Difference between revisions of "Algorithm Administration"
m |
m |
||
| Line 38: | Line 38: | ||
** [http://www.wandb.com/ Weights and Biases] ...experiment tracking, model optimization, and dataset versioning | ** [http://www.wandb.com/ Weights and Biases] ...experiment tracking, model optimization, and dataset versioning | ||
** [http://feedback.azure.com/forums/906052-data-catalog How can we improve Azure Data Catalog?] | ** [http://feedback.azure.com/forums/906052-data-catalog How can we improve Azure Data Catalog?] | ||
| + | ** [http://sigopt.com/ SigOpt] ...optimization platform and API designed to unlock the potential of modeling pipelines. This fully agnostic software solution accelerates, amplifies, and scales the model development process | ||
* [http://getmanta.com/?gclid=CjwKCAjwsfreBRB9EiwAikSUHSSOxld0nZNyLNXmiPM43x7jEAgeTxkXRH_s5XPJlfTekPdO8N1Y1xoCKwwQAvD_BwE Automate your data lineage] | * [http://getmanta.com/?gclid=CjwKCAjwsfreBRB9EiwAikSUHSSOxld0nZNyLNXmiPM43x7jEAgeTxkXRH_s5XPJlfTekPdO8N1Y1xoCKwwQAvD_BwE Automate your data lineage] | ||
* [http://www.information-age.com/benefiting-ai-data-management-123471564/ Benefiting from AI: A different approach to data management is needed] | * [http://www.information-age.com/benefiting-ai-data-management-123471564/ Benefiting from AI: A different approach to data management is needed] | ||
| Line 184: | Line 185: | ||
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| + | |||
| + | = <span id="Hyperparameter"></span>Hyperparameter = | ||
| + | [http://www.youtube.com/results?search_query=hyperparameters+deep+learning+tuning+optimization YouTube search...] | ||
| + | [http://www.google.com/search?q=hyperparameters+optimization+deep+machine+learning+ML ...Google search] | ||
| + | |||
| + | * [[Gradient Descent Optimization & Challenges]] | ||
| + | * [http://cloud.google.com/ml-engine/docs/tensorflow/using-hyperparameter-tuning Using TensorFlow Tuning] | ||
| + | * [http://towardsdatascience.com/understanding-hyperparameters-and-its-optimisation-techniques-f0debba07568 Understanding Hyperparameters and its Optimisation techniques | Prabhu - Towards Data Science] | ||
| + | * [http://nanonets.com/blog/hyperparameter-optimization/ How To Make Deep Learning Models That Don’t Suck | Ajay Uppili Arasanipalai] | ||
| + | |||
| + | In machine learning, a hyperparameter is a parameter whose value is set before the learning process begins. By contrast, the values of other parameters are derived via training. Different model training algorithms require different hyperparameters, some simple algorithms (such as ordinary least squares regression) require none. Given these hyperparameters, the training algorithm learns the parameters from the data. [http://en.wikipedia.org/wiki/Hyperparameter_(machine_learning) Hyperparameter (machine learning) | Wikipedia] | ||
| + | |||
| + | Machine learning algorithms train on data to find the best set of weights for each independent variable that affects the predicted value or class. The algorithms themselves have variables, called hyperparameters. They’re called hyperparameters, as opposed to parameters, because they control the operation of the algorithm rather than the weights being determined. The most important hyperparameter is often the learning rate, which determines the step size used when finding the next set of weights to try when optimizing. If the learning rate is too high, the gradient descent may quickly converge on a plateau or suboptimal point. If the learning rate is too low, the gradient descent may stall and never completely converge. Many other common hyperparameters depend on the algorithms used. Most algorithms have stopping parameters, such as the maximum number of epochs, or the maximum time to run, or the minimum improvement from epoch to epoch. Specific algorithms have hyperparameters that control the shape of their search. For example, a [[Random Forest (or) Random Decision Forest]] Classifier has hyperparameters for minimum samples per leaf, max depth, minimum samples at a split, minimum weight fraction for a leaf, and about 8 more. [http://www.infoworld.com/article/3394399/machine-learning-algorithms-explained.html Machine learning algorithms explained | Martin Heller - InfoWorld] | ||
