, continuous [[TensorFlow]] AI model training and deployment pipeline on our own GPU-based cloud instance. At the end, we will combine our cloud instances to create the LARGEST Distributed [[TensorFlow]] AI Training and Serving Cluster in the WORLD! Pre-requisites Just a modern browser and an internet connection. We'll provide the rest! Agenda Spark ML [[TensorFlow]] AI Storing and Serving Models with HDFS Trade-offs of CPU vs. *GPU, Scale Up vs. Scale Out | ||
| − | CUDA + cuDNN GPU Development Overview [[TensorFlow]] Model Checkpointing, Saving, Exporting, and Importing Distributed [[TensorFlow]] AI Model Training (Distributed [[TensorFlow]]) [[TensorFlow]]'s Accelerated Linear Algebra Framework (XLA) [[TensorFlow]]'s Just-in-Time (JIT) Compiler, Ahead of Time (AOT) Compiler Centralized Logging and Visualizing of Distributed [[TensorFlow]] Training (Tensorboard) Distributed [[TensorFlow]] AI Model Serving/Predicting ([[TensorFlow]] Serving) Centralized Logging and Metrics Collection (Prometheus, Grafana) Continuous [[TensorFlow]] AI Model Deployment ([[TensorFlow]], Airflow) Hybrid Cross-Cloud and On-Premise Deployments (Kubernetes) High-Performance and Fault-Tolerant Micro-services (NetflixOSS) https://pipeline.ai | + | CUDA + cuDNN GPU [[Development]] Overview [[TensorFlow]] Model Checkpointing, Saving, Exporting, and Importing Distributed [[TensorFlow]] AI Model Training (Distributed [[TensorFlow]]) [[TensorFlow]]'s Accelerated Linear Algebra Framework (XLA) [[TensorFlow]]'s Just-in-Time (JIT) Compiler, Ahead of Time (AOT) Compiler Centralized Logging and Visualizing of Distributed [[TensorFlow]] Training (Tensorboard) Distributed [[TensorFlow]] AI Model Serving/Predicting ([[TensorFlow]] Serving) Centralized Logging and Metrics Collection (Prometheus, Grafana) Continuous [[TensorFlow]] AI Model Deployment ([[TensorFlow]], Airflow) Hybrid Cross-Cloud and On-Premise Deployments (Kubernetes) High-Performance and Fault-Tolerant Micro-services (NetflixOSS) https://pipeline.ai |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 666: | Line 664: | ||
<youtube>ml4vlXzVFeE</youtube> | <youtube>ml4vlXzVFeE</youtube> | ||
<b>MLOps #34 Owned By Statistics: How Kubeflow & MLOps Can Help Secure ML Workloads // David Aronchick | <b>MLOps #34 Owned By Statistics: How Kubeflow & MLOps Can Help Secure ML Workloads // David Aronchick | ||
| − | </b><br>While machine learning is spreading like wildfire, very little attention has been paid to the ways that it can go wrong when moving from development to production. Even when models work perfectly, they can be attacked and/or degrade quickly if the data changes. Having a well understood MLOps process is necessary for ML security! Using Kubeflow, we demonstrated how to the common ways machine learning workflows go wrong, and how to mitigate them using MLOps pipelines to provide reproducibility, validation, versioning/tracking, and safe/compliant deployment. We also talked about the direction for MLOps as an industry, and how we can use it to move faster, with less risk, than ever before. David leads Open Source Machine Learning Strategy at Azure. This means he spends most of his time helping humans to convince machines to be smarter. He is only moderately successful at this. Previously, he led product management for Kubernetes on behalf of [[Google]], launched [[Google]] Kubernetes Engine, and co-founded the Kubeflow project. He has also worked at [[Microsoft]], [[Amazon]] and Chef and co-founded three startups. When not spending too much time in service of electrons, he can be found on a mountain (on skis), traveling the world (via restaurants) or participating in kid activities, of which there are a lot more than he remembers than when he was that age. | + | </b><br>While machine learning is spreading like wildfire, very little attention has been paid to the ways that it can go wrong when moving from [[development]] to production. Even when models work perfectly, they can be attacked and/or degrade quickly if the data changes. Having a well understood MLOps process is necessary for ML security! Using Kubeflow, we demonstrated how to the common ways machine learning workflows go wrong, and how to mitigate them using MLOps pipelines to provide reproducibility, validation, versioning/tracking, and safe/compliant deployment. We also talked about the direction for MLOps as an industry, and how we can use it to move faster, with less risk, than ever before. David leads Open Source Machine Learning Strategy at Azure. This means he spends most of his time helping humans to convince machines to be smarter. He is only moderately successful at this. Previously, he led product management for Kubernetes on behalf of [[Google]], launched [[Google]] Kubernetes Engine, and co-founded the Kubeflow project. He has also worked at [[Microsoft]], [[Amazon]] and Chef and co-founded three startups. When not spending too much time in service of electrons, he can be found on a mountain (on skis), traveling the world (via restaurants) or participating in kid activities, of which there are a lot more than he remembers than when he was that age. |
|} | |} | ||
|<!-- M --> | |<!-- M --> | ||
| Line 674: | Line 672: | ||
<youtube>6gdrwFMaEZ0</youtube> | <youtube>6gdrwFMaEZ0</youtube> | ||
<b>An introduction to MLOps on Google Cloud | <b>An introduction to MLOps on Google Cloud | ||
| − | </b><br>The enterprise machine learning life cycle is expanding as firms increasingly look to automate their production ML systems. MLOps is an ML engineering culture and practice that aims at unifying ML system development and ML system operation enabling shorter development cycles, increased deployment velocity, and more dependable releases in close alignment with business objectives. Learn how to construct your systems to standardize and manage the life cycle of machine learning in production with MLOps on Google Cloud. Speaker: Nate Keating Watch more: Google Cloud Next ’20: OnAir → https://goo.gle/next2020 | + | </b><br>The enterprise machine learning life cycle is expanding as firms increasingly look to automate their production ML systems. MLOps is an ML engineering culture and practice that aims at unifying ML system [[development]] and ML system operation enabling shorter [[development]] cycles, increased deployment velocity, and more dependable releases in close alignment with business objectives. Learn how to construct your systems to standardize and manage the life cycle of machine learning in production with MLOps on Google Cloud. Speaker: Nate Keating Watch more: Google Cloud Next ’20: OnAir → https://goo.gle/next2020 |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 726: | Line 724: | ||
