Difference between revisions of "Natural Language Processing (NLP)"
(→Text Preprocessing) |
m |
||
| (316 intermediate revisions by the same user not shown) | |||
| Line 2: | Line 2: | ||
|title=PRIMO.ai | |title=PRIMO.ai | ||
|titlemode=append | |titlemode=append | ||
| − | |keywords=artificial, intelligence, machine, learning, models | + | |keywords=ChatGPT, artificial, intelligence, machine, learning, GPT-4, GPT-5, NLP, NLG, NLC, NLU, models, data, singularity, moonshot, Sentience, AGI, Emergence, Moonshot, Explainable, TensorFlow, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Hugging Face, OpenAI, Tensorflow, OpenAI, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Meta, LLM, metaverse, assistants, agents, digital twin, IoT, Transhumanism, Immersive Reality, Generative AI, Conversational AI, Perplexity, Bing, You, Bard, Ernie, prompt Engineering LangChain, Video/Image, Vision, End-to-End Speech, Synthesize Speech, Speech Recognition, Stanford, MIT |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools |
| − | |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | + | |
| + | <!-- Google tag (gtag.js) --> | ||
| + | <script async src="https://www.googletagmanager.com/gtag/js?id=G-4GCWLBVJ7T"></script> | ||
| + | <script> | ||
| + | window.dataLayer = window.dataLayer || []; | ||
| + | function gtag(){dataLayer.push(arguments);} | ||
| + | gtag('js', new Date()); | ||
| + | |||
| + | gtag('config', 'G-4GCWLBVJ7T'); | ||
| + | </script> | ||
}} | }} | ||
| − | [ | + | [https://www.youtube.com/results?search_query=ai+nlp+natural+language+Processing+text YouTube] |
| − | [ | + | [https://www.quora.com/search?q=ai%20nlp%20natural%20language%20Processing%20text ... Quora] |
| − | + | [https://www.google.com/search?q=ai+nlp+natural+language+Processing+text ...Google search] | |
| − | + | [https://news.google.com/search?q=ai+nlp+natural+language+Processing+text ...Google News] | |
| + | [https://www.bing.com/news/search?q=ai+nlp+natural+language+Processing+text&qft=interval%3d%228%22 ...Bing News] | ||
| − | * [ | + | * [[Natural Language Processing (NLP)]] ... [[Natural Language Generation (NLG)|Generation (NLG)]] ... [[Natural Language Classification (NLC)|Classification (NLC)]] ... [[Natural Language Processing (NLP)#Natural Language Understanding (NLU)|Understanding (NLU)]] ... [[Language Translation|Translation]] ... [[Summarization]] ... [[Sentiment Analysis|Sentiment]] ... [[Natural Language Tools & Services|Tools]] |
| − | * [[Natural Language | + | * [[Large Language Model (LLM)]] ... [[Large Language Model (LLM)#Multimodal|Multimodal]] ... [[Foundation Models (FM)]] ... [[Generative Pre-trained Transformer (GPT)|Generative Pre-trained]] ... [[Transformer]] ... [[GPT-4]] ... [[GPT-5]] ... [[Attention]] ... [[Generative Adversarial Network (GAN)|GAN]] ... [[Bidirectional Encoder Representations from Transformers (BERT)|BERT]] |
| − | * NLP Models: | + | * [[Case Studies]] |
| + | ** [[Social Science]] | ||
| + | ** [[Humor]] ... [[Writing/Publishing]] ... [[Storytelling]] ... [[AI Generated Broadcast Content|Broadcast]] ... [[Journalism|Journalism/News]] ... [[Podcasts]] ... [[Books, Radio & Movies - Exploring Possibilities]] | ||
| + | *** [https://newsletter.ruder.io/ NLP News | Sebastian Ruder] | ||
| + | ** [[Human Resources (HR)]] | ||
| + | * [[End-to-End Speech]] ... [[Synthesize Speech]] ... [[Speech Recognition]] ... [[Music]] ... (speech) translation, understanding (semantic parsing) complete sentences, understanding synonyms of matching words, [[Sentiment Analysis]], and [[Writing/Publishing|writing]]/generating complete grammatically correct sentences and paragraphs. | ||
| + | * [[Semantic Search]] | ||
| + | * [[Agents]] ... [[Robotic Process Automation (RPA)|Robotic Process Automation]] ... [[Assistants]] ... [[Personal Companions]] ... [[Personal Productivity|Productivity]] ... [[Email]] ... [[Negotiation]] ... [[LangChain]] | ||
| + | * [[What is Artificial Intelligence (AI)? | Artificial Intelligence (AI)]] ... [[Generative AI]] ... [[Machine Learning (ML)]] ... [[Deep Learning]] ... [[Neural Network]] ... [[Reinforcement Learning (RL)|Reinforcement]] ... [[Learning Techniques]] | ||
| + | * [[Conversational AI]] ... [[ChatGPT]] | [[OpenAI]] ... [[Bing/Copilot]] | [[Microsoft]] ... [[Gemini]] | [[Google]] ... [[Claude]] | [[Anthropic]] ... [[Perplexity]] ... [[You]] ... [[phind]] ... [[Ernie]] | [[Baidu]] | ||
| + | * [[Groq]] | ||
| + | * Wikipedia ([[Wiki]]): | ||
| + | ** [https://en.wikipedia.org/wiki/Outline_of_natural_language_processing#Natural_language_processing_tools Outline of Natural Language Processing] | ||
| + | ** [https://en.wikipedia.org/wiki/Natural_language_processing Natural Language Processing] | ||
| + | ** [https://en.wikipedia.org/wiki/Grammar_induction Grammar Induction] | ||
| + | * [[Courses & Certifications#Natural Language Processing (NLP)|Natural Language Processing (NLP)]] Courses & Certifications | ||
| + | * [https://gluebenchmark.com/leaderboard NLP Models:] | ||
| + | ** [[StructBERT]] - Alibaba Group's method to incorporate language structures into pre-training | ||
| + | ** [[T5]] - Google's Text-To-Text Transfer Transformer model. | ||
| + | ** [[ERNIE]] - Baidu ensemble | ||
| + | ** [[SMART - Multi-Task Deep Neural Networks (MT-DNN)]] Microsoft Research & GATECH train the tasks MT-DNN and HNN models starting with RoBERTa | ||
** [[XLNet]] - unsupervised language representation learning method based on [[Transformer-XL]] and a novel generalized permutation language modeling objective | ** [[XLNet]] - unsupervised language representation learning method based on [[Transformer-XL]] and a novel generalized permutation language modeling objective | ||
| − | ** [[Bidirectional Encoder Representations from Transformers (BERT)]] | Google - built on ideas from [[ULMFiT]], [[ELMo]], and [ | + | ** [[Bidirectional Encoder Representations from Transformers (BERT)]] | Google - built on ideas from [[ULMFiT]], [[ELMo]], and [[OpenAI]] |
** [[Transformer-XL]] - state-of-the-art autoregressive model | ** [[Transformer-XL]] - state-of-the-art autoregressive model | ||
| − | ** GPT-2 | + | ** GPT-2 [[OpenAI]]… [https://towardsdatascience.com/too-powerful-nlp-model-generative-pre-training-2-4cc6afb6655 GPT-2 - Too powerful NLP model (GPT-2) | Edward Ma - Towards Data Science] |
** [[Attention]] Mechanism/[[Transformer]] Model | ** [[Attention]] Mechanism/[[Transformer]] Model | ||
| − | ** [[Recurrent Neural Network (RNN)]] | + | ** Previous Efforts: |
| − | *** [[Average-Stochastic Gradient Descent (SGD) Weight-Dropped LSTM (AWD-LSTM)]] | + | *** [[Autoencoder (AE) / Encoder-Decoder]] |
| − | * [ | + | *** [[Gated Recurrent Unit (GRU)]] |
| − | + | *** [[Deep Q Network (DQN)]] | |
| − | * [ | + | *** [[Recurrent Neural Network (RNN)]] |
| − | + | *** [[Long Short-Term Memory (LSTM)]] | |
| − | * [ | + | **** [[Average-Stochastic Gradient Descent (SGD) Weight-Dropped LSTM (AWD-LSTM)]] |
| − | * [ | + | * [https://hint.fm/seer/ For fun: Web Seer] Google complete ...for one query... 'cats are'...for the other 'dogs are' |
| − | * [ | + | * [https://pathmind.com/wiki/thought-vectors Thought Vectors | Geoffrey Hinton - A.I. Wiki - pathmind] |
| − | * [ | + | * [https://medium.com/@datamonsters/artificial-neural-networks-for-natural-language-processing-part-1-64ca9ebfa3b2 7 types of Artificial Neural Networks for Natural Language Processing] |
| − | * [[ | + | * [https://www.quora.com/How-do-I-learn-Natural-Language-Processing How do I learn Natural Language Processing? | Sanket Gupta] |
| − | + | * [https://www.chrisumbel.com/article/node_js_natural_language_nlp Natural Language | Chris Umbel] | |
| − | ** [ | + | * [https://azure.microsoft.com/en-us/services/cognitive-services/directory/lang/ Language services | Cognitive Services | Microsoft Azure] |
| − | ** [ | + | * [https://www.tutorialspoint.com/natural_language_processing/natural_language_processing_quick_guide.htm Natural Language Processing - Quick Guide | TutorialsPoint] |
| − | ** [ | + | * [https://web.stanford.edu/~jurafsky/slp3/ Speech and Language Processing | Dan Jurafsky and James H. Martin] (3rd ed. draft) |
| − | + | * [https://nlp.stanford.edu/projects/snli/ The Stanford Natural Language Inference (SNLI) Corpus] | |
| − | + | * NLP/NLU/NLI [[Benchmarks]]: | |
| + | ** [[Benchmarks#GLUE|General Language Understanding Evaluation (GLUE)]] | ||
| + | ** [[Benchmarks#SQuAD|The Stanford Question Answering Dataset (SQuAD)]] | ||
| + | ** [[Benchmarks#RACE|ReAding Comprehension (RACE)]] | ||
| + | * [https://quac.ai/ Question Answering in Context (QuAC)] ...Question Answering in [[Context]] for modeling, understanding, and participating in information seeking dialog. | ||
| + | * [https://www.topbots.com/leading-nlp-language-models-2020/ 10 Leading Language Models For NLP In 2022 | Mariya Yao - TOPBOTS] | ||
| + | |||
| + | |||
| + | <b>Natural Language Processing (NLP)</b> are techniques used by to understand and generate human language, including text classification and [[Sentiment Analysis]], using machine learning algorithms, statistical models, and linguistic rules. e.g. [[Large Language Model (LLM)]] | ||
| + | |||
| + | Over the last two years, the Natural Language Processing community has witnessed an acceleration in progress on a wide range of different tasks and applications. This progress was enabled by a shift of paradigm in the way we classically build an NLP system [https://medium.com/huggingface/the-best-and-most-current-of-modern-natural-language-processing-5055f409a1d1 The Best and Most Current of Modern Natural Language Processing | Victor Sanh - Medium]: | ||
| + | * For a long time, we used pre-trained word [[embedding]]s such as [[Word2Vec]] or [[Global Vectors for Word Representation (GloVe)]] to initialize the first layer of a neural network, followed by a task-specific architecture that is trained in a supervised way using a single dataset. | ||
| + | * Recently, several works demonstrated that we can learn hierarchical [[context]]ualized representations on web-scale datasets leveraging unsupervised (or self-supervised) signals such as language modeling and transfer this pre-training to downstream tasks ([[Transfer Learning]]). Excitingly, this shift led to significant advances on a wide range of downstream applications ranging from Question Answering, to Natural Language Inference through Syntactic Parsing… | ||
| + | |||
| + | <img src="https://mobidev.biz/wp-content/uploads/2019/12/natural-language-processing-nlp-tasks.png" width="800" height="600"> | ||
| + | |||
| + | |||
| + | https://images.xenonstack.com/blog/future-applications-of-nlp.png [https://www.xenonstack.com/blog/artificial-intelligence/ Artificial Intelligence Overview and Applications | Jagreet Kaur Gill] | ||
| + | |||
| + | = <span id="Capabilities"></span>Capabilities = | ||
| + | |||
| + | * [[Agents#AI-Powered Search|AI-Powered Search]] | ||
| + | * [[Automated Scoring]] | ||
| + | * [[Language Translation]] | ||
| + | * [[Assistants]] - Dialog Systems | ||
| + | * [[Summarization / Paraphrasing]] | ||
| + | * [[Sentiment Analysis]] | ||
| + | * [[Wikifier]] | ||
| + | * [[Natural Language Generation (NLG)]] ...Text [[Analytics]] | ||
| + | |||
| + | <img src="https://www.e-spirit.com/images/Blog/2018/07_NLG_future_of_content_management/NLG_Future_of_Content_Management_Content_01.png" width="900" height="450"> | ||
| + | |||
| + | = <span id="Natural Language Understanding (NLU)"></span>Natural Language Understanding (NLU) = | ||
| + | [https://www.youtube.com/results?search_query=Understanding+NLU+natural+language+inference+entailment+RTE+Text+Speech Youtube search...] | [https://www.quora.com/topic/Natural-Language-Processing Quora search...] | ||
| + | [https://www.google.com/search?q=Understanding+NLU+nli+natural+language+inference+entailment+RTE+Text+Speech ...Google search] | ||
| + | |||
| + | * [[Natural Language Processing (NLP)]] ... [[Natural Language Generation (NLG)|Generation (NLG)]] ... [[Natural Language Classification (NLC)|Classification (NLC)]] ... [[Natural Language Processing (NLP)#Natural Language Understanding (NLU)|Understanding (NLU)]] ... [[Language Translation|Translation]] ... [[Summarization]] ... [[Sentiment Analysis|Sentiment]] ... [[Natural Language Tools & Services|Tools]] | ||
| + | * [[Large Language Model (LLM)]] ... [[Large Language Model (LLM)#Multimodal|Multimodal]] ... [[Foundation Models (FM)]] ... [[Generative Pre-trained Transformer (GPT)|Generative Pre-trained]] ... [[Transformer]] ... [[GPT-4]] ... [[GPT-5]] ... [[Attention]] ... [[Generative Adversarial Network (GAN)|GAN]] ... [[Bidirectional Encoder Representations from Transformers (BERT)|BERT]] | ||
| + | * [[Natural Language Processing (NLP)#Phonology (Phonetics)|Phonology (Phonetics)]] | ||
| + | * [[Natural Language Processing (NLP)#Lexical (Morphology)|Lexical (Morphology)]] | ||
| + | * [[Natural Language Processing (NLP)#Syntax (Parsing)| Syntax (Parsing)]] | ||
| + | * [[Natural Language Processing (NLP)#Semantics| Semantics]] | ||
| + | * [[Natural Language Processing (NLP)#Discourse (Dialog)| Discourse (Dialog)]] | ||
| + | * [[Natural Language Processing (NLP)#Pragmatics| Pragmatics]] | ||
| + | * [https://www.chatpdf.com/ ChatPDF] ... upload any PDF file and essentially “Chat” with it, including long research papers | ||
| + | |||
| + | |||
| + | Natural-language understanding (NLU) or natural-language interpretation (NLI) is a subtopic of natural-language processing in artificial intelligence that deals with machine reading comprehension. There is considerable commercial interest in the field because of its application to automated reasoning, machine translation, question answering, news-gathering, text categorization, voice-activation, archiving, and large-scale content analysis. | ||
| + | |||
| + | NLU is the post-processing of text, after the use of NLP algorithms (identifying parts-of-speech, etc.), that utilizes [[context]] from recognition devices; automatic [[Speech Recognition| speech recognition]] (ASR), vision recognition, last conversation, misrecognized words from ASR, personalized profiles, microphone proximity etc.), in all of its forms, to discern meaning of fragmented and run-on sentences to execute an intent from typically voice commands. NLU has an [[Graph#Ontology|ontology]] around the particular product vertical that is used to figure out the probability of some intent. An NLU has a defined list of known intents that derives the message payload from designated [[context]]ual information recognition sources. The NLU will provide back multiple message outputs to separate services (software) or resources (hardware) from a single derived intent (response to voice command initiator with visual sentence (shown or spoken) and transformed voice command message too different output messages to be consumed for M2M communications and actions) [https://en.wikipedia.org/wiki/Natural-language_understanding Natural-language understanding | Wikipedia] | ||
| + | |||
