Difference between revisions of "Decision Forest Regression"
m |
m |
||
| Line 28: | Line 28: | ||
Decision trees are non-parametric models that perform a sequence of simple tests for each instance, traversing a binary tree data structure until a leaf node (decision) is reached. Decision trees have these advantages: | Decision trees are non-parametric models that perform a sequence of simple tests for each instance, traversing a binary tree data structure until a leaf node (decision) is reached. Decision trees have these advantages: | ||
| − | * They are efficient in both computation and memory usage during training and prediction. | + | * They are efficient in both computation and [[memory]] usage during training and prediction. |
* They can represent non-linear decision boundaries. | * They can represent non-linear decision boundaries. | ||
* They perform integrated feature selection and classification and are resilient in the presence of noisy features. | * They perform integrated feature selection and classification and are resilient in the presence of noisy features. | ||
Revision as of 23:52, 1 March 2024
YouTube search... ...Google search
- AI Solver ... Algorithms ... Administration ... Model Search ... Discriminative vs. Generative ... Optimizer ... Train, Validate, and Test
- Regression Analysis
- Math for Intelligence ... Finding Paul Revere ... Social Network Analysis (SNA) ... Dot Product ... Kernel Trick
- Decision Forest Regression | Microsoft
- When to choose linear regresssion or Decision Tree or Random Forest regression? | Stack Exchange
- Data Science Concepts Explained to a Five-year-old | Megan Dibble - Toward Data Science
- Feature Exploration/Learning
Decision trees are non-parametric models that perform a sequence of simple tests for each instance, traversing a binary tree data structure until a leaf node (decision) is reached. Decision trees have these advantages:
- They are efficient in both computation and memory usage during training and prediction.
- They can represent non-linear decision boundaries.
- They perform integrated feature selection and classification and are resilient in the presence of noisy features.
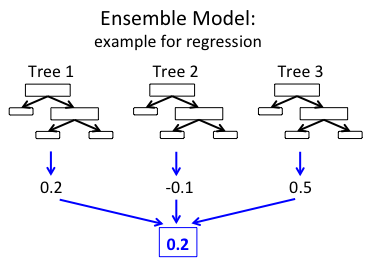
This regression model consists of an ensemble of decision trees. Each tree in a regression decision forest outputs a Gaussian distribution as a prediction. An aggregation is performed over the ensemble of trees to find a Gaussian distribution closest to the combined distribution for all trees in the model.