Sequence to Sequence (Seq2Seq)
YouTube ... Quora ...Google search ...Google News ...Bing News
- State Space Model (SSM) ... Mamba ... Sequence to Sequence (Seq2Seq) ... Recurrent Neural Network (RNN) ... Convolutional Neural Network (CNN)
- Large Language Model (LLM) ... Multimodal ... Foundation Models (FM) ... Generative Pre-trained ... Transformer ... Attention ... GAN ... BERT
- Natural Language Processing (NLP) ... Generation (NLG) ... Classification (NLC) ... Understanding (NLU) ... Translation ... Summarization ... Sentiment ... Tools
- Open Seq2Seq | NVIDIA
- Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) | Jay Alammar
- Autoencoder (AE) / Encoder-Decoder
- Embedding - projecting an input into another more convenient representation space; e.g. word represented by a vector
- Embedding ... Fine-tuning ... RAG ... Search ... Clustering ... Recommendation ... Anomaly Detection ... Classification ... Dimensional Reduction. ...find outliers
- NLP Keras model in browser with TensorFlow.js
- LOOKING FOR SEQUENCE DIAGRAMS
- NLP - Sequence to Sequence Networks - Part 1 - Processing text data | Mohammed Ma'amari - Towards Data Science
- Understanding Encoder-Decoder Sequence to Sequence Model | Simeon Kostadinov - Towards Data Science
- End-to-End Speech ... Synthesize Speech ... Speech Recognition ... Music
- Artificial Intelligence (AI) ... Generative AI ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Conversational AI ... ChatGPT | OpenAI ... Bing/Copilot | Microsoft ... Gemini | Google ... Claude | Anthropic ... Perplexity ... You ... phind ... Ernie | Baidu
A general-purpose encoder-decoder that can be used for machine translation, text summarization, [[conversational modeling, image captioning, interpreting dialects of software code, and more. The encoder processes each item in the input sequence, it compiles the information it captures into a vector (called the context). After processing the entire input sequence, the encoder sends the context over to the decoder, which begins producing the output sequence item by item. The context is a vector (an array of numbers, basically) in the case of machine translation. The encoder and decoder tend to both be Recurrent Neural Network (RNN). Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) | Jay Alammar
