Agents
Youtube ... Quora ...Google search ...Google News ...Bing News
- Agents ... Robotic Process Automation ... Assistants ... Personal Companions ... Productivity ... Email ... Negotiation ... LangChain
- Assistant: Reactive; task completion
- Personal Companion: Proactive and reactive; building a relationship with the user
- Agent: Proactive; performing tasks, making decisions on behalf of the user
- Robotic Process Automation (RPA)
- Memory
- Development ... Notebooks ... AI Pair Programming ... Codeless ... Hugging Face ... AIOps/MLOps ... AIaaS/MLaaS
- Immersive Reality ... Metaverse ... Omniverse ... Transhumanism ... Religion
- Simulation ... Simulated Environment Learning ... World Models ... Minecraft: Voyager
- Telecommunications ... Computer Networks ... 5G ... Satellite Communications ... Quantum Communications ... Communication Agents ... Smart Cities ... Digital Twin ... Internet of Things (IoT)
- Artificial General Intelligence (AGI) to Singularity ... Curious Reasoning ... Emergence ... Moonshots ... Explainable AI ... Automated Learning
- Python ... GenAI w/ Python ... JavaScript ... GenAI w/ JavaScript ... TensorFlow ... PyTorch
- Gaming ... Game-Based Learning (GBL) ... Security ... Generative AI ... Games - Metaverse ... Quantum ... Game Theory ... Design
- Artificial Intelligence (AI) ... Generative AI ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Conversational AI ... ChatGPT | OpenAI ... Bing/Copilot | Microsoft ... Gemini | Google ... Claude | Anthropic ... Perplexity ... You ... phind ... Ernie | Baidu
- ChatGPT Integration
- Minecraft: Voyager ... an AI agent powered by a Large Language Model (LLM) that has been introduced to the world of Minecraft
- Large Language Model (LLM) ... Natural Language Processing (NLP) ...Generation ... Classification ... Understanding ... Translation ... Tools & Services
- Attention Mechanism ...Transformer ...Generative Pre-trained Transformer (GPT) ... GAN ... BERT
- Artificial Intelligence (AI) ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Policy ... Policy vs Plan ... Constitutional AI ... Trust Region Policy Optimization (TRPO) ... Policy Gradient (PG) ... Proximal Policy Optimization (PPO)
- Multi-Task Learning (MTL) ... SMART - Multi-Task Deep Neural Networks (MT-DNN)
- Deep Distributed Q Network Partial Observability
- Metaverse#AI TownAI Town ... a virtual town where AI characters live, chat and socialize.
- What Is A Virtual Agent & What Can It Do For Your Business? | Talkative
- Types of AI Agents | JavaTpoint ... Simple Reflex, Model-based reflex, Goal-based, Utility-based, Learning agents
- Key Research Advances in Building Task-Oriented Dialog Agents | Mariya Yao - TOPBOTS
- MineDojo ... framework built on the popular Minecraft game for embodied agent research
- Google Tells AI Agents to Behave Like 'Believable Humans' to Create 'Artificial Society' | Chloe Xiang - Vice ... The characters have developed specific routines, such as waking up, taking a shower, cooking breakfast, interacting with their families, then going to work every day... researchers input one paragraph per character into ChatGPT
- Amazon creates a new user-centric simulation platform to develop embodied AI agents | Ingrid Fadelli - TechExplore ... Arena is a new Embodied AI platform, for robotic task completion in simulated environments.
- Your AI Council ... assesses queries through various agents, offering insights from many perspectives.
- 70 Top AI AI Agent Development Tools | TopAI.tools
- Agent.ai ... A marketplace and professional network for AI agents and the people who love them.
The paradigm of AI copilots is undergoing a transformation, shifting from AI serving as a supportive assistant to humans, to humans taking on the role of AI copilots. This shift represents a significant change in how individuals interact with AI, enabling users to harness the power of AI to enhance decision-making and efficiency. This shift in the copilot paradigm signifies a move towards a more collaborative and empowering relationship between humans and AI, where humans actively engage with AI to augment their capabilities and productivity.
Contents
There are 3 stages; Beside, Inside, & Outside - Steven Bathiche
- AI will be beside what we are doing: AI is a valuable tool; a helper, a sidebar, an assistant that can aid us in many aspects of our lives. As a conversational AI, it can help us with research, writing, and presentations, breaking our mental blacks, managing our personal lives by scheduling appointments and managing our finances. By automating tasks such as data entry and email processing, AI frees up our time so that we can focus on more important tasks.
- AI will inside what we are doing: AI will become even more integrated into our daily lives, understanding our needs and preferences and anticipating our actions. It will be everywhere, acting as the scaffolding for our interactions with technology. Instead of waiting for us to make a keystroke or select an application, AI will take the lead, choosing the best app for us and coaching us through a vast array of possibilities.
- AI will be outside what we are doing: AI agents will act as intermediaries, pulling information from disparate data sources and interpreting the world for us. They will help us navigate and understand the context, acting as facilitators and eliminating the challenge of starting with a blank sheet.
An intelligent agent is anything which perceives its environment, takes actions autonomously in order to achieve goals, and may improve its performance with learning or acquiring knowledge. An agent has an "objective function" that encapsulates all the IA's goals. Such an agent is designed to create and execute whatever plan will, upon completion, maximize the expected value of the objective function.[2] For example, a reinforcement learning agent has a "reward function" that allows the programmers to shape the IA's desired behavior,[3] and an evolutionary algorithm's behavior is shaped by a "fitness function". - Wikipedia
OpenClaw is an open-source autonomous AI agent framework capable of executing multi-step tasks across various digital platforms. Created in late 2025 by Austrian developer Peter Steinberger (formerly known as "Clawdbot" and "Moltbot" before a rebranding), the software runs locally on a user's machine and serves as a bridge between Large Language Models (LLMs) and local system tools. Unlike traditional chatbots that only generate text, OpenClaw is designed to perform active workflows—such as managing files, sending emails, and writing code—initiated via messaging apps like WhatsApp, Telegram (software), and Slack (software).
