Difference between revisions of "Evaluation - Measures"
m (→Confidence Interval) |
m (→Confidence Interval) |
||
| Line 382: | Line 382: | ||
|}<!-- B --> | |}<!-- B --> | ||
| − | == <span id="Confidence Interval"></span>Confidence Interval == | + | == <span id="Confidence Interval (CI)"></span>Confidence Interval (CI) == |
[http://www.youtube.com/results?search_query='Confidence Interval'+Metric+~bayes+artificial+intelligence+ai YouTube search...] | [http://www.youtube.com/results?search_query='Confidence Interval'+Metric+~bayes+artificial+intelligence+ai YouTube search...] | ||
[http://www.google.com/search?q='Confidence Interval'+Metric+~bayes+artificial+intelligence+ai ...Google search] | [http://www.google.com/search?q='Confidence Interval'+Metric+~bayes+artificial+intelligence+ai ...Google search] | ||
| + | |||
| + | In statistics, a confidence interval (CI) is a type of estimate computed from the statistics of the observed data. This proposes a range of plausible values for an unknown parameter (for example, the mean). The interval has an associated confidence level that the true parameter is in the proposed range. Given observations and a confidence level gamma, a valid confidence interval has a probability gamma of containing the true underlying parameter. The level of confidence can be chosen by the investigator. In general terms, a confidence interval for an unknown parameter is based on sampling the distribution of a corresponding estimator. More strictly speaking, the confidence level represents the frequency (i.e. the proportion) of possible confidence intervals that contain the true value of the unknown population parameter. In other words, if confidence intervals are constructed using a given confidence level from an infinite number of independent sample statistics, the proportion of those intervals that contain the true value of the parameter will be equal to the confidence level. For example, if the confidence level (CL) is 90% then in a hypothetical indefinite data collection, in 90% of the samples the interval estimate will contain the population parameter. The confidence level is designated before examining the data. Most commonly, a 95% confidence level is used. However, confidence levels of 90% and 99% are also often used in analysis. Factors affecting the width of the confidence interval include the size of the sample, the confidence level, and the variability in the sample. A larger sample will tend to produce a better estimate of the population parameter, when all other factors are equal. A higher confidence level will tend to produce a broader confidence interval. | ||
{|<!-- T --> | {|<!-- T --> | ||
| Line 390: | Line 392: | ||
{| class="wikitable" style="width: 550px;" | {| class="wikitable" style="width: 550px;" | ||
|| | || | ||
| − | <youtube> | + | <youtube>tFWsuO9f74o</youtube> |
| − | <b> | + | <b>Understanding Confidence Intervals: Statistics Help |
| − | </b><br> | + | </b><br>Dr. Nic's Maths and Stats This short video gives an explanation of the concept of confidence intervals, with helpful diagrams and examples. A good follow-up to check understanding is the video: Confidence Intervals - a quiz to develop understanding. https://youtu.be/gvVD-xlY2Hc See http://creativemaths.net/videos/ for all of Dr. Nic's videos organized by topic. |
|} | |} | ||
|<!-- M --> | |<!-- M --> | ||
| Line 398: | Line 400: | ||
{| class="wikitable" style="width: 550px;" | {| class="wikitable" style="width: 550px;" | ||
|| | || | ||
| − | <youtube> | + | <youtube>TqOeMYtOc1w</youtube> |
| − | <b> | + | <b>StatQuest: Confidence Intervals |
| − | </b><br> | + | </b><br>StatQuest with Josh Starmer A StatQuest http://statquest.org/ for Confidence Intervals. For a complete index of all the StatQuest videos, check out: http://statquest.org/video-index/ |
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
Revision as of 11:43, 12 October 2020
YouTube search... ...Google search
- Evaluation
- Data Governance
- Explainable / Interpretable AI
- Train, Validate, and Test
- Model Monitoring
- ML Test Score
- Objective vs. Cost vs. Loss vs. Error Function
- Math for Intelligence
- Metric Learning and Kernel Learning
- Performance Metrics for Classification problems in Machine Learning | Mohammed Sunasra = Medium
- Evaluation Metrics for Machine Learning - Accuracy, Precision, Recall, and F1 Defined | Chris Nicholson - A.I. Wiki pathmind
Confusion Matrix, Precision, Recall, F Score, ROC Curves, trade off between True Positive Rate and False Positive Rate.