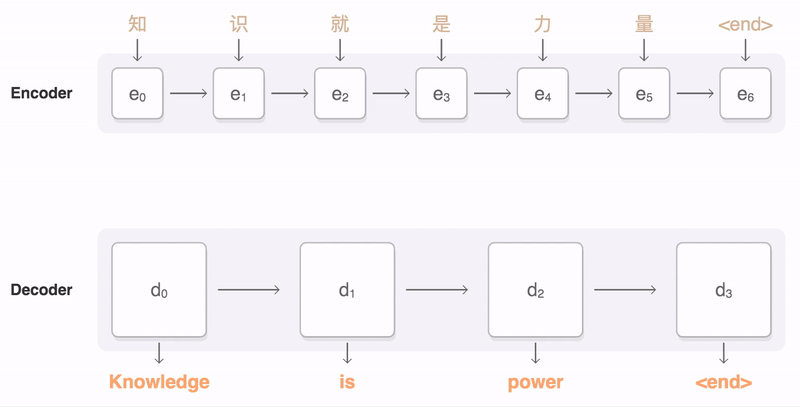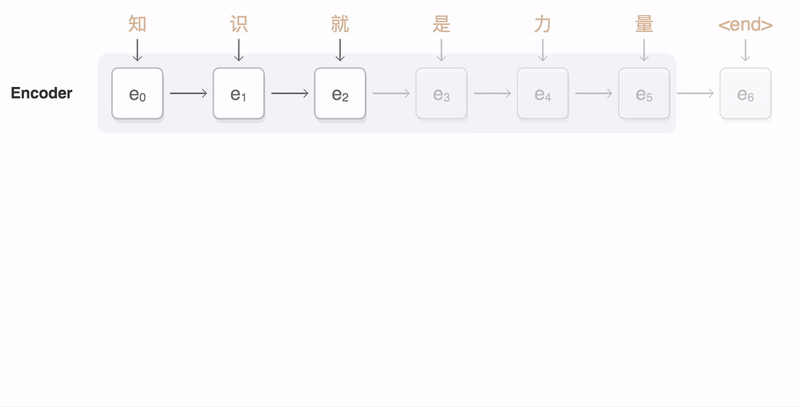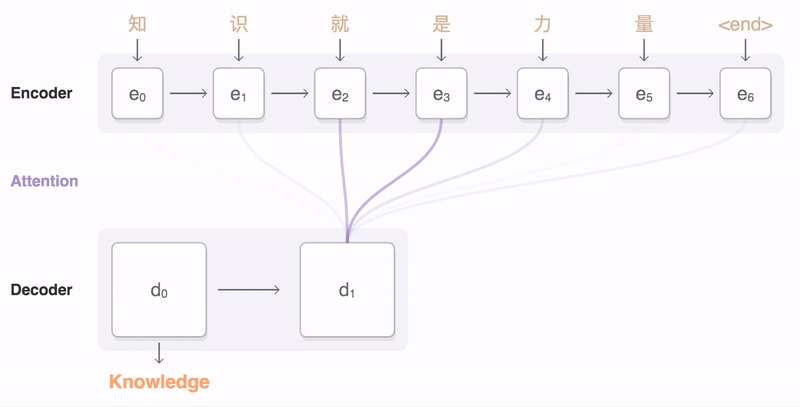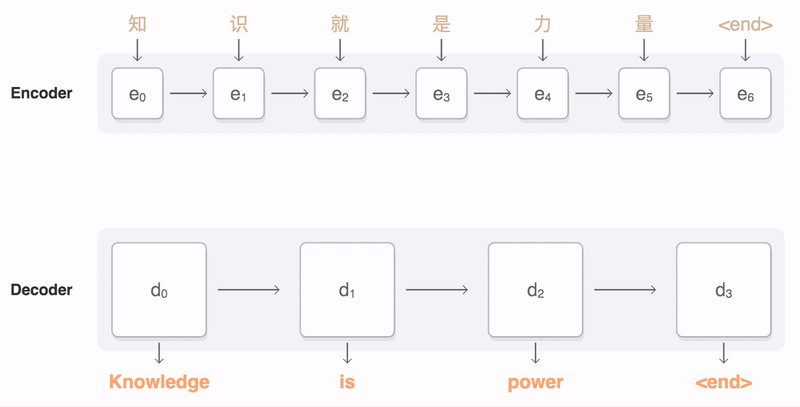
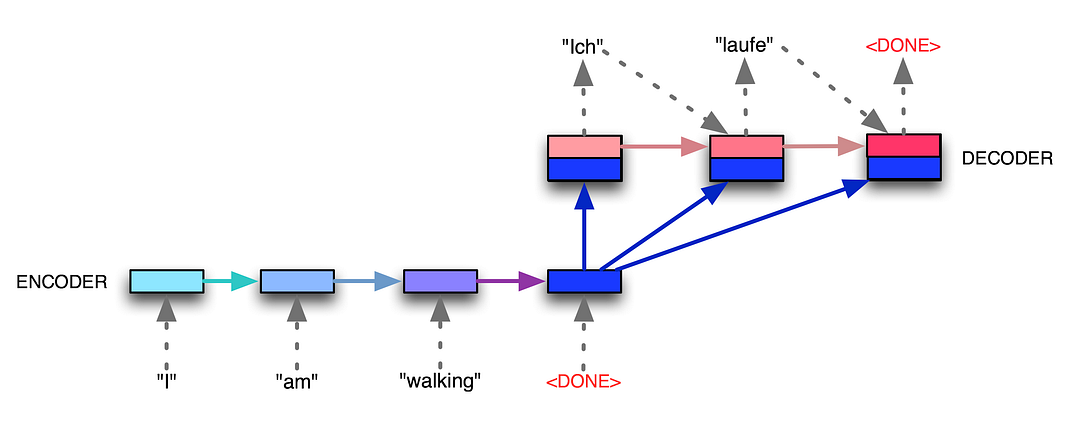
We essentially have two different recurrent neural networks tied together here — the encoder RNN (bottom left boxes) listens to the input tokens until it gets a special <DONE> token, and then the decoder RNN (top right boxes) takes over and starts generating tokens, also finishing with its own <DONE> token. The encoder RNN evolves its internal state (depicted by light blue changing to dark blue while the English sentence tokens come in), and then once the <DONE> token arrives, we take the final encoder state (the dark blue box) and pass it, unchanged and repeatedly, into the decoder RNN along with every single generated German token. The decoder RNN also has its own dynamic internal state, going from light red to dark red. Voila! Variable-length input, variable-length output, from a fixed-size architecture. seq2seq: the clown car of deep learning | Dev Nag - Medium
Retrieval Augmented Generation (RAG)
- Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models Facebook AI
- Facebook’s Flexible ‘RAG’ Language Model Achieves SOTA Results on Open-Domain QA | Synced
Building a model that researches and contextualizes is more challenging, but it's essential for future advancements. We recently made substantial progress in this realm with our Retrieval Augmented Generation (RAG) architecture, an end-to-end differentiable model that combines an information retrieval component (Facebook AI’s dense-passage retrieval system ) with a seq2seq generator (our Bidirectional and Auto-Regressive Transformers [BART] model). RAG can be fine-tuned on knowledge-intensive downstream tasks to achieve state-of-the-art results compared with even the largest pretrained seq2seq language models. And unlike these pretrained models, RAG’s internal knowledge can be easily altered or even supplemented on the fly, enabling researchers and engineers to control what RAG knows and doesn’t know without wasting time or compute power retraining the entire model.

|
|