The project gained viral popularity in early 2026, often described as "AI that actually does things," due to its ability to retain persistent memory and execute complex chains of actions without continuous human oversight. However, its deep system access has drawn scrutiny from cybersecurity researchers, who have highlighted potential risks involving unauthorized data modification and "rogue" agent behavior.
Related Efforts
Following OpenClaw's rapid rise, major technology companies accelerated the development of competing autonomous agents or integrated similar capabilities into their ecosystems.
In May 2026, reports emerged that Google was internally testing a competitor codenamed "Remy" (derived from remigus, Latin for "oarsman"). Integrated into a staff-only version of Gemini, Remy is described as a "24/7 personal agent" capable of proactively handling workflows across the Google Workspace ecosystem (Gmail, Calendar, Drive) rather than just responding to prompts. The project is seen as a direct response to OpenClaw's "agentic" capabilities, aiming to offer a more secure, managed alternative for task automation.
OpenAI
Rather than releasing a direct clone, OpenAI "absorbed" the primary talent behind the project. In February 2026, CEO Sam Altman announced the hiring of OpenClaw creator Peter Steinberger to work on OpenAI's next generation of personal agents. While OpenClaw itself remained open-source, this move was widely interpreted as a strategic pivot by OpenAI to internalize the "agentic" workflow infrastructure that Steinberger had popularized.
Microsoft
Microsoft developed an enterprise-focused alternative internally codenamed "Project Lobster" (a nod to the crustacean theme of OpenClaw). This initiative evolved into the official product Microsoft Scout, announced in June 2026. Scout is integrated into Microsoft 365 and Windows, offering similar autonomous capabilities—such as scheduling and data processing—but wrapped in enterprise-grade security and identity management (Entra ID) to address the compliance concerns associated with self-hosted agents.
Anthropic
Early tension existed between OpenClaw and Anthropic due to the original name "Clawdbot" being a homophone for their model "Claude," which led to a legal request for a rename. Anthropic is reportedly developing a remote control feature called "Dispatch" to allow its models to operate agents in the background.
Meta
Meta's entry into the space includes both product development and strategic acquisitions. • Manus: In March 2026, Meta launched a desktop application for its AI agent, Manus (sometimes referred to in leaks as "Manis" or "Malice"), which brings agentic capabilities directly to personal computers. The tool allows users to control desktop applications and local files, positioning it as a consumer-friendly alternative to OpenClaw. • Moltbook Acquisition: Meta acquired Moltbook, a viral social media platform populated exclusively by AI agents (originally built for OpenClaw agents). The acquisition brought the platform's founders into Meta's "Superintelligence Labs" to further develop social behaviors for autonomous agents.
Other Competitors
Salesforce: The company is developing an enterprise alternative named "Albert." Perplexity: In February 2026, Perplexity launched a local agent system dubbed "Personal Computer." Open Source: The OpenClaw ecosystem has spawned numerous forks and lightweight alternatives, including NanoClaw (focused on security sandboxing), Hermes Agent, and ZeroClaw.
What is an AI Agent?
- AI Tools and Autonomous Agents: Auto-GPT, BabyAGI, LangChain, AgentGPT, HeyGPT, and more | Anna Geller - Medium ... Summary of recent trends for AI end-users (rather than AI engineers or researchers)
LlamaIndex’s Agent
LlamaIndex's Agent is a large language model (LLM) chatbot developed by LlamaIndex, a company that specializes in alpaca and llama products and information. The agent is trained on a massive dataset of text and code, including LlamaIndex's own database of alpaca and llama information. This allows the agent to answer a wide range of questions about alpacas and llamas, including their biology, behavior, care, and products. The agent can also be used to generate creative text formats of text content, like poems, code, scripts, musical pieces, email, letters, etc. It can also be used to translate languages. LlamaIndex's Agent is a valuable resource for anyone who is interested in learning more about alpacas and llamas. It is also a useful tool for alpaca and llama breeders, farmers, and businesses. Here are some examples of how LlamaIndex's Agent can be used:
- Answer questions about alpacas and llamas: The agent can answer a wide range of questions about alpacas and llamas, including their biology, behavior, care, and products. For example, you could ask the agent "How long do alpacas live?" or "What is the difference between a llama and an alpaca?"
- Generate creative text formats: The agent can be used to generate creative text formats of text content, like poems, code, scripts, musical pieces, email, letters, etc. For example, you could ask the agent to write a poem about alpacas or a script for a video about llama care.
- Translate languages: The agent can also be used to translate languages. For example, you could ask the agent to translate a Spanish article about alpacas into English.
Langchain’s Agent
LangChain's Agent is a type of artificial intelligence (AI) that can be used to automate a variety of tasks. It is a language model that is trained on a massive dataset of text and code. This allows the agent to understand and respond to natural language, and to perform many kinds of tasks, including:
- Answering questions in a comprehensive and informative way
- Generating different creative text formats of text content
- Translating languages
- Automating tasks that would otherwise require human intervention
LangChain's Agent is still under development, but it has the potential to revolutionize the way we work and live. For example, it could be used to develop new types of customer service chatbots, to automate tasks in software development, and to create new forms of creative content. Here are some examples of how LangChain's Agent could be used in the real world:
- A customer service chatbot could use LangChain's Agent to answer customer questions in a more comprehensive and informative way than traditional chatbots.
