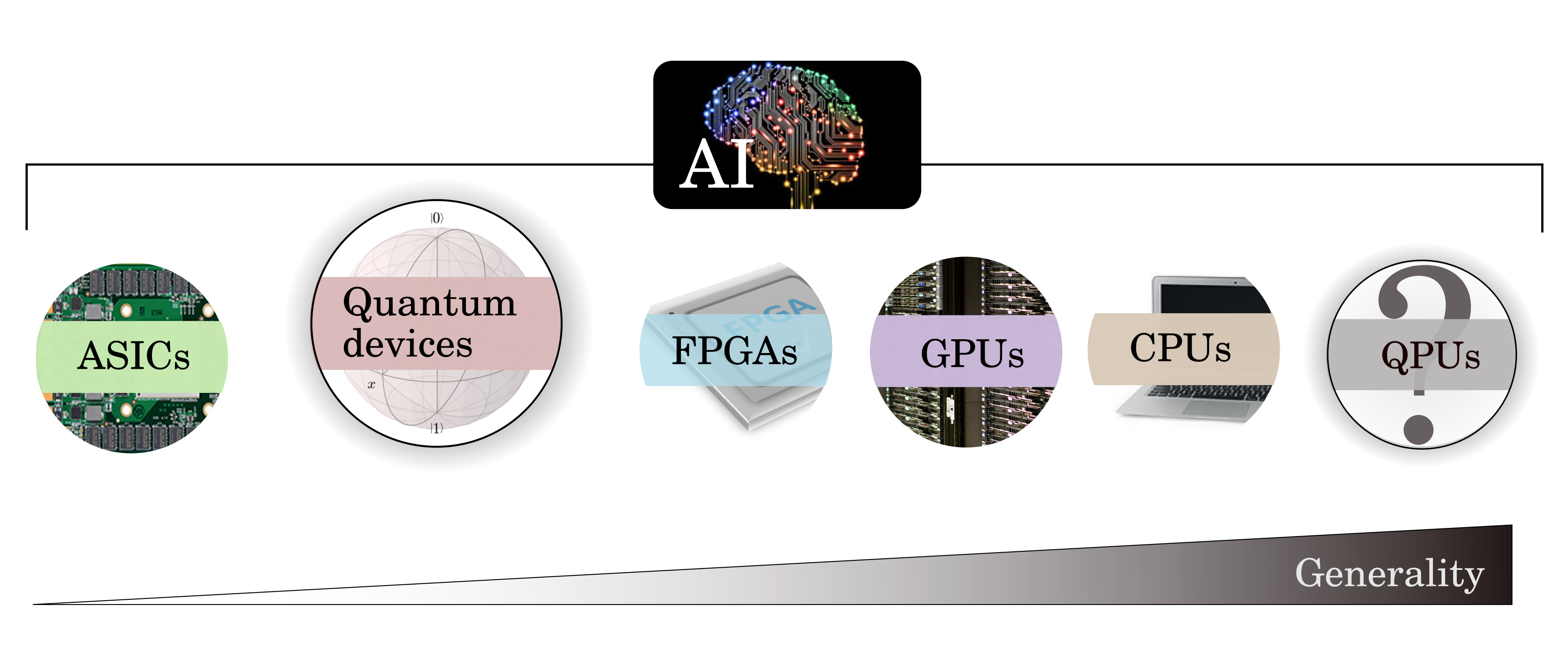
Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU
Youtube search... ...Google search
- Neuromorphic Computing Chips
- Development ... Notebooks ... AI Pair Programming ... Codeless ... Hugging Face ... AIOps/MLOps ... AIaaS/MLaaS
- Architectures for AI ... Generative AI Stack ... Enterprise Architecture (EA) ... Enterprise Portfolio Management (EPM) ... Architecture and Interior Design
- NVIDIA
- Time ... PNT ... GPS ... Retrocausality ... Delayed Choice Quantum Eraser ... Quantum
- NVIDIA A100 HPC (High-Performance Computing) Accelerator for ChatGPT
- AI accelerator | Wikipedia
- CPUs, GPUs, and Now AI Chips
- Moore’s Law Is Dying. This Brain-Inspired Analogue Chip Is a Glimpse of What’s Next | Shelly Fan
- Artificial Intelligence Is Driving A Silicon Renaissance | Rob Toews - Forbes
- MIT’s Tiny New Brain Chip Aims for AI in Your Pocket | Jason Dorrier - SingularityHub ... Alloying conducting channels for reliable neuromorphic computing | H. Yeon, P. Lin, C. Choi, S. Tan, Y. Park, D. Lee, J. Lee, F. Xu, B. Gao, H. Wu, H. Qian, Y. Nie, S. Kim & J. Kim - Nature Nanotechnology
- NVIDIA Faces a Tough New Rival in Artificial Intelligence Chips | Leo Sun - The Motley Fool
- New Chip Expands the Possibilities for AI | Allison Whitten - QuantaMagazine... an energy-efficient chip called NeuRRAM operating in an analog fashion to save more energy and space.