| + | NLU uses algorithms to reduce human speech into a structured [[Graph#Ontology|ontology]]. Then AI algorithms detect such things as intent, timing, locations, and sentiments. ... Natural language understanding is the first step in many processes, such as categorizing text, gathering news, archiving individual pieces of text, and, on a larger scale, analyzing content. Real-world examples of NLU range from small tasks like issuing short commands based on comprehending text to some small degree, like rerouting an email to the right person based on basic syntax and a decently-sized lexicon. Much more complex endeavors might be fully comprehending news articles or shades of meaning within poetry or novels. [https://www.kdnuggets.com/2019/07/nlp-vs-nlu-understanding-language-processing.html NLP vs. NLU: from Understanding a Language to Its Processing | Sciforce] | ||
| + | |||
| + | https://cdn-images-1.medium.com/max/1000/1*Uf_qQ0zF8G8y9zUhndA08w.png | ||
| + | |||
| + | Image Source: [https://nlp.stanford.edu/~wcmac/papers/20140716-UNLU.pdf Understanding Natural Language Understanding | Bill MacCartney] | ||
| + | |||
| + | <youtube>Io0VfObzntA</youtube> | ||
| + | <youtube>mhHfnhh-pB4</youtube> | ||
| + | <youtube>1-8KJV8aSQM</youtube> | ||
| + | <youtube>ycXWAtm22-w</youtube> | ||
| + | |||
| + | |||
| + | |||
| + | |||
| + | [https://cobusgreyling.medium.com/the-cobus-quadrant-of-nlu-design-4b1654f21d70 NLU Design Landscape | Cobus Greyling - Medium] | ||
| + | |||
| + | == <span id="Phonology (Phonetics)"></span>[https://en.wikipedia.org/wiki/Phonology Phonology (Phonetics)] == | ||
| + | [https://www.youtube.com/results?search_query=phonetics+phoneme+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=phonetics+phoneme+nlp+natural+language ...Google search] | ||
| + | |||
| + | Phonology is a branch of linguistics concerned with the systematic organization of sounds in spoken languages and signs in sign languages. It used to be only the study of the systems of phonemes in spoken languages (and therefore used to be also called phonemics, or phonematics), but it may also cover any linguistic analysis either at a level beneath the word (including syllable, onset and rime, articulatory gestures, articulatory features, mora, etc.) or at all levels of language where sound or signs are structured to convey linguistic meaning. | ||
| − | < | + | A <b>Phoneme</b> is the most basic sound unit of sound; any of the perceptually distinct units of sound in a specified language that distinguish one word from another, for example p, b, d, and t in the English words pad, pat, bad, and bat. [https://en.wikipedia.org/wiki/Phoneme Phoneme | Wikipedia] |
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | A <b>Grapheme</b> is the smallest unit of a [[Writing/Publishing|writing]] system of any given language. An individual grapheme may or may not carry meaning by itself, and may or may not correspond to a single phoneme of the spoken language | |
| − | |||
| − | [ | ||
| − | |||
| − | + | <youtube>IKS2DQ_6RHQ</youtube> | |
| − | + | <youtube>OlCtIqsqvrY</youtube> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | < | + | == <span id="Lexical (Morphology)"></span>[https://en.wikipedia.org/wiki/Morphology_(linguistics) Lexical (Morphology)] == |
| − | < | + | <b>Lexical Ambiguity</b> – Words have multiple meanings |
| + | The study of words, how they are formed, and their relationship to other words in the same language. It analyzes the structure of words and parts of words, such as stems, root words, prefixes, and suffixes. Morphology also looks at parts of speech, intonation and stress, and the ways [[context]] can change a word's pronunciation and meaning.About the words that make up the sentence, how they are formed, and how do they change depending on their [[context]]. Some examples of these include: | ||
| + | * Prefixes/suffixes | ||
| + | * Singularization/pluralization | ||
| + | * Gender detection | ||
| + | * Word inflection (modification of word to express different grammatical categories such tenses, case, voice etc..). Other forms of inflection includes conjugation (inflection of verbs) and declension (inflection of nouns, adjectives, adverbs etc…). | ||
| + | * Lemmatization (the base form of the word, or the reverse of inflection) | ||
| + | * Spell checking | ||
| − | == <span id="Text Preprocessing"></span>Text Preprocessing == | + | === <span id="Text Preprocessing"></span>Text Preprocessing === |
Cleaning and preparation the information for use, such as punctuation removal, spelling correction, lowercasing, stripping markup tags (HTML,XML) | Cleaning and preparation the information for use, such as punctuation removal, spelling correction, lowercasing, stripping markup tags (HTML,XML) | ||
| − | * [ | + | * [https://archive.org/stream/NoamChomskySyntcaticStructures/Noam%20Chomsky%20-%20Syntcatic%20structures_djvu.txt Syntactic Structures |] [[Creatives#Noam Chomsky |Noam Chomsky]] |
| − | + | <youtube>nxhCyeRR75Q</youtube> | |
| − | + | ==== <span id="Regular Expressions (Regex)"></span>Regular Expressions (Regex) ==== | |
| − | |||
| − | + | [https://www.youtube.com/results?search_query=Regex+Regular+Expression+nlp+natural+language Youtube search...] | |
| + | [https://www.google.com/search?q=Regex+Regular+Expression+nlp+natural+language ...Google search] | ||
| − | + | * [https://app.pluralsight.com/library/courses/code-school-breaking-the-ice-with-regular-expressions/table-of-contents Breaking the Ice with Regular Expressions | Code Schol] | |
| + | * [[Web Automation]] | ||
| − | + | Search for text patterns, validate emails and URLs, capture information, and use patterns to save [[development]] time. | |
| + | |||
| + | https://twiki.org/p/pub/Codev/TWikiPresentation2013x03x07/regex-example.png | ||
<youtube>VrT3TRDDE4M</youtube> | <youtube>VrT3TRDDE4M</youtube> | ||
| − | === | + | ==== <span id="Soundex"></span>Soundex ==== |
| + | [https://www.youtube.com/results?search_query=Soundex+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=Soundex+nlp+natural+language ...Google search] | ||
| + | |||
| + | a phonetic algorithm for indexing names by sound, as pronounced in English. The goal is for homophones to be encoded to the same representation so that they can be matched despite minor differences in spelling. The Soundex code for a name consists of a Letter alphabet followed by three numerical digits: the letter is the first letter of the name, and the digits encode the remaining consonants. Consonants at a similar place of articulation share the same digit so, for example, the labial consonants B, F, P, and V are each encoded as the number 1. [https://en.wikipedia.org/wiki/Soundex Wikipedia] | ||
| + | |||
| + | The correct value can be found as follows: | ||
| + | #Retain the first letter of the name and drop all other occurrences of a, e, i, o, u, y, h, w. | ||
| + | # Replace consonants with digits as follows (after the first letter): | ||
| + | #* b, f, p, v → 1 | ||
| + | #* c, g, j, k, q, s, x, z → 2 | ||
| + | #* d, t → 3 | ||
| + | #* l → 4 | ||
| + | #* m, n → 5 | ||
| + | #* r → 6 | ||
| + | # If two or more letters with the same number are adjacent in the original name (before step 1), only retain the first letter; also two letters with the same number separated by 'h' or 'w' are coded as a single number, whereas such letters separated by a vowel are coded twice. This rule also applies to the first letter. | ||
| + | # If you have too few letters in your word that you can't assign three numbers, append with zeros until there are three numbers. If you have more than 3 letters, just retain the first 3 numbers. | ||
| + | |||
| + | <youtube>GBkKn_ty_Hs</youtube> | ||
| + | |||
| − | + | === <span id="Tokenization / Sentence Splitting"></span>Tokenization / Sentence Splitting === | |
| − | [ | + | [https://www.youtube.com/results?search_query=Tokenization+Sentence+Splitting+nlp+natural+language Youtube search...] |
| − | [ | + | [https://www.google.com/search?q=Tokenization+Sentence+Splitting+nlp+natural+language ...Google search] |
* [[Bag-of-Words (BoW)]] | * [[Bag-of-Words (BoW)]] | ||
* [[Continuous Bag-of-Words (CBoW)]] | * [[Continuous Bag-of-Words (CBoW)]] | ||
| − | * [ | + | * [https://books.google.com/ngrams Ngram Viewer | Google Books] |
| − | + | ** [https://books.google.com/ngrams/info Ngram Viewer Info] | |
| − | ** [ | + | * [https://www.languagesquad.com/ Language Squad] The Greatest Language Identifying & Guessing Game |
Tokenization is the process of demarcating (breaking text into individual words) and possibly classifying sections of a string of input characters. The resulting tokens are then passed on to some other form of processing. The process can be considered a sub-task of parsing input. A token (or n-gram) is a contiguous sequence of n items from a given sample of text or speech. The items can be phonemes, syllables, letters, words or base pairs according to the application. | Tokenization is the process of demarcating (breaking text into individual words) and possibly classifying sections of a string of input characters. The resulting tokens are then passed on to some other form of processing. The process can be considered a sub-task of parsing input. A token (or n-gram) is a contiguous sequence of n items from a given sample of text or speech. The items can be phonemes, syllables, letters, words or base pairs according to the application. | ||
| − | + | https://www.researchgate.net/profile/Amelia_Carolina_Sparavigna/publication/286134641/figure/fig5/AS:309159452004356@1450720765824/In-this-time-series-Google-Ngram-Viewer-is-used-to-compare-some-literature-for-children.png | |
| − | |||
<youtube>FLZvOKSCkxY</youtube> | <youtube>FLZvOKSCkxY</youtube> | ||
<youtube>4nMP24xhuWg</youtube> | <youtube>4nMP24xhuWg</youtube> | ||
<youtube>z4UbVNRnZM4</youtube> | <youtube>z4UbVNRnZM4</youtube> | ||
<youtube>qzbjPq8vwx8</youtube> | <youtube>qzbjPq8vwx8</youtube> | ||
| + | <youtube>7YacOe4XwhY</youtube> | ||
| + | |||
| + | === <span id="Normalization"></span>[https://nlp.stanford.edu/IR-book/html/htmledition/normalization-equivalence-classing-of-terms-1.html Normalization] === | ||
| + | [https://www.youtube.com/results?search_query=Normalization+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=Normalization+nlp+natural+language ...Google search] | ||
| + | |||
| + | Process that converts a list of words to a more uniform sequence. . | ||
| + | |||
| + | <youtube>207x-6KvXK8</youtube> | ||
| + | <youtube>2H34SM66xdk</youtube> | ||
| + | |||
| + | ==== <span id="Stemming (Morphological Similarity)"></span>Stemming (Morphological Similarity) ==== | ||
| + | [https://www.youtube.com/results?search_query=Stemming+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=Stemming+nlp+natural+language ...Google search] | ||
| + | |||
| + | * [https://www.nltk.org/howto/stem.html Stemmers | NLTK] | ||
| + | |||
| + | Stemmers remove morphological affixes from words, leaving only the word stem. Refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes. | ||
| + | |||
| + | https://leanjavaengineering.files.wordpress.com/2012/02/figure3.png | ||
| + | |||
| + | <youtube>yGKTphqxR9Q</youtube> | ||
| + | <youtube>hdwhI3VYO5A</youtube> | ||
| + | |||
| + | ==== <span id="Lemmatization"></span>Lemmatization ==== | ||
| + | [https://www.youtube.com/results?search_query=Lemmatization+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=Lemmatization+nlp+natural+language ...Google search] | ||
| + | |||
| + | Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma . If confronted with the token saw, stemming might return just s, whereas lemmatization would attempt to return either see or saw depending on whether the use of the token was as a verb or a noun. The two may also differ in that stemming most commonly collapses derivationally related words, whereas lemmatization commonly only collapses the different inflectional forms of a lemma. [https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html Stemming and lemmatization | Stanford.edu] NLTK's lemmatizer knows "am" and "are" are related to "be." | ||
| + | |||
| + | <img src="https://searchingforbole.files.wordpress.com/2018/01/re-learning-english-multiple1.png" width="500" height="400"> | ||
| + | |||
| + | <youtube>uoHVztKY6S4</youtube> | ||
| + | <youtube>beGwzQVKLNQ</youtube> | ||
| + | |||
| + | ==== <span id="Capitalization / Case Folding"></span>Capitalization / Case Folding ==== | ||
| + | [https://www.youtube.com/results?search_query=Case+Folding+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=Case+Folding+nlp+natural+language ...Google search] | ||
| + | |||
| + | A common strategy is to do case-folding by reducing all letters to lower case. Often this is a good idea: it will allow instances of Automobile at the beginning of a sentence to match with a query of automobile. It will also help on a web search engine when most of your users type in ferrari when they are interested in a Ferrari car. On the other hand, such case folding can equate words that might better be kept apart. Many proper nouns are derived from common nouns and so are distinguished only by case, including companies (General Motors, The Associated Press), government organizations (the Fed vs. fed) and person names (Bush, Black). We already mentioned an example of unintended query expansion with acronyms, which involved not only acronym normalization (C.A.T. $\rightarrow$ CAT) but also case-folding (CAT $\rightarrow$ cat). [https://nlp.stanford.edu/IR-book/html/htmledition/capitalizationcase-folding-1.html Capitalization/case-folding | Stanford] | ||
| + | |||
| + | === <span id="Similarity"></span>Similarity === | ||
| + | [https://www.youtube.com/results?search_query=text+word+sentence+document+similarity+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=text+word+sentence+document+similarity+similarity+nlp+natural+language ...Google search] | ||
| + | |||
| + | ==== <span id="Word Similarity"></span>Word Similarity ==== | ||
| + | [https://www.youtube.com/results?search_query=word+similarity+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=word+similarity+similarity+nlp+natural+language ...Google search] | ||
| + | |||
| + | * [https://towardsdatascience.com/mapping-word-embeddings-with-word2vec-99a799dc9695 Mapping Word Embeddings with Word2vec | Sam Liebman - Towards Data Science] | ||
| + | * [[Word2Vec]] | ||
| + | * [https://wordnet.princeton.edu/ WordNet] - One of the most important uses is to find out the similarity among words | ||
| + | |||
| + | <img src="https://miro.medium.com/max/700/1*vvtIsW1AblmgLkq1peKfOg.png" width="700" height="600"> | ||
| + | |||
| + | ==== <span id="Text Clustering"></span>Text Clustering ==== | ||
| + | [https://www.youtube.com/results?search_query=text+Clustering+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=text+Clustering+nlp+natural+language ...Google search] | ||
| + | |||
| + | * [[Latent Dirichlet Allocation (LDA)]] | ||
| + | |||
| + | https://brandonrose.org/header_short.jpg | ||
| + | |||
| + | <youtube>WY5MdnhoG9w</youtube> | ||
| + | <youtube>yK7NWZ9BLy8</youtube> | ||
| + | |||
| + | |||
| + | |||
| + | <hr> | ||
| + | |||
