Difference between revisions of "Reinforcement Learning (RL)"
m |
m (→Lunar Lander: Deep Q learning is Easy in PyTorch) |
||
| Line 162: | Line 162: | ||
=== Jump Start === | === Jump Start === | ||
<youtube>sOiNMW8k4T0</youtube> | <youtube>sOiNMW8k4T0</youtube> | ||
| − | |||
| − | |||
| − | |||
=== Lunar Lander: How to Beat Lunar Lander with Policy Gradients | Tensorflow Tutorial === | === Lunar Lander: How to Beat Lunar Lander with Policy Gradients | Tensorflow Tutorial === | ||
Revision as of 09:16, 10 June 2023
YouTube ... Quora ...Google search ...Google News ...Bing News
- Artificial Intelligence (AI) ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Case Studies
- Capabilities
- Assistants ... Agents ... Negotiation ... LangChain
- Inverse Reinforcement Learning (IRL)
- Game Theory
- Policy ... Policy vs Plan ... Constitutional AI ... Trust Region Policy Optimization (TRPO) ... Policy Gradient (PG) ... Proximal Policy Optimization (PPO)
- Robotics
- Multi-Task Learning (MTL) ... SMART - Multi-Task Deep Neural Networks (MT-DNN)
- AdaNet
- Feedback Loop - The AI Economist
- Dopamine Google DeepMind
- Inside Out - Curious Optimistic Reasoning
- World Models
- Google DeepMind AlphaGo Zero
- Neural Architecture Search (NAS) with Reinforcement Learning | Barret Zoph & Quoc V. Le ...Wikipedia
- Beyond DQN/A3C: A Survey in Advanced Reinforcement Learning | Joyce Xu - Towards Data Science
- Google’s AI picks which machine learning models will produce the best results | Kyle Wiggers - VentureBeat off-policy classification,” or OPC, which evaluates the performance of AI-driven agents by treating evaluation as a classification problem
- Deep Reinforcement Learning Hands-On: Apply modern RL methods, with deep Q-networks, value iteration, policy gradients, TRPO, AlphaGo Zero and more | Maxim Lapan
- Reinforcement-Learning-Notebooks - A collection of Reinforcement Learning algorithms from Sutton and Barto's book and other research papers implemented in Python
- What is Reinforcement Learning? | Daniel Nelson - Unite.ai
- Reinforcement Learning (RL) | Wikipedia
- A Beginner's Guide to Deep Reinforcement Learning | Chris Nicholson - A.I. Wiki pathmind
- Use subject matter expertise in machine teaching and reinforcement learning | Microsoft
- Faster sorting algorithms discovered using deep reinforcement learning | D. Mankowitz, A. Michi, A. Zhernov, M. Gelmi, M. Selvi, C. Paduraru, E. Leurent, S. Iqbal, J. Lespiau, A. Ahern, T. Köppe, K. Millikin, S. Gaffney, S. Elster, J. Broshear, C. Gamble, K. Milan, R. Tung, M. Hwang, T. Cemgil, M. Barekatain, Y. Li, A. Mandhane, T. Hubert, D. Silver - Nature ... Deep reinforcement learning has been used to improve computer code by treating the task as a game — with no special knowledge needed on the part of the player. The result has already worked its way into countless programs.
Reinforcement Learning (RL) A technique that teaches an AI model to find the best result through trial and error and receiving rewards or punishments based on its results, often enhanced by human feedback for games and complex tasks.
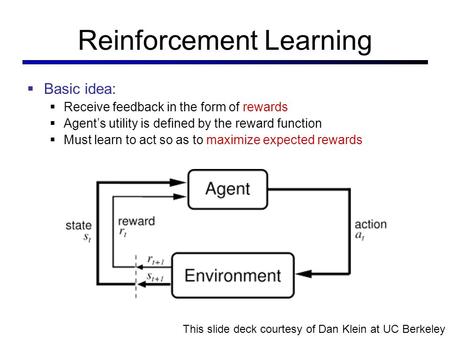
This is a bit similar to the traditional type of data analysis; the algorithm discovers through trial and error and decides which action results in greater rewards. Three major components can be identified in reinforcement learning functionality: the agent, the environment, and the actions. The agent is the learner or decision-maker, the environment includes everything that the agent interacts with, and the actions are what the agent can do. Reinforcement learning occurs when the agent chooses actions that maximize the expected reward over a given time. This is best achieved when the agent has a good policy to follow. Machine Learning: What it is and Why it Matters | Priyadharshini @ simplilearn
DeepMind says reinforcement learning is enough to reach Artificial General Intelligence (AGI)
...