<youtube>KidlhiqSNmM</youtube> | <youtube>KidlhiqSNmM</youtube> | ||
<b>Commit Virtual 2020: MLOps DevOps for Machine Learning | <b>Commit Virtual 2020: MLOps DevOps for Machine Learning | ||
| − | </b><br>GitLab Speaker: Monmayuri Ray The practice of Devops - developing software and operationalizing the development cycle has been evolving for over a decade. Now, a new addition has joined this holistic development cycle: Machine Predictions. The emerging art and science of machine learning algorithms integrated into current operational systems is opening new possibilities for engineers, scientists, and architects in the tech world. This presentation will take the audience on a journey in understanding the fundamentals of orchestrating machine predictions using MLOps in this ever-changing, agile world of software development. You’ll learn how to excel at the craft of DevOps for Machine Learning (ML). Monmayuri will unpack the theoretical constructs and show they apply to real-world scenarios. Get in touch with Sales: https://bit.ly/2IygR7z | + | </b><br>GitLab Speaker: Monmayuri Ray The practice of Devops - developing software and operationalizing the [[development]] cycle has been evolving for over a decade. Now, a new addition has joined this holistic [[development]] cycle: Machine Predictions. The emerging art and science of machine learning algorithms integrated into current operational systems is opening new possibilities for engineers, scientists, and architects in the tech world. This presentation will take the audience on a journey in understanding the fundamentals of orchestrating machine predictions using MLOps in this ever-changing, agile world of software [[development]]. You’ll learn how to excel at the craft of DevOps for Machine Learning (ML). Monmayuri will unpack the theoretical constructs and show they apply to real-world scenarios. Get in touch with Sales: https://bit.ly/2IygR7z |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 743: | Line 741: | ||
<youtube>uClvvlfJxqo</youtube> | <youtube>uClvvlfJxqo</youtube> | ||
<b>[[Python]] Lunch Break presents MLOps | <b>[[Python]] Lunch Break presents MLOps | ||
| − | </b><br>Deploy your [[Assistants#Chatbot | Chatbot]] using CI/CD by William Arias Leverage DevOps practices in your next [[Assistants#Chatbot | Chatbot]] deployments, create pipelines for training and testing your [[Assistants#Chatbot | Chatbot]] before automating the deployment to staging or production. NLP developers can focus on the [[Assistants#Chatbot | Chatbot]] development and worry less about infrastructure and environments configuration Bio: Born and raised in Colombia, studied Electronic Engineering and specialized in Digital Electronics, former exchange student in Czech Technical University in the faculty of Data Science. I started my career working in Intel as Field Engineer, then moved to Oracle in Bogota. After 5 years in Oracle as Solution Architect I decided to get deeper in my knowledge of Machine Learning and Databases, relocated to Prague in Czech Republic, where I studied Data Science for a while from the academia perspective, later jumped to Solution Architect in CA technologies, later moved on to Developer of Automations and NLP in Adecco. Currently I work at Gitlab as Technical Marketing Engineer, teaching and evangelizing developers about DevOps | + | </b><br>Deploy your [[Assistants#Chatbot | Chatbot]] using CI/CD by William Arias Leverage DevOps practices in your next [[Assistants#Chatbot | Chatbot]] deployments, create pipelines for training and testing your [[Assistants#Chatbot | Chatbot]] before automating the deployment to staging or production. NLP developers can focus on the [[Assistants#Chatbot | Chatbot]] [[development]] and worry less about infrastructure and environments configuration Bio: Born and raised in Colombia, studied Electronic Engineering and specialized in Digital Electronics, former exchange student in Czech Technical University in the faculty of Data Science. I started my career working in Intel as Field Engineer, then moved to Oracle in Bogota. After 5 years in Oracle as Solution Architect I decided to get deeper in my knowledge of Machine Learning and Databases, relocated to Prague in Czech Republic, where I studied Data Science for a while from the academia perspective, later jumped to Solution Architect in CA technologies, later moved on to Developer of Automations and NLP in Adecco. Currently I work at Gitlab as Technical Marketing Engineer, teaching and evangelizing developers about DevOps |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 794: | Line 792: | ||
* [https://dzone.com/articles/leveraging-ai-and-automation-for-successful-devsec Leveraging AI and Automation for Successful DevSecOps | Vishnu Nallani - DZone] | * [https://dzone.com/articles/leveraging-ai-and-automation-for-successful-devsec Leveraging AI and Automation for Successful DevSecOps | Vishnu Nallani - DZone] | ||
| − | DevSecOps (also known as SecDevOps and DevOpsSec) is the process of integrating secure development best practices and methodologies into continuous design, development, deployment and integration processes | + | DevSecOps (also known as SecDevOps and DevOpsSec) is the process of integrating secure [[development]] best practices and methodologies into continuous design, development, [[deployment]] and integration processes |
<hr> | <hr> | ||
| Line 814: | Line 812: | ||
<youtube>19FfDsadajk</youtube> | <youtube>19FfDsadajk</youtube> | ||
<b>DevSecOps State of the Union | <b>DevSecOps State of the Union | ||
