Difference between revisions of "Bidirectional Encoder Representations from Transformers (BERT)"
m |
m |
||
| (6 intermediate revisions by the same user not shown) | |||
| Line 19: | Line 19: | ||
* [[Large Language Model (LLM)]] ... [[Large Language Model (LLM)#Multimodal|Multimodal]] ... [[Foundation Models (FM)]] ... [[Generative Pre-trained Transformer (GPT)|Generative Pre-trained]] ... [[Transformer]] ... [[GPT-4]] ... [[GPT-5]] ... [[Attention]] ... [[Generative Adversarial Network (GAN)|GAN]] ... [[Bidirectional Encoder Representations from Transformers (BERT)|BERT]] | * [[Large Language Model (LLM)]] ... [[Large Language Model (LLM)#Multimodal|Multimodal]] ... [[Foundation Models (FM)]] ... [[Generative Pre-trained Transformer (GPT)|Generative Pre-trained]] ... [[Transformer]] ... [[GPT-4]] ... [[GPT-5]] ... [[Attention]] ... [[Generative Adversarial Network (GAN)|GAN]] ... [[Bidirectional Encoder Representations from Transformers (BERT)|BERT]] | ||
* [[Natural Language Processing (NLP)]] ... [[Natural Language Generation (NLG)|Generation (NLG)]] ... [[Natural Language Classification (NLC)|Classification (NLC)]] ... [[Natural Language Processing (NLP)#Natural Language Understanding (NLU)|Understanding (NLU)]] ... [[Language Translation|Translation]] ... [[Summarization]] ... [[Sentiment Analysis|Sentiment]] ... [[Natural Language Tools & Services|Tools]] | * [[Natural Language Processing (NLP)]] ... [[Natural Language Generation (NLG)|Generation (NLG)]] ... [[Natural Language Classification (NLC)|Classification (NLC)]] ... [[Natural Language Processing (NLP)#Natural Language Understanding (NLU)|Understanding (NLU)]] ... [[Language Translation|Translation]] ... [[Summarization]] ... [[Sentiment Analysis|Sentiment]] ... [[Natural Language Tools & Services|Tools]] | ||
| − | * [[Assistants]] ... [[Personal Companions]] ... [[ | + | * [[Agents]] ... [[Robotic Process Automation (RPA)|Robotic Process Automation]] ... [[Assistants]] ... [[Personal Companions]] ... [[Personal Productivity|Productivity]] ... [[Email]] ... [[Negotiation]] ... [[LangChain]] |
* [[SMART - Multi-Task Deep Neural Networks (MT-DNN)]] | * [[SMART - Multi-Task Deep Neural Networks (MT-DNN)]] | ||
* [[Deep Distributed Q Network Partial Observability]] | * [[Deep Distributed Q Network Partial Observability]] | ||
| Line 33: | Line 33: | ||
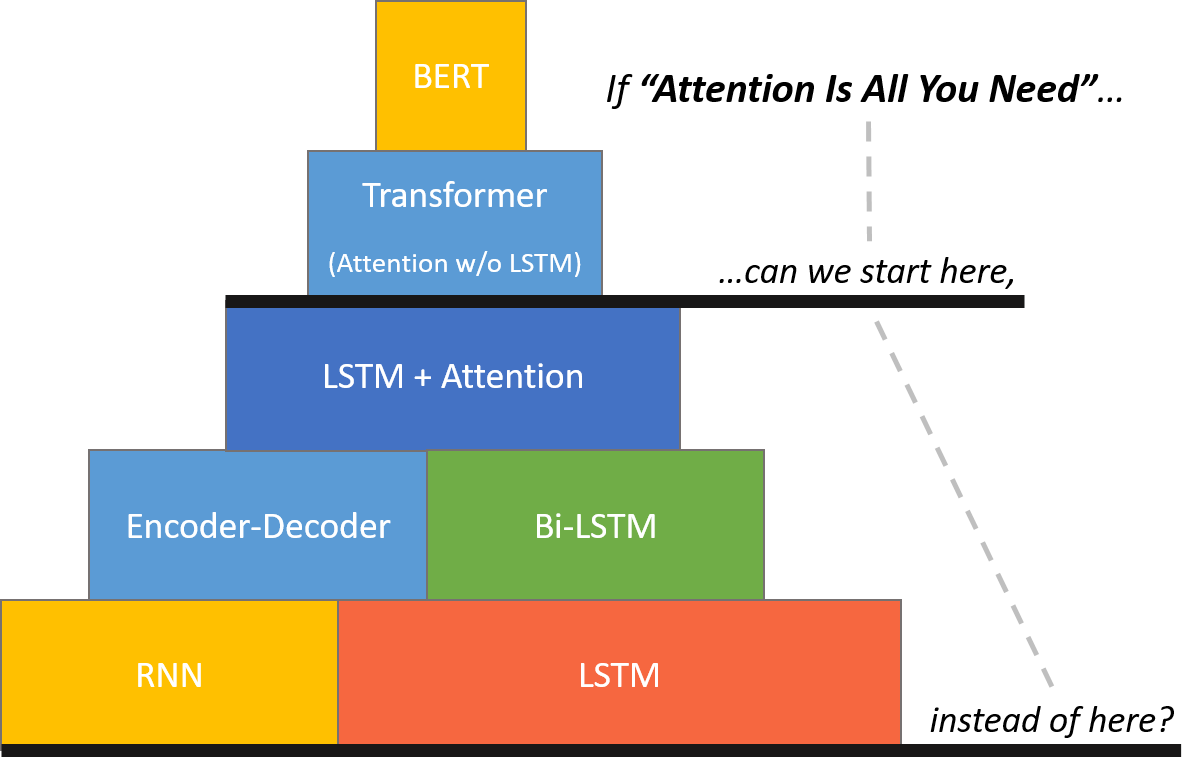
* [[Attention]] Mechanism/[[Transformer]] Model | * [[Attention]] Mechanism/[[Transformer]] Model | ||
** [[Generative Pre-trained Transformer (GPT)]]2/3 | ** [[Generative Pre-trained Transformer (GPT)]]2/3 | ||
| − | * | + | * [[Conversational AI]] ... [[ChatGPT]] | [[OpenAI]] ... [[Bing/Copilot]] | [[Microsoft]] ... [[Gemini]] | [[Google]] ... [[Claude]] | [[Anthropic]] ... [[Perplexity]] ... [[You]] ... [[phind]] ... [[Ernie]] | [[Baidu]] |
