YouTube
... Quora
...Google search
...Google News
...Bing News
- Data Quality ...validity, accuracy, cleaning, completeness, consistency, encoding, padding, augmentation, labeling, auto-tagging, normalization, standardization, and imbalanced data
- Data Science ... Governance ... Preprocessing ... Exploration ... Interoperability ... Master Data Management (MDM) ... Bias and Variances ... Benchmarks ... Datasets
- Risk, Compliance and Regulation ... Ethics ... Privacy ... Law ... AI Governance ... AI Verification and Validation
- Managed Vocabularies
- Excel ... Documents ... Database ... Graph ... LlamaIndex
- Development ... AI Pair Programming Tools ... Analytics ... Visualization ... Diagrams for Business Analysis ... AIOps/MLOps ... AIaaS/MLaaS
- Hyperparameters
- Evaluation ... for assessing AI projects
- Train, Validate, and Test
- Automated Learning
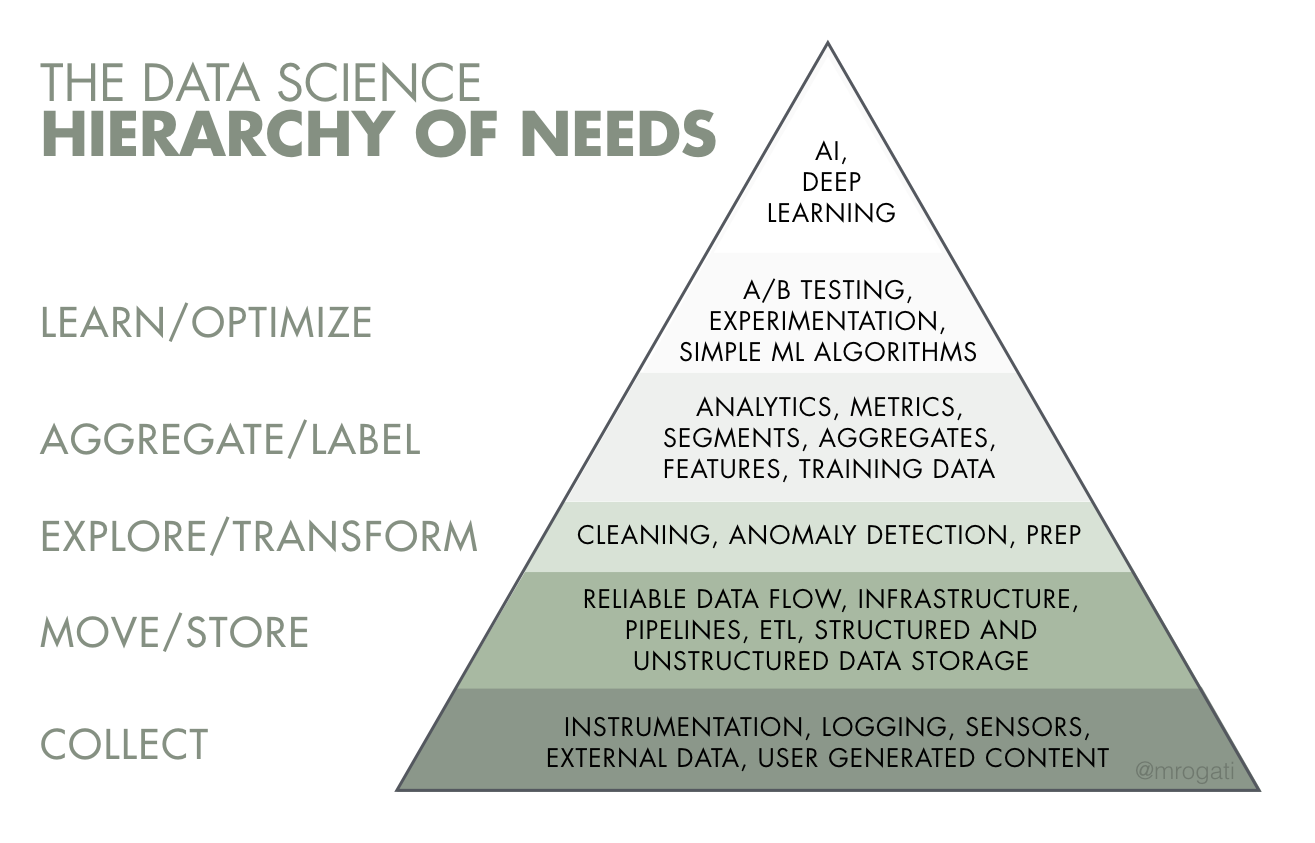
- The AI Hierarchy of Needs | Monica Rogati - Hackernoon
- Great Expectations ...helps data teams eliminate pipeline debt, through data testing, documentation, and profiling.