| − | </b><br>Clint Gibler, Research Director, NCC Group It’s tough to keep up with the DevSecOps resources out there, or even know where to start. This talk will summarize and distill the unique tips and tricks, lessons learned, and tools discussed in dozens of blog posts and more than 50 conference talks over the past few years, and combine it with knowledge gained from in-person discussions with security leaders at companies with mature security programs. Pre-Requisites: General understanding of the fundamental areas of modern application security programs, including threat modeling, secure code reviews, security training, building security culture/developing security champions, security scanning (static and dynamic analysis tools), monitoring and logging in production, etc. Understanding of how software generally moves from development to production in agile environments that embrace CI/CD practices. Basic understanding of the principles of network/infrastructure and cloud security. | + | </b><br>Clint Gibler, Research Director, NCC Group It’s tough to keep up with the DevSecOps resources out there, or even know where to start. This talk will summarize and distill the unique tips and tricks, lessons learned, and tools discussed in dozens of blog posts and more than 50 conference talks over the past few years, and combine it with knowledge gained from in-person discussions with security leaders at companies with mature security programs. Pre-Requisites: General understanding of the fundamental areas of modern application security programs, including threat modeling, secure code reviews, security training, building security culture/developing security champions, security scanning (static and dynamic analysis tools), monitoring and logging in production, etc. Understanding of how software generally moves from [[development]] to production in agile environments that embrace CI/CD practices. Basic understanding of the principles of network/infrastructure and cloud security. |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 831: | Line 829: | ||
<youtube>MTurwl9QDu8</youtube> | <youtube>MTurwl9QDu8</youtube> | ||
<b>DevOps for Beginners Where to Start | <b>DevOps for Beginners Where to Start | ||
| − | </b><br>DevOpsTV Tim Beattie Global Head of Product, Open Innovation Labs, RedHat If you're beginning to learn more about DevOps, you may be confused about where to start or where to focus. The term “DevOps” refers to this idea that we no longer have pure and separated development streams and operations streams – and to a set of DevOps practices that optimizes and improves both functions. Join this webinar to explore how to get going with this cross-functional way of working that breaks down walls, removes bottlenecks, improves speed of delivery, and increases experimentation. | + | </b><br>DevOpsTV Tim Beattie Global Head of Product, Open Innovation Labs, RedHat If you're beginning to learn more about DevOps, you may be confused about where to start or where to focus. The term “DevOps” refers to this idea that we no longer have pure and separated [[development]] streams and operations streams – and to a set of DevOps practices that optimizes and improves both functions. Join this webinar to explore how to get going with this cross-functional way of working that breaks down walls, removes bottlenecks, improves speed of delivery, and increases experimentation. |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 947: | Line 945: | ||
<youtube>2STTK52eAbM</youtube> | <youtube>2STTK52eAbM</youtube> | ||
<b>[[Defense|DOD]] Enterprise DevSecOps Initiative | <b>[[Defense|DOD]] Enterprise DevSecOps Initiative | ||
| − | </b><br>CSIAC The current [[Defense|Department of Defense (DOD)]] software acquisition process is not responsive to the needs of our warfighters. Therefore, it is difficult for the DOD to keep pace with our potential adversaries and avoid falling behind them. To address this situation, the [[Defense|DOD]] is pursuing a new software development activity called the [[Defense|DOD]] Enterprise DevSecOps Initiative. This webinar will present the vision for transforming [[Defense|DOD]] software acquisition into secure, responsive software factories. It will examine and explore the utilization of modern software development processes and tools to revolutionize the Department’s ability to provide responsive, timely, and secure software capabilities for our warfighters. The focus of the effort involves exploiting automated software tools, services, and standards so warfighters can rapidly create, deploy, and operate software applications in a secure, flexible, and interoperable manner. [https://www.csiac.org/podcast/dod-enterprise-devsecops-initiative/ Slides] | + | </b><br>CSIAC The current [[Defense|Department of Defense (DOD)]] software acquisition process is not responsive to the needs of our warfighters. Therefore, it is difficult for the DOD to keep pace with our potential adversaries and avoid falling behind them. To address this situation, the [[Defense|DOD]] is pursuing a new software [[development]] activity called the [[Defense|DOD]] Enterprise DevSecOps Initiative. This webinar will present the vision for transforming [[Defense|DOD]] software acquisition into secure, responsive software factories. It will examine and explore the utilization of modern software [[development]] processes and tools to revolutionize the Department’s ability to provide responsive, timely, and secure software capabilities for our warfighters. The focus of the effort involves exploiting automated software tools, services, and standards so warfighters can rapidly create, deploy, and operate software applications in a secure, flexible, and interoperable manner. [https://www.csiac.org/podcast/dod-enterprise-devsecops-initiative/ Slides] |
|} | |} | ||
|<!-- M --> | |<!-- M --> | ||
| Line 955: | Line 953: | ||
<youtube>mE9HMNn7_Pg</youtube> | <youtube>mE9HMNn7_Pg</youtube> | ||
<b>DevSecOps Implementation in the [[Defense|DoD]]: Barriers and Enablers | <b>DevSecOps Implementation in the [[Defense|DoD]]: Barriers and Enablers | ||