- A software development team could use LangChain's Agent to automate tasks such as writing unit tests and generating documentation.
- A writer could use LangChain's Agent to generate ideas for new articles or stories, or to translate their work into other languages.
LangChain's Agent is a powerful tool that has the potential to be used in a wide variety of applications. As the technology continues to develop, we can expect to see even more innovative and exciting uses for LangChain's Agent in the future. In addition to the examples above, LangChain's Agent could also be used to:
- Develop new educational tools that can personalize instruction and provide feedback to students.
- Create new types of creative content, such as interactive stories and games.
- Develop new tools for scientific research, such as helping scientists to design experiments and analyze data.
- Automate tasks in a variety of industries, such as healthcare, finance, and manufacturing.
DeepMind's WebAgent
YouTube ... Quora ...Google search ...Google News ...Bing News
- A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis | I. Gur, H. Furuta, A. Huang, M. Safdari, Y. Matsuo, D. Eck, & A. Faust
- Meet WebAgent: DeepMind’s New LLM that Follows Instructions and Complete Tasks on Websites Google | Jesus Rodriguez - Towards AI] ... The model combines language understanding and web navigation.
- Google DeepMind and the University of Tokyo Researchers Introduce WebAgent: An LLM-Driven Agent that can Complete the Tasks on Real Websites Following Natural Language Instructions | Aneesh Tickoo - MarketTechPost
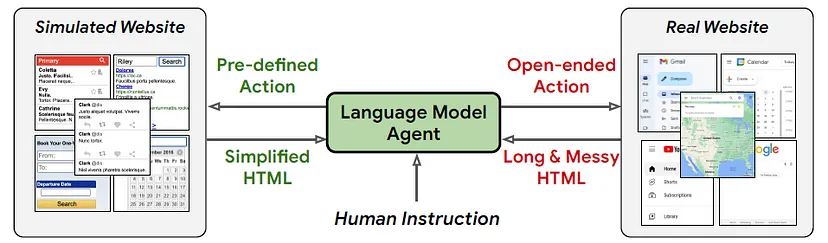
Google DeepMind's WebAgent can autonomously navigate and interact with websites, following natural language instructions to complete tasks; capable of understanding and interacting with the vast and complex world of the internet.
'https://miro.medium.com/v2/resize:fit:828/format:webp/1*sA904oL8A4DUQ6FQInNAbw.png'
Key Features of WebAgent:
- Planning and Long Context Understanding: WebAgent can break down complex instructions into smaller, manageable steps and analyze lengthy HTML documents to extract relevant information. This allows it to effectively plan its actions and adapt to the dynamic nature of websites.
- Large Language Model (LLM): WebAgent's design incorporates two distinct large language models, HTML-T5 and Flan-U-PaLM, each specialized for specific tasks. This modular approach allows for efficient processing and enhanced performance. HTML-T5: A domain-specific LLM trained on a massive corpus of HTML documents, specializing in understanding and summarizing website content. Flan-U-PaLM: A powerful LLM capable of generating executable Python code, enabling WebAgent to interact with websites directly.
- Program Synthesis: WebAgent employs program synthesis techniques to translate natural language instructions into executable code, allowing it to perform actions on websites. WebAgent can generate executable Python code based on its understanding of instructions and website structure. This enables it to directly interact with websites, filling forms, clicking buttons, and extracting data.
- Reinforcement Learning (RL): Reinforcement learning algorithms are used to train WebAgent, enabling it to learn from experience and improve its performance over time.
- Web Scraping Techniques: WebAgent utilizes web scraping techniques to extract relevant information from websites, such as text, images, and links.
- Natural Language Processing (NLP): NLP techniques are employed to analyze and understand natural language instructions, enabling WebAgent to follow complex commands.
- Machine Learning (ML): Machine learning algorithms are used to train and optimize WebAgent's various components, enhancing its ability to perform tasks accurately and efficiently.
Potential Applications:
- Automated Web Testing: WebAgent can be employed to automate website testing, identifying bugs, and ensuring functionality across different platforms and browsers.
- Web Scraping and Data Extraction: WebAgent's ability to understand and navigate websites makes it an ideal tool for extracting specific data from various sources, streamlining data collection processes.
- Personalized Web Assistance: WebAgent could serve as a personalized web assistant, helping users with tasks like booking appointments, making online purchases, or managing personal accounts.