|
Testing and Documenting Your Data Doesn't Have to Suck | Superconductive
Data teams everywhere struggle with pipeline debt: untested, undocumented assumptions that drain productivity, erode trust in data and kill team morale. Unfortunately, rolling your own data validation tooling usually takes weeks or months. In addition, most teams suffer from “documentation rot,” where data documentation is hard to maintain, and therefore chronically outdated, incomplete, and only semi-trusted. Great Expectations - https://bit.ly/2OtmY1W, the leading open source project for fighting pipeline debt, can solve these problems for you. We're excited to share new features and under-the-hood architecture with the data community. ABOUT THE SPEAKER
Abe Gong is a core contributor to the Great Expectations open source library, and CEO and Co-founder at Superconductive. Prior to Superconductive, Abe was Chief Data Officer at Aspire Health, the founding member of the Jawbone data science team, and lead data scientist at Massive Health. Abe has been leading teams using data and technology to solve problems in health care, consumer wellness, and public policy for over a decade. Abe earned his PhD at the University of Michigan in Public Policy, Political Science, and Complex Systems. He speaks and writes regularly on data, healthcare, and data ethics.
|
|
|
|
"Data Quality Check In Machine Learning"
The world of data quality check in Machine Learning is expanding at an unimaginable pace. Researchers estimate that by 2020, every human would create 1.7MB of information each second. The true power of data can be unlocked when it is refined and transformed into a high quality state where we can realize its true potential. Many businesses and researchers believe that data quality is one of the primary concerns for data-driven enterprises and associated processes considering the pace of data growth. Most of the operational processes and analytics rely on good quality data for being efficient and consistent in output.Data quality process has evolved in its capacity but the demand for pace and efficiency has been proliferating extensively. Data management experts believe that data quality remains a bottleneck that creeps repeatedly to bother the data management and business fraternity due to proliferating data volumes and the complexity involved to derive quality insights. Innovative technologies such as Big Data, AI, ML etc.ML algorithms can learn from human decision labels in the training datasets and replicate the scenarios in real-time. However, ML algorithms are also prone to biases that may reflect in these data sets and are learnt through fresh data sets. These biases could lead to erosion of data quality. External validity testing and audits on a regular basis will help in avoiding such situations.
|
|
|
An Approach to Data Quality for Netflix Personalization Systems
Personalization is one of the key pillars of Netflix as it enables each member to experience the vast collection of content tailored to their interests. Our personalization system is powered by several machine learning models. These models are only as good as the data that is fed to them. They are trained using hundreds of terabytes of data everyday, that make it a non-trivial challenge to track and maintain data quality. To ensure high data quality, we require three things: automated monitoring of data; visualization to observe changes in the metrics over time; and mechanisms to control data related regressions, wherein a data regression is defined as data loss or distributional shifts over a given period of time. In this talk, we will describe infrastructure and methods that we used to achieve the above: – ‘Swimlanes’ that help us define data boundaries for different environments that are used to develop, evaluate and deploy ML models, – Pipelines that aggregate data metrics from various sources within each swimlane – Time series and dashboard visualization tools across an atypically larger period of time – Automated audits that periodically monitor these metrics to detect data regressions. We will explain how we run aggregation jobs to optimize metric computations, SQL queries to quickly define/test individual metrics and other ETL jobs to power the visualization/audits tools using Spark.’ About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business. Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc
|
|
|
|
Data Quality: AI Ups the Ante
Dataiku Any sound data science pipeline prioritizes gathering clean, trusted, and accessible data before diving into a machine learning project. Ensuring quality data also inspires trust and promotes adoption of data-driven practices. How do you ensure your data checks these boxes? Find out in this webinar with GigaOm Researc
|
|
Sourcing Data
YouTube search...
...Google search

|
Data Sourcing: Foundations of Data Science, Part 2
datalabcc Data science can't happen without the raw material of data. This course provides a concise overview of the range of methods available for gathering existing data and creating new data for data science projects. (mini-course)
|
|
|
|
The inner layer research methods -data sourcing
Adina Dudau
|
|
Data Cleaning
YouTube search...
...Google search
When it comes to utilizing ML data, most of the time is spent on cleaning data sets or creating a dataset that is free of errors. Setting up a quality plan, filling missing values, removing rows, reducing data size are some of the best practices used for data cleaning in Machine Learning. Data Cleaning in Machine Learning: Best Practices and Methods | Smishad Thomas
Overall, incorrect data is either removed, corrected, or imputed... The Ultimate Guide to Data Cleaning | Omar Elgabry - Towards Data Science
- Irrelevant data - are those that are not actually needed, and don’t fit under the context of the problem we’re trying to solve.
- Duplicates - are data points that are repeated in your dataset.
- Type conversion - Make sure numbers are stored as numerical data types. A date should be stored as a date object, or a Unix timestamp (number of seconds), and so on. Categorical values can be converted into and from numbers if needed.
- Syntax errors:
- Remove extra white spaces
- Pad strings - Strings can be padded with spaces or other characters to a certain width
- Fix typos - Strings can be entered in many different ways
- Standardize format
- Scaling / Transformation - scaling means to transform your data so that it fits within a specific scale, such as 0–100 or 0–1.
- Normalization - also rescales the values into a range of 0–1, the intention here is to transform the data so that it is normally distributed.
- Missing values:
- Drop - If the missing values in a column rarely happen and occur at random, then the easiest and most forward solution is to drop observations (rows) that have missing values.
- Impute - It means to calculate the missing value based on other observations.
- Flag
- Outliers - They are values that are significantly different from all other observations...they should not be removed unless there is a good reason for that.