| − | </b><br>Software Engineering Institute | Carnegie Mellon University Today's [[Defense|DOD]] software development and deployment is not responsive to warfighter needs. As a result, the [[Defense|DOD]]'s ability to keep pace with potential adversaries is falling behind. In this webcast, panelists discuss potential enablers of and barriers to using modern software development techniques and processes in the [[Defense|DOD]] or similar segregated environments. These software development techniques and processes are as commonly known as DevSecOps. | + | </b><br>Software Engineering Institute | Carnegie Mellon University Today's [[Defense|DOD]] software [[development]] and deployment is not responsive to warfighter needs. As a result, the [[Defense|DOD]]'s ability to keep pace with potential adversaries is falling behind. In this webcast, panelists discuss potential enablers of and barriers to using modern software [[development]] techniques and processes in the [[Defense|DOD]] or similar segregated environments. These software [[development]] techniques and processes are as commonly known as DevSecOps. |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 1,051: | Line 1,049: | ||
<youtube>x4oIdooDzKo</youtube> | <youtube>x4oIdooDzKo</youtube> | ||
<b>Machine Learning Models in Production | <b>Machine Learning Models in Production | ||
| − | </b><br>Data Scientists and Machine Learning practitioners, nowadays, seem to be churning out models by the dozen and they continuously experiment to find ways to improve their accuracies. They also use a variety of ML and DL frameworks & languages , and a typical organization may find that this results in a heterogenous, complicated bunch of assets that require different types of runtimes, resources and sometimes even specialized compute to operate efficiently. But what does it mean for an enterprise to actually take these models to "production" ? How does an organization scale inference engines out & make them available for real-time applications without significant latencies ? There needs to be different techniques for batch ,offline, inferences and instant, online scoring. Data needs to be accessed from various sources and cleansing, transformations of data needs to be enabled prior to any predictions. In many cases, there maybe no substitute for customized data handling with scripting either. Enterprises also require additional auditing and authorizations built in, approval processes and still support a "continuous delivery" paradigm whereby a data scientist can enable insights faster. Not all models are created equal, nor are consumers of a model - so enterprises require both metering and allocation of compute resources for SLAs. In this session, we will take a look at how machine learning is operationalized in IBM Data Science Experience, DSX, a Kubernetes based offering for the Private Cloud and optimized for the HortonWorks Hadoop Data Platform. DSX essentially brings in typical software engineering development practices to Data Science, organizing the dev-test-production for machine learning assets in much the same way as typical software deployments. We will also see what it means to deploy, monitor accuracies and even rollback models & custom scorers as well as how API based techniques enable consuming business processes and applications to remain relatively stable amidst all the chaos. Speaker: Piotr Mierzejewski, Program Director Development [[IBM]] DSX Local, [[IBM]] | + | </b><br>Data Scientists and Machine Learning practitioners, nowadays, seem to be churning out models by the dozen and they continuously experiment to find ways to improve their accuracies. They also use a variety of ML and DL frameworks & languages , and a typical organization may find that this results in a heterogenous, complicated bunch of assets that require different types of runtimes, resources and sometimes even specialized compute to operate efficiently. But what does it mean for an enterprise to actually take these models to "production" ? How does an organization scale inference engines out & make them available for real-time applications without significant latencies ? There needs to be different techniques for batch ,offline, inferences and instant, online scoring. Data needs to be accessed from various sources and cleansing, transformations of data needs to be enabled prior to any predictions. In many cases, there maybe no substitute for customized data handling with scripting either. Enterprises also require additional auditing and authorizations built in, approval processes and still support a "continuous delivery" paradigm whereby a data scientist can enable insights faster. Not all models are created equal, nor are consumers of a model - so enterprises require both metering and allocation of compute resources for SLAs. In this session, we will take a look at how machine learning is operationalized in IBM Data Science Experience, DSX, a Kubernetes based offering for the Private Cloud and optimized for the HortonWorks Hadoop Data Platform. DSX essentially brings in typical software engineering [[development]] practices to Data Science, organizing the dev-test-production for machine learning assets in much the same way as typical software deployments. We will also see what it means to deploy, monitor accuracies and even rollback models & custom scorers as well as how API based techniques enable consuming business processes and applications to remain relatively stable amidst all the chaos. Speaker: Piotr Mierzejewski, Program Director [[Development]] [[IBM]] DSX Local, [[IBM]] |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
Revision as of 14:30, 17 March 2023
YouTube search... Quora search... ...Google search
- AI Governance / Algorithm Administration
- Graphical Tools for Modeling AI Components
- Hyperparameters
- Evaluation ... Prompts for assessing AI projects
- Train, Validate, and Test
- NLP Workbench / Pipeline
- Development ...AI Pair Programming Tools ... Analytics ... Visualization ... Diagrams for Business Analysis
- Building Your Environment
- Service Capabilities
- AI Marketplace & Toolkit/Model Interoperability
- Directed Acyclic Graph (DAG) - programming pipelines
- Containers; Docker, Kubernetes & Microservices
- Platforms: AI/Machine Learning as a Service (AIaaS/MLaaS)
- Automatic Machine Learning (AutoML) Landscape Survey | Alexander Allen & Adithya Balaji - Georgian Partners...