** [https://www.technologyreview.com/2023/02/08/1068068/chatgpt-is-everywhere-heres-where-it-came-from/ ChatGPT is everywhere. Here’s where it came from | Will Douglas Heaven - MIT Technology Review] | ** [https://www.technologyreview.com/2023/02/08/1068068/chatgpt-is-everywhere-heres-where-it-came-from/ ChatGPT is everywhere. Here’s where it came from | Will Douglas Heaven - MIT Technology Review] | ||
* [[Transformer-XL]] | * [[Transformer-XL]] | ||
| Line 44: | Line 44: | ||
* [https://www.topbots.com/leading-nlp-language-models-2020/ 7 Leading Language Models for NLP in 2020 | Mariya Yao - TOPBOTS] | * [https://www.topbots.com/leading-nlp-language-models-2020/ 7 Leading Language Models for NLP in 2020 | Mariya Yao - TOPBOTS] | ||
* [https://www.topbots.com/bert-inner-workings/ BERT Inner Workings | George Mihaila - TOPBOTS] | * [https://www.topbots.com/bert-inner-workings/ BERT Inner Workings | George Mihaila - TOPBOTS] | ||
| − | * [https://www.marktechpost.com/2023/08/07/top-bert-applications-you-should-know-about/ Top BERT Applications You Should Know About | Tanya Malhotra - MarkTechPost] ... [[PaLM- | + | * [https://www.marktechpost.com/2023/08/07/top-bert-applications-you-should-know-about/ Top BERT Applications You Should Know About | Tanya Malhotra - MarkTechPost] ... [[PaLM]] |
| + | * [https://huggingface.co/blog/bert-101 BERT 101 | Hugging Face] | ||
| + | |||
| + | |||
| + | How BERT works using a fun [https://www.madlibs.com/ MadLibs] example. BERT is like a super smart language model that understands words and sentences really well. Imagine you're playing [https://www.madlibs.com/ MadLibs], and you have a sentence with a missing word. Let's say the sentence is: | ||
| + | |||
| + | <hr><center><b><i> | ||
| + | |||
| + | I went to the _______ to buy some delicious ice cream. | ||
| + | |||
| + | </i></b></center><hr> | ||
| + | |||
| + | You need to fill in the blank with the right word to make the sentence make sense. BERT does something similar, but with much more complex sentences. Here's how it works: | ||
| + | |||
| + | * <b>Tokenization</b>: BERT first breaks down the sentence into smaller pieces, called [[Large Language Model (LLM)#token|token]]s. In our [https://www.madlibs.com/ MadLibs] example, each word is a [[Large Language Model (LLM)#token|token]]. So, "I," "went," "to," "the," "_______," "to," "buy," "some," "delicious," "ice," and "cream" are all [[Large Language Model (LLM)#token|token]]s. | ||
| + | |||
| + | * <b>Word Representation</b>: BERT gives each [[Large Language Model (LLM)#token|token]] a special code to represent it. Just like in [https://www.madlibs.com/ MadLibs], you might have a list of possible words that could fit in the blank, and each word has a number next to it. BERT does something similar by giving each [[Large Language Model (LLM)#token|token]] a unique code that helps it understand what the word means. | ||
| + | |||