Contents
- 1 Overview
- 1.1 Error Metric
- 1.2 Confusion Matrix
- 1.3 Accuracy
- 1.4 Precision & Recall (Sensitivity)
- 1.5 Specificity
- 1.6 F1 Score (F-Measure)
- 1.7 Receiver Operating Characteristic (ROC)
- 1.8 Precision-Recall (PR) curves will be more informative than ROC
- 1.9 Correlation Coefficient
- 1.10 Rationality
- 1.11 P-Value
- 1.12 Confidence Interval (CI)
- 2 Tradeoffs
Overview
|
|
|
|
|
|
Error Metric
Predictive Modeling works on constructive feedback principle. You build a model. Get feedback from metrics, make improvements and continue until you achieve a desirable accuracy. Evaluation metrics explain the performance of a model. An important aspects of evaluation metrics is their capability to discriminate among model results. 7 Important Model Evaluation Error Metrics Everyone should know | Tavish Srivastava
|
|
Confusion Matrix
YouTube search... ...Google search
A performance measurement for machine learning classification - one of the fundamental concepts in machine learning is the Confusion Matrix. Combined with Cross Validation, it's how one decides which machine learning method would be best for a particular dataset. Understanding Confusion Matrix | Sarang Narkhede - Medium

|
|
|
|
Accuracy
YouTube search... ...Google search
The number of correct predictions made by the model over all kinds predictions made.
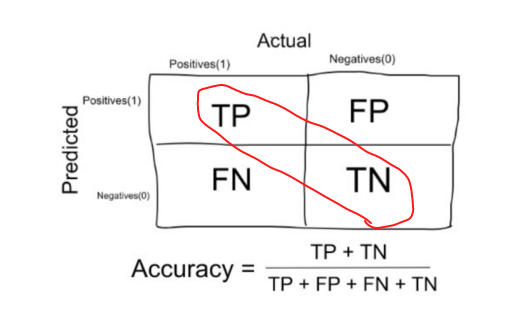
|
|
Precision & Recall (Sensitivity)
YouTube search... ...Google search
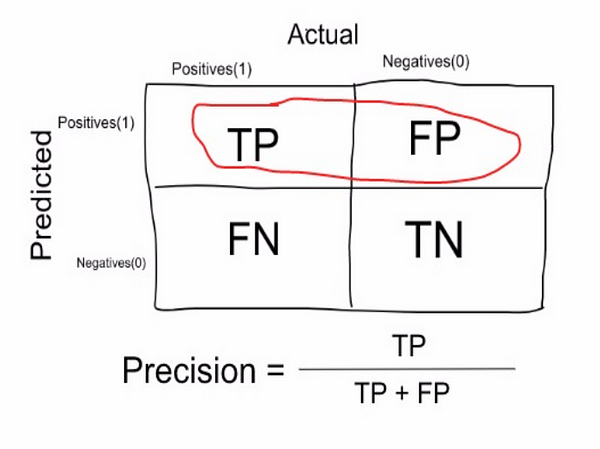
(also called positive predictive value) is the fraction of relevant instances among the retrieved instances, while recall (also known as sensitivity) is the fraction of relevant instances that have been retrieved over the total amount of relevant instances. Both precision and recall are therefore based on an understanding and measure of relevance. Precision and recall | Wikipedia
- Precision: measure that tells us what proportion of patients that we diagnosed as having cancer, actually had cancer. The predicted positives (People predicted as cancerous are TP and FP) and the people actually having a cancer are TP.
- Recall or Sensitivity: measure that tells us what proportion of patients that actually had cancer was diagnosed by the algorithm as having cancer. The actual positives (People having cancer are TP and FN) and the people diagnosed by the model having a cancer are TP. (Note: FN is included because the Person actually had a cancer even though the model predicted otherwise).