- In-record & cross-datasets errors - result from having two or more values in the same row or across datasets that contradict with each other.
|
Machine Learning Tutorial 11 - Cleaning Bad Data
Best Machine Learning book: https://amzn.to/2MilWH0 (Fundamentals Of Machine Learning for Predictive Data Analytics). Machine Learning and Predictive Analytics. #MachineLearning One of the processes in machine learning is data cleaning. This is the process of eliminating bad data and performing the needed transformations to make our data suitable for a machine learning algorithm. This online course covers big data analytics stages using machine learning and predictive analytics. Big data and predictive analytics is one of the most popular applications of machine learning and is foundational to getting deeper insights from data. Starting off, this course will cover machine learning algorithms, supervised learning, data planning, data cleaning, data visualization, models, and more. This self paced series is perfect if you are pursuing an online computer science degree, online data science degree, online artificial intelligence degree, or if you just want to get more machine learning experience. Enjoy!
|
|
|
|
Machine Learning Tutorial 12 - Cleaning Missing Values (NULL)
Best Machine Learning book: https://amzn.to/2MilWH0 (Fundamentals Of Machine Learning for Predictive Data Analytics). Machine Learning and Predictive Analytics. #MachineLearning One of the processes in machine learning is data cleaning. This video deals specifically with missing values.
This online course covers big data analytics stages using machine learning and predictive analytics. Big data and predictive analytics is one of the most popular applications of machine learning and is foundational to getting deeper insights from data. Starting off, this course will cover machine learning algorithms, supervised learning, data planning, data cleaning, data visualization, models, and more. This self paced series is perfect if you are pursuing an online computer science degree, online data science degree, online artificial intelligence degree, or if you just want to get more machine learning experience. Enjoy!
|
|
|
Missing data in various features:Data cleaning and understanding | Applied AI Course
In this video lets see how to deal with missing values. Applied AI course (AAIC Technologies Pvt. Ltd.) is an Ed-Tech company based out in Hyderabad offering on-line training in Machine Learning and Artificial intelligence. Applied AI course through its unparalleled curriculum aims to bridge the gap between industry requirements and skill set of aspiring candidates by churning out highly skilled machine learning professionals who are well prepared to tackle real world business problems. For More information Please visit https://www.appliedaicourse.com/
|
|
|
|
Data Cleaning and Normalization
Sundog Education with Frank Kane Cleaning your raw input data is often the most important, and time-consuming, part of your job as a data scientist!
|
|
Data Encoding
YouTube search...
...Google search
To use categorical data for machine classification, you need to encode the text labels into another form. There are two common encodings.
- One is label encoding, which means that each text label value is replaced with a number.
- The other is one-hot encoding, which means that each text label value is turned into a column with a binary value (1 or 0). Most machine learning frameworks have functions that do the conversion for you. In general, one-hot encoding is preferred, as label encoding can sometimes confuse the machine learning algorithm into thinking that the encoded column is ordered. Machine learning algorithms explained | Martin Heller - InfoWorld
|
Machine Learning Tutorial Python - 6: Dummy Variables & One Hot Encoding
Machine learning models work very well for dataset having only numbers. But how do we handle text information in dataset? Simple approach is to use interger or label encoding but when categorical variables are nominal, using simple label encoding can be problematic. One hot encoding is the technique that can help in this situation. In this tutorial, we will use pandas get_dummies method to create dummy variables that allows us to perform one hot encoding on given dataset. Alternatively we can use sklearn.preprocessing OneHotEncoder as well to create dummy variables. How to handle text data in machine learning model? Nominal vs Ordinal Variables Theory (Explain one hot encoding using home prices in different townships) Coding (Start) Pandas get_dummies method Create a model that uses dummy columns
Label Encoder fit_transform() method sklearn OneHotEncoder Exercise (To predict prices of car based on car model, age, mileage)
|
|
|
|
How To Encode Categorical Data in a CSV Dataset | Python | Machine Learning
Machine learning models deal with mathematical equations and numbers, so categorical data which are mostly strings needs to encoded in numbers. In this video, we discuss what one-hot encoding is, how this encoding is used in machine learning and artificial neural networks, and what is meant by having one-hot encoded vectors as labels for our input data. Welcome to DEEPLIZARD - Go to deeplizard.com for learning resources Collective Intelligence and the DEEPLIZARD HIVEMIND
|
|
|
One-hot Encoding explained
Machine learning models work very well for dataset having only numbers. But how do we handle text information in dataset? Simple approach is to use interger or label encoding but when categorical variables are nominal, using simple label encoding can be problematic. One hot encoding is the technique that can help in this situation. In this tutorial, we will use pandas get_dummies method to create dummy variables that allows us to perform one hot encoding on given dataset. Alternatively we can use sklearn.preprocessing OneHotEncoder as well to create dummy variables.
|
|
|
|
How to implement One Hot Encoding on Categorical Data | Dummy Encoding | Machine Learning | Python
Label encoding encodes categories to numbers in a data set that might lead to comparisons between the data , to avoid that we use one hot encoding
|
|
Data Augmentation, Data Labeling, and Auto-Tagging
Youtube search...