Some scientists believe that assembling multiple narrow AI modules will produce higher intelligent systems.

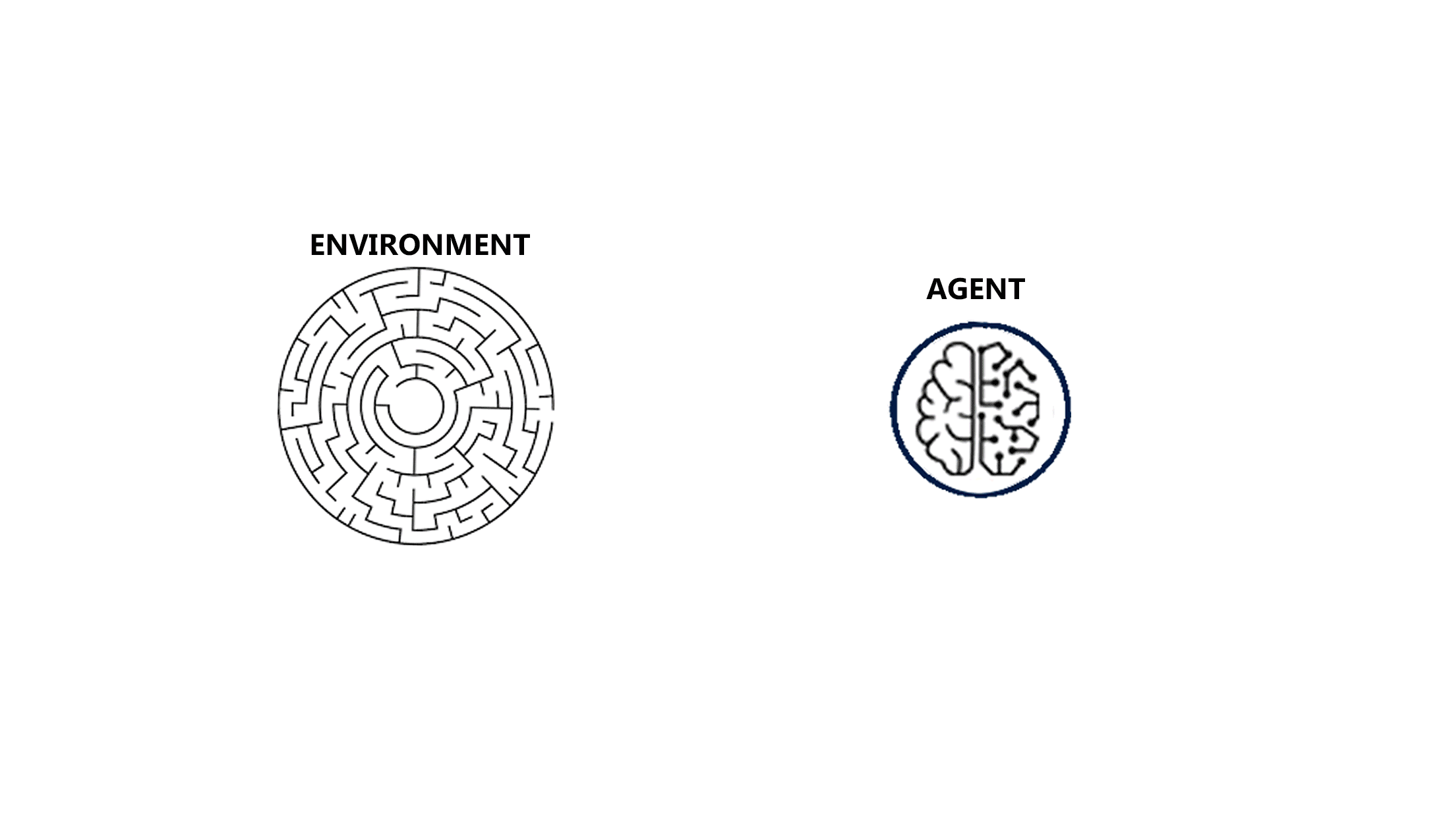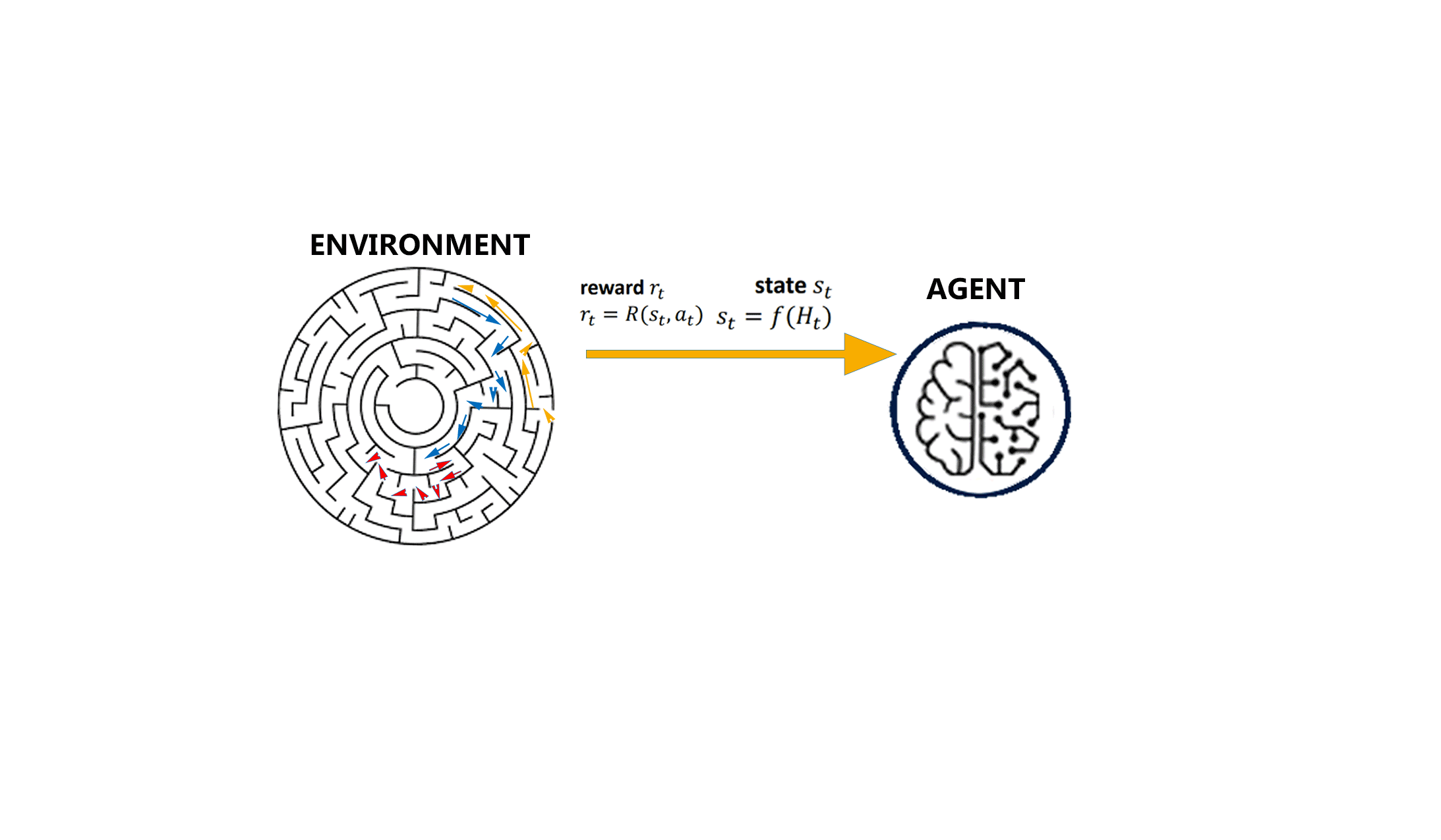