| + | |||
| + | http://nanonets.com/blog/content/images/2019/03/HPO1.png | ||
| + | |||
| + | ==== Hyperparameter tuning ==== | ||
| + | Hyperparameters are the variables that govern the training process. Your model parameters are optimized (you could say "tuned") by the training process: you run data through the operations of the model, compare the resulting prediction with the actual value for each data instance, evaluate the accuracy, and adjust until you find the best combination to handle the problem. | ||
| + | |||
| + | These algorithms automatically adjust (learn) their internal parameters based on data. However, there is a subset of parameters that is not learned and that have to be configured by an expert. Such parameters are often referred to as “hyperparameters” — and they have a big impact ...For example, the tree depth in a decision tree model and the number of layers in an artificial neural network are typical hyperparameters. The performance of a model can drastically depend on the choice of its hyperparameters. [http://thenextweb.com/podium/2019/11/11/machine-learning-algorithms-and-the-art-of-hyperparameter-selection/ Machine learning algorithms and the art of hyperparameter selection - A review of four optimization strategies | Mischa Lisovyi and Rosaria Silipo - TNW] | ||
| + | |||
| + | There are four commonly used optimization strategies for hyperparameters: | ||
| + | # Bayesian optimization | ||
| + | # Grid search | ||
| + | # Random search | ||
| + | # Hill climbing | ||
| + | |||
| + | Bayesian optimization tends to be the most efficient. You would think that tuning as many hyperparameters as possible would give you the best answer. However, unless you are running on your own personal hardware, that could be very expensive. There are diminishing returns, in any case. With experience, you’ll discover which hyperparameters matter the most for your data and choice of algorithms. [http://www.infoworld.com/article/3394399/machine-learning-algorithms-explained.html Machine learning algorithms explained | Martin Heller - InfoWorld] | ||
| + | |||
| + | Hyperparameter Optimization libraries: | ||
| + | * [https://github.com/maxim5/hyper-engine hyper-engine - Gaussian Process Bayesian optimization and some other techniques, like learning curve prediction] | ||
| + | * [http://ray.readthedocs.io/en/latest/tune.html Ray Tune: Hyperparameter Optimization Framework] | ||
| + | * [http://sigopt.com/ SigOpt’s API tunes your model’s parameters through state-of-the-art Bayesian optimization] | ||
| + | * [http://github.com/hyperopt/hyperopt hyperopt; Distributed Asynchronous Hyperparameter Optimization in Python - random search and tree of parzen estimators optimization.] | ||
| + | * [http://scikit-optimize.github.io/#skopt.Optimizer Scikit-Optimize, or skopt - Gaussian process Bayesian optimization] | ||
| + | * [http://github.com/polyaxon/polyaxon polyaxon] | ||
| + | * [http://github.com/SheffieldML/GPyOpt GPyOpt; Gaussian Process Optimization] | ||
| + | |||
| + | Tuning: | ||
| + | * Optimizer type | ||
| + | * Learning rate (fixed or not) | ||
| + | * Epochs | ||
| + | * Regularization rate (or not) | ||
| + | * Type of Regularization - L1, L2, ElasticNet | ||
| + | * Search type for local minima | ||
| + | ** Gradient descent | ||
| + | ** Simulated | ||
| + | ** Annealing | ||
| + | ** Evolutionary | ||
| + | * Decay rate (or not) | ||
| + | * Momentum (fixed or not) | ||
| + | * Nesterov Accelerated Gradient momentum (or not) | ||
| + | * Batch size | ||