...Google search
Data augmentation is the process of using the data you currently have and modifying it in a realistic but randomized way, to increase the variety of data seen during training. As an example for images, slightly rotating, zooming, and/or translating the image will result in the same content, but with a different framing. This is representative of the real-world scenario, so will improve the training. It's worth double-checking that the output of the data augmentation is still realistic. To determine what types of augmentation to use, and how much of it, do some trial and error. Try each augmentation type on a sample set, with a variety of settings (e.g. 1% translation, 5% translation, 10% translation) and see what performs best on the sample set. Once you know the best setting for each augmentation type, try adding them all at the same time. | Deep Learning Course Wiki
Note: In Keras, we can perform transformations using ImageDataGenerator.

|
Data Augmentation | Kaggle
The 5th video in the deep learning series at kaggle.com/learn/deep-learning
|
|
|
|
Data augmentation with Keras
In this episode, we demonstrate how to implement data augmentation techniques with TensorFlow's Keras API to augment image data.
|
|
|
Data Augmentation explained
In this video, we explain the concept of data augmentation, as it pertains to machine learning and deep learning. We also point to another resource to show how to implement data augmentation on images in code with Keras.
|
|
|
|
The 5th video in the deep learning series at kaggle.com/learn/deep-learning
Kaggle is the world's largest community of data scientists.
|
|
|
FastAI Webinar Series: Part 5 - Training with Data Augmentation
Aakash N S Code
|
|
|
|
YOW! Data 2018 - Atif Rahman - Privacy Preserved Data Augmentation #YOWData
Enterprises hold data that has potential value outside their own firewalls. We have been trying to figure out how to share such data at a level of detail with others in a secure, safe, legal and risk mitigated manner that ensure high level of privacy while adding tangible economic and social value. Enterprises are facing numerous roadblocks, failed projects, inadequate business cases, and issues of scale that needs newer techniques, technology and approach. In this talk, we will be setup the groundwork for scalable data augmentation for organizations and visualizing technical architectures and solutions around emerging technologies of data fabrics, edge computing and a second coming of data virtualisation. A self-assessment toolkit will be shared for people interested to apply it to their organizations.
|
|
Data augmentation adds value to base data by adding information derived from internal and external sources within an enterprise. Data is one of the core assets for an enterprise, making data management essential. Data augmentation can be applied to any form of data, but may be especially useful for customer data, sales patterns, product sales, where additional information can help provide more in-depth insight. Data augmentation can help reduce the manual intervention required to developed meaningful information and insight of business data, as well as significantly enhance data quality.
Data augmentation is of the last steps done in enterprise data management after monitoring, profiling and integration. Some of the common techniques used in data augmentation include:
- Extrapolation Technique: Based on heuristics. The relevant fields are updated or provided with values.
- Tagging Technique: Common records are tagged to a group, making it easier to understand and differentiate for the group.
- Aggregation Technique: Using mathematical values of averages and means, values are estimated for relevant fields if needed
- Probability Technique: Based on heuristics and analytical statistics, values are populated based on the probability of events.
Data Labeling
Youtube search...
...Google search
Labeling typically takes a set of unlabeled data and augments each piece of that unlabeled data with meaningful tags that are informative. Wikipedia
Automation has put low-skill jobs at risk for decades. And self-driving cars, robots, and Speech Recognition will continue the trend. But, some experts also see new opportunities in the automated age. ...the curation of data, where you take raw data and you clean it up and you have to kind of organize it for machines to ingest Is 'data labeling' the new blue-collar job of the AI era? | Hope Reese - TechRepublic
|
How 'AI Farms' Are At The Forefront Of China's Global Ambitions | TIME
As China’s economy slows and rising wages make manufacturing less competitive, the ruling Chinese Communist Party (CCP) is turning to technology to arrest the slide. Strategic technologies such as AI are a key focus.
Subscribe to TIME https://po.st/SubscribeTIME
|
|
|
|
China’s Big AI Advantage: Humans
Seemingly “intelligent” devices like self-driving trucks aren’t actually all that intelligent. In order to avoid plowing into other cars or making illegal lane changes, they need a lot of help. In China, that help is increasingly coming from rooms full of college students. Li Zhenwei is a data labeler. His job, which didn’t even exist a few years ago, involves sitting at a computer, clicking frame-by-frame through endless hours of dashcam footage, and drawing lines over each photo to help the computer recognize lane markers. “Every good-looking field has people working behind the scenes,” says Li. “I'd prefer to be an anonymous hero.”