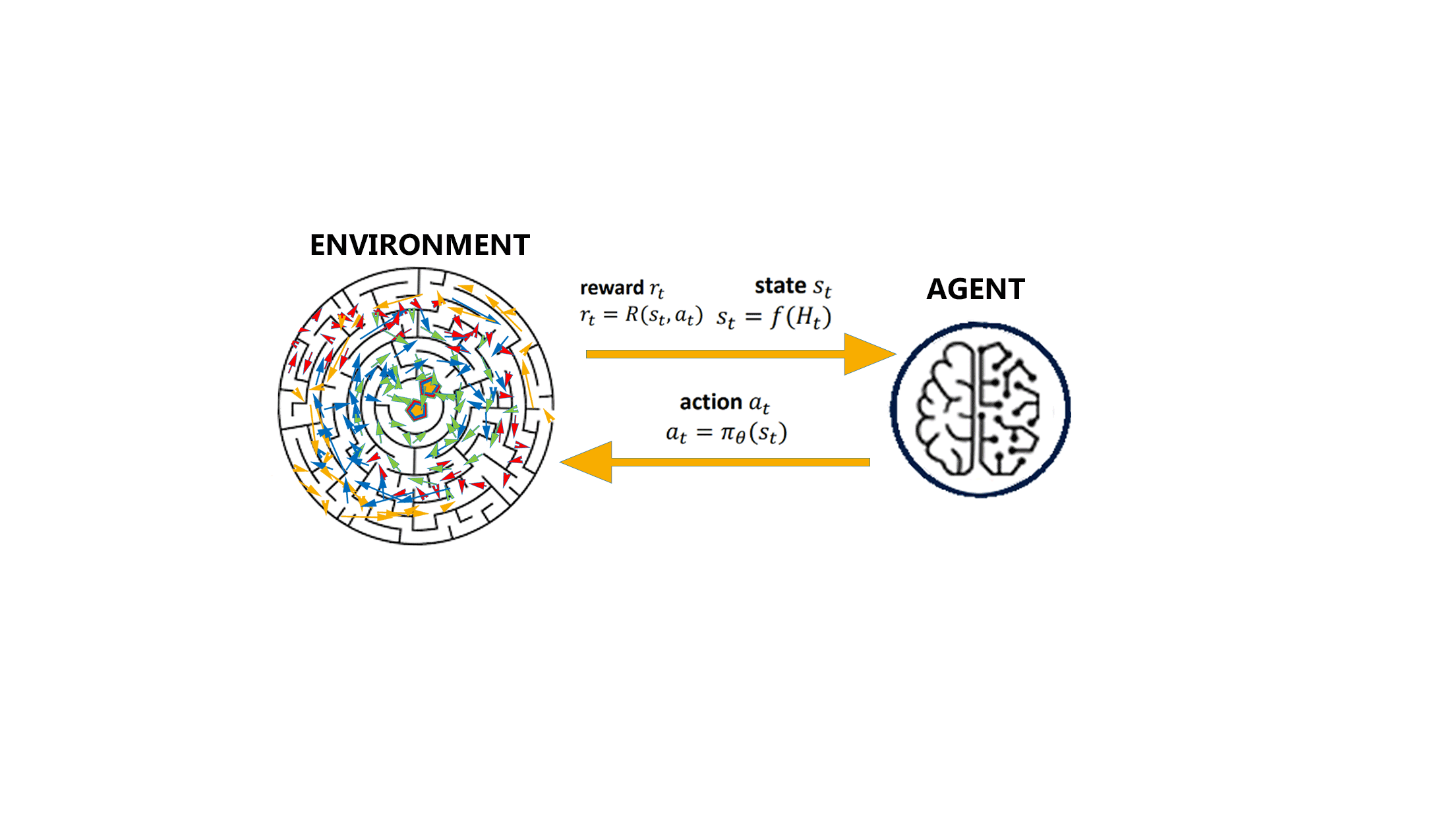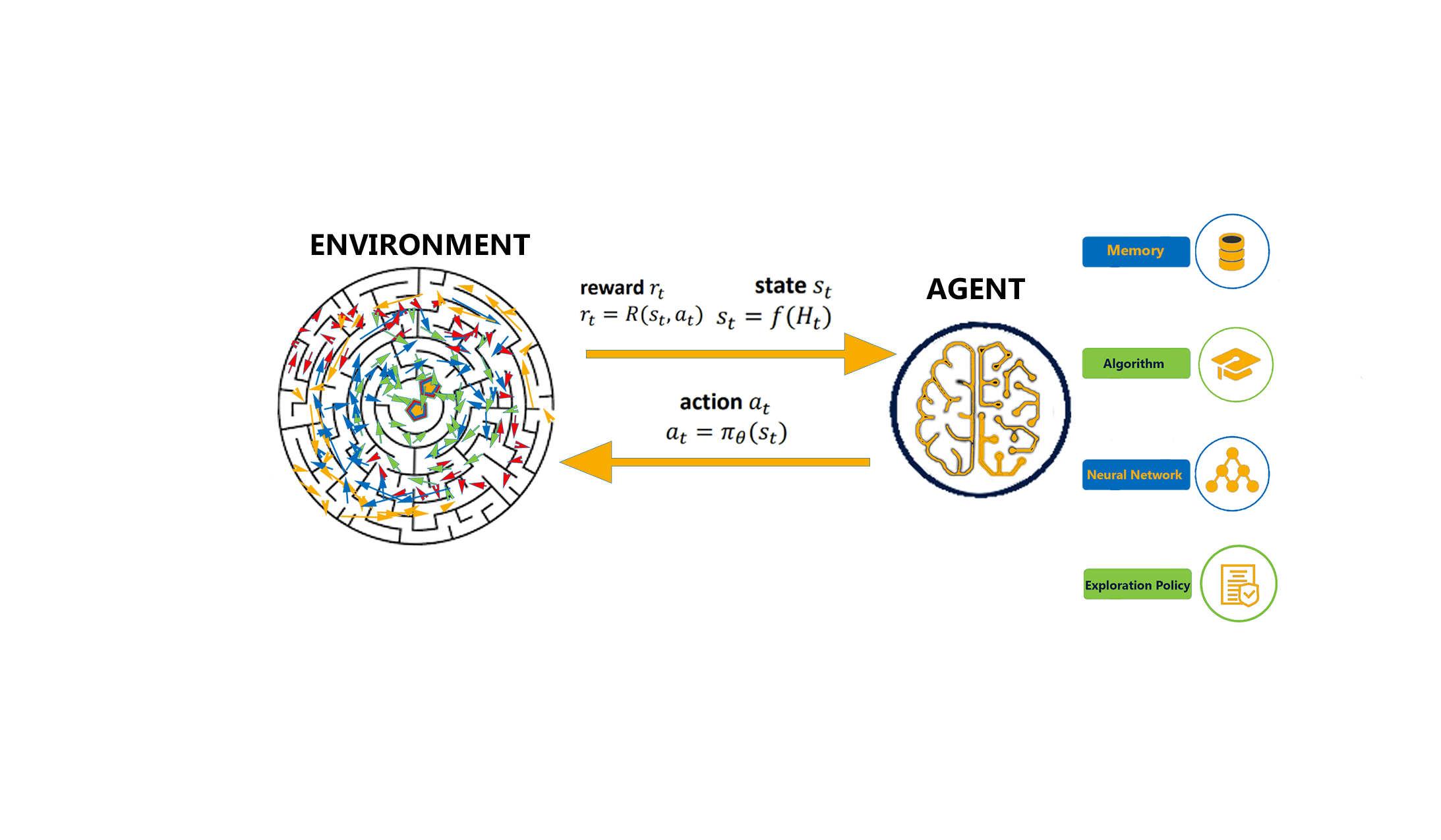
Control-based: When running a Reinforcement Learning (RL) policy in the real world, such as controlling a physical robot on visual inputs, it is non-trivial to properly track states, obtain reward signals or determine whether a goal is achieved for real. The visual data has a lot of noise that is irrelevant to the true state and thus the equivalence of states cannot be inferred from pixel-level comparison. Self-supervised representation learning has shown great potential in learning useful state embedding that can be used directly as input to a control policy.