- AI Accelerators and Machine Learning Algorithms: Co-Design and Evolution | Shashank Prasanna - Medium ... Efficient algorithms and methods in machine learning for AI accelerators — NVIDIA GPUs, Intel Habana Gaudi and AWS Trainium and Inferentia
- Chips and Science Act ... a U.S. federal statute enacted by the 117th United States Congress and signed into law by President Joe Biden on August 9, 2022
- Cerebras... Introducing the Cerebras CS-3: the world’s fastest AI accelerator. Built to scale out to 2048 systems, the CS-3 trains trillion parameter models at record speed.
Neural network accelerator chips, also known as AI accelerators, are specialized hardware designed to accelerate machine learning computations. They are often manycore designs and generally focus on low-precision arithmetic, novel dataflow architectures or in-memory computing capability. Massively multicore scalar processors, also known as superscalar processors, are a type of AI accelerator that uses a large number of simple processing cores to execute different types of algorithms. Scalar processing is at the heart of this hardware accelerator. One of the advantages of these hardware components is that they use simple arithmetic units that can be combined in various ways to execute different types of algorithms. Another advantage of massively multicore scalar processors is that they are highly scalable. Different types of processors are suited for different types of machine learning models. TPUs are well suited for Convolutional Neural Network (CNN), while GPUs have benefits for some fully-connected Neural Networks, and CPUs can have advantages for Recurrent Neural Network (RNN)s.
Contents
- 1 Unit - Heart of AI
- 2 Photonic Integrated Circuit (PIC)
- 3 TinyGPU
Unit - Heart of AI
Central Processing Unit (CPU), Graphical Process Unit (GPU), Associative Processing Unit (APU), Tensor Processing Unit (TPU), Field Programmable Gate Array (FPGA), Vision Processing Unit (VPU), and Quantum Processing Unit (QPU)
GPU - Graphical Process Unit
Youtube search... ...Google search
A Graphics Processing Unit (GPU) is a specialized electronic circuit designed to manipulate and alter memory to accelerate the creation of images in a frame buffer intended for output to a display device. GPUs were originally designed to accelerate the rendering of 3D graphics, but over time they became more flexible and programmable, enhancing their capabilities. This allowed graphics programmers to create more interesting visual effects and realistic scenes with advanced lighting and shadowing techniques. Other developers also began to tap the power of GPUs to dramatically accelerate additional workloads in high performance computing (HPC), deep learning, and more.
GPUs can process many pieces of data simultaneously, making them useful for machine learning, video editing, and gaming applications. GPUs may be integrated into the computer’s CPU or offered as a discrete hardware unit. The latest graphics processing units (GPUs) unlock new possibilities in gaming, content creation, machine learning, and more.
Examples: High-performance NVIDIA T4 and NVIDIA V100 GPUs
APU - Associative Process Unit
Youtube search... ...Google search
An Associative Processing Unit (APU) is a type of AI accelerator that focuses on identification tasks. It is designed to identify patterns in large amounts of data. GSI Technology’s Gemini APU takes associative memory to a new level, bringing greater flexibility and programmability. APUs are similar to associative memories, or ternary content-addressable memory (TCAM), but they are more flexible and programmable. They can handle masking operations and work with variable length words and comparisons. The APU uses a similar structure that combines computation with words in memory.