Jarvis
YouTube ... Quora ...Google search ...Google News ...Bing News
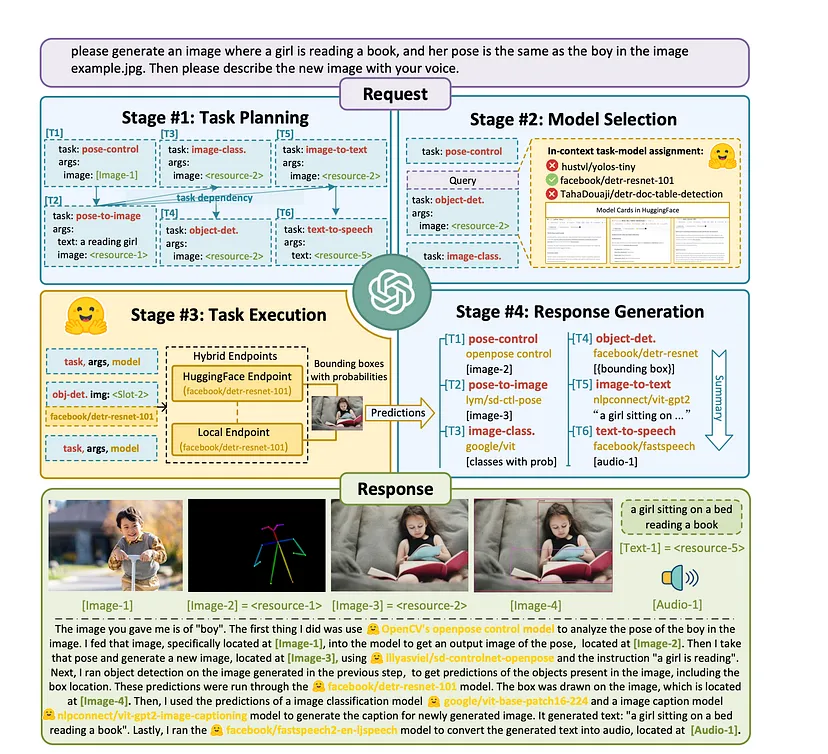
Jarvis is a project from Microsoft that uses ChatGPT as the controller for a system where it can employ a variety of other models as needed to respond to your prompt. Microsoft Jarvis connects LLMs with ML community. Language serves as an interface for Large Language Model (LLM)s to connect numerous AI models for solving complicated AI tasks. Solving complicated AI tasks with different domains and modalities is a key step toward advanced artificial intelligence. While there are abundant AI models available for different domains and modalities, they cannot handle complicated AI tasks. Considering Large Language Model (LLM) have exhibited exceptional ability in language understanding, generation, interaction, and reasoning, we advocate that LLMs could act as a controller to manage existing AI models to solve complicated AI tasks and language could be a generic interface to empower this.
HuggingGPT is one instance of Jarvis, a web-based chatbot at Hugging Face, an online AI community which hosts thousands of open-source models.
When a user makes a request to the bot, Jarvis plans the task, chooses which models it needs, has those models perform the task and then generates and issues a response. The workflow of this system consists of four stages:
- Task Planning: Using ChatGPT to analyze the requests of users to understand their intention, and disassemble them into possible solvable tasks via prompts.
- Model Selection: To solve the planned tasks, ChatGPT selects expert models that are hosted on Hugging Face based on model descriptions.
- Task Execution: Invoke and execute each selected model, and return the results to ChatGPT.
- Response Generation: Finally, using ChatGPT to integrate the prediction of all models, and generate answers for users.
HuggingGPT
YouTube ... Quora ...Google search ...Google News ...Bing News
- HuggingGPT | Microsoft ... A system to connect LLMs with ML community.
- How to Use Jarvis, Microsoft's One AI Bot to Rule Them All | Avram Piltch - Tom's Hardware
- How to Use Microsoft JARVIS (HuggingGPT) Right Now | Arjun Sha - Beebom
- HuggingGPT ... A Framework That Leverages LLMs to Connect Various AI Models in Machine Learning Communities Hugging Face to Solve AI Tasks
HuggingGPT that the Microsoft researchers have set up that leverages Large Language Model (LLM) such as ChatGPT to connect various AI models in machine learning communities to solve AI tasks. Specifically, HuggingGPT uses ChatGPT to conduct task planning when receiving a user request, select models according to their function descriptions available in Hugging Face, execute each subtask with the selected AI model, and summarize the response according to the execution results. To use HuggingGPT, you'll need to obtain an OpenAPI API Key if you don't already have one and sign up for a free account at Hugging Face. Once you've logged in to the site, navigate to Settings -> Access Tokens by clicking the links in the left rail.
Auto-GPT
YouTube ... Quora ...Google search ...Google News ...Bing News
- Auto-GPT | Significant Gravitas - GitHub
- GPT-4 | OpenAI
- ElevenLabs
- Pinecone
- Colaboratory | Google
- What is Auto-GPT? Everything to know about the next powerful AI tool | Sabrina Ortiz - ZDnet ... Auto-GPT can do a lot of things ChatGPT can't do.
- 6 Common Auto-GPT Installation Issues and How to Resolve Them | Jayric Maning - MakeUseOf
- AutoGPT: Everything You Need To Know | Nisha Arya - KDnuggets ... GPT has the ability to write its own code using GPT-4. It also executes Python scripts which allow it to recursively debug, develop, build and continuously self-improve.
- Revolutionizing Autonomous AI: Harnessing Vector Databases to Empower Auto-GPT | Sim Fu - zilliz ... Auto-GPT has limitations in understanding and retaining extensive contextual information because the GPT model it leverages has a token limit
Auto-GPT (AutoGPT) is an open-source Python AI Agent application based on GPT-4 that can self-prompt. This means that if the user states an end goal, the system can work out the steps needed to get there and carry them out. Auto-GPT works by setting a goal; the AI will then generate and complete tasks. Basically, it does all the follow-up work for you, asking and answering its own prompts in a loop. It utilizes the GPT-4 API and can perform a task with little human intervention.
Auto-GPT manages short-term and long-term memory by writing to and reading from databases and files; manages context window length requirements with summarization; can perform internet-based actions such as web searching, web form, and API interactions unattended; and includes text-to-speech for voice output. However, it has limitations in understanding and retaining extensive contextual information because the GPT model it leverages has a token limit. One way to address this contextual issue is to access a window of historical messages, such as the last ten messages or a fixed number of tokens, without exceeding the token limit of a single conversation. However, this method restricts Auto-GPT from accessing earlier contextual information, which might lead to the failure of Auto-GPT to accomplish its goal
To install Auto-GPT, you will need to have Python and Pip installed on your computer. You can download the latest version of Python from the official website and install it on your computer. You will also need to add API keys to use Auto-GPT. You can go to the GitHub release page of Auto-GPT and download the ZIP file by clicking on “Source code (zip)”
If you want Auto-GPT to speak using ElevenLabs, you will need to have an ElevenLabs API key. You can obtain your ElevenLabs API key from their website. Once you have your API key, you can add it to the .env file in the Auto-GPT directory.