- Automate your data lineage
- Benefiting from AI: A different approach to data management is needed
- Git - GitHub and GitLab ...publishing your model
- Use a Pipeline to Chain PCA with a RandomForest Classifier Jupyter Notebook | Jon Tupitza
- ML.NET Model Lifecycle with Azure DevOps CI/CD pipelines | Cesar de la Torre - Microsoft
- A Great Model is Not Enough: Deploying AI Without Technical Debt | DataKitchen - Medium
- Infrastructure Tools for Production | Aparna Dhinakaran - Towards Data Science ...Model Deployment and Serving
- Global Community for Artificial Intelligence (AI) in Master Data Management (MDM) | Camelot Management Consultants
- Particle Swarms for Dynamic Optimization Problems | T. Blackwell, J. Branke, and X. Li
- 5G_Security
Contents
Tools
- Google AutoML automatically build and deploy state-of-the-art machine learning models
- TensorBoard | Google
- Kubeflow Pipelines - a platform for building and deploying portable, scalable machine learning (ML) workflows based on Docker containers. Introducing AI Hub and Kubeflow Pipelines: Making AI simpler, faster, and more useful for businesses | Google
- SageMaker | Amazon
- MLOps | Microsoft ...model management, deployment, and monitoring with Azure
- Ludwig - a Python toolbox from Uber that allows to train and test deep learning models
- TPOT a Python library that automatically creates and optimizes full machine learning pipelines using genetic programming. Not for NLP, strings need to be coded to numerics.
- H2O Driverless AI for automated Visualization, feature engineering, model training, hyperparameter optimization, and explainability.
- alteryx: Feature Labs, Featuretools
- MLBox Fast reading and distributed data preprocessing/cleaning/formatting. Highly robust feature selection and leak detection. Accurate hyper-parameter optimization in high-dimensional space. State-of-the art predictive models for classification and regression (Deep Learning, Stacking, LightGBM,…). Prediction with models interpretation. Primarily Linux.
- auto-sklearn algorithm selection and hyperparameter tuning. It leverages recent advantages in Bayesian optimization, meta-learning and ensemble construction.is a Bayesian hyperparameter optimization layer on top of scikit-learn. Not for large datasets.
- Auto Keras is an open-source Python package for neural architecture search.
- ATM -auto tune models - a multi-tenant, multi-data system for automated machine learning (model selection and tuning). ATM is an open source software library under the Human Data Interaction project (HDI) at MIT.
- Auto-WEKA is a Bayesian hyperparameter optimization layer on top of Weka. Weka is a collection of machine learning algorithms for data mining tasks. The algorithms can either be applied directly to a dataset or called from your own Java code. Weka contains tools for data pre-processing, classification, regression, clustering, association rules, and visualization.
- TransmogrifAI - an AutoML library for building modular, reusable, strongly typed machine learning workflows. A Scala/SparkML library created by Salesforce for automated data cleansing, feature engineering, model selection, and hyperparameter optimization
- RECIPE - a framework based on grammar-based genetic programming that builds customized scikit-learn classification pipelines.
- AutoMLC Automated Multi-Label Classification. GA-Auto-MLC and Auto-MEKAGGP are freely-available methods that perform automated multi-label classification on the MEKA software.
- Databricks MLflow an open source framework to manage the complete Machine Learning lifecycle using Managed MLflow as an integrated service with the Databricks Unified Analytics Platform... ...manage the ML lifecycle, including experimentation, reproducibility and deployment
- SAS Viya automates the process of data cleansing, data transformations, feature engineering, algorithm matching, model training and ongoing governance.
- Comet ML ...self-hosted and cloud-based meta machine learning platform allowing data scientists and teams to track, compare, explain and optimize experiments and models
- Domino Model Monitor (DMM) | Domino ...monitor the performance of all models across your entire organization
- Weights and Biases ...experiment tracking, model optimization, and dataset versioning
- SigOpt ...optimization platform and API designed to unlock the potential of modeling pipelines. This fully agnostic software solution accelerates, amplifies, and scales the model development process
- DVC ...Open-source Version Control System for Machine Learning Projects
- ModelOp Center | ModelOp
- Moogsoft and Red Hat Ansible Tower
- DSS | Dataiku
- Model Manager | SAS
- Machine Learning Operations (MLOps) | DataRobot ...build highly accurate predictive models with full transparency
- Metaflow, Netflix and AWS open source Python library
Master Data Management (MDM)
YouTube search... ...Google search Feature Store / Data Lineage / Data Catalog
|
|
|
|
|
|
|
|
Versioning
YouTube search... ...Google search
- DVC | DVC.org
- Pachyderm …Pachyderm for data scientists | Gerben Oostra - bigdata - Medium
- Dataiku
- Continuous Machine Learning (CML)
|
|
|
|
|
|
Model Versioning - ModelDB
- ModelDB: An open-source system for Machine Learning model versioning, metadata, and experiment management
|
|
Hyperparameter
YouTube search... ...Google search
- Gradient Descent Optimization & Challenges
- Hypernetworks
- Using TensorFlow Tuning
- Understanding Hyperparameters and its Optimisation techniques | Prabhu - Towards Data Science
- How To Make Deep Learning Models That Don’t Suck | Ajay Uppili Arasanipalai