|
|
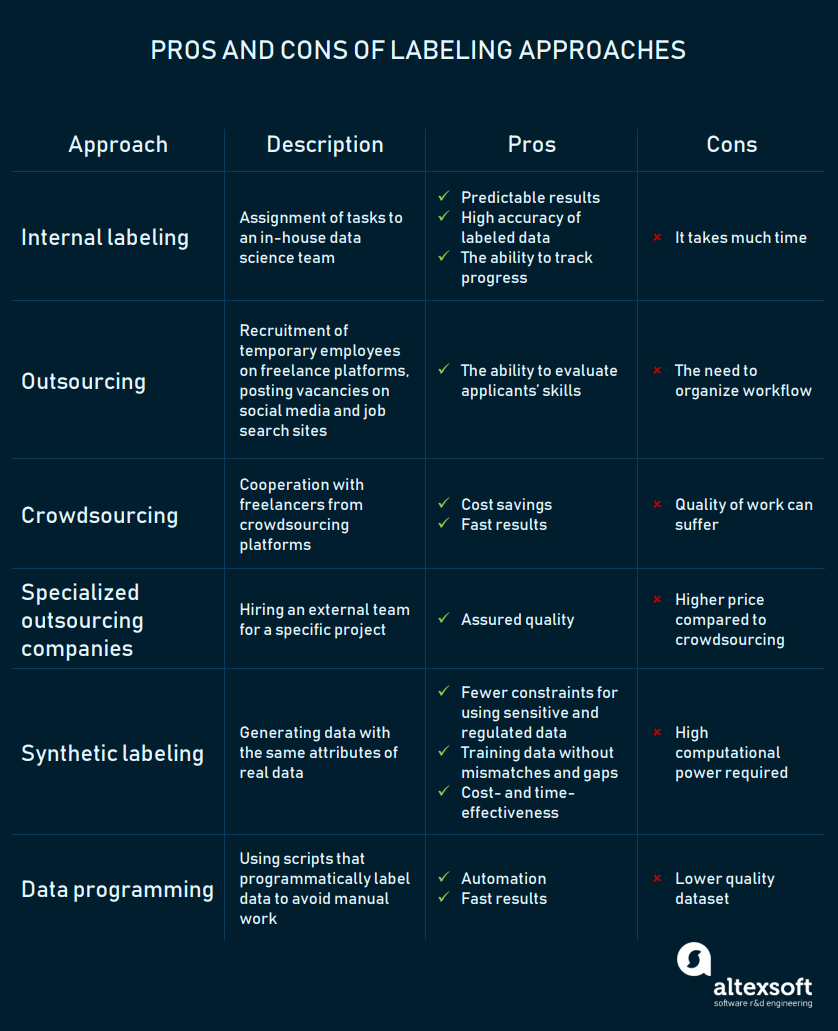
Auto-tagging
Youtube search...
...Google search
- ...predict categories (classification)
- Natural Language Processing (NLP)#Summarization / Paraphrasing
- Natural Language Tools & Services for Text labeling
- Image and video labeling:
- Annotorious the MIT-licensed free web image annotation and labeling tool. It allows for adding text comments and drawings to images on a website. The tool can be easily integrated with only two lines of additional code.
- OpenSeadragon An open-source, web-based viewer for high-resolution zoomable images, implemented in pure JavaScript, for desktop and mobile.
- LabelMe open online tool. Software must assist users in building image databases for computer vision research, its developers note. Users can also download the MATLAB toolbox that is designed for working with images in the LabelMe public dataset.
- Sloth allows users to label image and video files for computer vision research. Face recognition is one of Sloth’s common use cases.
- Object Tagging Tool (VoTT) labeling is one of the model development stages that VoTT supports. This tool also allows data scientists to train and validate object detection models.
- Labelbox build computer vision products for the real world. A complete solution for your training data problem with fast labeling tools, human workforce, data management, a powerful API and automation features.
- Alp’s Labeling Tool macro code allows easy labeling of images, and creates text files compatible with Detectnet / KITTI dataset format.
- imglab graphical tool for annotating images with object bounding boxes and optionally their part locations. Generally, you use it when you want to train an object detector (e.g. a face detector) since it allows you to easily create the needed training dataset.
- VGG Image Annotator (VIA) simple and standalone manual annotation software for image, audio and video
- Demon image annotation plugin allows you to add textual annotations to images by select a region of the image and then attach a textual description, the concept of annotating images with user comments. Integration with JQuery Image Annotation
- FastAnnotationTool (FIAT) enables image data annotation, data augmentation, data extraction, and result visualisation/validation.
- RectLabel an image annotation tool to label images for bounding box object detection and segmentation.
- Audio labeling:
- Snorkel a Python library to help you label data for supervised machine learning tasks
- Praat free software for labeling audio files, mark timepoints of events in the audio file and annotate these events with text labels in a lightweight and portable TextGrid file.
- Speechalyzer a tool for the daily work of a 'speech worker'. It is optimized to process large speech data sets with respect to transcription, labeling and annotation.
- EchoML tool for audio file annotation. It allows users to visualize their data.
|
Automatic tagging of short texts with scikit-learn and NLTK - Gilbert François Duivesteijn
Automatic tagging of short text messages with NLTK and scikit-learn, applicable to all kind of short messages, like email subjects, tweets, or as demonstrated in this hands-on tutorial, Slack messages. The tutorial will show step by step how to do automated tagging of short texts, enabling the analyst to structure the data and get meaningful statistics. www.pydata.org
|
|
|
|
Kaggle Meetup: Audio Tagging
ecording of this meetup where Matt walks us through the Audio Tagging competition.
|
|
|
Automated Tag prediction for Stack Overflow Questions
In our project we implemented a Multi-Label Classifier to predict a set of tags for questions posted on Stack Overflow website. Using One-Vs-Rest approach and Support Vector Machine with linear kernel, we reached a peak accuracy of 62%.
