Attention
YouTube search... ...Google search
- Large Language Model (LLM) ... Multimodal ... Foundation Models (FM) ... Generative Pre-trained ... Transformer ... GPT-4 ... GPT-5 ... Attention ... GAN ... BERT
- State Space Model (SSM) ... Mamba ... Sequence to Sequence (Seq2Seq) ... Recurrent Neural Network (RNN) ... Convolutional Neural Network (CNN)
- In-Context Learning (ICL) ... Context ... Causation vs. Correlation ... Autocorrelation ... Out-of-Distribution (OOD) Generalization ... Transfer Learning
- Natural Language Processing (NLP) ... Generation (NLG) ... Classification (NLC) ... Understanding (NLU) ... Translation ... Summarization ... Sentiment ... Tools
- Agents ... Robotic Process Automation ... Assistants ... Personal Companions ... Productivity ... Email ... Negotiation ... LangChain
- Artificial Intelligence (AI) ... Generative AI ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Conversational AI ... ChatGPT | OpenAI ... Bing/Copilot | Microsoft ... Gemini | Google ... Claude | Anthropic ... Perplexity ... You ... phind ... Ernie | Baidu
- Video/Image ... Vision ... Enhancement ... Fake ... Reconstruction ... Colorize ... Occlusions ... Predict image ... Image/Video Transfer Learning
- End-to-End Speech ... Synthesize Speech ... Speech Recognition ... Music
- ChatGPT is everywhere. Here’s where it came from | Will Douglas Heaven - MIT Technology Review
- Sequence to Sequence (Seq2Seq)
- Recurrent Neural Network (RNN)
- Long Short-Term Memory (LSTM)
- Bidirectional Encoder Representations from Transformers (BERT) ... a better model, but less investment than the larger OpenAI organization
- Autoencoder (AE) / Encoder-Decoder
- Memory Networks ... Agent communications
- Feature Exploration/Learning
- Embedding ... Fine-tuning ... RAG ... Search ... Clustering ... Recommendation ... Anomaly Detection ... Classification ... Dimensional Reduction. ...find outliers
- Attention? Attention! | Lilian Weng
- The Illustrated Transformer | Jay Alammar
- Attention in NLP | Kate Loginova - Medium
- Attention Mechanism | Gabriel Loye - FloydHub
- In Depth Understanding of Attention Mechanism (Part I) | FunCry - Medioum
Attention networks are a kind of short-term memory that allocates attention over input features they have recently seen. Attention mechanisms are components of memory networks, which focus their attention on external memory storage rather than a sequence of hidden states in a Recurrent Neural Networks (RNN). Memory networks are a little different, but not too. They work with external data storage, and they are useful for, say, mapping questions as input to answers stored in that external memory. That external data storage acts as an embedding that the attention mechanism can alter, writing to the memory what it learns, and reading from it to make a prediction. While the hidden states of a recurrent neural network are a sequence of embeddings, memory is an accumulation of those embeddings (imagine performing max pooling on all your hidden states – that would be like memory). A Beginner's Guide to Attention Mechanisms and Memory Networks | Skymind
Attention mechanisms in neural networks are about memory access. That’s the first thing to remember about attention: it’s something of a misnomer. In computer vision Attention is used to highlight important parts of an image that contribute to a desired output
In the Transformer, the Attention module repeats its computations multiple times in parallel. Each of these is called an Attention Head. The Attention module splits its Query, Key, and Value parameters N-ways and passes each split independently through a separate Head. All of these similar Attention calculations are then combined together to produce a final Attention score. This is called Multi-head attention and gives the Transformer greater power to encode multiple relationships and nuances for each word. Transformers Explained Visually (Part 3): Multi-head Attention, deep dive | Ketan Doshi - Towards Data Science
The context vector turned out to be a bottleneck for these types of models. It made it challenging for the models to deal with long sentences. A solution was proposed in Bahdanau et al., 2014 and Luong et al., 2015. These papers introduced and refined a technique called “Attention”, which highly improved the quality of machine translation systems. Attention allows the model to focus on the relevant parts of the input sequence as needed. Let’s continue looking at attention models at this high level of abstraction. An attention model differs from a classic sequence-to-sequence model in two main ways: Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) | Jay Alammar
- First, the encoder passes a lot more data to the decoder. Instead of passing the last hidden state of the encoding stage, the encoder passes all the hidden states to the decoder
- Second, an attention decoder does an extra step before producing its output. In order to focus on the parts of the input that are relevant to this decoding time step
![]()
|
|
Contents
Attention Is All You Need
The dominant sequence transduction models are based on complex Recurrent Neural Network (RNN)) or (Deep) Convolutional Neural Network (DCNN/CNN) in an encoder-decoder (Autoencoder (AE) / Encoder-Decoder} configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Attention Is All You Need | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser, and I. Polosukhin - Google
“Attention Is All You Need” without a doubt, is one of the most impactful and interesting paper in 2017. It presented a lot of improvements to the soft attention and make it possible to do Sequence to Sequence (Seq2Seq) modeling without Recurrent Neural Network (RNN) units. The proposed “transformer” model is entirely built on the Self-Attention mechanisms without using sequence-aligned recurrent architecture.