| + | == <span id="Syntax (Parsing)"></span>[https://en.wikipedia.org/wiki/Syntax Syntax (Parsing)] == | ||
| + | |||
| + | * [https://corenlp.run/ CoreNLP - see NLP parsing techniques by pasting your text | Stanford] in [[Natural Language Tools & Services]] | ||
| + | |||
| − | |||
| − | |||
| − | |||
| − | + | <b>Syntactic Ambiguity </b> – Sentence is having multiple parse trees. | |
| − | + | The set of rules, principles, and processes that govern the structure of sentences (sentence structure) in a given language, usually including word order. The term syntax is also used to refer to the study of such principles and processes. Focus on the relationship of the words within a sentence — how a sentence is constructed. In a way, syntax is what we usually refer to as grammar. To derive this understanding, syntactical analysis is usually done at a sentence-level, where as for morphology the analysis is done at word level. When we’re building dependency trees or processing parts-of-speech — we’re basically analyzing the syntax of the sentence. | |
| − | + | https://miro.medium.com/max/1062/1*Bi_s86b68I5kDEC2kmU39A.png | |
| − | |||
| − | * | ||
=== <span id="Identity Scrubbing"></span>Identity Scrubbing === | === <span id="Identity Scrubbing"></span>Identity Scrubbing === | ||
| − | [ | + | [https://www.youtube.com/results?search_query=Identity+ID+Scrubbing+scrubber+MIST+nlp+natural+language Youtube search...] |
| − | [ | + | [https://www.google.com/search?q=Identity+ID+Scrubbing+scrubber+MIST+nlp+natural+language ...Google search] |
| − | * [ | + | * [https://mist-deid.sourceforge.net/ MITRE Identification Scrubber Toolkit (MIST)] ...suite of tools for identifying and redacting personally identifiable information (PII) in free-text. For example, MIST can help you convert this document: |
<b>Patient ID: P89474</b> | <b>Patient ID: P89474</b> | ||
| Line 153: | Line 333: | ||
=== <span id="Stop Words"></span>Stop Words === | === <span id="Stop Words"></span>Stop Words === | ||
| − | [ | + | [https://www.youtube.com/results?search_query=Stop+Words+Sentence+Splitting+nlp+natural+language Youtube search...] |
| − | [ | + | [https://www.google.com/search?q=Stop+Words+Sentence+Splitting+nlp+natural+language ...Google search] |
* [https://www.geeksforgeeks.org/removing-stop-words-nltk-python/ Removing stop words with NLTK in Python | GeeksforGeeks] | * [https://www.geeksforgeeks.org/removing-stop-words-nltk-python/ Removing stop words with NLTK in Python | GeeksforGeeks] | ||
| Line 160: | Line 340: | ||
One of the major forms of pre-processing is to filter out useless data. In natural language processing, useless words (data), are referred to as stop words. A stop word is a commonly used word (such as “the”, “a”, “an”, “in”) that a search engine has been programmed to ignore, both when indexing entries for searching and when retrieving them as the result of a search query. | One of the major forms of pre-processing is to filter out useless data. In natural language processing, useless words (data), are referred to as stop words. A stop word is a commonly used word (such as “the”, “a”, “an”, “in”) that a search engine has been programmed to ignore, both when indexing entries for searching and when retrieving them as the result of a search query. | ||
| − | + | https://www.geeksforgeeks.org/wp-content/uploads/Stop-word-removal-using-NLTK.png | |
<youtube>w36-U-ccajM</youtube> | <youtube>w36-U-ccajM</youtube> | ||
<youtube>DxCwtkrYR-s</youtube> | <youtube>DxCwtkrYR-s</youtube> | ||
| − | === <span id=" | + | === <span id="Relating Text"></span>Relating Text === |
| − | + | Understanding how the words relate to each other and the underlying grammar by segmenting the sentences syntax | |
| − | |||
| − | |||
| − | |||
| − | + | * [https://pmbaumgartner.github.io/blog/holy-nlp/ Holy NLP! Understanding Part of Speech Tags, Dependency Parsing, and Named Entity Recognition | Peter Baumgartner] | |
| − | < | + | ==== <span id="Part-of-Speech (POS) Tagging"></span>Part-of-Speech (POS) Tagging ==== |
| − | + | [https://www.youtube.com/results?search_query=POS+Part+Speech+nlp+natural+language Youtube search...] | |
| + | [https://www.google.com/search?q=POS+Part+Speech+nlp+natural+language ...Google search] | ||
| − | + | * [https://www.nltk.org/book/ch05.html Categorizing and Tagging Words | NLTK.org] | |
| − | [ | + | * [https://web.stanford.edu/class/cs124/lec/postagging.pdf Part-of-Speech Tagging presentation | Stanford] |
| − | [ | + | * [https://www.cs.bgu.ac.il/~elhadad/nlp18/NLTKPOSTagging.html Parts of Speech Tagging with NLTK | Michael Elhadad] [https://www.cs.bgu.ac.il/~elhadad/nlp18/NLTKPOSTagging.ipynb Jupyter Notebook] |
| − | + | * [https://www.geeksforgeeks.org/python-pos-tagging-and-lemmatization-using-spacy/ Python | PoS Tagging and Lemmatization using spaCy | GeeksforGeeks] | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | (POST), also called grammatical tagging or word-category disambiguation, is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech,[1] based on both its definition and its [[context]]—i.e., its relationship with adjacent and related words in a phrase, sentence, or paragraph. A simplified form of this is commonly taught to school-age children, in the identification of words as nouns, verbs, adjectives, adverbs, etc. | |
| − | + | Taggers: | |
| − | |||
| − | |||
| − | + | * [https://www.coli.uni-saarland.de/~thorsten/tnt/ Trigrams’n’Tags (TnT)] statistical part-of-speech tagger that is trainable on different languages and virtually any tagset. The component for parameter generation trains on tagged corpora. The system incorporates several methods of smoothing and of handling unknown words. [https://www.coli.uni-saarland.de/~thorsten/tnt/ TnT -- Statistical Part-of-Speech Tagging | Thorsten Brants] | |
| + | * [https://www.geeksforgeeks.org/nlp-combining-ngram-taggers/ N-Gram] | ||
| + | ** [https://www.nltk.org/_modules/nltk/tag/sequential.html#UnigramTagger Unigram (Baseline) | NLTK.org] | ||
| + | ** Bigram - subclass uses <i>previous</i> tag as part of its [[context]] | ||
| + | ** Trigram - subclass uses the <i>previous two</i> tags as part of its [[context]] | ||
| + | * [https://www.fon.hum.uva.nl/rob/Courses/InformationInSpeech/CDROM/Literature/LOTwinterschool2006/homepages.inf.ed.ac.uk/s0450736/maxent.html Maximum Entropy (ME or MaxEnt)] [https://people.eecs.berkeley.edu/~klein/papers/maxent-tutorial-slides.pdf Examples | Stanford] | ||
| + | * [https://en.wikipedia.org/wiki/Maximum-entropy_Markov_model MEMM] model for sequence labeling that combines features of [[Markov Model (Chain, Discrete Time, Continuous Time, Hidden)#Hidden Markov Model (HMM)|hidden Markov models (HMMs)]] and Maximum Entropy | ||
| + | * Upper Bound | ||
| + | * Dependency | ||
| + | * [https://nlp.stanford.edu/software/tagger.shtml Log-linear | Stanford] | ||
| + | * [https://www.geeksforgeeks.org/nlp-backoff-tagging-to-combine-taggers/ Backoff | GeeksforGeeks] allows to combine the taggers together. The advantage of doing this is that if a tagger doesn’t know about the tagging of a word, then it can pass this tagging task to the next backoff tagger. If that one can’t do it, it can pass the word on to the next backoff tagger, and so on until there are no backoff taggers left to check. | ||
| + | * [https://www.geeksforgeeks.org/nlp-classifier-based-tagging/ Classifier-based | GeeksforGeeks] | ||
| − | https:// | + | <img src="https://slideplayer.com/slide/5260592/16/images/2/What+is+POS+tagging+Tagged+Text+Raw+Text+POS+Tagger.jpg" width="600" height="400"> |
| − | + | https://i.imgur.com/lsmcqqk.jpg | |
| − | |||
| − | + | <youtube>6j6M2MtEqi8</youtube> | |
| − | + | <youtube>GJgEBhYqs7U</youtube> | |
| − | === <span id=" | + | ==== <span id="Constituency Tree"></span>Constituency Tree ==== |
| − | [ | + | [https://www.youtube.com/results?search_query=Constituency+Tree+nlp+natural+language Youtube search...] |
| − | [ | + | [https://www.google.com/search?q=Constituency+Tree+nlp+natural+language ...Google search] |
| − | ( | + | * [https://en.wikipedia.org/wiki/Immediate_constituent_analysis Immediate constituent analysis (IC) | Wikipedia] |
| + | * [https://en.wikipedia.org/wiki/Sentence_diagram#Constituency_and_dependency Sentence diagram | Wikipedia] | ||
| − | + | a one-to-one-or-more relation; every word in the sentence corresponds to one or more nodes in the tree diagram; employ the convention where the category acronyms (e.g. N, NP, V, VP) are used as the labels on the nodes in the tree. The one-to-one-or-more constituency relation is capable of increasing the amount of sentence structure to the upper limits of what is possible. | |
| + | |||
| + | https://upload.wikimedia.org/wikipedia/commons/0/08/E-ICA-01.jpg | ||
| − | <youtube> | + | <youtube>tyLnW7rwnOU</youtube> |
| − | <youtube> | + | <youtube>nC9_RfjYwqA</youtube> |
| − | === <span id="Chunking"></span>Chunking === | + | ==== <span id="Chunking"></span>Chunking ==== |
| − | [ | + | [https://www.youtube.com/results?search_query=Chunking+nlp+natural+language Youtube search...] |
| − | [ | + | [https://www.google.com/search?q=Chunking+nlp+natural+language ...Google search] |
The Hierarchy of Ideas (also known as chunking) is a linguistic tool used in NLP that allows the speaker to traverse the realms of abstract to specific easily and effortlessly. | The Hierarchy of Ideas (also known as chunking) is a linguistic tool used in NLP that allows the speaker to traverse the realms of abstract to specific easily and effortlessly. | ||
| − | When we speak or think we use words that indicate how abstract, or how detailed we are in processing the information. In general, as human beings our brain is quite good at chunking information together in order to make it easier for us to process and simpler to understand. Thinking about the word “learning” for example is much simpler that thinking about all the different things that we could be learning about. When we memorise a telephone number or any other sequence of numbers we do not tend to memorise them as separate individual numbers, we group them together to make them easier to remember. [ | + | When we speak or think we use words that indicate how abstract, or how detailed we are in processing the information. In general, as human beings our brain is quite good at chunking information together in order to make it easier for us to process and simpler to understand. Thinking about the word “learning” for example is much simpler that thinking about all the different things that we could be learning about. When we memorise a telephone number or any other sequence of numbers we do not tend to memorise them as separate individual numbers, we group them together to make them easier to remember. [https://excellenceassured.com/nlp-training/nlp-certification/hierarchy-of-ideas Hierarchy of Ideas or Chunking in NLP | Excellence Assured] |
| − | + | https://www.coursebb.com/wp-content/uploads/2017/01/image-result-for-chunking-examples-in-marketing.gif | |
<youtube>imPpT2Qo2sk</youtube> | <youtube>imPpT2Qo2sk</youtube> | ||
<youtube>DEkDN1eLPtc</youtube> | <youtube>DEkDN1eLPtc</youtube> | ||
| − | === <span id="Chinking"></span>Chinking === | + | ==== <span id="Chinking"></span>Chinking ==== |
| − | [ | + | [https://www.youtube.com/results?search_query=Chinking+nlp+natural+language Youtube search...] |
| − | [ | + | [https://www.google.com/search?q=Chinking+nlp+natural+language ...Google search] |
| − | * [ | + | * [https://pythonprogramming.net/chinking-nltk-tutorial/ Chinking with NLTK | Discord] |
The process of removing a sequence of tokens from a chunk. If the matching sequence of tokens spans an entire chunk, then the whole chunk is removed; if the sequence of tokens appears in the middle of the chunk, these tokens are removed, leaving two chunks where there was only one before. If the sequence is at the periphery of the chunk, these tokens are removed, and a smaller chunk remains. | The process of removing a sequence of tokens from a chunk. If the matching sequence of tokens spans an entire chunk, then the whole chunk is removed; if the sequence of tokens appears in the middle of the chunk, these tokens are removed, leaving two chunks where there was only one before. If the sequence is at the periphery of the chunk, these tokens are removed, and a smaller chunk remains. | ||
| Line 245: | Line 421: | ||
<youtube>EymPQgCtcAE</youtube> | <youtube>EymPQgCtcAE</youtube> | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <hr> | |
| − | + | == <span id="Semantics"></span>[https://en.wikipedia.org/wiki/Semantics Semantics] == | |
| − | + | * [https://medium.com/huggingface/learning-meaning-in-natural-language-processing-the-semantics-mega-thread-9c0332dfe28e Learning Meaning in Natural Language Processing — The Semantics Mega-Thread | Thomas Wolf - Medium] | |
| − | |||
| − | |||
| − | |||
| − | + | * <b>Semantic Ambiguity</b> – Sentence having multiple meanings | |
| − | |||
| − | + | The linguistic and philosophical study of meaning in language, programming languages, formal logics, and semiotics. It is concerned with the relationship between signifiers—like words, phrases, signs, and symbols—and what they stand for in reality, their denotation. The “meaning” of the sentence. It’s difficult to (i) link raw text to a knowledge base of mathematical facts in our system and (ii) combine pieces of knowledge together to infer an answer. Meaning in Natural Language is a multi-facetted concept with: | |
| + | * semantic, | ||
| + | * pragmatic, | ||
| + | * cognitive and | ||
| + | * social aspects. | ||
| − | < | + | === <span id="Word Embeddings"></span>Word Embeddings === |
| + | [https://www.youtube.com/results?search_query=word+embeddings+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=word+embeddings+nlp+natural+language ...Google search] | ||
| − | + | * [[Embedding]] ... [[Fine-tuning]] ... [[Retrieval-Augmented Generation (RAG)|RAG]] ... [[Agents#AI-Powered Search|Search]] ... [[Clustering]] ... [[Recommendation]] ... [[Anomaly Detection]] ... [[Classification]] ... [[Dimensional Reduction]]. [[...find outliers]] | |
| − | [ | + | * [[Word2Vec]] |
| − | [ | + | * [https://explosion.ai/blog/sense2vec-with-spacy Sense2Vec | Matthew Honnibal] |
| + | * [[Global Vectors for Word Representation (GloVe)]] | ||
| + | * [https://embeddings.macheads101.com/ Word Embeddings Demo] | ||
| + | * [[Representation Learning]] | ||
| + | * [https://papers.nips.cc/paper/7368-on-the-dimensionality-of-word-embedding.pdf On the Dimensionality of Word Embedding | Zi Yin and Yuanyyuan Shen] | ||
| + | * [https://towardsdatascience.com/introduction-to-word-embedding-and-word2vec-652d0c2060fa Introduction to Word Embedding and Word2Vec | Dhruvil Karani - Towards Data Science] | ||
| + | * [https://arxiv.org/pdf/1805.07467.pdf Unsupervised Cross-Modal Alignment of Speech and Text Embedding Spaces | Yu-An Chung, Wei-Hung Weng, Schrasing Tong, and James Glass] | ||
| + | * [https://people.ee.duke.edu/~lcarin/Xinyuan_NIPS18.pdf Diffusion Maps for Textual Network Embedding | Xinyuan Zhang, Yitong Li, Dinghan Shen, and Lawrence Carin] | ||