Contents
[hide]Reinforcement Learning (RL) Algorithms
- Reinforcement Learning (RL) from Human Feedback (RLHF)
- In-context Reinforcement Learning
- Monte Carlo (MC) Method - Model Free Reinforcement Learning
- Markov Decision Process (MDP)
- State-Action-Reward-State-Action (SARSA)
- Q Learning
- Deep Reinforcement Learning (DRL) DeepRL
- Distributed Deep Reinforcement Learning (DDRL)
- Evolutionary Computation / Genetic Algorithms
- Actor Critic
- Hierarchical Reinforcement Learning (HRL)
- Apprenticeship Learning - Inverse Reinforcement Learning (IRL)
- Lifelong Learning
Q Learning Algorithm and Agent - Reinforcement Learning w/ Python Tutorial | Sentdex - Harrison
Reinforcement Learning | Phil Tabor
Reinforcement learning is an area of machine learning that involves taking right action to maximize reward in a particular situation. In this full tutorial course, you will get a solid foundation in reinforcement learning core topics. The course covers Q learning, State-Action-Reward-State-Action (SARSA), double Q learning, Deep Q Learning (DQN), and Policy Gradient (PG) methods. These algorithms are employed in a number of environments from the open AI gym, including space invaders, breakout, and others. The deep learning portion uses Tensorflow and PyTorch. The course begins with more modern algorithms, such as deep q learning and Policy Gradient (PG) methods, and demonstrates the power of reinforcement learning. Then the course teaches some of the fundamental concepts that power all reinforcement learning algorithms. These are illustrated by coding up some algorithms that predate deep learning, but are still foundational to the cutting edge. These are studied in some of the more traditional environments from the OpenAI Gym, like the cart pole problem.
⌨️ (00:00:00) Introduction
⌨️ (00:01:30) Intro to Deep Q Learning
⌨️ (00:08:56) How to Code Deep Q Learning in Tensorflow
⌨️ (00:52:03) Deep Q Learning with Pytorch Part 1: The Q Network
⌨️ (01:06:21) Deep Q Learning with Pytorch part 2: Coding the Agent
⌨️ (01:28:54) Deep Q Learning with Pytorch part 3
⌨️ (01:46:39) Intro to Policy Gradients 3: Coding the main loop
⌨️ (01:55:01) How to Beat Lunar Lander with Policy Gradients
⌨️ (02:21:32) How to Beat Space Invaders with Policy Gradients
⌨️ (02:34:41) How to Create Your Own Reinforcement Learning Environment Part 1
⌨️ (02:55:39) How to Create Your Own Reinforcement Learning Environment Part 2
⌨️ (03:08:20) Fundamentals of Reinforcement Learning
⌨️ (03:17:09) Markov Decision Processes
⌨️ (03:23:02) The Explore Exploit Dilemma
⌨️ (03:29:19) Reinforcement Learning in the Open AI Gym: SARSA
⌨️ (03:39:56) Reinforcement Learning in the Open AI Gym: Double Q Learning
⌨️ (03:54:07) Conclusion
Jump Start
Lunar Lander: How to Beat Lunar Lander with Policy Gradients | Tensorflow Tutorial
Breakout: How to Code Deep Q Learning in Tensorflow (Tutorial)
Gridworld: How To Create Your Own Reinforcement Learning Environments