Ternary Content-Addressable Memory (TCAM) is a type of Content-Addressable Memory (CAM) that can store and search for data in parallel, based on its content rather than its memory address. CAM is also known as associative memory. TCAMs are similar to CAMs, but they can store and search for data using three states: 0, 1, and X (don’t care). TCAMs are used in networking devices where they speed up forwarding information base and routing table operations3. This kind of associative memory is also used in cache memory. In associative cache memory, both address and content are stored side by side. When the address matches, the corresponding content is fetched from cache memory.
Content-Addressable Memory (CAM) is a special type of computer memory used in certain very-high-speed searching applications. It is also known as associative memory or associative storage and compares input search data against a table of stored data, and returns the address of matching data. Unlike standard computer memory, random-access memory (RAM), in which the user supplies a memory address and the RAM returns the data word stored at that address, a CAM is designed such that the user supplies a data word and the CAM searches its entire memory to see if that data word is stored anywhere in it. If the data word is found, the CAM returns a list of one or more storage addresses where the word was found. Thus, a CAM is the hardware embodiment of what in software terms would be called an associative array. CAM is frequently used in networking devices where it speeds up forwarding information base and routing table operations. This kind of associative memory is also used in cache memory. In associative cache memory, both address and content are stored side by side. When the address matches, the corresponding content is fetched from cache memory.
TPU - Tensor Processing Unit / AI Chip (Scalar Accelerators)
Youtube search... ...Google search
- Google Pixel Phone
- Here are the likely specs of the Google Tensor chip in the Pixel 6 | Mishaal Rahman | XDA
- Tensor Processing Unit (TPU) | Wikipedia
- Google AIY Projects Program
- Baidu unveils Kunlun AI chip for edge and cloud computing | Khari Johnson - VentureBeat
- Google Unveils The New Tensor SoC, The Heart Of The New Pixel 6 Line Of Phones | Patrick Moorhead - Forbes
A Tensor Processing Unit (TPU) is an AI accelerator application-specific integrated circuit (ASIC) developed by Google for neural network machine learning, using Google’s own TensorFlow software1. TPUs are designed for a high volume of low precision computation (e.g. as little as 8-bit precision) with more input/output operations per joule, without hardware for rasterisation/texture mapping. Google provides third parties access to TPUs through its Cloud TPU service as part of the Google Cloud Platform and through its notebook-based services Kaggle and Colaboratory.
Google Tensor: the chip still has four A55s for the small cores, but it has two Arm Cortex-X1 CPUs at 2.8 GHz to handle foreground processing duties. For "medium" cores, we get two 2.25 GHz A76 CPUs. (That's A76, not the A78 everyone else is using—these A76s are the "big" CPU cores from last year.) The “Google Silicon” team gives us a tour of the Pixel 6’s Tensor SoC | Ron Amadeo - ARS Technical
AWS Trainium and Inferentia
Youtube search... ...Google search
- AWS Trainium is a high-performance machine learning training accelerator, purpose-built by AWS for deep learning training of 100B+ parameter models1. Each Amazon Elastic Compute Cloud (EC2) Trn1 instance deploys up to 16 AWS Trainium accelerators to deliver a high-performance, low-cost solution for Deep Learning (DL) training in the cloud. Trainium has been optimized for training Natural Language Processing (NLP), computer vision, and recommender models used in a broad set of applications, such as text summarization, code generation, question answering, image and video generation, recommendation, and fraud detection.
- AWS Inferentia is a high-performance machine learning inference accelerator designed by AWS to deliver high performance at the lowest cost for your deep learning (DL) inference applications. The first-generation AWS Inferentia accelerator powers Amazon Elastic Compute Cloud (Amazon EC2) Inf1 instances, which deliver up to 2.3x higher throughput and up to 70% lower cost per inference than comparable Amazon EC2 instances.
FPGA - Field Programmable Gate Array
Youtube search... ...Google search
A Field-Programmable Gate Array (FPGA) is an integrated circuit designed to be configured by a customer or a designer after manufacturing. The FPGA configuration is generally specified using a hardware description language (HDL), similar to that used for an application-specific integrated circuit (ASIC). FPGAs contain an array of programmable logic blocks, and a hierarchy of reconfigurable interconnects allowing blocks to be wired together. Logic blocks can be configured to perform complex combinational functions, or act as simple logic gates like AND and XOR. In most FPGAs, logic blocks also include memory elements, which may be simple flip-flops or more complete blocks of memory. FPGAs have a remarkable role in embedded system development due to their capability to start system software development simultaneously with hardware, enable system performance simulations at a very early phase of the development, and allow various system trials and design iterations before finalizing the system architecture.
