Objective vs. Cost vs. Loss vs. Error Function
YouTube ... Quora ... Google search ... Google News ... Bing News
- AI Agent Optimization ... Optimization Methods ... Optimizer ... Objective vs. Cost vs. Loss vs. Error Function ... Exploration
- Backpropagation ... FFNN ... Forward-Forward ... Activation Functions ...Softmax ... Loss ... Boosting ... Gradient Descent ... Hyperparameter ... Manifold Hypothesis ... PCA
- AI Solver ... Algorithms ... Administration ... Model Search ... Discriminative vs. Generative ... Train, Validate, and Test
- Error Analysis to Your Rescue! | Kritika Jalan
- 5 Regression Loss Functions All Machine Learners Should Know | Prince Grover
- Process Supervision
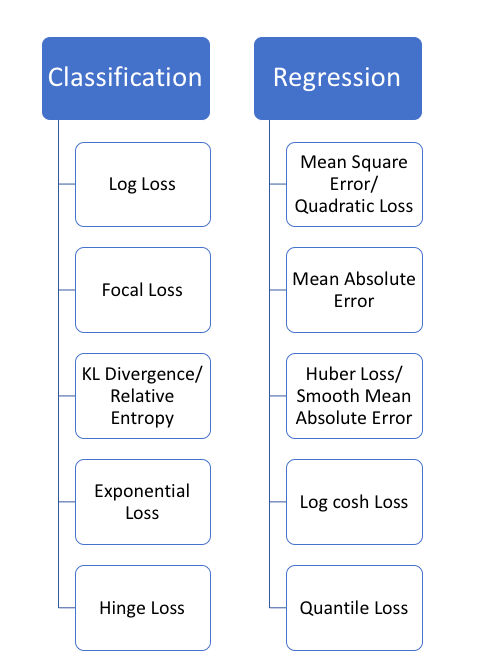
"The function we want to minimize or maximize is called the objective function, or criterion. When we are minimizing it, we may also call it the cost function, loss function, or error function - these terms are synonymous. The cost function is used more in optimization problem and loss function is used in parameter estimation.
The loss function (or error) is for a single training example, while the cost function is over the entire training set (or mini-batch for mini-batch gradient descent). Therefore, a loss function is a part of a cost function which is a type of an objective function. Objective function, cost function, loss function: are they the same thing? | StackExchange
- Loss function is usually a function defined on a data point, prediction and label, and measures the penalty. For example:
- square loss l(f(xi|θ),yi)=(f(xi|θ)−yi)2, used in linear Regression
- hinge loss l(f(xi|θ),yi)=max(0,1−f(xi|θ)yi), used in SVM
- 0/1 loss l(f(xi|θ),yi)=1⟺f(xi|θ)≠yi, used in theoretical analysis and definition of accuracy
- Cost function is usually more general. It might be a sum of loss functions over your training set plus some model complexity penalty (regularization). For example:
- Mean Squared Error MSE(θ)=1N∑Ni=1(f(xi|θ)−yi)2
- SVM cost function SVM(θ)=∥θ∥2+C∑Ni=1ξi (there are additional constraints connecting ξi with C and with training set)
- Objective function is the most general term for any function that you optimize during training. For example, a probability of generating training set in maximum likelihood approach is a well defined objective function, but it is not a loss function nor cost function (however you could define an equivalent cost function). For example:
- MLE is a type of objective function (which you maximize)
- Divergence between classes can be an objective function but it is barely a cost function, unless you define something artificial, like 1-Divergence, and name it a cost
- Error function - Backpropagation; or automatic differentiation, is commonly used by the gradient descent optimization algorithm to adjust the weight of neurons by calculating the gradient of the loss function. This technique is also sometimes called backward propagation of errors, because the error is calculated at the output and distributed back through the network layers. Backpropagation | Wikipedia