Imagine you are at a party and you are trying to have a conversation with someone. There are a lot of other people talking around you, and it's hard to focus on just one conversation. But then you notice that your friend is wearing a bright red shirt. You can start to focus on your friend's conversation more easily, because their red shirt helps you to identify them in the crowd. Attention in AI works in a similar way. It assigns weights to different parts of the input, just like the brightness of your friend's shirt. The higher the weight, the more important the model thinks that part is. The model then uses these weights to combine the information from all of the parts of the input to produce a final output.
Key, Value, and Query
Given a query q and a set of key-value pairs (K, V), attention can be generalized to compute a weighted sum of the values dependent on the query and the corresponding keys. The query determines which values to focus on; we can say that the query 'attends' to the values. Attention and its Different Forms | Anusha Lihala - Towards Data Science
The secret recipe is carried in its model architecture
The major component in the transformer is the unit of multi-head Self-Attention mechanism. The transformer views the encoded representation of the input as a set of key-value pairs, (K,V), both of dimension n (input sequence length); in the context of NMT, both the keys and values are the encoder hidden states. In the decoder, the previous output is compressed into a query (Q of dimension m) and the next output is produced by mapping this query and the set of keys and values.
The transformer adopts the scaled Dot Product Attention: the output is a weighted sum of the values, where the weight assigned to each value is determined by the Dot Product of the query with all the keys:
Attention(Q,K,V)=softmax(QK⊤n−−√)V
Multi-Head Self-Attention
- Transformers Explained Visually (Part 3): Multi-head Attention, deep dive | Ketan Doshi - Towards Data Science ... A Gentle Guide to the inner workings of Self-Attention, Encoder-Decoder Attention, Attention Score and Masking, in Plain English.
- GPT-4 explaining Self-Attention Mechanism | Fatos Ismali
Multi-head scaled Dot Product Attention
Rather than only computing the Attention once, the multi-head mechanism runs through the scaled Dot Product Attention multiple times in parallel. The independent Attention outputs are simply concatenated and linearly transformed into the expected dimensions. I assume the motivation is because ensembling always helps? ;) According to the paper, “multi-head Attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single Attention head, averaging inhibits this.” Attention? Attention! | Lilian Weng
Explained
Attention Head
An attention head is a component of the attention mechanism, which is a technique used by AI models to focus on specific parts of an input sequence when making a prediction. Attention heads are particularly useful for Natural Language Processing (NLP) tasks, where they can help models to understand the relationships between words in a sentence.
Attention heads work by calculating a set of weights for each token in the input sequence. These weights represent the importance of each token to the model's prediction. The model then uses these weights to combine the information from all of the tokens in the sequence to produce a final output.
One way to think about attention heads is as a set of parallel filters. Each filter is tuned to a different aspect of the input sequence. For example, one filter might be tuned to long-range dependencies, while another filter might be tuned to short-range dependencies. By combining the outputs of all of the filters, the model can get a more complete understanding of the input sequence.