| + | * [https://papers.nips.cc/paper/8209-a-retrieve-and-edit-framework-for-predicting-structured-outputs.pdf A Retrieve-and-Edit Framework for Predicting Structured Outputs | Tatsunori B. Hashimoto, Kelvin Guu, Yonatan Oren, and Percy Liang] | ||
| − | + | The collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers. | |
| − | + | https://www.researchgate.net/profile/Sylvain_Marie3/publication/282569641/figure/fig2/AS:391484353335317@1470348551823/Example-of-embedding-of-time-series-xi-from-the-temporal-space-left-into-the-pairwise.png | |
| − | + | <youtube>5PL0TmQhItY</youtube> | |
| + | <youtube>S-CspeZ8FHc</youtube> | ||
| − | < | + | === <span id="Named Entity Recognition (NER)"></span>Named Entity Recognition (NER) === |
| + | [https://www.youtube.com/results?search_query=Named+Entity+Recognition+NER+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=Named+Entity+Recognition+NER+nlp+natural+language ...Google search] | ||
| − | + | * [[NLP Keras model in browser with TensorFlow.js]] | |
| − | [ | + | * [https://medium.com/explore-artificial-intelligence/introduction-to-named-entity-recognition-eda8c97c2db1 Introduction to Named Entity Recognition | Suvro Banerjee - Medium] |
| − | [ | + | * [https://stanfordnlp.github.io/CoreNLP/ner.html NERClassifierCombiner | Stanford CoreNLP] |
| + | * [https://www.kdnuggets.com/2018/08/named-entity-recognition-practitioners-guide-nlp-4.html Named Entity Recognition: A Practitioner’s Guide to NLP | Dipanjan Sarkar - RedHat KDnuggets] | ||
| − | + | Named Entities (also known as entity identification, entity chunking, sequence tagging, [[Natural Language Processing (NLP)#Part-of-Speech (POS) Tagging|Part-of-Speech (POS) Tagging]], and entity chunking/extraction) is a subtask of information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. Most research on NER systems has been structured as taking an unannotated block of text, and producing an annotated block of text that highlights the names of entities. | |
| − | |||
| − | + | https://joecyw.files.wordpress.com/2017/02/maxthonsnap20170219114627.png | |
| − | |||
| − | |||
| − | + | <youtube>LFXsG7fueyk</youtube> | |
| − | |||
| − | < | + | === <span id="Semantic Slot Filling"></span>Semantic Slot Filling === |
| − | + | [https://www.youtube.com/results?search_query=Semantic+Slot+Filling+nlp+natural+language Youtube search...] | |
| + | [https://www.google.com/search?q=Semantic+Slot+Filling+nlp+natural+language ...Google search] | ||
| − | + | * [https://mc.ai/semantic-slot-filling-part-1/ Semantic Slot Filling: Part 1 | Soumik Rakshit - mc.ai] | |
| − | [ | + | * [https://www.coursera.org/lecture/language-processing/main-approaches-in-nlp-j8kee Main approaches in NLP | Anna Potapenko - National Research University Higher School of Economics - Coursera] |
| − | [ | ||
| − | + | One way of making sense of a piece of text is to tag the words or tokens which carry meaning to the sentences. There are three main approaches to solve this problem: | |
| − | + | # <b>Rule Based</b>; regular expressions, [[context]]-free grammars | |
| + | # <b>Probabilistic modeling & Machine Learning</b>; likelihood maximization, linear classifiers | ||
| + | # <b>Deep Learning</b>; recurrent neural networks, convolutional neural networks | ||
| − | + | https://cdn-images-1.medium.com/freeze/max/1000/1*bpkI_VpU1j0wXv4VqW5e5Q.png | |
| − | |||
| − | === <span id=" | + | === <span id="Relation Extraction"></span>Relation Extraction === |
| − | [ | + | [https://www.youtube.com/results?search_query=Relation+Extraction+nlp+natural+language Youtube search...] |
| − | [ | + | [https://www.google.com/search?q=Relation+Extraction+nlp+natural+language ...Google search] |
| − | + | task of extracting semantic relationships from a text. Extracted relationships usually occur between two or more entities of a certain type (e.g. Person, Organisation, Location) and fall into a number of semantic categories (e.g. married to, employed by, lives in). | |
| + | [https://nlpprogress.com/english/relationship_extraction.html Relationship Extraction] | ||
| − | + | https://tianjun.me/static/essay_resources/RelationExtraction/Resources/TypicalRelationExtractionPipeline.png | |
| − | + | [https://tianjun.me/essays/RelationExtraction Relation Extraction | Jun Tian] | |
| − | + | <youtube>gTFMULX7vU0</youtube> | |
| − | |||
| − | |||
| − | + | <hr> | |
| + | == <span id="Discourse (Dialog)"></span>[https://en.wikipedia.org/wiki/Discourse_analysis Discourse (Dialog)] == | ||
| + | Discourse is the creation and organization of the segments of a language above as well as below the sentence. It is segments of language which may be bigger or smaller than a single sentence but the adduced meaning is always beyond the sentence. | ||
| − | + | * identifying the discourse structure of a connected text, i.e. the nature of the discourse relationships between sentences (e.g. elaboration, explanation, contrast). | |
| + | * recognizing and classifying the speech acts in a chunk of text (e.g. yes-no question, content question, statement, assertion, etc.). | ||
| − | + | The objects of discourse analysis (discourse, [[Writing/Publishing|writing]], conversation, communicative event) are variously defined in terms of coherent sequences of sentences, propositions, speech, or turns-at-talk. | |
| − | [ | ||
| − | |||
| − | + | The problems addressed in discourse research aim to answer two general kinds of questions: | |
| − | + | # what information is contained in extended sequences of utterances that goes beyond the meaning of the individual utterances themselves? | |
| + | # how does the [[context]] in which an utterance is used affect the meaning of the individual utterances, or parts of them? | ||
| − | + | [https://www.ccs.neu.edu/home/futrelle/bionlp/hlt/chpt6.pdf Chapter 6 Discourse and Dialogue] | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <b> Compared to traditional linguistics </b> | |
| + | Contrary to much of traditional linguistics, discourse analysts not only study language use 'beyond the sentence boundary' but also prefer to analyze 'naturally occurring' language use, not invented examples. Text linguistics is a closely related field. The essential difference between discourse analysis and text linguistics is that discourse analysis aims at revealing socio-psychological characteristics of a person/persons rather than text structure. | ||
| − | |||
| − | < | + | <hr> |
| − | |||
| − | |||
| − | |||
| − | == <span id=" | + | == <span id="Pragmatics"></span>[https://en.wikipedia.org/wiki/Pragmatics Pragmatics] == |
| − | [ | + | <b>Anaphoric Ambiguity</b> – Phrase or word which is previously mentioned but has a different meaning. |
| − | |||
| − | + | Studies the ways in which [[context]] contributes to meaning. Pragmatics encompasses speech act theory, conversational implicature, talk in interaction and other approaches to language behavior in philosophy, sociology, linguistics and anthropology -- Understanding the text as a whole. Popular problems that we’re trying to solve at this stage are: | |
| − | + | * Topic modelling | |
| − | + | * Coreference/Anaphora | |
| − | + | * Summarization | |
| − | + | * Question & Answering | |
| − | |||
| − | * | ||
| − | * | ||
| − | * | ||
| − | * | ||
| − | + | === <span id="Grouping"></span>Grouping === | |
| − | https://www. | + | ==== <span id="Sentence/Document Similarity"></span>Sentence/Document Similarity ==== |
| + | [https://www.youtube.com/results?search_query=sentence+document+similarity+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=sentence+document+similarity+similarity+nlp+natural+language ...Google search] | ||
| − | + | * [[Document Similarity]] | |
| + | * [[Term Frequency–Inverse Document Frequency (TF-IDF)]] | ||
| + | * [[Doc2Vec]] | ||
| + | * [https://text2vec.org/similarity.html Text2Vec] | ||
| + | * [https://www.slideshare.net/PyData/sujit-pal-applying-the-fourstep-embed-encode-attend-predict-framework-to-predict-document-similarity Applying the four-step "Embed, Encode, Attend, Predict" framework to predict document similarity | Sujit Pal] | ||
| + | * [https://kanoki.org/2019/03/07/sentence-similarity-in-python-using-doc2vec/ Sentence Similarity in Python using Doc2Vec | Kanoki] As a next step you can use the Bag of Words or TF-IDF model to covert these texts into numerical feature and check the accuracy score using cosine similarity. | ||
| + | Word [[embedding]]s have become widespread in Natural Language Processing. They allow us to easily compute the semantic similarity between two words, or to find the words most similar to a target word. However, often we're more interested in the similarity between two sentences or short texts. [https://nlp.town/blog/sentence-similarity/ Comparing Sentence Similarity Methods | Yves Peirsman - NLPtown ] | ||
| + | https://kanoki.org/wp-content/uploads/2019/03/image-1.png | ||
| + | <youtube>_d7i0cDajEY</youtube> | ||
| + | ==== <span id="Text Classification"></span>Text Classification ==== | ||
| + | [https://www.youtube.com/results?search_query=text+Classification+Classifier+Hierarchical+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=text+Classification+Classifier+Hierarchical+nlp+natural+language ...Google search] | ||
| + | * [[Large Language Model (LLM)]] ... [[Natural Language Processing (NLP)]] ...[[Natural Language Generation (NLG)|Generation]] ... [[Natural Language Classification (NLC)|Classification]] ... [[Natural Language Processing (NLP)#Natural Language Understanding (NLU)|Understanding]] ... [[Language Translation|Translation]] ... [[Natural Language Tools & Services|Tools & Services]] | ||
| + | * [https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.183.302&rep=rep1&type=pdf A Survey of Hierarchical Classification Across Different Application Domains | Carlos N. Silla Jr. and Alex A. Freitas] | ||
| + | * [https://www.kdnuggets.com/2018/03/hierarchical-classification.html Hierarchical Classification – a useful approach for predicting thousands of possible categories | Pedro Chaves - KDnuggets] | ||
| + | * [https://cloud.google.com/blog/products/gcp/problem-solving-with-ml-automatic-document-classification Problem-solving with ML: automatic document classification | Ahmed Kachkach] | ||
| + | Tasks: | ||
| + | * predict tags or categories | ||
| + | * predict sentiment | ||
| + | * filter spam eMails | ||
| + | Text Classification approaches: | ||
| + | * Flat - there is no inherent hierarchy between the possible categories the data can belong to (or we chose to ignore it). Train either a single classifier to predict all of the available classes or one classifier per category (1 vs All) | ||
| + | * Hierarchically - organizing the classes, creating a tree or DAG (Directed Acyclic Graph) of categories, exploiting the information on relationships among them. Although there are different types of hierarchical classification approaches, the difference between both modes of reasoning and analysing are particularly easy to understand in these illustrations, taken from a great review on the subject by [https://www.researchgate.net/publication/225716424_A_survey_of_hierarchical_classification_across_different_application_domains Silla and Freitas (2011)]. Taking a top-down approach, training a classifier per level (or node) of the tree (again, although this is not the only hierarchical approach, it is definitely the most widely used and the one we’ve selected for our problem at hands), where a given decision will lead us down a different classification path. | ||
| + | https://www.johnsnowlabs.com/wp-content/uploads/2018/02/1.png | ||
| + | https://www.johnsnowlabs.com/wp-content/uploads/2018/02/2.png | ||
| + | <youtube>Xg8UtTgziZE</youtube> | ||
| + | ==== <span id="Topic Modeling"></span>Topic Modeling ==== | ||
| + | [https://www.youtube.com/results?search_query=Topic+Modeling+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=Topic+Modeling+nlp+natural+language ...Google search] | ||
| + | * [[Doc2Vec]] | ||
| + | * [[Latent Dirichlet Allocation (LDA)]] | ||
| + | A type of statistical modeling for discovering the abstract “topics” that occur in a collection of documents. [[Latent Dirichlet Allocation (LDA)]] is an example of topic model and is used to classify text in a document to a particular topic | ||
| + | https://media.springernature.com/original/springer-static/image/art%3A10.1186%2Fs40064-016-3252-8/MediaObjects/40064_2016_3252_Fig5_HTML.gif | ||
| + | <youtube>BuMu-bdoVrU</youtube> | ||
| + | <youtube>yK7nN3FcgUs</youtube> | ||
| + | <youtube>vOIjI_qF1yg</youtube> | ||
| + | <youtube>3mHy4OSyRf0</youtube> | ||
| + | === <span id="Neural Coreference"></span>Neural Coreference === | ||
| + | [https://www.youtube.com/results?search_query=Coreference+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=Coreference+nlp+natural+language ...Google search] | ||
| − | + | * [[Neural Coreference]] | |
| − | [ | ||
| − | |||
| − | + | Coreference is the fact that two or more expressions in a text – like pronouns or nouns – link to the same person or thing. It is a classical Natural language processing task, that has seen a revival of interest in the past two years as several research groups applied cutting-edge deep-learning and reinforcement-learning techniques to it. It is also one of the key building blocks to building conversational Artificial intelligence. | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <img src="https://cdn-images-1.medium.com/max/800/1*-jpy11OAViGz2aYZais3Pg.png" width="600" height="300"> | |
| − | + | <youtube>rpwEWLaueRk</youtube> | |
| − | |||
| − | + | === <span id="Whole Word Masking"></span>Whole Word Masking === | |
| − | + | [https://www.youtube.com/results?search_query=Whole+Word+Masking+nlp+natural+language Youtube search...] | |
| − | + | [https://www.google.com/search?q=Whole+Word+Masking+nlp+natural+language ...Google search] | |
| − | + | * [https://www.kdnuggets.com/2018/12/bert-sota-nlp-model-explained.html BERT: State of the Art NLP Model, Explained - Rani Horev - KDnuggets] | |
| − | |||
| − | + | Training the language model in [[Bidirectional Encoder Representations from Transformers (BERT)]] is done by predicting 15% of the tokens in the input, that were randomly picked. These tokens are pre-processed as follows — 80% are replaced with a “[MASK]” token, 10% with a random word, and 10% use the original word. The intuition that led the authors to pick this approach is as follows (Thanks to [https://ai.google/research/people/106320 Jacob Devlin] from Google for the insight): | |
| − | [ | ||
| − | [ | ||
| − | + | * If we used [MASK] 100% of the time the model wouldn’t necessarily produce good token representations for non-masked words. The non-masked tokens were still used for [[context]], but the model was optimized for predicting masked words. | |
| − | + | * If we used [MASK] 90% of the time and random words 10% of the time, this would teach the model that the observed word is never correct. | |
| − | + | * If we used [MASK] 90% of the time and kept the same word 10% of the time, then the model could just trivially copy the non-[[context]]ual [[embedding]]. | |