In machine learning, a hyperparameter is a parameter whose value is set before the learning process begins. By contrast, the values of other parameters are derived via training. Different model training algorithms require different hyperparameters, some simple algorithms (such as ordinary least squares regression) require none. Given these hyperparameters, the training algorithm learns the parameters from the data. Hyperparameter (machine learning) | Wikipedia
Machine learning algorithms train on data to find the best set of weights for each independent variable that affects the predicted value or class. The algorithms themselves have variables, called hyperparameters. They’re called hyperparameters, as opposed to parameters, because they control the operation of the algorithm rather than the weights being determined. The most important hyperparameter is often the learning rate, which determines the step size used when finding the next set of weights to try when optimizing. If the learning rate is too high, the gradient descent may quickly converge on a plateau or suboptimal point. If the learning rate is too low, the gradient descent may stall and never completely converge. Many other common hyperparameters depend on the algorithms used. Most algorithms have stopping parameters, such as the maximum number of epochs, or the maximum time to run, or the minimum improvement from epoch to epoch. Specific algorithms have hyperparameters that control the shape of their search. For example, a Random Forest (or) Random Decision Forest Classifier has hyperparameters for minimum samples per leaf, max depth, minimum samples at a split, minimum weight fraction for a leaf, and about 8 more. Machine learning algorithms explained | Martin Heller - InfoWorld
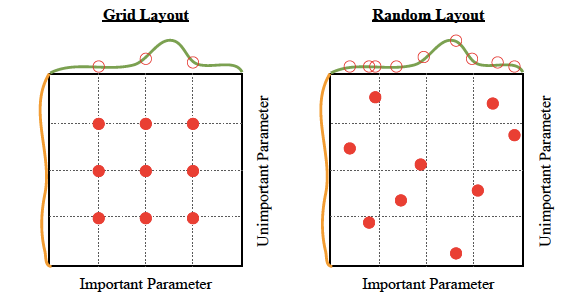
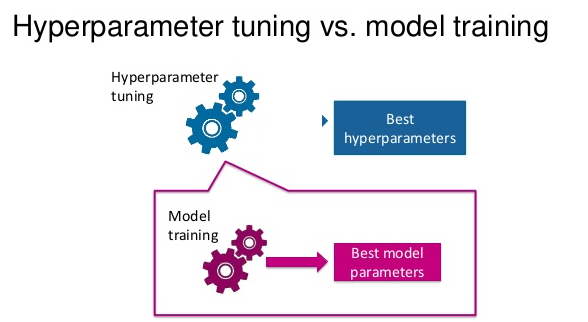
Hyperparameter Tuning
Hyperparameters are the variables that govern the training process. Your model parameters are optimized (you could say "tuned") by the training process: you run data through the operations of the model, compare the resulting prediction with the actual value for each data instance, evaluate the accuracy, and adjust until you find the best combination to handle the problem. These algorithms automatically adjust (learn) their internal parameters based on data. However, there is a subset of parameters that is not learned and that have to be configured by an expert. Such parameters are often referred to as “hyperparameters” — and they have a big impact ...For example, the tree depth in a decision tree model and the number of layers in an artificial neural network are typical hyperparameters. The performance of a model can drastically depend on the choice of its hyperparameters. Machine learning algorithms and the art of hyperparameter selection - A review of four optimization strategies | Mischa Lisovyi and Rosaria Silipo - TNW
There are four commonly used optimization strategies for hyperparameters:
- Bayesian optimization
- Grid search
- Random search
- Hill climbing
Bayesian optimization tends to be the most efficient. You would think that tuning as many hyperparameters as possible would give you the best answer. However, unless you are running on your own personal hardware, that could be very expensive. There are diminishing returns, in any case. With experience, you’ll discover which hyperparameters matter the most for your data and choice of algorithms. Machine learning algorithms explained | Martin Heller - InfoWorld
Hyperparameter Optimization libraries:
- hyper-engine - Gaussian Process Bayesian optimization and some other techniques, like learning curve prediction
- Ray Tune: Hyperparameter Optimization Framework
- SigOpt’s API tunes your model’s parameters through state-of-the-art Bayesian optimization
- hyperopt; Distributed Asynchronous Hyperparameter Optimization in Python - random search and tree of parzen estimators optimization.
- Scikit-Optimize, or skopt - Gaussian process Bayesian optimization
- polyaxon
- GPyOpt; Gaussian Process Optimization
Tuning:
- Optimizer type
- Learning rate (fixed or not)
- Epochs
- Regularization rate (or not)
- Type of Regularization - L1, L2, ElasticNet
- Search type for local minima
- Gradient descent
- Simulated
- Annealing
- Evolutionary
- Decay rate (or not)
- Momentum (fixed or not)
- Nesterov Accelerated Gradient momentum (or not)
- Batch size
- Fitness measurement type
- MSE, accuracy, MAE, Cross-Entropy Loss
- Precision, recall
- Stop criteria
Automated Learning
YouTube search... ...Google search
- Other codeless options, Code Generators, Drag n' Drop
- AdaNet
- AI Software Learns to Make AI Software
- The Pentagon Wants AI to Take Over the Scientific Process | Automating Scientific Knowledge Extraction (ASKE) | DARPA
- Hallucinogenic Deep Reinforcement Learning Using Python and Keras | David Foster
- Automated Feature Engineering in Python - How to automatically create machine learning features | Will Koehrsen - Towards Data Science
- Why Meta-learning is Crucial for Further Advances of Artificial Intelligence? | Pavel Kordik
- Assured Autonomy | Dr. Sandeep Neema, DARPA
- Automatic Machine Learning is Broken | Piotr Plonski - KDnuggets
- Why 2020 will be the Year of Automated Machine Learning | Senthil Ravindran - Gigabit
- Meta Learning | Wikipedia
Several production machine-learning platforms now offer automatic hyperparameter tuning. Essentially, you tell the system what hyperparameters you want to vary, and possibly what metric you want to optimize, and the system sweeps those hyperparameters across as many runs as you allow. (Google Cloud hyperparameter tuning extracts the appropriate metric from the TensorFlow model, so you don’t have to specify it.)