Auto-GPT is not yet capable of achieving the AGI (Artificial General Intelligence) due to data quality, generalization, and explainability issues. - Kanwal Mehreen
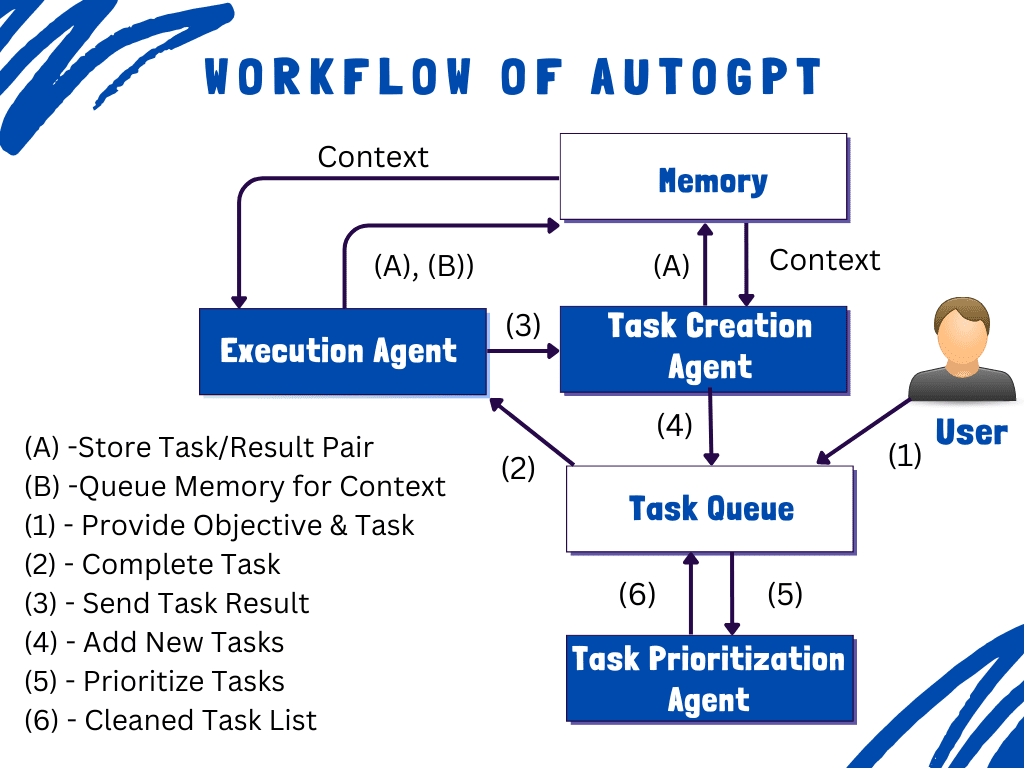
Breaking Down AutoGPT | Kanwal Mehreen - KDnuggets ... here are the steps
- Input from the User
- Task Creation Agent
- Task Prioritization Agent
- Communication Between Agents
- Final Result - It also uses external memory to keep track of history and learn from its past experiences to generate more precise results.
The actions of these agents are visible on the user end in the following form:
- Thoughts: AI agent share their thoughts after completing the action
- Reasoning: It explains its choices of why is it choosing a particular course of action
- Plan: The plan includes the new set of tasks
- Criticism: Critically review the choices by identifying the limitations or concerns
Reflexion
YouTube ... Quora ...Google search ...Google News ...Bing News
- Reflexion: an autonomous agent with dynamic memory and self-reflection | N. Shinn, B. Labash, A. Gopinath - arXiv
- GPT-4 | OpenAI
- AlfWorld
Reflexion is a meta-technique approach that endows an agent with dynamic memory and self-reflection capabilities to enhance its existing reasoning trace and task-specific action choice abilities1 It builds on recent research and allows agents to learn from their mistakes and solve novel problems efficiently through a process of trial and error. Reflexion’s success has been demonstrated through evaluations in AlfWorld and HotPotQA environments, achieving success rates of 97% and 51%, respectively. To achieve full automation, Reflexion introduces a straightforward yet effective heuristic that enables the agent to pinpoint hallucination instances, avoid repetition in action sequences, and, in some environments, construct an internal memory map of the given environment.
Self-reflection allows humans to efficiently solve novel problems through a process of trial and error.
Autonomous GPT
YouTube ... Quora ...Google search ...Google News ...Bing News
- Embedding ... Fine-tuning ... RAG ... Search ... Clustering ... Recommendation ... Anomaly Detection ... Classification ... Dimensional Reduction. ...find outliers
- Developers Are Connecting Multiple AI Agents to Make More ‘Autonomous’ AI | Chloe Xiang - Vice ... Auto-GPT
- Auto-GPT | Toran Bruce Richards ... driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set by can prompting itself to complete an objective.