| − | <youtube> | + | <youtube>Fs8Zb4T-_CE</youtube> |
| − | |||
| + | === <span id="Managed Vocabularies"></span>Managed Vocabularies === | ||
| − | + | * [[Datasets]] | |
| − | [ | ||
| − | |||
| − | + | ==== <span id="Corpora"></span>[https://en.wikipedia.org/wiki/Text_corpus Corpora] ==== | |
| + | [https://www.youtube.com/results?search_query=Corpora+nlp+natural+language Youtube search...] | ||
| + | [https://www.google.com/search?q=Corpora+nlp+natural+language ...Google search] | ||
| − | + | * [https://storage.googleapis.com/books/ngrams/books/datasetsv2.html Google Books Corpus] | |
| + | * [https://en.wikipedia.org/wiki/Oxford_English_Corpus Oxford English Corpus] | ||
| − | + | A corpus (plural corpora) or text corpus is a large and structured set of texts (nowadays usually electronically stored and processed). In corpus linguistics, they are used to do statistical analysis and hypothesis testing, checking occurrences or validating linguistic rules within a specific language territory. | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | == | + | {|<!-- T --> |
| − | + | | valign="top" | | |
| − | + | {| class="wikitable" style="width: 550px;" | |
| + | || | ||
| + | <youtube>TKAXDqoG2dc</youtube> | ||
| + | <b>NLTK Corpora - Natural Language Processing With Python and NLTK p.9 | ||
| + | </b><br>Part of the NLTK Corpora is WordNet. I wouldn't totally classify WordNet as a Corpora, if anything it is really a giant Lexicon, but, either way, it is super useful. With WordNet we can do things like look up words and their meaning according to their parts of speech, we can find synonyms, antonyms, and even examples of the word in use. | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>T68P5-8tM-Y</youtube> | ||
| + | <b>WordNet - Natural Language Processing With Python and NLTK p.10 | ||
| + | </b><br>Part of the NLTK Corpora is WordNet. I wouldn't totally classify WordNet as a Corpora, if anything it is really a giant Lexicon, but, either way, it is super useful. With WordNet we can do things like look up words and their meaning according to their parts of speech, we can find synonyms, antonyms, and even examples of the word in use. | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| − | |||
| − | |||
| − | + | ===== Building your Corpora | Yassine Iabdounane ===== | |
| + | * Ant | ||
| + | ** [https://www.laurenceanthony.net/software/antconc/ AntConc] - a freeware corpus analysis toolkit for concordancing and text analysis. | ||
| + | ** [https://www.youtube.com/user/AntlabJPN/videos AntLab | Laurence Anthony] | ||
| + | * [https://nlp.fi.muni.cz/projekty/justext/ jusText] - a heuristic based boilerplate removal tool. | ||
| − | <youtube> | + | {|<!-- T --> |
| − | <youtube> | + | | valign="top" | |
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>ePD46YjYRzQ</youtube> | ||
| + | <b>#1 Introduction to Corpus Linguistics - What is Corpus Linguistics? (For Absolute Beginners) | ||
| + | </b><br>Hello there! My name is Yassine Iabdounane and I'm a Moroccan MA student of Applied Linguistics and ELT. My areas of interest are Syntax, Phonology, Semantics, Cognitive Linguistic, and Corpus Linguistics. | ||
| + | This video is made specifically for those who don't know much about Corpus Linguistics and would like to get started in the field. | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>GWVFWgRgeOA</youtube> | ||
| + | <b>#2 Introduction to Corpus Linguistics - Types of Corpora | ||
| + | </b><br>Hello there! In this video I present to you some of the most common types of corpora. This is by no means an exhaustive list but it's enough to get you started :) | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>g6xJLqDeU7E</youtube> | ||
| + | <b># 3 Introduction to Corpus Linguistics - Compiling and Analysing our First Corpus | ||
| + | </b><br>Hello there! In this video, we compile our first corpus and analyse it using AntConc. We generate frequency lists, concordances, look for collocates, and discover a cool hack by the end of the video! | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>BZoXR7saE1s</youtube> | ||
| + | <b>#4 Introduction to Corpus Linguistics - Part-of-Speech Tagging and Working with Tagged Data | ||
| + | </b><br>Hello there! In this video, we see how to tag a corpus for part of speech and how to work with tagged data using two methods/tools. We'll learn about how to look for specific parts of speech, how to restrict the search to only specific word classes, and how to use two regular expressions. | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>e9_dPFeAsEI</youtube> | ||
| + | <b>#5 Introduction to Corpus Linguistics - Rank Words that Belong to a Specific Word Class | ||
| + | </b><br>Hello there! In this video we see a really easy way to rank words that belong to specific word classes. If you want to rank nouns only, verbs only, adverbs only and so on, this video is for you! :D | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>8jq8v6vF_rk</youtube> | ||
| + | <b>#6 Introduction to Corpus Linguistics - Look for Constructions in a Corpus | ||
| + | </b><br>Hello there! In this video we see how to look for constructions in a tagged corpus. I've tagged the corpus using TagAnt. And, I've got my AC/DC shirt on :) | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>cMLLe4qHHwk</youtube> | ||
| + | <b>#7 Introduction to Corpus Linguistics - Searching with Regular Expressions (Regex) | ||
| + | </b><br>Hey there! In this video we see how to look for specific parts of speech or constructions using regular expressions. | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>LHXrVQOHP9M</youtube> | ||
| + | <b>#8 Now what? What can I do in Corpus Linguistics? | ||
| + | </b><br>Hey there! In this video we have a look at some fields and areas of research that use corpora to study language phenomena. | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| − | == <span id=" | + | ==== <span id="Ontology"></span>Ontology ==== |
| − | [ | + | * [[Graph#Ontology|Ontology]] |
| − | [ | + | * [https://www.degruyter.com/downloadpdf/j/cplbu.2015.1.issue-1/cplbu-2015-0024/cplbu-2015-0024.pdf Teaching Natural Language Processing (NLP) Using Ontology Based Education Design | Zobia Rehman and Stefania Kifor] |
| + | * [https://www.expert.ai/blog/how_ontology_works_and_adds_value_to_nlu Understanding Ontology and How It Adds Value to NLU]... ntroduction to ontologies and how they can be used in data science today with the NLU 101 series. It explains what ontologies are, why they are important, how they are created, and how they are used in NLU applications. | ||
| + | * [https://plato.stanford.edu/entries/natural-language-ontology Natural Language Ontology] ... Stanford Encyclopedia of Philosophy that discusses natural language ontology as a sub-discipline of both philosophy and linguistics. It covers the history, scope, methods, features, and challenges of natural language ontology and its relation to reality, truth conditions, cognition, and reasoning. | ||
| + | * [https://arxiv.org/abs/2112.02992 Towards More Robust Natural Language Understanding] ... surveys the recent advances and challenges in natural language understanding (NLU) with deep learning techniques. It covers various NLU tasks, such as text classification, information extraction, natural language inference, question answering, dialogue systems, and text generation. It also discusses the limitations and future directions of NLU research. | ||
| − | + | ==== <span id="Taxonomy"></span>[https://en.wikipedia.org/wiki/Taxonomy Taxonomy] ==== | |
| − | + | [https://www.youtube.com/results?search_query=Taxonomies+Taxonomy+nlp+natural+language Youtube search...] | |
| − | + | [https://www.google.com/search?q=Taxonomies+taxonomy+nlp+natural+language ...Google search] | |
| − | |||
| − | |||
| − | |||
| − | + | * [https://en.wikipedia.org/wiki/Automatic_taxonomy_construction Automatic taxonomy construction | Wikipedia] | |
| + | * [https://nlpprogress.com/english/taxonomy_learning.html Taxonomy Learning | NLP-progress] | ||
| − | + | The practice and science of classification of things or concepts, including the principles that underlie such classification. | |
| − | |||
| − | |||
| − | + | https://www.researchgate.net/profile/Yoshihiko_Hayashi/publication/239531939/figure/fig8/AS:298694755799053@1448225787229/Taxonomy-of-linguistic-analyzers.png | |
| − | + | <youtube>6VI0QAzz6LM</youtube> | |
| − | |||
| − | |||
| − | |||
| − | = | + | = Related = |
| − | [ | + | == <span id="Workbench / Pipeline"></span>Workbench / Pipeline == |
| − | [ | + | [https://www.youtube.com/results?search_query=Pipeline+workflow+workbench+nlp+natural+language Youtube search...] |
| + | [https://www.google.com/search?q=Pipeline+workflow+workbench+nlp+natural+language ...Google search] | ||
| − | * [ | + | * [[Algorithm Administration#AIOps/MLOps|AIOps/MLOps]] e.g. Google [[Kubeflow Pipelines]] |
| + | * [[Natural Language Tools & Services]] | ||
| + | * [https://github.com/CogComp/cogcomp-nlp/tree/master/pipeline CogComp NLP Pipeline | Cognitive Computation Group, led by Prof. Dan Roth] | ||
| + | * [https://azure.github.io/LearnAI-CustomTextAnalyticsWithAML/ Building Custom Text Analytics solutions using Azure Machine Learning (AML)] | ||
| + | * [[H2O]] Driverless AI | ||
| + | * [https://gate.ac.uk/ GATE] toolkit | ||
| + | * [https://uima.apache.org/ Apache UIMA] - Unstructured Information Management Applications | ||
| + | * [https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5486409/ An Ontology-Enabled Natural Language Processing Pipeline for Provenance Metadata Extraction from Biomedical Text | J. Valdez, M. Rueschman, M. Kim, S. Redline, and S. Sahoo] | ||
| − | + | https://lexalytics.com/lexablog/wp-content/uploads/2012/02/technology-stack1.png | |
| − | + | https://ai2-s2-public.s3.amazonaws.com/figures/2017-08-08/38a1108341d34efabbe999c046c693751b95a0a7/4-Figure3-1.png | |
| + | https://www.researchgate.net/profile/Tom_Engers/publication/228726028/figure/fig1/AS:301890404405248@1448987689617/A-global-model-of-the-Power-Workbench.png | ||
| − | == | + | <img src="https://vignette.wikia.nocookie.net/natural-language-understanding/images/d/d9/NLU_Architecture_Ovchinnikova.png" width="600" height="400"> |
| − | + | <youtube>IM99o2B_0Nw</youtube> | |
| − | + | <youtube>k5X12mdEvb8</youtube> | |
| − | + | == Sapir Whorf Hypothesis - How language shapes the way we think == | |
| + | [https://www.youtube.com/results?search_query=sapir+whorf+hypothesis Youtube search...] | ||
| + | [https://www.google.com/search?q=sapir+whorf+hypothesis ...Google search] | ||
| − | <youtube> | + | <youtube>RKK7wGAYP6k</youtube> |
| − | <youtube> | + | <youtube>QglKeIIC5Ds</youtube> |
| − | |||
| − | |||
| − | == | + | == General Natural Language Processing (NLP) Videos == |
| − | |||
| − | |||
| − | + | <youtube>OQQ-W_63UgQ</youtube> | |
| − | + | <youtube>s5zuplW8ua8</youtube> | |
| − | + | <youtube>lCRs-Xn0Af8</youtube> | |
| + | <youtube>53Bip8-F7xw</youtube> | ||
| + | <youtube>GazFsfcijXQ</youtube> | ||
| + | <youtube>bDxFvr1gpSU</youtube> | ||
| + | <youtube>p5K_xtldcp4</youtube> | ||
| + | <youtube>DDByc9LyMV8</youtube> | ||
| + | <youtube>DDByc9LyMV8</youtube> | ||
| − | + | = Natural Language Processing (NLP) Techniques = | |
| + | [http://www.youtube.com/results?search_query=nlp+nli+natural+language+Techniques+Approaches Youtube search...] | [http://www.quora.com/topic/Natural-Language-Processing Quora search...] | ||
| + | [http://www.google.com/search?q=nlp+nli+natural+language+Techniques+Approaches ...Google search] | ||
| − | + | Speech recognition, (speech) translation, understanding (semantic parsing) complete sentences, understanding synonyms of matching words, [[Sentiment Analysis]], and [[Writing/Publishing|writing]]/generating complete grammatically correct sentences and paragraphs. | |
| − | [ | ||
| − | [ | ||
| − | + | * [[Natural Language Processing (NLP)]] ...[[Natural Language Generation (NLG)|Generation]] ...[[Large Language Model (LLM)|LLM]] ...[[Natural Language Tools & Services|Tools & Services]] | |
| − | + | * [[Text Transfer Learning]] | |
| + | * [[End-to-End Speech]] | ||
| + | * [[Topic Model/Mapping]] | ||
| + | * [http://www.aclweb.org/anthology/C16-1229 Combination of Convolutional and Recurrent Neural Network for Sentiment Analysis of Short Texts | Xingyou Wang, Weijie Jiang, Zhiyong Luo] | ||
| + | * [http://dailynlp.com/nlp-techniques/ NLP Techniques: A Preliminary Cornerstone List | Martin Messier] | ||
| + | * [http://towardsdatascience.com/linguistic-knowledge-in-natural-language-processing-332630f43ce1 Linguistic Knowledge in Natural Language Processing | Hafidz Zulkifli | Towards Data Science - Medium] | ||
| + | * [http://www.nltk.org/book/ch07.html Extracting Information from Text | NLTK.org] | ||
| + | * [http://techxplore.com/news/2019-02-neural-networks-microscope.html Linguistic Correlation Analysis - Putting neural networks under the microscope | Rob Matheson] | ||
| + | * [http://www.engadget.com/2018/07/24/google-docs-ai-grammar-checking/ Google Docs uses AI to catch your grammar mistakes | Jon Fingas - Engadget] | ||
| + | * [http://blog.kensho.com/announcing-the-kensho-derived-wikimedia-dataset-5d1197d72bcf?gi=a94e1b9ff840 Introducing the Kensho Derived Wikimedia Dataset (KDWD) | Gabriel Altay] - [http://blog.kensho.com/ Kensho - Medium] Wikipedia, the free encyclopedia, and Wikidata, the free knowledge base, are crowd-sourced projects supported by the Wikimedia Foundation. Kaggle notebooks: | ||
| + | ** [http://www.kaggle.com/kenshoresearch/kensho-derived-wikimedia-data Kensho Derived Wikimedia Dataset] | ||
| + | ** [http://blog.kensho.com/how-to-build-a-smart-synonyms-model-1d525971a4ee How to Build a Smart Synonyms Model | Patrick O'Beill - Medium] ...[http://www.kaggle.com/kenshoresearch/kdwd-aliases-and-disambiguation Entity Aliases and Disambiguation Candidates with Anchor Link Statistics] | ||
| + | ** [http://www.kaggle.com/kenshoresearch/kdwd-explicit-topic-models Explicit Topic Models] | ||
| + | ** [http://www.kaggle.com/kenshoresearch/kdwd-pmi-word-vectors Word Vectors from Decomposing a Word-Word Pointwise Mutual Information Matrix] | ||
| + | ** [http://www.kaggle.com/gabrielaltay/kdwd-subclass-path-ner Create Named entity recognition (NER) Labels for Wikidata Items Based on Subclass Paths] | ||
Latest revision as of 10:03, 28 April 2024
YouTube ... Quora ...Google search ...Google News ...Bing News
- Natural Language Processing (NLP) ... Generation (NLG) ... Classification (NLC) ... Understanding (NLU) ... Translation ... Summarization ... Sentiment ... Tools
- Large Language Model (LLM) ... Multimodal ... Foundation Models (FM) ... Generative Pre-trained ... Transformer ... GPT-4 ... GPT-5 ... Attention ... GAN ... BERT
- Case Studies
- End-to-End Speech ... Synthesize Speech ... Speech Recognition ... Music ... (speech) translation, understanding (semantic parsing) complete sentences, understanding synonyms of matching words, Sentiment Analysis, and writing/generating complete grammatically correct sentences and paragraphs.