|
|
|
|
"Search Logs + Machine Learning = Auto-Tagged Inventory" - John Berryman (Pyohio 2019)
For e-commerce applications, matching users with the items they want is the name of the game. If they can't find what they want then how can they buy anything?! Typically this functionality is provided through search and browse experience. Search allows users to type in text and match against the text of the items in the inventory. Browse allows users to select filters and slice-and-dice the inventory down to the subset they are interested in. But with the shift toward mobile devices, no one wants to type anymore - thus browse is becoming dominant in the e-commerce experience. But there's a problem! What if your inventory is not categorized? Perhaps your inventory is user generated or generated by external providers who don't tag and categorize the inventory. No categories and no tags means no browse experience and missed sales. You could hire an army of taxonomists and curators to tag items - but training and curation will be expensive. You can demand that your providers tag their items and adhere to your taxonomy - but providers will buck this new requirement unless they see obvious and immediate benefit. Worse, providers might use tags to game the system - artificially placing themselves in the wrong category to drive more sales. Worst of all, creating the right taxonomy is hard. You have to structure a taxonomy to realistically represent how your customers think about the inventory.
|
|
Synthetic Labeling
This approach entails generating data that imitates real data in terms of essential parameters set by a user. Synthetic data is produced by a generative model that is trained and validated on an original dataset. There are three types of generative models: (1) Generative Adversarial Network (GAN); generative/discriminative, (2) Autoregressive models (ARs); previous values, and (3) Variational Autoencoder (VAE); encoding/decoding.
|
Active Learning: Why Smart Labeling is the Future of Data Annotation | Alectio
Today, with always more data at their fingertips, Machine Learning experts seem to have no shortage of opportunities to create always better models. Over and over again, research has proven that both the volume and quality of the training data is what differentiates good models from the highest performing ones. But with an ever-increasing volume of data, and with the constant rise of data-greedy algorithms such as Deep Neural Networks, it is becoming challenging for data scientists to get the volume of labels they need at the speed they need, regardless of their budgetary and time constraints. To address this “Big Data labeling crisis”, most data labeling companies offer solutions based on semi-automation, where a machine learning algorithm predicts labels before this labeled data is sent to an annotator so that he/she can review the results and validate their accuracy. There is a radically different approach to this problem which focuses on labeling “smarter” rather than labeling faster. Instead of labeling all of the data, it is usually possible to reach the same model accuracy by labeling just a fraction of the data, as long as the most informational rows are labeled. Active Learning allows data scientists to train their models and to build and label training sets simultaneously in order to guarantee the best results with the minimum number of labels. ABOUT THE SPEAKER: Jennifer Prendki is currently the VP of Machine Learning at Figure Eight, the essential human-in-the-loop AI platform for data science and machine learning teams. She has spent most of her career creating a data-driven culture wherever she went, succeeding in sometimes highly skeptical environments. She is particularly skilled at building and scaling high-performance Machine Learning teams, and is known for enjoying a good challenge. Trained as a particle physicist (she holds a PhD in Particle Physics from Sorbonne University), she likes to use her analytical mind not only when building complex models, but also as part of her leadership philosophy. She is pragmatic yet detail-oriented. Jennifer also takes great pleasure in addressing both technical and non-technical audiences at conferences and seminars, and is passionate about attracting more women to careers in STEM.
|
|
|
|
PyCon.DE 2017 Hendrik Niemeyer - Synthetic Data for Machine Learning Applications
Dr. Hendrik Niemeyer (@hniemeye) Data Scientist working on predictive analytics with data from pipeline inspection measurements.
Tags: data-science Python machine learning ai In this talk I will show how we use real and synthetic data to create successful models for risk assessing pipeline anomalies. The main focus is the estimation of the difference in the statistical properties of real and generated data by machine learning methods. ROSEN provides predictive analytics for pipelines by detecting and risk assessing anomalies from data gathered by inline inspection measurement devices. Due to budget reasons (pipelines need to be dug up to get acess) ground truth data for machine learning applications in this field are usually scarce, imbalanced and not available for all existing configurations of measurement devices. This creates the need for synthetic data (using FEM simulations and unsupervised learning algorithms) in order to be able to create successful models. But a naive mixture of real-world and synthetic samples in a model does not necessarily yield to an increased predictive performance because of differences in the statistical distributions in feature space. I will show how we evaluate the use of synthetic data besides simple visual inspection. Manifold learning (e.g. TSNE) can be used to gain an insight whether real and generated data are inherently different. Quantitative approaches like classifiers trained to discriminate between these types of data provide a non visual insight whether a "synthetic gap" in the feature distributions exists. If the synthetic data is useful for model building careful considerations have to be applied when constructing cross validation folds and test sets to prevent biased estimates of the model performance. Recorded at PyCon.DE 2017 Karlsruhe: pycon.de Video editing: Sebastian Neubauer & Andrei Dan Tools: Blender, Avidemux & Sonic Pi
|
|
Batch Norm(alization) & Standardization
Youtube search...