| + | * <b>Context Matters</b>: BERT doesn't just look at one [[Large Language Model (LLM)#token|token]] at a time; it pays attention to all the [[Large Language Model (LLM)#token|token]]s in the sentence. This is like looking at the whole [https://www.madlibs.com/ MadLibs] sentence to figure out what word fits best in the blank. BERT considers the words that come before and after the blank to understand the [[context]]. | ||
| + | |||
| + | * <b>Prediction</b>: Now, the magic happens. BERT tries to predict what the missing word is by looking at the surrounding words and their codes. It's like guessing the right word for the [https://www.madlibs.com/ MadLibs] sentence based on the words you've already filled in. | ||
| + | |||
| + | * <b>Learning from Data</b>: BERT got really good at this by studying lots and lots of sentences from the internet. It learned to understand language by seeing how words are used in different [[context]]s. So, it's like you getting better at [https://www.madlibs.com/ MadLibs] by playing it over and over. | ||
| + | |||
| + | * <b>Results</b>: BERT gives a list of possible words for the blank, along with how confident it is about each one. It can even give more than one option, just like you might have a few choices in [https://www.madlibs.com/ MadLibs]. | ||
| Line 55: | Line 79: | ||
<youtube>Y9Uvje7NQI4</youtube> | <youtube>Y9Uvje7NQI4</youtube> | ||
<youtube>-9evrZnBorM</youtube> | <youtube>-9evrZnBorM</youtube> | ||
| + | <youtube>-249nmQfv1U</youtube> | ||
<youtube>BhlOGGzC0Q0</youtube> | <youtube>BhlOGGzC0Q0</youtube> | ||
<youtube>BaPM47hO8p8</youtube> | <youtube>BaPM47hO8p8</youtube> | ||
Latest revision as of 08:14, 23 March 2024
Youtube search... ...Google search
- Large Language Model (LLM) ... Multimodal ... Foundation Models (FM) ... Generative Pre-trained ... Transformer ... GPT-4 ... GPT-5 ... Attention ... GAN ... BERT
- Natural Language Processing (NLP) ... Generation (NLG) ... Classification (NLC) ... Understanding (NLU) ... Translation ... Summarization ... Sentiment ... Tools
- Agents ... Robotic Process Automation ... Assistants ... Personal Companions ... Productivity ... Email ... Negotiation ... LangChain
- SMART - Multi-Task Deep Neural Networks (MT-DNN)
- Deep Distributed Q Network Partial Observability
- TaBERT
- Google is improving 10 percent of searches by understanding language context - Say hello to BERT | Dieter Bohn - The Verge ...the old Google search algorithm treated that sentence as a “Bag-of-Words (BoW)”
- Google AI’s ALBERT claims top spot in multiple NLP performance benchmarks | Khari Johnson - VentureBeat
- RoBERTa:
- RoBERTa: A Robustly Optimized BERT Pretraining Approach | Y. Li, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov
- RoBERTa: A Robustly Optimized BERT Pretraining Approach | GitHub - iterates on BERT's pretraining procedure, including training the model longer, with bigger batches over more data; removing the next sentence prediction objective; training on longer sequences; and dynamically changing the masking pattern applied to the training data.