- Semantic Search
- Agents ... Robotic Process Automation ... Assistants ... Personal Companions ... Productivity ... Email ... Negotiation ... LangChain
- Artificial Intelligence (AI) ... Generative AI ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Conversational AI ... ChatGPT | OpenAI ... Bing/Copilot | Microsoft ... Gemini | Google ... Claude | Anthropic ... Perplexity ... You ... phind ... Ernie | Baidu
- Groq
- Wikipedia (Wiki):
- Natural Language Processing (NLP) Courses & Certifications
- NLP Models:
- StructBERT - Alibaba Group's method to incorporate language structures into pre-training
- T5 - Google's Text-To-Text Transfer Transformer model.
- ERNIE - Baidu ensemble
- SMART - Multi-Task Deep Neural Networks (MT-DNN) Microsoft Research & GATECH train the tasks MT-DNN and HNN models starting with RoBERTa
- XLNet - unsupervised language representation learning method based on Transformer-XL and a novel generalized permutation language modeling objective
- Bidirectional Encoder Representations from Transformers (BERT) | Google - built on ideas from ULMFiT, ELMo, and OpenAI
- Transformer-XL - state-of-the-art autoregressive model
- GPT-2 OpenAI… GPT-2 - Too powerful NLP model (GPT-2) | Edward Ma - Towards Data Science
- Attention Mechanism/Transformer Model
- Previous Efforts:
- For fun: Web Seer Google complete ...for one query... 'cats are'...for the other 'dogs are'
- Thought Vectors | Geoffrey Hinton - A.I. Wiki - pathmind
- 7 types of Artificial Neural Networks for Natural Language Processing
- How do I learn Natural Language Processing? | Sanket Gupta
- Natural Language | Chris Umbel
- Language services | Cognitive Services | Microsoft Azure
- Natural Language Processing - Quick Guide | TutorialsPoint
- Speech and Language Processing | Dan Jurafsky and James H. Martin (3rd ed. draft)
- The Stanford Natural Language Inference (SNLI) Corpus
- NLP/NLU/NLI Benchmarks:
- Question Answering in Context (QuAC) ...Question Answering in Context for modeling, understanding, and participating in information seeking dialog.
- 10 Leading Language Models For NLP In 2022 | Mariya Yao - TOPBOTS
Natural Language Processing (NLP) are techniques used by to understand and generate human language, including text classification and Sentiment Analysis, using machine learning algorithms, statistical models, and linguistic rules. e.g. Large Language Model (LLM)
Over the last two years, the Natural Language Processing community has witnessed an acceleration in progress on a wide range of different tasks and applications. This progress was enabled by a shift of paradigm in the way we classically build an NLP system The Best and Most Current of Modern Natural Language Processing | Victor Sanh - Medium:
- For a long time, we used pre-trained word embeddings such as Word2Vec or Global Vectors for Word Representation (GloVe) to initialize the first layer of a neural network, followed by a task-specific architecture that is trained in a supervised way using a single dataset.
- Recently, several works demonstrated that we can learn hierarchical contextualized representations on web-scale datasets leveraging unsupervised (or self-supervised) signals such as language modeling and transfer this pre-training to downstream tasks (Transfer Learning). Excitingly, this shift led to significant advances on a wide range of downstream applications ranging from Question Answering, to Natural Language Inference through Syntactic Parsing…
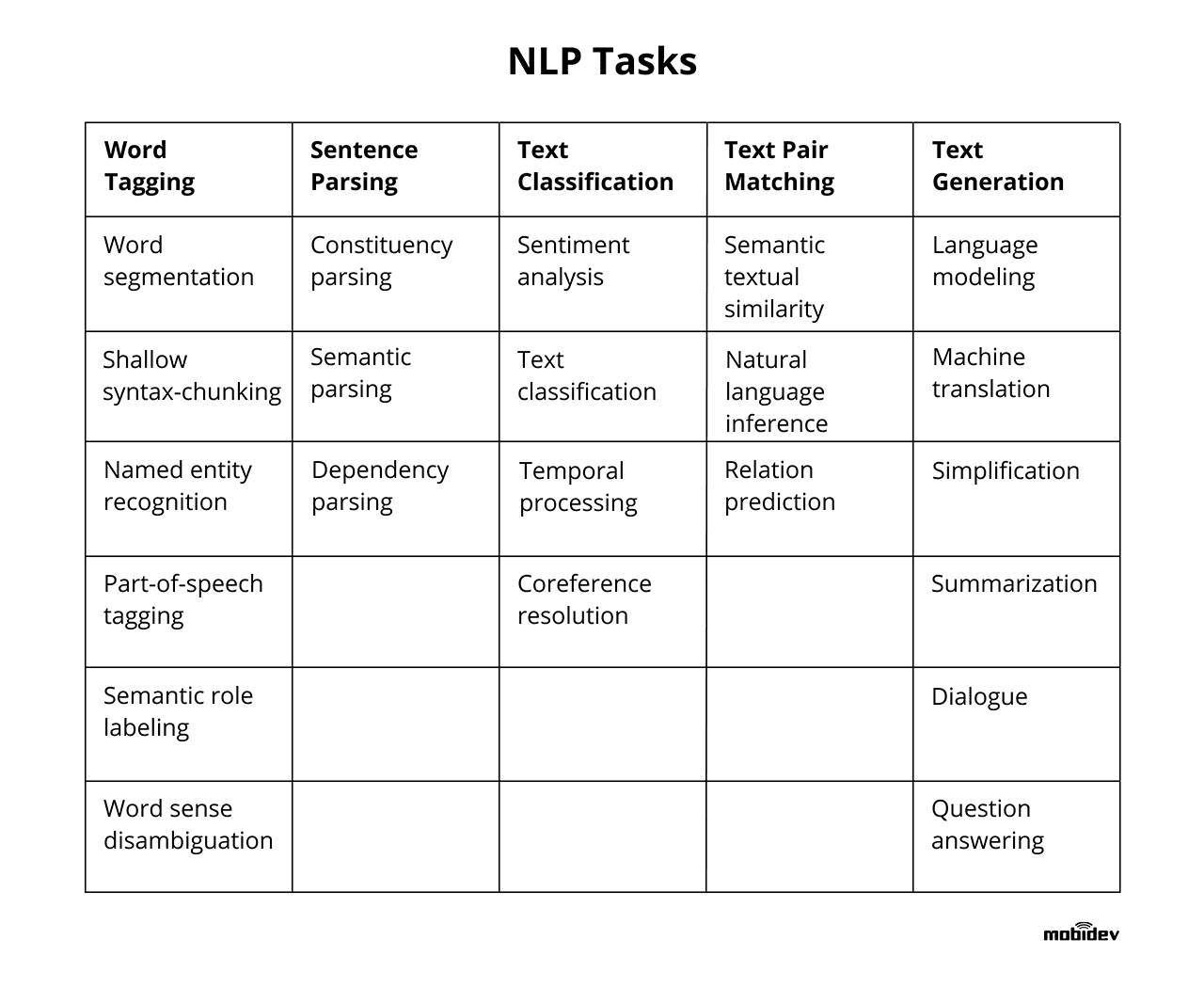
 Artificial Intelligence Overview and Applications | Jagreet Kaur Gill
Artificial Intelligence Overview and Applications | Jagreet Kaur Gill
Contents
- 1 Capabilities
- 2 Natural Language Understanding (NLU)
- 3 Related
- 4 Natural Language Processing (NLP) Techniques
Capabilities
- AI-Powered Search
- Automated Scoring
- Language Translation
- Assistants - Dialog Systems
- Summarization / Paraphrasing
- Sentiment Analysis
- Wikifier
- Natural Language Generation (NLG) ...Text Analytics

Natural Language Understanding (NLU)
Youtube search... | Quora search... ...Google search
- Natural Language Processing (NLP) ... Generation (NLG) ... Classification (NLC) ... Understanding (NLU) ... Translation ... Summarization ... Sentiment ... Tools
- Large Language Model (LLM) ... Multimodal ... Foundation Models (FM) ... Generative Pre-trained ... Transformer ... GPT-4 ... GPT-5 ... Attention ... GAN ... BERT
- Phonology (Phonetics)
- Lexical (Morphology)
- Syntax (Parsing)
- Semantics
- Discourse (Dialog)
- Pragmatics
- ChatPDF ... upload any PDF file and essentially “Chat” with it, including long research papers
Natural-language understanding (NLU) or natural-language interpretation (NLI) is a subtopic of natural-language processing in artificial intelligence that deals with machine reading comprehension. There is considerable commercial interest in the field because of its application to automated reasoning, machine translation, question answering, news-gathering, text categorization, voice-activation, archiving, and large-scale content analysis.
NLU is the post-processing of text, after the use of NLP algorithms (identifying parts-of-speech, etc.), that utilizes context from recognition devices; automatic speech recognition (ASR), vision recognition, last conversation, misrecognized words from ASR, personalized profiles, microphone proximity etc.), in all of its forms, to discern meaning of fragmented and run-on sentences to execute an intent from typically voice commands. NLU has an ontology around the particular product vertical that is used to figure out the probability of some intent. An NLU has a defined list of known intents that derives the message payload from designated contextual information recognition sources. The NLU will provide back multiple message outputs to separate services (software) or resources (hardware) from a single derived intent (response to voice command initiator with visual sentence (shown or spoken) and transformed voice command message too different output messages to be consumed for M2M communications and actions) Natural-language understanding | Wikipedia
NLU uses algorithms to reduce human speech into a structured ontology. Then AI algorithms detect such things as intent, timing, locations, and sentiments. ... Natural language understanding is the first step in many processes, such as categorizing text, gathering news, archiving individual pieces of text, and, on a larger scale, analyzing content. Real-world examples of NLU range from small tasks like issuing short commands based on comprehending text to some small degree, like rerouting an email to the right person based on basic syntax and a decently-sized lexicon. Much more complex endeavors might be fully comprehending news articles or shades of meaning within poetry or novels. NLP vs. NLU: from Understanding a Language to Its Processing | Sciforce
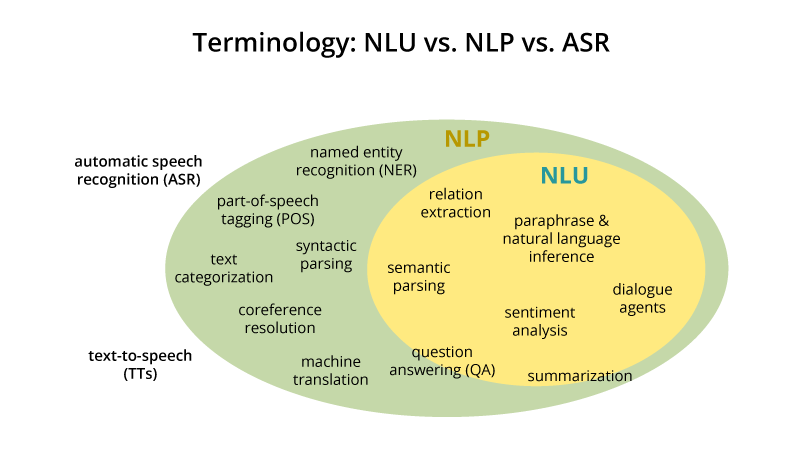
Image Source: Understanding Natural Language Understanding | Bill MacCartney
NLU Design Landscape | Cobus Greyling - Medium
Phonology (Phonetics)
Youtube search... ...Google search
Phonology is a branch of linguistics concerned with the systematic organization of sounds in spoken languages and signs in sign languages. It used to be only the study of the systems of phonemes in spoken languages (and therefore used to be also called phonemics, or phonematics), but it may also cover any linguistic analysis either at a level beneath the word (including syllable, onset and rime, articulatory gestures, articulatory features, mora, etc.) or at all levels of language where sound or signs are structured to convey linguistic meaning.