Attention heads are typically used in a multi-head attention architecture. This means that the model uses multiple attention heads in parallel, each of which is tuned to a different aspect of the input sequence. The outputs of the attention heads are then combined to produce the final output.
Multi-head attention has been shown to be very effective for a variety of NLP tasks, including machine translation, text summarization, and question answering. It is also used in many state-of-the-art large language models, such as GPT-3 and LaMDA.
Here is an example of how attention heads can be used in NLP:
Consider the following sentence:
The cat sat on the mat.
An attention head might calculate the following weights for each word in the sentence:
- The: 0.2
- cat: 0.5
- sat: 0.3
- on: 0.2
- the: 0.1
- mat: 0.7
The model would then use these weights to combine the information from all of the words in the sentence to produce a final output. For example, the model might predict that the next word in the sentence is likely to be "and" because that word often follows the word "mat" in sentences.
Induction Head
An induction head is a type of attention head that is used to implement a simple algorithm to complete token sequences. Induction heads are particularly useful for in-context learning, which is the ability of a language model to learn new information from the context in which it is used. induction heads are a powerful tool for in-context learning that has the potential to improve the performance of language models on a wide range of tasks.
Induction heads work by copying information from the previous token into each token. In other words, an induction head will pay attention to the previous token in a sequence and then use that information to predict the next token.
For example, consider the following sequence:
[A] [B] [A] [B]
An induction head would learn to predict that the next token in the sequence will be [B] because that is the token that came after [A] in the previous two instances.
Induction heads are a powerful tool for in-context learning because they allow language models to learn new patterns from the data that they are exposed to. This is in contrast to traditional language models, which are typically trained on a large corpus of text and then used to generate text that is similar to the text that they were trained on.
Induction heads are still under development, but they have the potential to revolutionize the way that language models are trained and used.
Here are some examples of how induction heads can be used in AI:
- Natural Language Processing (NLP): Induction heads can be used to improve the performance of language models on tasks such as machine translation, text summarization, and question answering.
- Code generation: Induction heads can be used to generate code from natural language descriptions.