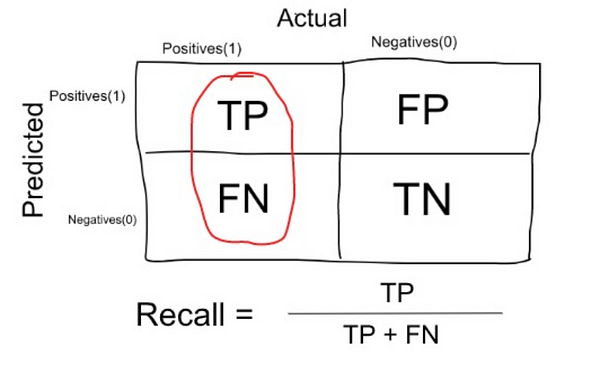
|
|
Specificity
YouTube search... ...Google search
Measure that tells us what proportion of patients that did NOT have cancer, were predicted by the model as non-cancerous. The actual negatives (People actually NOT having cancer are FP and TN) and the people diagnosed by us not having cancer are TN. (Note: FP is included because the Person did NOT actually have cancer even though the model predicted otherwise).
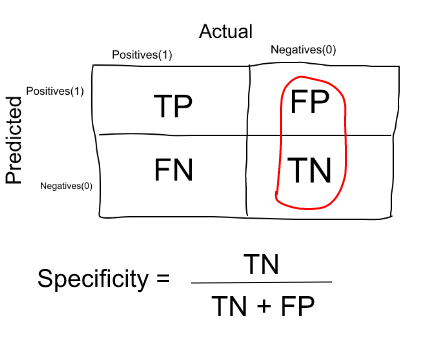
|
F1 Score (F-Measure)
F1 Score = 2 * Precision * Recall / (Precision + Recall)
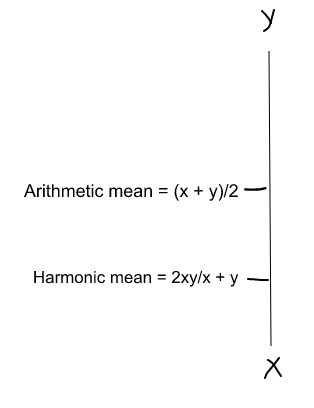
(Harmonic mean) is kind of an average when x and y are equal. But when x and y are different, then it’s closer to the smaller number as compared to the larger number. So if one number is really small between precision and recall, the F1 Score kind of raises a flag and is more closer to the smaller number than the bigger one, giving the model an appropriate score rather than just an arithmetic mean.
|
|
Receiver Operating Characteristic (ROC)
In a ROC curve the true positive rate (Sensitivity) is plotted in function of the false positive rate (100-Specificity) for different cut-off points of a parameter. a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied.
The ROC curve is created by plotting the True Positive Rate (TPR) against the False Positive Rate (FPR) at various threshold settings. The true-positive rate is also known as sensitivity, recall or probability of detection[1] in machine learning. The false-positive rate is also known as probability of false alarm[1] and can be calculated as (1 − specificity). Wikipedia
|
Area Under the Curve (AUC)
The area under the ROC curve ( AUC ) is a measure of how well a parameter can distinguish between two diagnostic groups (diseased/normal).