A Phoneme is the most basic sound unit of sound; any of the perceptually distinct units of sound in a specified language that distinguish one word from another, for example p, b, d, and t in the English words pad, pat, bad, and bat. Phoneme | Wikipedia
A Grapheme is the smallest unit of a writing system of any given language. An individual grapheme may or may not carry meaning by itself, and may or may not correspond to a single phoneme of the spoken language
Lexical (Morphology)
Lexical Ambiguity – Words have multiple meanings
The study of words, how they are formed, and their relationship to other words in the same language. It analyzes the structure of words and parts of words, such as stems, root words, prefixes, and suffixes. Morphology also looks at parts of speech, intonation and stress, and the ways context can change a word's pronunciation and meaning.About the words that make up the sentence, how they are formed, and how do they change depending on their context. Some examples of these include:
- Prefixes/suffixes
- Singularization/pluralization
- Gender detection
- Word inflection (modification of word to express different grammatical categories such tenses, case, voice etc..). Other forms of inflection includes conjugation (inflection of verbs) and declension (inflection of nouns, adjectives, adverbs etc…).
- Lemmatization (the base form of the word, or the reverse of inflection)
- Spell checking
Text Preprocessing
Cleaning and preparation the information for use, such as punctuation removal, spelling correction, lowercasing, stripping markup tags (HTML,XML)
Regular Expressions (Regex)
Youtube search... ...Google search
Search for text patterns, validate emails and URLs, capture information, and use patterns to save development time.

Soundex
Youtube search... ...Google search
a phonetic algorithm for indexing names by sound, as pronounced in English. The goal is for homophones to be encoded to the same representation so that they can be matched despite minor differences in spelling. The Soundex code for a name consists of a Letter alphabet followed by three numerical digits: the letter is the first letter of the name, and the digits encode the remaining consonants. Consonants at a similar place of articulation share the same digit so, for example, the labial consonants B, F, P, and V are each encoded as the number 1. Wikipedia
The correct value can be found as follows:
- Retain the first letter of the name and drop all other occurrences of a, e, i, o, u, y, h, w.
- Replace consonants with digits as follows (after the first letter):
- b, f, p, v → 1
- c, g, j, k, q, s, x, z → 2
- d, t → 3
- l → 4
- m, n → 5
- r → 6
- If two or more letters with the same number are adjacent in the original name (before step 1), only retain the first letter; also two letters with the same number separated by 'h' or 'w' are coded as a single number, whereas such letters separated by a vowel are coded twice. This rule also applies to the first letter.
- If you have too few letters in your word that you can't assign three numbers, append with zeros until there are three numbers. If you have more than 3 letters, just retain the first 3 numbers.
Tokenization / Sentence Splitting
Youtube search... ...Google search
- Bag-of-Words (BoW)
- Continuous Bag-of-Words (CBoW)
- Ngram Viewer | Google Books
- Language Squad The Greatest Language Identifying & Guessing Game
Tokenization is the process of demarcating (breaking text into individual words) and possibly classifying sections of a string of input characters. The resulting tokens are then passed on to some other form of processing. The process can be considered a sub-task of parsing input. A token (or n-gram) is a contiguous sequence of n items from a given sample of text or speech. The items can be phonemes, syllables, letters, words or base pairs according to the application.

Normalization
Youtube search... ...Google search
Process that converts a list of words to a more uniform sequence. .
Stemming (Morphological Similarity)
Youtube search... ...Google search
Stemmers remove morphological affixes from words, leaving only the word stem. Refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes.
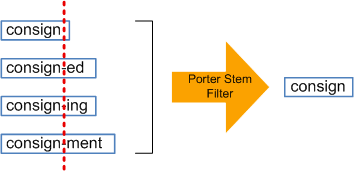
Lemmatization
Youtube search... ...Google search
Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma . If confronted with the token saw, stemming might return just s, whereas lemmatization would attempt to return either see or saw depending on whether the use of the token was as a verb or a noun. The two may also differ in that stemming most commonly collapses derivationally related words, whereas lemmatization commonly only collapses the different inflectional forms of a lemma. Stemming and lemmatization | Stanford.edu NLTK's lemmatizer knows "am" and "are" are related to "be."
Capitalization / Case Folding
Youtube search... ...Google search
A common strategy is to do case-folding by reducing all letters to lower case. Often this is a good idea: it will allow instances of Automobile at the beginning of a sentence to match with a query of automobile. It will also help on a web search engine when most of your users type in ferrari when they are interested in a Ferrari car. On the other hand, such case folding can equate words that might better be kept apart. Many proper nouns are derived from common nouns and so are distinguished only by case, including companies (General Motors, The Associated Press), government organizations (the Fed vs. fed) and person names (Bush, Black). We already mentioned an example of unintended query expansion with acronyms, which involved not only acronym normalization (C.A.T. $\rightarrow$ CAT) but also case-folding (CAT $\rightarrow$ cat). Capitalization/case-folding | Stanford
Similarity
Youtube search... ...Google search
Word Similarity
Youtube search... ...Google search
- Mapping Word Embeddings with Word2vec | Sam Liebman - Towards Data Science
- Word2Vec
- WordNet - One of the most important uses is to find out the similarity among words

Text Clustering
Youtube search... ...Google search
Syntax (Parsing)
- CoreNLP - see NLP parsing techniques by pasting your text | Stanford in Natural Language Tools & Services
Syntactic Ambiguity – Sentence is having multiple parse trees.
The set of rules, principles, and processes that govern the structure of sentences (sentence structure) in a given language, usually including word order. The term syntax is also used to refer to the study of such principles and processes. Focus on the relationship of the words within a sentence — how a sentence is constructed. In a way, syntax is what we usually refer to as grammar. To derive this understanding, syntactical analysis is usually done at a sentence-level, where as for morphology the analysis is done at word level. When we’re building dependency trees or processing parts-of-speech — we’re basically analyzing the syntax of the sentence.

Identity Scrubbing
Youtube search... ...Google search
- MITRE Identification Scrubber Toolkit (MIST) ...suite of tools for identifying and redacting personally identifiable information (PII) in free-text. For example, MIST can help you convert this document:
Patient ID: P89474
Mary Phillips is a 45-year-old woman with a history of diabetes. She arrived at New Hope Medical Center on August 5 complaining of abdominal pain. Dr. Gertrude Philippoussis diagnosed her with appendicitis and admitted her at 10 PM.
into this:
Patient ID: [ID]
[NAME] is a [AGE]-year-old woman with a history of diabetes. She arrived at [HOSPITAL] on [DATE] complaining of abdominal pain. Dr. [PHYSICIAN] diagnosed her with appendicitis and admitted her at 10 PM.
or this:
Patient ID: ID586
Sandy Parkinson is a 34-year-old woman with a history of diabetes. She arrived at Mercy Hospital on July 10 complaining of abdominal pain. Dr. Myron Prendergast diagnosed her with appendicitis and admitted her at 10 PM.
Stop Words
Youtube search... ...Google search
One of the major forms of pre-processing is to filter out useless data. In natural language processing, useless words (data), are referred to as stop words. A stop word is a commonly used word (such as “the”, “a”, “an”, “in”) that a search engine has been programmed to ignore, both when indexing entries for searching and when retrieving them as the result of a search query.
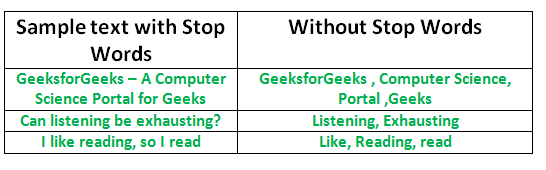
Relating Text
Understanding how the words relate to each other and the underlying grammar by segmenting the sentences syntax
Part-of-Speech (POS) Tagging
Youtube search... ...Google search
- Categorizing and Tagging Words | NLTK.org
- Part-of-Speech Tagging presentation | Stanford
- Parts of Speech Tagging with NLTK | Michael Elhadad Jupyter Notebook
- Python | PoS Tagging and Lemmatization using spaCy | GeeksforGeeks
(POST), also called grammatical tagging or word-category disambiguation, is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech,[1] based on both its definition and its context—i.e., its relationship with adjacent and related words in a phrase, sentence, or paragraph. A simplified form of this is commonly taught to school-age children, in the identification of words as nouns, verbs, adjectives, adverbs, etc.
Taggers:
- Trigrams’n’Tags (TnT) statistical part-of-speech tagger that is trainable on different languages and virtually any tagset. The component for parameter generation trains on tagged corpora. The system incorporates several methods of smoothing and of handling unknown words. TnT -- Statistical Part-of-Speech Tagging | Thorsten Brants
- N-Gram
- Unigram (Baseline) | NLTK.org
- Bigram - subclass uses previous tag as part of its context
- Trigram - subclass uses the previous two tags as part of its context
- Maximum Entropy (ME or MaxEnt) Examples | Stanford
- MEMM model for sequence labeling that combines features of hidden Markov models (HMMs) and Maximum Entropy
- Upper Bound
- Dependency
- Log-linear | Stanford
- Backoff | GeeksforGeeks allows to combine the taggers together. The advantage of doing this is that if a tagger doesn’t know about the tagging of a word, then it can pass this tagging task to the next backoff tagger. If that one can’t do it, it can pass the word on to the next backoff tagger, and so on until there are no backoff taggers left to check.
- Classifier-based | GeeksforGeeks
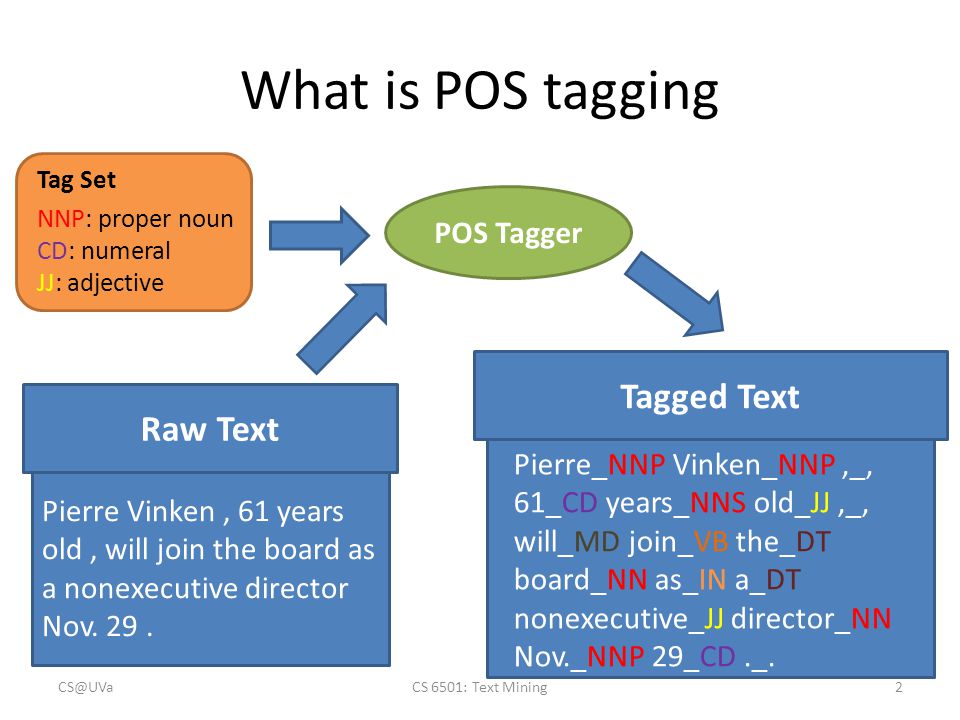
Constituency Tree
Youtube search... ...Google search
a one-to-one-or-more relation; every word in the sentence corresponds to one or more nodes in the tree diagram; employ the convention where the category acronyms (e.g. N, NP, V, VP) are used as the labels on the nodes in the tree. The one-to-one-or-more constituency relation is capable of increasing the amount of sentence structure to the upper limits of what is possible.

Chunking
Youtube search... ...Google search
The Hierarchy of Ideas (also known as chunking) is a linguistic tool used in NLP that allows the speaker to traverse the realms of abstract to specific easily and effortlessly. When we speak or think we use words that indicate how abstract, or how detailed we are in processing the information. In general, as human beings our brain is quite good at chunking information together in order to make it easier for us to process and simpler to understand. Thinking about the word “learning” for example is much simpler that thinking about all the different things that we could be learning about. When we memorise a telephone number or any other sequence of numbers we do not tend to memorise them as separate individual numbers, we group them together to make them easier to remember. Hierarchy of Ideas or Chunking in NLP | Excellence Assured

Chinking
Youtube search... ...Google search
The process of removing a sequence of tokens from a chunk. If the matching sequence of tokens spans an entire chunk, then the whole chunk is removed; if the sequence of tokens appears in the middle of the chunk, these tokens are removed, leaving two chunks where there was only one before. If the sequence is at the periphery of the chunk, these tokens are removed, and a smaller chunk remains.
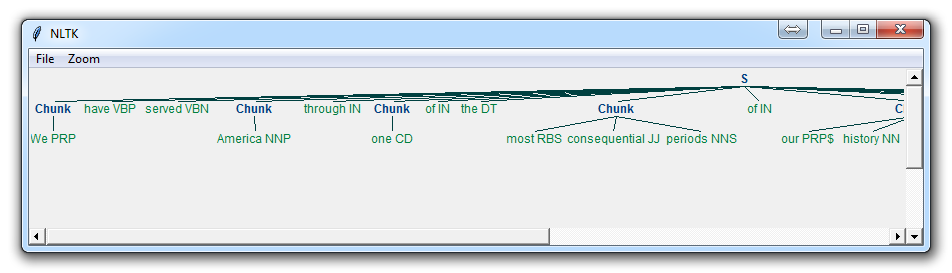
Semantics
- Semantic Ambiguity – Sentence having multiple meanings
The linguistic and philosophical study of meaning in language, programming languages, formal logics, and semiotics. It is concerned with the relationship between signifiers—like words, phrases, signs, and symbols—and what they stand for in reality, their denotation. The “meaning” of the sentence. It’s difficult to (i) link raw text to a knowledge base of mathematical facts in our system and (ii) combine pieces of knowledge together to infer an answer. Meaning in Natural Language is a multi-facetted concept with:
- semantic,
- pragmatic,
- cognitive and
- social aspects.