- Creative AI: Induction heads can be used to generate creative text formats, such as poems, code, scripts, and musical pieces.
SNAIL
The transformer has no Recurrent Neural Network (RNN) or (Deep) Convolutional Neural Network (DCNN/CNN) structure, even with the positional encoding added to the embedding vector, the sequential order is only weakly incorporated. For problems sensitive to the positional dependency like Reinforcement Learning (RL), this can be a big problem.
The Simple Neural Attention Meta-Learner (SNAIL) (Mishra et al., 2017) was developed partially to resolve the problem with positioning in the transformer model by combining the self-attention Attention in transformer with temporal convolutions. It has been demonstrated to be good at both Supervised learning and Reinforcement Learning (RL) tasks. Attention? Attention! | Lilian Weng
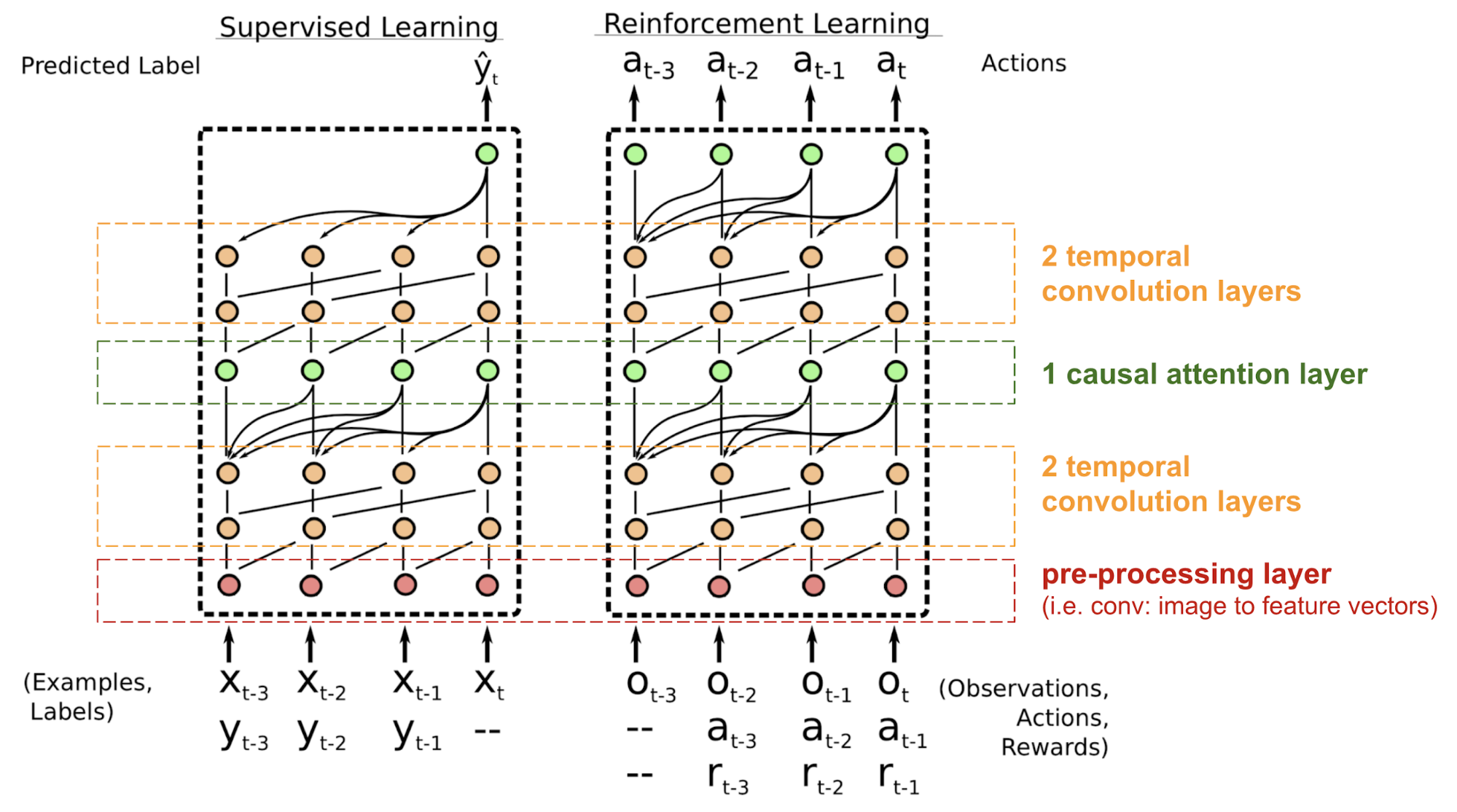
Making decisions about where to send information
History
The history of attention in AI can be traced back to the 1980s, when it was first proposed as a way to improve the performance of Neural Networks. However, it was not until the 2010s that attention became widely used in AI, thanks to advances in computing power and the development of new training algorithms.
One of the most important advances in attention was the development of the Transformer architecture in 2017. Transformers are a type of Neural Network that uses attention extensively to achieve state-of-the-art results on a variety of Natural Language Processing (NLP) tasks.
Since then, attention has become a key component of many state-of-the-art AI models, including Large Language Model (LLM) such as GPT-4 and LaMDA. LLMs are trained on massive datasets of text and code, and they can be used to generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
Some of the latest advances in attention include:
- Induction heads: a type of attention head that can be used to implement a simple algorithm to complete token sequences. Induction heads are particularly useful for in-context learning, which is the ability of a language model to learn new information from the context in which it is used.
- Self-attention: a type of attention mechanism that allows a model to focus on different parts of its own input sequence. This is particularly useful for tasks such as machine translation and question answering, where the model needs to be able to understand the relationships between different parts of the input sequence.
- Cross-attention: a type of attention mechanism that allows a model to focus on different parts of two different input sequences. This is particularly useful for tasks such as text summarization and question answering, where the model needs to be able to understand the relationships between the input text and the output text.
More Explanation