...Google search
To use numeric data for machine regression, you usually need to normalize the data. Otherwise, the numbers with larger ranges may tend to dominate the Euclidian distance between feature vectors, their effects can be magnified at the expense of the other fields, and the steepest descent optimization may have difficulty converging. There are a number of ways to normalize and standardize data for ML, including min-max normalization, mean normalization, standardization, and scaling to unit length. This process is often called feature scaling. Machine learning algorithms explained | Martin Heller - InfoWorld
When feeding data into a machine learning model, the data should usually be "normalized". This means scaling the data so that it has a mean and standard deviation within "reasonable" limits. This is to ensure the objective functions in the machine learning model will work as expected and not focus on a specific feature of the input data. Without normalizing inputs the model may be extremely fragile. Batch normalization is an extension of this concept. Instead of just normalizing the data at the input to the neural network, batch normalization adds layers to allow normalization to occur at the input to each convolutional layer. | Deep Learning Course Wiki
Batch Norm is a normalization method that normalizes Activation Functions in a network across the mini-batch. For each feature, batch normalization computes the mean and variance of that feature in the mini-batch. It then subtracts the mean and divides the feature by its mini-batch standard deviation.
The benefits of using batch normalization (batch norm) are:
- Improves gradient flow through the network
- Allows higher learning rates
- Reduces the strong dependence on initialization
- Acts as a form of regularization
Batch normalization has two elements:
- Normalize the inputs to the layer. This is the same as regular feature scaling or input normalization.
- Add two more trainable parameters. One for a gradient and one for an offset that apply to each of the activations. by adding these parameters, the normalization can effectively be completely undone, using the gradient and offset. This allows the back propagation process to completely ignore the back normalization layer if it wants to.
Good practices for addressing Overfitting Challenge:
|
Batch Normalization (“batch norm”) explained
et's discuss batch normalization, otherwise known as batch norm, and show how it applies to training artificial neural networks. We also briefly review general normalization and standardization techniques, and we then see how to implement batch norm in code with Keras.
|
|
|
|
Normalization and Standardization
Simple introduction to price transformations such as normalization and standardization.
|
|
Data Completeness
Youtube search...
...Google search
|
Yali Sassoon - How do you build assurance in the accuracy and completeness of your data?
Whilst the growth in AI and real-time data processing have created new opportunities for companies to use data to drive competitive advantage, seizing these opportunities is only possible if companies have an accurate and complete data set to begin with. In this session you will discover how the need for accurate and complete data is growing and only going to continue to grow, what happens when organisations lose confidence in the validity of their data, before exploring a practical range of approaches and techniques employed by companies to build assurance in their data sets, with a particular focus on customer data.
|
|
|
|
Data Quality: Completeness
This is episode 7 of Dataverax, which describes the data quality dimension of completeness.
|
|
Zero Padding
Youtube search...
...Google search
|
Zero Padding in Convolutional Neural Networks explained
Let's start out by explaining the motivation for zero padding and then we get into the details about what zero padding actually is. We then talk about the types of issues we may run into if we don’t use zero padding, and then we see how we can implement zero padding in code using Keras. We build on some of the ideas that we discussed in our video on Convolutional Neural Networks, so if you haven’t seen that yet, go ahead and check it out, and then come back to watch this video once you’ve finished up there. https://youtu.be/YRhxdVk_sIs
|
|
|
|
Imbalanced Data
Youtube search...
...Google search
What is imbalanced data? The definition of imbalanced data is straightforward. A dataset is imbalanced if at least one of the classes constitutes only a very small minority. Imbalanced data prevail in banking, insurance, engineering, and many other fields. It is common in fraud detection that the imbalance is on the order of 100 to 1. ... The issue of class imbalance can result in a serious bias towards the majority class, reducing the classification performance and increasing the number of false negatives. How can we alleviate the issue? The most commonly used techniques are data resampling either under-sampling the majority of the class, or over-sampling the minority class, or a mix of both. | Dataman
Classification algorithms tend to perform poorly when data is skewed towards one class, as is often the case when tackling real-world problems such as fraud detection or medical diagnosis. A range of methods exist for addressing this problem, including re-sampling, one-class learning and cost-sensitive learning. | Natalie Hockham
|
Natalie Hockham: Machine learning with imbalanced data sets
Classification algorithms tend to perform poorly when data is skewed towards one class, as is often the case when tackling real-world problems such as fraud detection or medical diagnosis. A range of methods exist for addressing this problem, including re-sampling, one-class learning and cost-sensitive learning. This talk looks at these different approaches in the context of fraud detection.
|
|
|
|
Machine Learning - Over-& Undersampling - Python/ Scikit/ Scikit-Imblearn
In this video I will explain you how to use Over- & Undersampling with machine learning using Python, scikit and scikit-imblearn. The concepts shown in this video will show you what Over-and Undersampling is and how to correctly use it even when cross-validating. So let's go!
|
|
|
Tutorial 44-Balanced vs Imbalanced Dataset and how to handle Imbalanced Dataset
Here is a detailed explanation about the balanced vs imbalanced dataset and how to handle the imbalanced dataset.
|
|
|
|
Sampling Techniques for Handling Imbalanced Datasets
We will discuss various sampling methods used to address issues that arise when working with imbalanced datasets, then take a deep dive into SMOTE.
|
|
|
Applied Machine Learning 2019 - Lecture 11 - Imbalanced data
Undersampling, oversampling, SMOTE, Easy Ensembles
|
|
|
|
Ajinkya More | Resampling techniques and other strategies
PyData SF 2016 Ajinkya More | Resampling techniques and other strategies for handling highly unbalanced datasets in classification
Many real world machine learning problems need to deal with imbalanced class distribution i.e. when one class has significantly higher/lower representation than the other classes. Often performance on the minority class is more crucial, e.g. fraud detection, product classification, medical diagnosis, etc. In this talk I will discuss several techniques to handle class imbalance in classification.