- Task-driven Autonomous Agent Utilizing GPT-4, Pinecone, and LangChain for Diverse Applications | Yohei Nakajima
AgentGPT
YouTube ... Quora ...Google search ...Google News ...Bing News
- AgentGPT
- Beyond ChatGPT: AgentGPT is Bringing Autonomous AI To The Browser NOW | Sebastian - Medium
- AgentGPT template | Vercel ... Assemble, configure, and deploy autonomous AI Agents in your browser, using LangChain, OpenAI, AutoGPT and T3 Stack
AgentGPT allows you to configure and deploy Autonomous AI agents. Name your custom AI and have it embark on any goal imaginable. It will attempt to reach the goal by thinking of tasks to do, executing them, and learning from the results
BabyAGI
YouTube ... Quora ...Google search ...Google News ...Bing News
- Auto-GPT and BabyAGI: How ‘autonomous agents’ are bringing generative AI to the masses | Mark Sullivan - Fast Company ... Autonomous agents may mark an important step toward a world where AI-driven systems are smart enough to work on their own, without need of human involvement.
- AI & Identity, from East & West, with Yohei Nakajima GP at Untapped Capital and BabyAGI Creator | Erik Torenberg and Nathan Labenz - The Cognitive Revolution
OpenAGI
- OpenAGI: When LLM Meets Domain Experts | Y. Ge, W. Hua, K. Mei, J. Ji, J. Tan, S. Xu, Z. Li, Y. Zhang | Arxiv
- OpenAGI | Github
OpenAGI is an open-source research platform for artificial general intelligence (AGI). It's designed to offer complex, multi-step tasks. OpenAGI offers complex tasks, datasets, metrics, and models for solving tasks. It also provides task-specific datasets, evaluation metrics, and a diverse range of extensible models. OpenAGI uses a dual strategy, integrating standard benchmark tasks for benchmarking and evaluation, and open-ended tasks including more expandable models, tools, plugins, or APIs for creative problem-solving. OpenAGI formulates complex tasks as natural language queries, serving as input to the LLM. It also proposes an LLM+RLTF approach to learning better task design.
AutoGen
YouTube ... Quora ...Google search ...Google News ...Bing News
- AutoGen | Microsoft
- AutoGen Studio 2.0: Revolutionizing AI Agents
- Create AI Agents Easily with AutoGen Studio UI 2.0
- AutoGen Studio UI 2.0 : Step By Step Installation Guide
- AutoGen Studio: Interactively Explore Multi-Agent Workflows
AutoGen Studio 2.0** is a comprehensive tool suitable for developers of all skill levels. It simplifies AI development by providing an intuitive interface and extensive toolset. The platform caters to a broad spectrum of developers, from novices to experts.
Getting Started:
- Environment Preparation: Crucial steps include installing **Python** and **Anaconda**.
- Configuring LLM Provider: Obtain an API key from **OpenAI** or **Azure** for language model access.
- Installation and Launch: A simplified process to kickstart AutoGen Studio.
- Interface Navigation:
- Build Section: Enables AI agent creation, skill definition, and workflow setup.
- Playground Section: A dynamic platform for testing and observing AI agent behavior.
- Gallery Section: Stores AI development sessions for future reference.
- Powerful Python API:
- Beneath its web interface, AutoGen Studio features a **Python API**.
- Developers can use this API to gain detailed control over agent workflows.
MultiOn
YouTube ... Quora ...Google search ...Google News ...Bing News
Personal AI agent and life copilot that uses the browser to execute complex tasks.
- MultiOn Browser is a web browser that uses ChatGPT and OpenAI plugins to interact with anything on the internet on your behalf
- MultiOn is also a ChatGPT plugin that can automate tasks for you, such as posting on social media or ordering products online, or find any content on the web
CrewAI
YouTube ... Quora ...Google search ...Google News ...Bing News
- CrewAI
- crewAI Tools - crewAI
- GitHub - joaomdmoura/crewAI: Framework for orchestrating role-playing
- Building Collaborative AI Agents With CrewAI | Analytics Vidhya
- crewai · PyPI
CrewAI is a cutting-edge framework designed for orchestrating role-playing and autonomous AI agents. It fosters collaborative intelligence, empowering agents to work together seamlessly and tackle complex tasks. Here are some key points about CrewAI:
- CrewAI enables AI agents to assume roles, share goals, and operate as a cohesive unit—much like a well-coordinated crew.
- Whether you're building a smart assistant platform, an automated customer service ensemble, or a multi-agent research team, CrewAI provides the backbone for sophisticated multi-agent interactions.
- Agent Setup Example:
- Let's say you're creating a research team. Here's how you might set up an agent:
```python
from crewai import Agent, Task, Crew, Process
from crewai_tools import SerperDevTool
# Define your agents with roles and goals
researcher = Agent(
role='Senior Research Analyst',
goal='Uncover cutting-edge developments in AI and data science',
backstory="You work at a leading tech think tank...",
verbose=True,
allow_delegation=False,
tools=[SerperDevTool()] # Optional tools for the agent
)
Tasking.AI
- Tasking.AI ... The developer-friendly cloud platform for building and running LLM agents for AI-native applications.
Tasking.AI stands out due to its innovative approach to artificial intelligence integration and deployment. Here are some key features that make it unique, particularly with the introduction of its groundbreaking serverless cloud platform:
- Serverless Architecture: The serverless cloud platform allows users to run AI models without worrying about underlying infrastructure. This means no server management, automatic scaling, and pay-as-you-go pricing, making it cost-effective and efficient.
- Ease of Use: Tasking AI is designed for ease of use, with intuitive interfaces and tools that enable even those with limited technical knowledge to deploy and manage AI solutions.
- Scalability: The platform automatically scales resources based on demand, ensuring optimal performance for applications of any size without manual intervention.
- Integration Capabilities: Tasking AI provides seamless integration with various data sources and other cloud services, allowing users to easily incorporate AI into their existing workflows and systems.
- Flexibility and Customization: Users can customize AI models to fit specific needs, whether through pre-built templates or by building models from scratch. This flexibility supports a wide range of applications across different industries.