VPU - Vision Processing Unit
Youtube search... ...Google search
A Vision Processing Unit (VPU) is a type of microprocessor designed to accelerate machine vision tasks. It is a specific type of AI accelerator, aimed at accelerating machine learning and artificial intelligence technologies. VPUs are used in a variety of applications, including computer vision, image recognition, and object detection. VPUs are distinct from video processing units (which are specialized for video encoding and decoding) in their suitability for running machine vision algorithms such as CNN (convolutional neural networks), SIFT (Scale-invariant feature transform), and similar. They may include direct interfaces to take data from cameras (bypassing any off-chip buffers), and have a greater emphasis on on-chip dataflow between many parallel execution units with scratchpad memory, like a manycore DSP. One example of a VPU is the Intel® Movidius™ Vision Processing Unit (VPU), which enables demanding computer vision and AI workloads with efficiency. By coupling highly parallel programmable compute with workload-specific AI hardware acceleration in a unique architecture that minimizes data movement, Movidius VPUs achieve a balance of power efficiency and compute performance.
Neuromorphic Chip
A Neuromorphic Chip is an electronic system that imitates the function of the human brain or parts of it. They contain artificial neurons and synapses that mimic the activity spikes and the learning process of the brain. These chips are used for various applications that require smarter and more energy-efficient computing, such as image and speech recognition, robotics, medical devices, and data processing. Neuromorphic chips attempt to model in silicon the massively parallel way the brain processes information as billions of neurons and trillions of synapses respond to sensory inputs such as visual and auditory stimuli. Those neurons also change how they connect with each other in response to changing images, sounds, and the like.
QPU - Quantum Processing Unit
Youtube search... ...Google search
- Quantum
- List of Quantum Processing Units (QPU) | Wikipedia
- Two-qubit gate: the speediest quantum operation yet | Phys.org
- A Preview of Bristlecone, Google’s New Quantum Processor | Google ... scaled to a square array of 72 Qubits
- A Huge Step Forward in Quantum Computing Was Just Announced: The First-Ever Quantum Circuit | Felicity Nelson - ScienceAlert
A Quantum Processing Unit (QPU) is the central component of a quantum computer or quantum simulator. It is a physical or simulated processor that contains a number of interconnected qubits that can be manipulated to compute quantum algorithms. A QPU uses the behavior of particles, such as electrons or photons, to perform specific types of calculations much faster than the processors in today’s computers. QPUs rely on behaviors like superposition, the ability of a particle to be in many states at once, described in the relatively new branch of physics called quantum mechanics. By contrast, CPUs, GPUs and DPUs all apply principles of classical physics to electrical currents. That’s why today’s systems are called classical computers.

Cerebras Wafer-Scale Engine (WSE)
The Cerebras Wafer-Scale Engine (WSE) is the largest chip ever built. It is the heart of our deep learning system. 56x larger than any other chip, the WSE delivers more compute, more memory, and more communication bandwidth. This enables AI research at previously-impossible speeds and scale.
Summit (supercomputer)
Youtube search... ...Google search
Summit or OLCF-4 is a supercomputer developed by IBM for use at Oak Ridge National Laboratory, which as of November 2018 is the fastest supercomputer in the world, capable of 200 petaflops. Its current LINPACK is clocked at 148.6 petaflops. As of November 2018, the supercomputer is also the 3rd most energy efficient in the world with a measured power efficiency of 14.668 GFlops/watt. Summit is the first supercomputer to reach exaop (exa operations per second) speed, achieving 1.88 exaops during a genomic analysis and is expected to reach 3.3 exaops using mixed precision calculations.