Word Embeddings
Youtube search... ...Google search
- Embedding ... Fine-tuning ... RAG ... Search ... Clustering ... Recommendation ... Anomaly Detection ... Classification ... Dimensional Reduction. ...find outliers
- Word2Vec
- Sense2Vec | Matthew Honnibal
- Global Vectors for Word Representation (GloVe)
- Word Embeddings Demo
- Representation Learning
- On the Dimensionality of Word Embedding | Zi Yin and Yuanyyuan Shen
- Introduction to Word Embedding and Word2Vec | Dhruvil Karani - Towards Data Science
- Unsupervised Cross-Modal Alignment of Speech and Text Embedding Spaces | Yu-An Chung, Wei-Hung Weng, Schrasing Tong, and James Glass
- Diffusion Maps for Textual Network Embedding | Xinyuan Zhang, Yitong Li, Dinghan Shen, and Lawrence Carin
- A Retrieve-and-Edit Framework for Predicting Structured Outputs | Tatsunori B. Hashimoto, Kelvin Guu, Yonatan Oren, and Percy Liang
The collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers.

Named Entity Recognition (NER)
Youtube search... ...Google search
- NLP Keras model in browser with TensorFlow.js
- Introduction to Named Entity Recognition | Suvro Banerjee - Medium
- NERClassifierCombiner | Stanford CoreNLP
- Named Entity Recognition: A Practitioner’s Guide to NLP | Dipanjan Sarkar - RedHat KDnuggets
Named Entities (also known as entity identification, entity chunking, sequence tagging, Part-of-Speech (POS) Tagging, and entity chunking/extraction) is a subtask of information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. Most research on NER systems has been structured as taking an unannotated block of text, and producing an annotated block of text that highlights the names of entities.
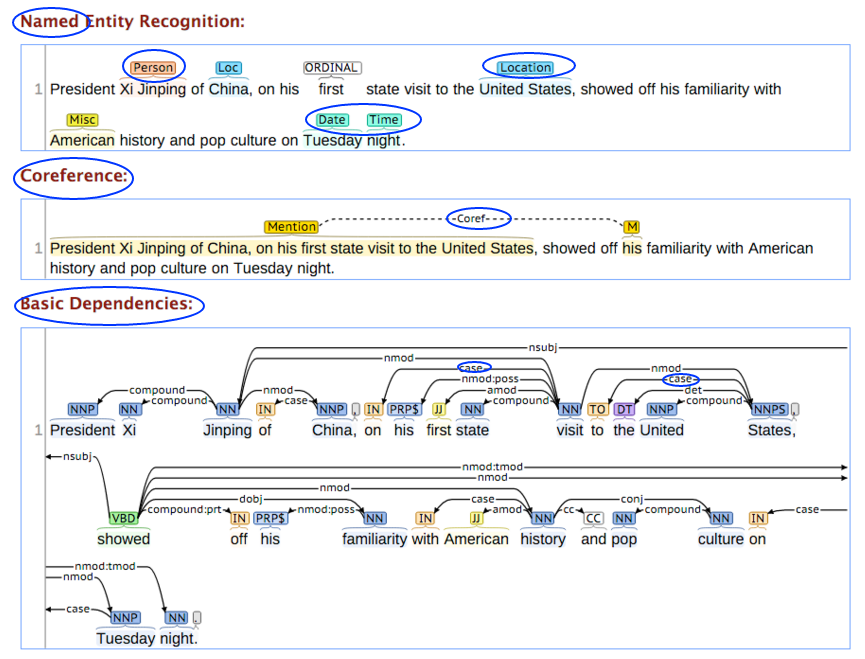
Semantic Slot Filling
Youtube search... ...Google search
- Semantic Slot Filling: Part 1 | Soumik Rakshit - mc.ai
- Main approaches in NLP | Anna Potapenko - National Research University Higher School of Economics - Coursera
One way of making sense of a piece of text is to tag the words or tokens which carry meaning to the sentences. There are three main approaches to solve this problem:
- Rule Based; regular expressions, context-free grammars
- Probabilistic modeling & Machine Learning; likelihood maximization, linear classifiers
- Deep Learning; recurrent neural networks, convolutional neural networks
Relation Extraction
Youtube search... ...Google search
task of extracting semantic relationships from a text. Extracted relationships usually occur between two or more entities of a certain type (e.g. Person, Organisation, Location) and fall into a number of semantic categories (e.g. married to, employed by, lives in). Relationship Extraction

Relation Extraction | Jun Tian
Discourse (Dialog)
Discourse is the creation and organization of the segments of a language above as well as below the sentence. It is segments of language which may be bigger or smaller than a single sentence but the adduced meaning is always beyond the sentence.
- identifying the discourse structure of a connected text, i.e. the nature of the discourse relationships between sentences (e.g. elaboration, explanation, contrast).
- recognizing and classifying the speech acts in a chunk of text (e.g. yes-no question, content question, statement, assertion, etc.).
The objects of discourse analysis (discourse, writing, conversation, communicative event) are variously defined in terms of coherent sequences of sentences, propositions, speech, or turns-at-talk.
The problems addressed in discourse research aim to answer two general kinds of questions:
- what information is contained in extended sequences of utterances that goes beyond the meaning of the individual utterances themselves?
- how does the context in which an utterance is used affect the meaning of the individual utterances, or parts of them?
Chapter 6 Discourse and Dialogue
Compared to traditional linguistics
Contrary to much of traditional linguistics, discourse analysts not only study language use 'beyond the sentence boundary' but also prefer to analyze 'naturally occurring' language use, not invented examples. Text linguistics is a closely related field. The essential difference between discourse analysis and text linguistics is that discourse analysis aims at revealing socio-psychological characteristics of a person/persons rather than text structure.
Pragmatics
Anaphoric Ambiguity – Phrase or word which is previously mentioned but has a different meaning.
Studies the ways in which context contributes to meaning. Pragmatics encompasses speech act theory, conversational implicature, talk in interaction and other approaches to language behavior in philosophy, sociology, linguistics and anthropology -- Understanding the text as a whole. Popular problems that we’re trying to solve at this stage are:
- Topic modelling
- Coreference/Anaphora
- Summarization
- Question & Answering
Grouping
Sentence/Document Similarity
Youtube search... ...Google search
- Document Similarity
- Term Frequency–Inverse Document Frequency (TF-IDF)
- Doc2Vec
- Text2Vec
- Applying the four-step "Embed, Encode, Attend, Predict" framework to predict document similarity | Sujit Pal
- Sentence Similarity in Python using Doc2Vec | Kanoki As a next step you can use the Bag of Words or TF-IDF model to covert these texts into numerical feature and check the accuracy score using cosine similarity.
Word embeddings have become widespread in Natural Language Processing. They allow us to easily compute the semantic similarity between two words, or to find the words most similar to a target word. However, often we're more interested in the similarity between two sentences or short texts. Comparing Sentence Similarity Methods | Yves Peirsman - NLPtown

Text Classification
Youtube search... ...Google search
- Large Language Model (LLM) ... Natural Language Processing (NLP) ...Generation ... Classification ... Understanding ... Translation ... Tools & Services
- A Survey of Hierarchical Classification Across Different Application Domains | Carlos N. Silla Jr. and Alex A. Freitas
- Hierarchical Classification – a useful approach for predicting thousands of possible categories | Pedro Chaves - KDnuggets
- Problem-solving with ML: automatic document classification | Ahmed Kachkach
Tasks:
- predict tags or categories
- predict sentiment
- filter spam eMails
Text Classification approaches:
- Flat - there is no inherent hierarchy between the possible categories the data can belong to (or we chose to ignore it). Train either a single classifier to predict all of the available classes or one classifier per category (1 vs All)
- Hierarchically - organizing the classes, creating a tree or DAG (Directed Acyclic Graph) of categories, exploiting the information on relationships among them. Although there are different types of hierarchical classification approaches, the difference between both modes of reasoning and analysing are particularly easy to understand in these illustrations, taken from a great review on the subject by Silla and Freitas (2011). Taking a top-down approach, training a classifier per level (or node) of the tree (again, although this is not the only hierarchical approach, it is definitely the most widely used and the one we’ve selected for our problem at hands), where a given decision will lead us down a different classification path.
Topic Modeling
Youtube search... ...Google search
A type of statistical modeling for discovering the abstract “topics” that occur in a collection of documents. Latent Dirichlet Allocation (LDA) is an example of topic model and is used to classify text in a document to a particular topic
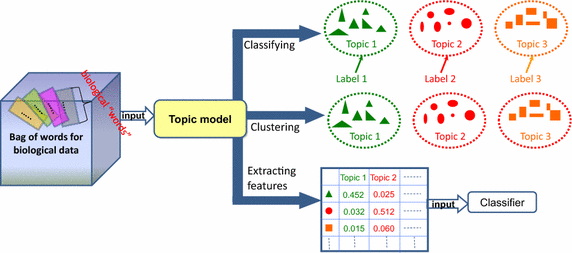
Neural Coreference
Youtube search... ...Google search
Coreference is the fact that two or more expressions in a text – like pronouns or nouns – link to the same person or thing. It is a classical Natural language processing task, that has seen a revival of interest in the past two years as several research groups applied cutting-edge deep-learning and reinforcement-learning techniques to it. It is also one of the key building blocks to building conversational Artificial intelligence.
Whole Word Masking
Youtube search... ...Google search
Training the language model in Bidirectional Encoder Representations from Transformers (BERT) is done by predicting 15% of the tokens in the input, that were randomly picked. These tokens are pre-processed as follows — 80% are replaced with a “[MASK]” token, 10% with a random word, and 10% use the original word. The intuition that led the authors to pick this approach is as follows (Thanks to Jacob Devlin from Google for the insight):
- If we used [MASK] 100% of the time the model wouldn’t necessarily produce good token representations for non-masked words. The non-masked tokens were still used for context, but the model was optimized for predicting masked words.
- If we used [MASK] 90% of the time and random words 10% of the time, this would teach the model that the observed word is never correct.
- If we used [MASK] 90% of the time and kept the same word 10% of the time, then the model could just trivially copy the non-contextual embedding.
Managed Vocabularies
Corpora
Youtube search... ...Google search
A corpus (plural corpora) or text corpus is a large and structured set of texts (nowadays usually electronically stored and processed). In corpus linguistics, they are used to do statistical analysis and hypothesis testing, checking occurrences or validating linguistic rules within a specific language territory.
|
|
Building your Corpora | Yassine Iabdounane
- Ant
- AntConc - a freeware corpus analysis toolkit for concordancing and text analysis.
- AntLab | Laurence Anthony
- jusText - a heuristic based boilerplate removal tool.
|
|
|
|
|
|
|
|
Ontology
- Ontology
- Teaching Natural Language Processing (NLP) Using Ontology Based Education Design | Zobia Rehman and Stefania Kifor
- Understanding Ontology and How It Adds Value to NLU... ntroduction to ontologies and how they can be used in data science today with the NLU 101 series. It explains what ontologies are, why they are important, how they are created, and how they are used in NLU applications.
- Natural Language Ontology ... Stanford Encyclopedia of Philosophy that discusses natural language ontology as a sub-discipline of both philosophy and linguistics. It covers the history, scope, methods, features, and challenges of natural language ontology and its relation to reality, truth conditions, cognition, and reasoning.
- Towards More Robust Natural Language Understanding ... surveys the recent advances and challenges in natural language understanding (NLU) with deep learning techniques. It covers various NLU tasks, such as text classification, information extraction, natural language inference, question answering, dialogue systems, and text generation. It also discusses the limitations and future directions of NLU research.
Taxonomy
Youtube search... ...Google search
The practice and science of classification of things or concepts, including the principles that underlie such classification.

Related
Workbench / Pipeline
Youtube search... ...Google search
- AIOps/MLOps e.g. Google Kubeflow Pipelines
- Natural Language Tools & Services
- CogComp NLP Pipeline | Cognitive Computation Group, led by Prof. Dan Roth
- Building Custom Text Analytics solutions using Azure Machine Learning (AML)
- H2O Driverless AI
- GATE toolkit
- Apache UIMA - Unstructured Information Management Applications
- An Ontology-Enabled Natural Language Processing Pipeline for Provenance Metadata Extraction from Biomedical Text | J. Valdez, M. Rueschman, M. Kim, S. Redline, and S. Sahoo


Sapir Whorf Hypothesis - How language shapes the way we think
Youtube search... ...Google search
General Natural Language Processing (NLP) Videos
Natural Language Processing (NLP) Techniques
Youtube search... | Quora search... ...Google search
Speech recognition, (speech) translation, understanding (semantic parsing) complete sentences, understanding synonyms of matching words, Sentiment Analysis, and writing/generating complete grammatically correct sentences and paragraphs.
- Natural Language Processing (NLP) ...Generation ...LLM ...Tools & Services
- Text Transfer Learning
- End-to-End Speech
- Topic Model/Mapping
- Combination of Convolutional and Recurrent Neural Network for Sentiment Analysis of Short Texts | Xingyou Wang, Weijie Jiang, Zhiyong Luo
- NLP Techniques: A Preliminary Cornerstone List | Martin Messier
- Linguistic Knowledge in Natural Language Processing | Hafidz Zulkifli | Towards Data Science - Medium
- Extracting Information from Text | NLTK.org
- Linguistic Correlation Analysis - Putting neural networks under the microscope | Rob Matheson
- Google Docs uses AI to catch your grammar mistakes | Jon Fingas - Engadget
- Introducing the Kensho Derived Wikimedia Dataset (KDWD) | Gabriel Altay - Kensho - Medium Wikipedia, the free encyclopedia, and Wikidata, the free knowledge base, are crowd-sourced projects supported by the Wikimedia Foundation. Kaggle notebooks:
- Kensho Derived Wikimedia Dataset
- How to Build a Smart Synonyms Model | Patrick O'Beill - Medium ...Entity Aliases and Disambiguation Candidates with Anchor Link Statistics
- Explicit Topic Models
- Word Vectors from Decomposing a Word-Word Pointwise Mutual Information Matrix
- Create Named entity recognition (NER) Labels for Wikidata Items Based on Subclass Paths