An emerging class of data science toolkit that is finally making machine learning accessible to business subject matter experts. We anticipate that these innovations will mark a new era in data-driven decision support, where business analysts will be able to access and deploy machine learning on their own to analyze hundreds and thousands of dimensions simultaneously. Business analysts at highly competitive organizations will shift from using visualization tools as their only means of analysis, to using them in concert with AML. Data visualization tools will also be used more frequently to communicate model results, and to build task-oriented user interfaces that enable stakeholders to make both operational and strategic decisions based on output of scoring engines. They will also continue to be a more effective means for analysts to perform inverse analysis when one is seeking to identify where relationships in the data do not exist. 'Five Essential Capabilities: Automated Machine Learning' | Gregory Bonnette
H2O Driverless AI automatically performs feature engineering and hyperparameter tuning, and claims to perform as well as Kaggle masters. AmazonML SageMaker supports hyperparameter optimization. Microsoft Azure Machine Learning AutoML automatically sweeps through features, algorithms, and hyperparameters for basic machine learning algorithms; a separate Azure Machine Learning hyperparameter tuning facility allows you to sweep specific hyperparameters for an existing experiment. Google Cloud AutoML implements automatic deep transfer learning (meaning that it starts from an existing Deep Neural Network (DNN) trained on other data) and neural architecture search (meaning that it finds the right combination of extra network layers) for language pair translation, natural language classification, and image classification. Review: Google Cloud AutoML is truly automated machine learning | Martin Heller
|
|
AutoML
YouTube search... ...Google search
- Automated Machine Learning (AutoML) | Wikipedia
- AutoML.org ...ML Freiburg ... GitHub and ML Hannover
New cloud software suite of machine learning tools. It’s based on Google’s state-of-the-art research in image recognition called Neural Architecture Search (NAS). NAS is basically an algorithm that, given your specific dataset, searches for the most optimal neural network to perform a certain task on that dataset. AutoML is then a suite of machine learning tools that will allow one to easily train high-performance deep networks, without requiring the user to have any knowledge of deep learning or AI; all you need is labelled data! Google will use NAS to then find the best network for your specific dataset and task. AutoKeras: The Killer of Google’s AutoML | George Seif - KDnuggets

Automatic Machine Learning (AML)
Self-Learning
DARTS: Differentiable Architecture Search
YouTube search... ...Google search
- DARTS: Differentiable Architecture Search | H. Liu, K. Simonyan, and Y. Yang addresses the scalability challenge of architecture search by formulating the task in a differentiable manner. Unlike conventional approaches of applying evolution or reinforcement learning over a discrete and non-differentiable search space, the method is based on the continuous relaxation of the architecture representation, allowing efficient search of the architecture using gradient descent.
- Neural Architecture Search | Debadeepta Dey - Microsoft Research

AIOps / MLOps
Youtube search... ...Google search
- DevOps.com
- A Silver Bullet For CIOs; Three ways AIOps can help IT leaders get strategic - Lisa Wolfe - Forbes
- MLOps: What You Need To Know | Tom Taulli - Forbes
- What is so Special About AIOps for Mission Critical Workloads? | Rebecca James - DevOps
- What is AIOps? Artificial Intelligence for IT Operations Explained | BMC
- AIOps: Artificial Intelligence for IT Operations, Modernize and transform IT Operations with solutions built on the only Data-to-Everything platform | splunk>
- How to Get Started With AIOps | Susan Moore - Gartner
- Why AI & ML Will Shake Software Testing up in 2019 | Oleksii Kharkovyna - Medium
- Continuous Delivery for Machine Learning D. Sato, A. Wider and C. Windheuser - MartinFowler
- Defense: Adaptive Acquisition Framework (AAF)
Machine learning capabilities give IT operations teams contextual, actionable insights to make better decisions on the job. More importantly, AIOps is an approach that transforms how systems are automated, detecting important signals from vast amounts of data and relieving the operator from the headaches of managing according to tired, outdated runbooks or policies. In the AIOps future, the environment is continually improving. The administrator can get out of the impossible business of refactoring rules and policies that are immediately outdated in today’s modern IT environment. Now that we have AI and machine learning technologies embedded into IT operations systems, the game changes drastically. AI and machine learning-enhanced automation will bridge the gap between DevOps and IT Ops teams: helping the latter solve issues faster and more accurately to keep pace with business goals and user needs. How AIOps Helps IT Operators on the Job | Ciaran Byrne - Toolbox
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Continuous Machine Learning (CML)
- Continuous Machine Learning (CML) ...is Continuous Integration/Continuous Deployment (CI/CD) for Machine Learning Projects
- DVC | DVC.org
|
|
DevSecOps
Youtube search... ...Google search
- Cybersecurity
- Containers; Docker, Kubernetes & Microservices
- SafeCode ...nonprofit organization that brings business leaders and technical experts together to exchange insights and ideas on creating, improving and promoting scalable and effective software security programs.