| + | * Fitness measurement type | ||
| + | ** MSE, accuracy, MAE, [[Cross-Entropy Loss]] | ||
| + | ** Precision, recall | ||
| + | |||
| + | * Stop criteria | ||
| + | |||
| + | <youtube>oaxf3rk0KGM</youtube> | ||
| + | <youtube>wKkcBPp3F1Y</youtube> | ||
| + | <youtube>giBAxWeuysM</youtube> | ||
| + | <youtube>WYLoNEcVeZo</youtube> | ||
| + | <youtube>ttE0F7fghfk</youtube> | ||
| + | |||
| + | === Automatic Hyperparameter Tuning === | ||
| + | * [[Automated Machine Learning (AML) - AutoML]] | ||
| + | |||
| + | Several production machine-learning platforms now offer automatic hyperparameter tuning. Essentially, you tell the system what hyperparameters you want to vary, and possibly what metric you want to optimize, and the system sweeps those hyperparameters across as many runs as you allow. ([[Google Cloud]] hyperparameter tuning extracts the appropriate metric from the TensorFlow model, so you don’t have to specify it.) | ||
| + | |||
| + | <youtube>ynYnZywayC4</youtube> | ||
| + | <youtube>mSvw0TfxqDo</youtube> | ||
Revision as of 15:15, 27 September 2020
YouTube search... Quora search... ...Google search
- AI Governance / Algorithm Administration
- Visualization
- Graphical Tools for Modeling AI Components
- Hyperparameters
- Evaluation
- Train, Validate, and Test
- Tools:
- TensorBoard
- Comet ML ...self-hosted and cloud-based meta machine learning platform allowing data scientists and teams to track, compare, explain and optimize experiments and models
- MLflow | Databrinks ...manage the ML lifecycle, including experimentation, reproducibility and deployment
- Domino Model Monitor (DMM) | Domino ...monitor the performance of all models across your entire organization
- alteryx: Feature Labs, Featuretools
- Weights and Biases ...experiment tracking, model optimization, and dataset versioning
- How can we improve Azure Data Catalog?
- SigOpt ...optimization platform and API designed to unlock the potential of modeling pipelines. This fully agnostic software solution accelerates, amplifies, and scales the model development process
- Automate your data lineage
- Benefiting from AI: A different approach to data management is needed
- Git - GitHub and GitLab ...publishing your model
- Global Community for Artificial Intelligence (AI) in Master Data Management (MDM) | Camelot Management Consultants
Contents
Master Data Management (MDM)
Feature Store / Data Lineage / Data Catalog
|
|
|
|
|
|
|
|
Versioning
- DVC | DVC.org
- Pachyderm …Pachyderm for data scientists | Gerben Oostra - bigdata - Medium
- Dataiku
- Continuous Machine Learning (CML)
|
|
|
|
|
|
Hyperparameter
YouTube search... ...Google search
- Gradient Descent Optimization & Challenges
- Using TensorFlow Tuning
- Understanding Hyperparameters and its Optimisation techniques | Prabhu - Towards Data Science
- How To Make Deep Learning Models That Don’t Suck | Ajay Uppili Arasanipalai
In machine learning, a hyperparameter is a parameter whose value is set before the learning process begins. By contrast, the values of other parameters are derived via training. Different model training algorithms require different hyperparameters, some simple algorithms (such as ordinary least squares regression) require none. Given these hyperparameters, the training algorithm learns the parameters from the data. Hyperparameter (machine learning) | Wikipedia