- Security and Compliance: The platform emphasizes strong security measures and compliance with industry standards, ensuring that data and AI models are protected and meet regulatory requirements.
- Cost Efficiency: With a serverless model, users only pay for the compute time they actually use, which can significantly reduce costs compared to traditional server-based architectures.
- Rapid Deployment: The platform allows for quick deployment of AI solutions, reducing the time from development to production and enabling faster innovation cycles.
- Real-Time Processing: Capable of handling real-time data processing and analytics, Tasking AI supports applications that require immediate insights and decision-making.
AI-Powered Search
YouTube ... Quora ...Google search ...Google News ...Bing News
- Embedding ... Fine-tuning ... RAG ... Search ... Clustering ... Recommendation ... Anomaly Detection ... Classification ... Dimensional Reduction. ...find outliers
- Excel ... Documents ... Database; Vector & Relational ... Graph ... LlamaIndex
- Pinecone
- Recurrent Neural Network (RNN)
- Autoencoder (AE) / Encoder-Decoder
Multi-Agent
- Towards the AI Agent Ecosystem | M. Wu, J. Matheson, J. Stener and A. Steele ... A Technical Guide for Founders & Operators Building Agents
Multi-Agent Communications
Youtube search... ...Google search
- Telecommunications ... Computer Networks ... 5G ... Satellite Communications ... Quantum Communications ... Communication Agents ... Smart Cities ... Digital Twin ... Internet of Things (IoT)
- Attention
- TALISMAN: A multi-agent system for natural language processing | Marie-Hélène Stefanini & Yves Demazeau - Part of the Lecture Notes in Computer Science book series (LNAI,volume 991) ... One of the originalities of this system is the distributed treatment of sentence analysis (as opposed to a classic sequential treatment) and the introduction of linguistic laws which handle the communication between agents, without central control. At the implementation level, the system brings openness to dictionary modification, grammars and strategies of analysis, as well as the necessary mechanisms for the integration of new modules.
- Integrating AI Planning with Natural Language Processing: A Combination of Explicit and Tacit Knowledge | Kebing Jin, Hankz Hankui Zhuo - Cornell University
- BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation | J. Li, S. Hoi, and D. Rose - Salesforce AI Research
[bots] all communicating with other bots, but we find that you know it doesn't really make sense for these bots to like reduce everything to language and then send the language over and then have it be you know kind of re-embedded. Like why don't they just talk to each other in their native language which is this high dimensional space. ... you can adapt embeddings to another, you know, embedding space with basically just like a single of your projection. - Nathan Labenz | The Cognitive Revolution; 'Looking Up the AI Exponential with Azeem Azhar of the Exponential View episode'
Agents with Reinforcement Learning (RL)
Reinforcement Learning (RL) aims to make an agent (our “model”) learn through the interaction with an environment (this can be either virtual or real). RL was firstly developed to adhere to Markov Decision Process (MDP)es. In this ambit, an agent is placed in a stochastic stationary environment and tries to learn a policy through a reward/punishment mechanism. In this scenario, it is proved the agent will converge to a satisfactory policy. However, if multiple agents are placed in the same environment, this condition is no longer true. In fact, before the learning of the agent was only dependent on the interaction between the agent and the environment, now it is also dependent on the interaction between agents
Multi-Agents Reinforcement Learning (MARL)
In a similar vein, multi-agent RL also addresses sequential decision-making problems, but with more than one agent involved. In particular, both the evolution of the system state and the reward received by each agent are influenced by the joint actions of all agents. More intriguingly, each agent has its own long-term reward to optimize, which now becomes a function of the policies of all other agents.
- Markov/Stochastic Games
- Cooperative Setting
- Competitive Setting
- Mixed Setting
- Extensive-Form Games
Challenges
Despite a general model with broad applications, MARL suffers from several challenges in theoretical analysis, in addition to those that arise in single-agent RL.
- Non-Unique Learning Goals - Unlike single-agent RL, where the goal of the agent is to maximize the long-term return efficiently, the learning goals of MARL can be vague at times. ...Indeed, the goals that need to be considered in the analysis of MARL algorithms can be multi-dimensional ... is undoubtedly a reasonable solution concept in game theory, under the assumption that the agents are all rational, and are capable of perfectly reasoning and infinite mutual modeling of agents. However, with bounded rationality, the agents may only be able to perform finite mutual modeling
- Non-Stationarity - multiple agents usually learn concurrently, causing the environment faced by each individual agent to be non-stationary. In particular, the action taken by one agent affects the reward of other opponent agents, and the evolution of the state. As a result, the learning agent is required to account for how the other agents behave and adapt to the joint behavior accordingly. This invalidates the stationarity assumption for establishing the convergence of single-agent RL algorithms
- Scalability Issue - To handle non-stationarity, each individual agent may need to account for the joint action space, whose dimension increases exponentially with the number of agents. This is also referred to as the combinatorial nature of MARL
- Various Information Structures - Compared to the single-agent case, the information structure of MARL, namely, who knows what at the training and execution, is more involved. For example, in the framework of Markov games, it suffices to observe the instantaneous state st , in order for each agent to make decisions
AI Agent Optimization
- AI Agent Optimization ... Optimization Methods ... Optimizer ... Objective vs. Cost vs. Loss vs. Error Function ... Exploration
Agent optimization involves combining various elements like Prompt Engineering (PE), Human-in-the-Loop (HITL) Learning, and critique mechanisms to create highly advanced bots capable of completing tasks in natural language. These components include memory repositories to remember actions taken, critique algorithms for error correction, and orchestration software that combines LLMs with tools for optimal performance.