|
|
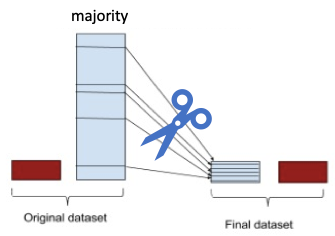
Under-sampling
|
Undersampling for Handling Imbalanced Datasets | Python | Machine Learning
Whenever we do classification in ML, we often assume that target label is evenly distributed in our dataset. This helps the training algorithm to learn the features as we have enough examples for all the different cases. For example, in learning a spam filter, we should have good amount of data which corresponds to emails which are spam and non spam. This even distribution is not always possible. I'll discuss one of the techniques known as Undersampling that helps us tackle this issue. Undersampling is one of the techniques used for handling class imbalance. In this technique, we under sample majority class to match the minority class.
|
|
|
|
Tutorial 45-Handling imbalanced Dataset using Python - Part 1
Machine Learning algorithms tend to produce unsatisfactory classifiers when faced with imbalanced datasets. For any imbalanced data set, if the event to be predicted belongs to the minority class and the event rate is less than 5%, it is usually referred to as a rare even.
|
|
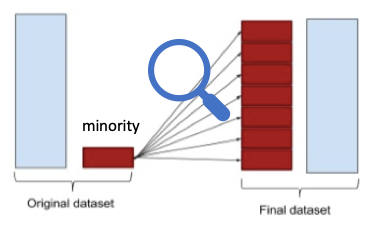
Over-sampling
|
SMOTE - Synthetic Minority Oversampling Technique
This is part of the Data Science course on Udemy. In this lecture, we cover the intuition behind SMOTE or Synthetic Minority Oversampling Technique for dealing with the Imbalanced Dataset.
|
|
|
|
Tutorial 46-Handling imbalanced Dataset using Python- Part 2
Machine Learning algorithms tend to produce unsatisfactory classifiers when faced with imbalanced datasets. For any imbalanced data set, if the event to be predicted belongs to the minority class and the event rate is less than 5%, it is usually referred to as a rare even
|
|
Skewed Data
Youtube search...
"Skewed+Data"+artificial+intelligence ...Google search
|
Lecture 11.3 — Machine Learning System Design | Error Metrics For Skewed Classes — Creatives#Andrew Ng
Artificial Intelligence - All in One
|
|
|
|
Feature Engineering-How to Transform Data to Better Fit The Gaussian Distribution-Data Science
Some machine learning models like linear and logistic regression assume that the variables are normally distributed. Others benefit from "Gaussian-like" distributions, as in such distributions the observations of X available to predict Y vary across a greater range of values. Thus, Gaussian distributed variables may boost the machine learning algorithm performance.
|
|
|
Log Transformation for Outliers | Convert Skewed data to Normal Distribution
This video titled "Log Transformation for Outliers | Convert Skewed data to Normal Distribution" explains how to use Log Transformation for treating Outliers as well as using Log Transformation for Converting Positive Skewed data to Normal Distribution form. Code example in Python is also covered in the video. This is a machine learning & deep learning Bootcamp series of data science. You will also get some flavor of data engineering as well in this Bootcamp series. Through this series, you will be able to learn each aspect of the Data science lifecycle right from collecting data from disparate data sources, data preprocessing to doing visualization as well as model deployment in production. You will also see how to perform data preprocessing and build, regression, classification, clustering as well as a recurrent neural network, convolution neural network, autoencoders, etc. Through this series, you will be able to learn everything pertaining to Machine and Deep Learning in one place. Content & Playlist will be updated regularly to add videos with new topics.
|
|
|
|
Working with Skewed Data: The Iterative Broadcast - Rob Keevil & Fokko Driesprong
"Skewed data is the enemy when joining tables using Spark. It shuffles a large proportion of the data onto a few overloaded nodes, bottlenecking Spark's parallelism and resulting in out of memory errors. The go-to answer is to use broadcast joins; leaving the large, skewed dataset in place and transmitting a smaller table to every machine in the cluster for joining. But what happens when your second table is too large to broadcast, and does not fit into memory? Or even worse, when a single key is bigger than the total size of your executor? Firstly, we will give an introduction into the problem. Secondly, the current ways of fighting the problem will be explained, including why these solutions are limited. Finally, we will demonstrate a new technique - the iterative broadcast join - developed while processing ING Bank's global transaction data. This technique, implemented on top of the Spark SQL API, allows multiple large and highly skewed datasets to be joined successfully, while retaining a high level of parallelism. This is something that is not possible with existing Spark join types. Session hashtag: #EUde11" About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business. Website: https://databricks.com
|
|
Data Consistency
YouTube search...
...Google search
|
Managing Data Consistency Among Microservices with Debezium - Justin Chao, Optum
The Linux Foundation
|
|
|
|
5 Data Quality Metrics for Big Data #dataquality
As with traditional data, establishing data quality metrics that are aligned with business objectives enables you to quickly uncover data quality issues and establish remediation plans. Accuracy, completeness, validity, consistency, and integrity will still be present with big data, but there are additional 5 data quality metrics to be considered.
|
|