Machine learning algorithms train on data to find the best set of weights for each independent variable that affects the predicted value or class. The algorithms themselves have variables, called hyperparameters. They’re called hyperparameters, as opposed to parameters, because they control the operation of the algorithm rather than the weights being determined. The most important hyperparameter is often the learning rate, which determines the step size used when finding the next set of weights to try when optimizing. If the learning rate is too high, the gradient descent may quickly converge on a plateau or suboptimal point. If the learning rate is too low, the gradient descent may stall and never completely converge. Many other common hyperparameters depend on the algorithms used. Most algorithms have stopping parameters, such as the maximum number of epochs, or the maximum time to run, or the minimum improvement from epoch to epoch. Specific algorithms have hyperparameters that control the shape of their search. For example, a Random Forest (or) Random Decision Forest Classifier has hyperparameters for minimum samples per leaf, max depth, minimum samples at a split, minimum weight fraction for a leaf, and about 8 more. Machine learning algorithms explained | Martin Heller - InfoWorld
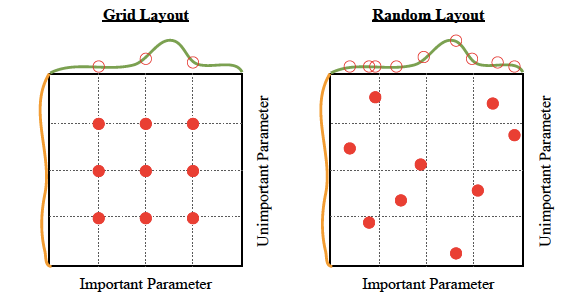
Hyperparameter tuning
Hyperparameters are the variables that govern the training process. Your model parameters are optimized (you could say "tuned") by the training process: you run data through the operations of the model, compare the resulting prediction with the actual value for each data instance, evaluate the accuracy, and adjust until you find the best combination to handle the problem.
These algorithms automatically adjust (learn) their internal parameters based on data. However, there is a subset of parameters that is not learned and that have to be configured by an expert. Such parameters are often referred to as “hyperparameters” — and they have a big impact ...For example, the tree depth in a decision tree model and the number of layers in an artificial neural network are typical hyperparameters. The performance of a model can drastically depend on the choice of its hyperparameters. Machine learning algorithms and the art of hyperparameter selection - A review of four optimization strategies | Mischa Lisovyi and Rosaria Silipo - TNW
There are four commonly used optimization strategies for hyperparameters:
- Bayesian optimization
- Grid search
- Random search
- Hill climbing
Bayesian optimization tends to be the most efficient. You would think that tuning as many hyperparameters as possible would give you the best answer. However, unless you are running on your own personal hardware, that could be very expensive. There are diminishing returns, in any case. With experience, you’ll discover which hyperparameters matter the most for your data and choice of algorithms. Machine learning algorithms explained | Martin Heller - InfoWorld
Hyperparameter Optimization libraries:
- hyper-engine - Gaussian Process Bayesian optimization and some other techniques, like learning curve prediction
- Ray Tune: Hyperparameter Optimization Framework
- SigOpt’s API tunes your model’s parameters through state-of-the-art Bayesian optimization
- hyperopt; Distributed Asynchronous Hyperparameter Optimization in Python - random search and tree of parzen estimators optimization.
- Scikit-Optimize, or skopt - Gaussian process Bayesian optimization
- polyaxon
- GPyOpt; Gaussian Process Optimization
Tuning:
- Optimizer type
- Learning rate (fixed or not)
- Epochs
- Regularization rate (or not)
- Type of Regularization - L1, L2, ElasticNet
- Search type for local minima
- Gradient descent
- Simulated
- Annealing
- Evolutionary
- Decay rate (or not)
- Momentum (fixed or not)
- Nesterov Accelerated Gradient momentum (or not)
- Batch size
- Fitness measurement type
- MSE, accuracy, MAE, Cross-Entropy Loss
- Precision, recall
- Stop criteria
Automatic Hyperparameter Tuning
Several production machine-learning platforms now offer automatic hyperparameter tuning. Essentially, you tell the system what hyperparameters you want to vary, and possibly what metric you want to optimize, and the system sweeps those hyperparameters across as many runs as you allow. (Google Cloud hyperparameter tuning extracts the appropriate metric from the TensorFlow model, so you don’t have to specify it.)