- 3 ways AI will advance DevSecOps | Joseph Feiman - TechBeacon
- Leveraging AI and Automation for Successful DevSecOps | Vishnu Nallani - DZone
DevSecOps (also known as SecDevOps and DevOpsSec) is the process of integrating secure development best practices and methodologies into continuous design, development, deployment and integration processes
|
|
|
|
|
|
DevSecOps in Government
- Evaluation: DevSecOps Guide | General Services Administration (GSA)
- Cybersecurity & Acquisition Lifecycle Integration
- Defense|DOD Enterprise DevSecOps Reference Design Version 1.0 12 August 2019 | Department of Defense (DOD) Chief Information Officer (CIO
- Understanding the Differences Between Agile & DevSecOps - from a Business Perspective | General Services Administration (GSA)
|
|
|
|
Strangler Fig / Strangler Pattern
- Strangler Fig Application | Martin Fowler
- The Strangler pattern in practice | Michiel Rook
- Strangler pattern ...Cloud Design Patterns | Microsoft
- How to use strangler pattern for microservices modernization | N. Natean - Software Intelligence Plus
- Serverless Strangler Pattern on AWS | Ryan Means - Medium ... Serverless
Strangulation of a legacy or undesirable solution is a safe way to phase one thing out for something better, cheaper, or more expandable. You make something new that obsoletes a small percentage of something old, and put them live together. You do some more work in the same style, and go live again (rinse, repeat). Strangler Applications | Paul Hammant ...case studies
|
|
Model Monitoring
YouTube search... ...Google search
- How do you evaluate the performance of a machine learning model that's deployed into production? | Quora
- Why your Models need Maintenance | Martin Schmitz - Towards Data Science ...Change of concept & drift of Concept
- Deployed your Machine Learning Model? Here’s What you Need to Know About Post-Production Monitoring | Om Deshmukh - Analytics Vidhya ...proactive & reactive model monitoring
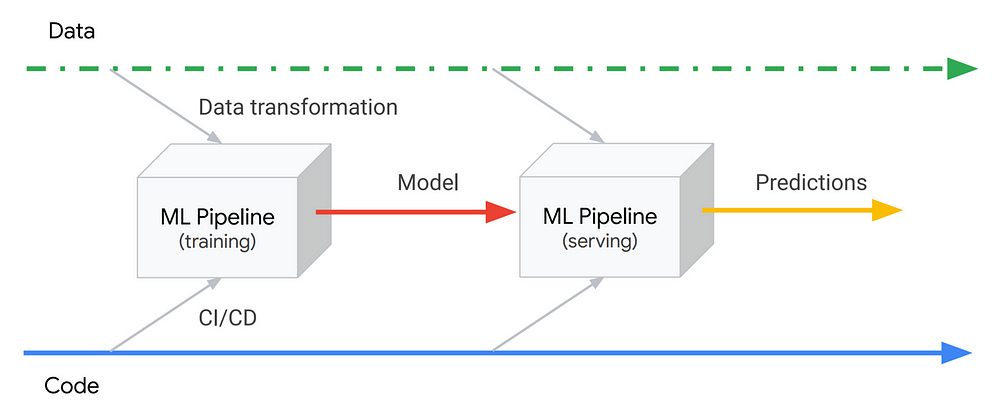
Monitoring production systems is essential to keeping them running well. For ML systems, monitoring becomes even more important, because their performance depends not just on factors that we have some control over, like infrastructure and our own software, but also on data, which we have much less control over. Therefore, in addition to monitoring standard metrics like latency, traffic, errors and saturation, we also need to monitor model prediction performance. An obvious challenge with monitoring model performance is that we usually don’t have a verified label to compare our model’s predictions to, since the model works on new data. In some cases we might have some indirect way of assessing the model’s effectiveness, for example by measuring click rate for a recommendation model. In other cases, we might have to rely on comparisons between time periods, for example by calculating a percentage of positive classifications hourly and alerting if it deviates by more than a few percent from the average for that time. Just like when validating the model, it’s also important to monitor metrics across slices, and not just globally, to be able to detect problems affecting specific segments. ML Ops: Machine Learning as an Engineering Discipline | Cristiano Breuel - Towards Data Science
|
|
|
|
A/B Testing
YouTube search... ...Google search
A/B testing (also known as bucket testing or split-run testing) is a user experience research methodology. A/B tests consist of a randomized experiment with two variants, A and B. It includes application of statistical hypothesis testing or "two-sample hypothesis testing" as used in the field of statistics. A/B testing is a way to compare two versions of a single variable, typically by testing a subject's response to variant A against variant B, and determining which of the two variants is more effective. A/B testing | Wikipedia
A randomized controlled trial (or randomized control trial; RCT) is a type of scientific (often medical) experiment that aims to reduce certain sources of bias when testing the effectiveness of new treatments; this is accomplished by randomly allocating subjects to two or more groups, treating them differently, and then comparing them with respect to a measured response. One group—the experimental group—receives the intervention being assessed, while the other—usually called the control group—receives an alternative treatment, such as a placebo or no intervention. The groups are monitored under conditions of the trial design to determine the effectiveness of the experimental intervention, and efficacy is assessed in comparison to the control. There may be more than one treatment group or more than one control group. Randomized controlled trial | Wikipedia
|
|
Scoring Deployed Models
YouTube search... ...Google search
|
|