Critique mechanisms are crucial for the development of autonomous AI agents that can handle complex tasks efficiently and continuously improve their performance. By incorporating the following components and mechanisms into the design and development of AI agents, organizations can create autonomous systems that continuously self-assess and refine their outputs, leading to improved performance and efficiency over time. To build critique mechanisms in AI agents, particularly focusing on self-critique or auto-critique, the following steps are crucial based on the provided search results:
- Auto-Critique Process: Implement an autonomous process where AI agents reflect on past responses and errors to improve their output without human intervention. This involves drawing on new input from various sources like external tools, other agents, affiliated LLMs, and heuristic functions.
- Self-Criticism Process: In contrast, self-criticism is an internal feedback process where the AI evaluates its own responses, leading to immediate and iterative refinement. ChatGPT, for example, employs transformer-based neural networks and attention mechanisms to reassess and improve its outputs based on prompts. The use of self-criticism in AI tools empowers non-technical users, enhances versatility by creating multiple agents for different roles, and proves cost-effective by saving manual refining costs. This continuous loop of generating, evaluating, and revising output ensures a higher standard of response quality with each iteration.
- Stop Conditions: Define stop conditions that allow the AI agents to finalize their output once they reach a sufficient result based on predefined metrics for evaluating self-reasoning.
- Memory Repositories: Incorporate memory repositories within the AI agents to remember past actions taken, enabling them to learn from experiences and improve over time.
- Error Correction Algorithms: Integrate auto-critique algorithms within the AI agents to enable them to correct mistakes along the way, ensuring continuous improvement in their outputs.
- Orchestration Software: Combine Large Language Models (LLMs) with memory, tools, and auto-critique algorithms to create highly advanced bots capable of completing assigned tasks in natural language.
- Observability & Monitoring process: process ensures the correctness, reliability, and effectiveness of AI models by providing visibility into the AI's behavior and performance across their lifecycle.
Critique Frameworks
Some frameworks for self-critique and auto-critique mechanisms in AI agents include:
- CRITIC Reflexion: A framework that focuses on improving the agent's performance and robustness through self-critique, AI feedback, and synthetic data generation.
- SLAPA: A framework that involves self-critiquing models to assist human evaluators in refining AI outputs.
- ReACT: A framework that emphasizes improving the agent's performance and robustness through self-critique, AI feedback, and synthetic data generation.
- Chain of Hindsight: A method that enhances the self-criticism process by providing sequential context to AI agents, enabling them to refine outputs in a contextually relevant manner.
- ART (Auto-Critique Reflexion Technique): An autonomous process that allows agents to improve and amend their own output by reflecting on past responses and errors without human intervention.
- APE (Auto-Critique Prompt Engineering): Involves forming and refining natural language statements and questions to achieve optimal AI performance through self-critique mechanisms.
Observability & Monitoring Frameworks
Some frameworks for Observability & Monitoring Frameworks in AI Agents include:
- Arthur: A comprehensive AI observability platform that provides insights into model behavior, data, and performance across its lifecycle, enabling precise root cause analysis of predictions made by ML models.
- Honeyhive: A framework that focuses on monitoring, analyzing, and visualizing the internal states, inputs, and outputs of AI models to ensure correctness, reliability, and effectiveness.
- Scribbledata: Offers a holistic approach to drive insights on the ML model's behavior, data, and performance across its lifecycle, facilitating proactive detection of ML pipeline issues and quick resolution.
- Galileo: Provides a domain-driven AI observability solution that collects and analyzes relevant data during the operation of AI models and services, ensuring correctness, reliability, and effectiveness.
- Vellum: A platform that enables automated monitoring of ML pipelines, data, and models to identify and fix issues quickly, simplifying the monitoring of multiple ML models simultaneously.
- Promptmetheus: Focuses on enhancing the transparency of AI agents by providing insights into the factors influencing decision-making processes through techniques like model interpretability and feature importance analysis.
Curse of Optimization
There's nothing really insightful or interesting about just doing objective optimization. We've got plenty of good algorithms for doing that and it's not counterintuitive at all. It totally makes sense, but it's not going to get us hardly anywhere. Interesting whatsoever. It's kind of the curse of optimization And what that means is when you build an optimization system, you have to take a metric. You have to take a utility function or a cost function, and you have to optimize it, but then it suffers from the shortcut rule and good hot law. The shortcut rule is that you get what you optimize for exactly what you up to my support and nothing else, which means if you can't specify all of the richness and complexity that you want to capture in the cost function, then it's all gone. Then, good hearts law is this very interesting idea that when a target becomes a measure, it ceases to become a good measure, which means many of the systems. We design, including current social networks are divorced of all of the richness and creativity which exists in the real world. We need to create systems that capture the creative generative processes, which exist in our physical and social worlds. And with naïve objective optimization, it's impossible In my opinion, the reason why ChatGPT is the antithesis of creativity is its design to reduce entropy. It's designed to make things simple. Whereas a creative process is about producing new information. So there's a tug of war with things like GPT, which are centralized, because we have access to creativity, we have access to serendipitous novelty, and we can put it into gpt, but GPT is always pushing back on us. It wants to make things simple. This is model bias in order to produce a truly creative process, we need to design platforms which eliminate this centralizing force. - Kenneth O. O. Stanley
Stanley and Lehman begin with a surprising scientific discovery in artificial intelligence that leads ultimately to the conclusion that the objective obsession has gone too far. They make the case that great achievement can't be bottled up into mechanical metrics; that innovation is not driven by narrowly focused heroic effort; and that we would be wiser (and the outcomes better) if instead we whole-heartedly embraced serendipitous discovery and playful creativity.