|
Precision-Recall (PR) curves will be more informative than ROC
The Relationship Between Precision-Recall and ROC Curves | Jesse Davis & Mark Goadrich - University of Wisconsin-Madison proposes that Precision-Recall (PR) curves will be more informative than ROC when dealing with highly skewed datasets. The PR curves plot precision vs. recall (FPR). Because Precision is directly influenced by class imbalance so the Precision-recall curves are better to highlight differences between models for highly imbalanced data sets. When you compare different models with imbalanced settings, the area under the Precision-Recall curve will be more sensitive than the area under the ROC curve. Using Under-Sampling Techniques for Extremely Imbalanced Data | Dataman - Towards Data Science
Correlation Coefficient
- Causation vs. Correlation
- Interpreting Correlations - an interactive visualization | Kristoffer Magnusson - R Psychologist
- NumPy, SciPy, and Pandas: Correlation With Python | Mirko Stojiljković - Real Python
- Intuition on correlation | Sebastian Sauer
- Thirteen Ways to Look at the Correlation Coefficient | Joseph Lee Rodgers and W. Alan Nicewander
A correlation is about how two things change with each other. Knowing about how two things change together is the first step to prediction. The "r value" is a common way to indicate a correlation value. More specifically, it refers to the (sample) Pearson correlation, or Pearson's r. There is more than one way to calculate a correlation. Here we have touched on the case where both variables change at the same way. There are other cases where one variable may change at a different rate, but still have a clear relationship. This gives rise to what's called, non-linear relationships. What is a Correlation Coefficient? The r Value in Statistics Explained | Eric Leung - freeCodeCamp ...Code, Data, Microbiome blog


|
Rationality
|
P-Value
YouTube search... ...Google search
In statistics, every conjecture concerning the unknown probability distribution of a collection of random variables representing the observed data X in some study is called a statistical hypothesis. If we state one hypothesis only and the aim of the statistical test is to see whether this hypothesis is tenable, but not, at the same time, to investigate other hypotheses, then such a test is called a significance test. Note that the hypothesis might specify the probability distribution of X precisely, or it might only specify that it belongs to some class of distributions. Often, we reduce the data to a single numerical statistic T whose marginal probability distribution is closely connected to a main question of interest in the study. A statistical hypothesis that refers only to the numerical values of unknown parameters of the distribution of some statistic is called a parametric hypothesis. A hypothesis which specifies the distribution of the statistic uniquely is called simple, otherwise it is called composite. Methods of verifying statistical hypotheses are called statistical tests. Tests of parametric hypotheses are called parametric tests. We can likewise also have non-parametric hypotheses and non-parametric tests. The p-value is used in the context of null hypothesis testing in order to quantify the idea of statistical significance of evidence, the evidence being the observed value of the chosen statistic T. Null hypothesis testing is a reductio ad absurdum argument adapted to statistics. In essence, a claim is assumed valid if its counterclaim is highly implausible. p-value | Wikipedia
|
|
Confidence Interval (CI)
Interval'+Metric+~bayes+artificial+intelligence+ai YouTube search... Interval'+Metric+~bayes+artificial+intelligence+ai ...Google search
In statistics, a confidence interval (CI) is a type of estimate computed from the statistics of the observed data. This proposes a range of plausible values for an unknown parameter (for example, the mean). The interval has an associated confidence level that the true parameter is in the proposed range. Given observations and a confidence level gamma, a valid confidence interval has a probability gamma of containing the true underlying parameter. The level of confidence can be chosen by the investigator. In general terms, a confidence interval for an unknown parameter is based on sampling the distribution of a corresponding estimator. More strictly speaking, the confidence level represents the frequency (i.e. the proportion) of possible confidence intervals that contain the true value of the unknown population parameter. In other words, if confidence intervals are constructed using a given confidence level from an infinite number of independent sample statistics, the proportion of those intervals that contain the true value of the parameter will be equal to the confidence level. For example, if the confidence level (CL) is 90% then in a hypothetical indefinite data collection, in 90% of the samples the interval estimate will contain the population parameter. The confidence level is designated before examining the data. Most commonly, a 95% confidence level is used. However, confidence levels of 90% and 99% are also often used in analysis. Factors affecting the width of the confidence interval include the size of the sample, the confidence level, and the variability in the sample. A larger sample will tend to produce a better estimate of the population parameter, when all other factors are equal. A higher confidence level will tend to produce a broader confidence interval.
|
|
Tradeoffs
'Precision' & 'Recall'
It is clear that recall gives us information about a classifier’s performance with respect to false negatives (how many did we miss), while precision gives us information about its performance with respect to false positives(how many did we caught).
- Precision is about being precise. So even if we managed to capture only one cancer case, and we captured it correctly, then we are 100% precise.
- Recall is not so much about capturing cases correctly but more about capturing all cases that have “cancer” with the answer as “cancer”. So if we simply always say every case as “cancer”, we have 100% recall.
So basically if we want to focus more on:
- minimising False Negatives, we would want our Recall to be as close to 100% as possible without precision being too bad
- minimising False Positives, then our focus should be to make Precision as close to 100% as possible.

|
|
'Sensitivity' & 'Specificity'
|
|
'True Positive Rate' & 'False Positive Rate'
|
|
Accuracy is not the best measure for Machine Learning
|