DESIGN: Design Each one of its 4,608 nodes (9,216 IBM POWER9 CPUs and 27,648 Nvidia Tesla GPUs) has over 600 GB of coherent memory (6×16 = 96 GB HBM2 plus 2×8×32 = 512 GB DDR4 SDRAM) which is addressable by all CPUs and GPUs plus 800 GB of non-volatile RAM that can be used as a burst buffer or as extended memory. The POWER9 CPUs and Volta GPUs are connected using Nvidia's high speed NVLink. This allows for a heterogeneous computing model.[14] To provide a high rate of data throughput, the nodes will be connected in a non-blocking fat-tree topology using a dual-rail Mellanox EDR InfiniBand interconnect for both storage and inter-process communications traffic which delivers both 200Gb/s bandwidth between nodes and in-network computing acceleration for communications frameworks such as MPI and SHMEM/PGAS. Summit (supercomputer) | Wikipedia
Photonic Integrated Circuit (PIC)
Youtube search... ...Google search
- Microparticles create photonic nanojets for parallel manipulation of cells | Sally Cole Johnson - Laser Focus World ... Photonic nanojet-mediated optical backaction force enables parallel manipulation, which may help researchers design photonic devices with biological materials.
- Lightmatter
- Lightmatter Aims to Bridge Chiplets With Photonics | Francisco Pires - Tom's Hardware
- Wikipedia
Lightmatter is creating...
- Envise: the world's first AI Accelerator, Envise, running on photonic cores (computing via light). The company's platform unlocks improved latency performance (128^2 MVPs in a single 2.5GHz clock cycle), reduces total cost of ownership, and reduces power consumption (compared to traditional GPUs). he Envise 4S features 16 Envise Chips in a 4-U server configuration with only 3kW power consumption. 4S is a building block for a rack-scale Envise inference system that can run the largest neural networks developed to date at unprecedented performance — 3 times higher IPS than the Nvidia DGX-A100 with 8 times the IPS/W on BERT-Base SQuAD. Massive on-chip activation and weight storage enabling state-of-the-art neural network execution without leaving the processor. Standards-based host and interconnect interface. Revolutionary compute, standard communications. RISC cores per Envise processor. Generic off-load capabilities. Ultra-high performance out-of-order super-scalar processing architecture. Deployment-grade reliability, availability, and serviceability features. Next generation compute with the reliability of standard electronics. 400Gbps Lightmatter interconnect fabric per Envise chip — enabling large model scale-out. Running the most advanced neural networks on the planet.
- IDIOM: is the company's Software Development Kit that uses common machine learning frameworks, like PyTorch & TensorFlow.
- Passage: Further, Lightmatter has also created the world's first switchable optical interconnect platform, Passage, that unlocks optical speeds, system integration, dynamic workloads and reduced power consumption. Features: Reduce the carbon footprint and operating cost of your datacenter while powering the most advanced neural networks (and the next generation) with a fundamentally new, powerful and efficient computing platform: photonics. Photonics enables multiple operations within the same area. T
TinyGPU
Discover how Adam Majmudar embarked on an exceptional journey to create the TinyGPU from scratch, with no experience in GPU design. This insightful podcast follows Adam's process from learning to implementation, highlighting the progressive contributions of countless engineers and the accelerating role of AI in the learning journey. Experience the unfolding of GPU architecture and gain a deeper appreciation for the technology driving today's AI advancements. Nick Labenz - The Cognitive Revolution
Multi-Project Wafer (MPW)
- Skywater... Technology as a Service (TaaS)
- CMC Microsystems
A process where multiple people or entities share the cost of producing electronic wafer chips; allowing for the cost-effective manufacturing of small quantities of chips.
SkyWater Technology, a U.S.-based semiconductor manufacturer, offers a unique model known as Technology as a Service (TaaS). Through this model, SkyWater provides customers with a combination of technical capability, rigorous product development processes, and secure manufacturing, all within the same U.S. operation. This approach accelerates time to market, ensures that quality is designed in from the start, and scales easily to volume. It's particularly beneficial for innovators and small businesses, as it allows them to access high-quality chip manufacturing services without the need for significant upfront investment.
CMC Microsystems, a not-for-profit organization that accelerates research and innovation in advanced technologies². They specialize in areas including microelectronics, photonics, microelectromechanical systems (MEMS), Internet of Things (IoT), Artificial Intelligence (AI), and quantum software and hardware. They offer a range of services including state-of-the-art design tools, access to prototype fabrication, and laboratory resources for demonstration. They also coordinate cost-shared access to products and services for designing and manufacturing prototypes from a global supply chain of more than 100 suppliers.