- Facebook AI’s RoBERTa improves Google’s BERT pretraining methods | Khari Johnson - VentureBeat
- Google's BERT - built on ideas from ULMFiT, ELMo, and OpenAI
- Attention Mechanism/Transformer Model
- Conversational AI ... ChatGPT | OpenAI ... Bing/Copilot | Microsoft ... Gemini | Google ... Claude | Anthropic ... Perplexity ... You ... phind ... Ernie | Baidu
- Transformer-XL
- Microsoft makes Google’s BERT NLP model better | Khari Johnson - VentureBeat
- Watch me Build a Finance Startup | Siraj Raval
- Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT | Victor Sanh - Medium
- TinyBERT: Distilling BERT for Natural Language Understanding | X. Jiao, Y. Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, and Q. Liu researchers at Huawei produces a model called TinyBERT that is 7.5 times smaller and nearly 10 times faster than the original. It also reaches nearly the same language understanding performance as the original.
- Understanding BERT: Is it a Game Changer in NLP? | Bharat S Raj - Towards Data Science
- Allen Institute for Artificial Intelligence, or AI2’s Aristo AI system finally passes an eighth-grade science test | Alan Boyle - GeekWire
- 7 Leading Language Models for NLP in 2020 | Mariya Yao - TOPBOTS
- BERT Inner Workings | George Mihaila - TOPBOTS
- Top BERT Applications You Should Know About | Tanya Malhotra - MarkTechPost ... PaLM
- BERT 101 | Hugging Face
How BERT works using a fun MadLibs example. BERT is like a super smart language model that understands words and sentences really well. Imagine you're playing MadLibs, and you have a sentence with a missing word. Let's say the sentence is:
I went to the _______ to buy some delicious ice cream.
You need to fill in the blank with the right word to make the sentence make sense. BERT does something similar, but with much more complex sentences. Here's how it works:
- Tokenization: BERT first breaks down the sentence into smaller pieces, called tokens. In our MadLibs example, each word is a token. So, "I," "went," "to," "the," "_______," "to," "buy," "some," "delicious," "ice," and "cream" are all tokens.
- Word Representation: BERT gives each token a special code to represent it. Just like in MadLibs, you might have a list of possible words that could fit in the blank, and each word has a number next to it. BERT does something similar by giving each token a unique code that helps it understand what the word means.
- Context Matters: BERT doesn't just look at one token at a time; it pays attention to all the tokens in the sentence. This is like looking at the whole MadLibs sentence to figure out what word fits best in the blank. BERT considers the words that come before and after the blank to understand the context.
- Prediction: Now, the magic happens. BERT tries to predict what the missing word is by looking at the surrounding words and their codes. It's like guessing the right word for the MadLibs sentence based on the words you've already filled in.
- Learning from Data: BERT got really good at this by studying lots and lots of sentences from the internet. It learned to understand language by seeing how words are used in different contexts. So, it's like you getting better at MadLibs by playing it over and over.
- Results: BERT gives a list of possible words for the blank, along with how confident it is about each one. It can even give more than one option, just like you might have a few choices in MadLibs.

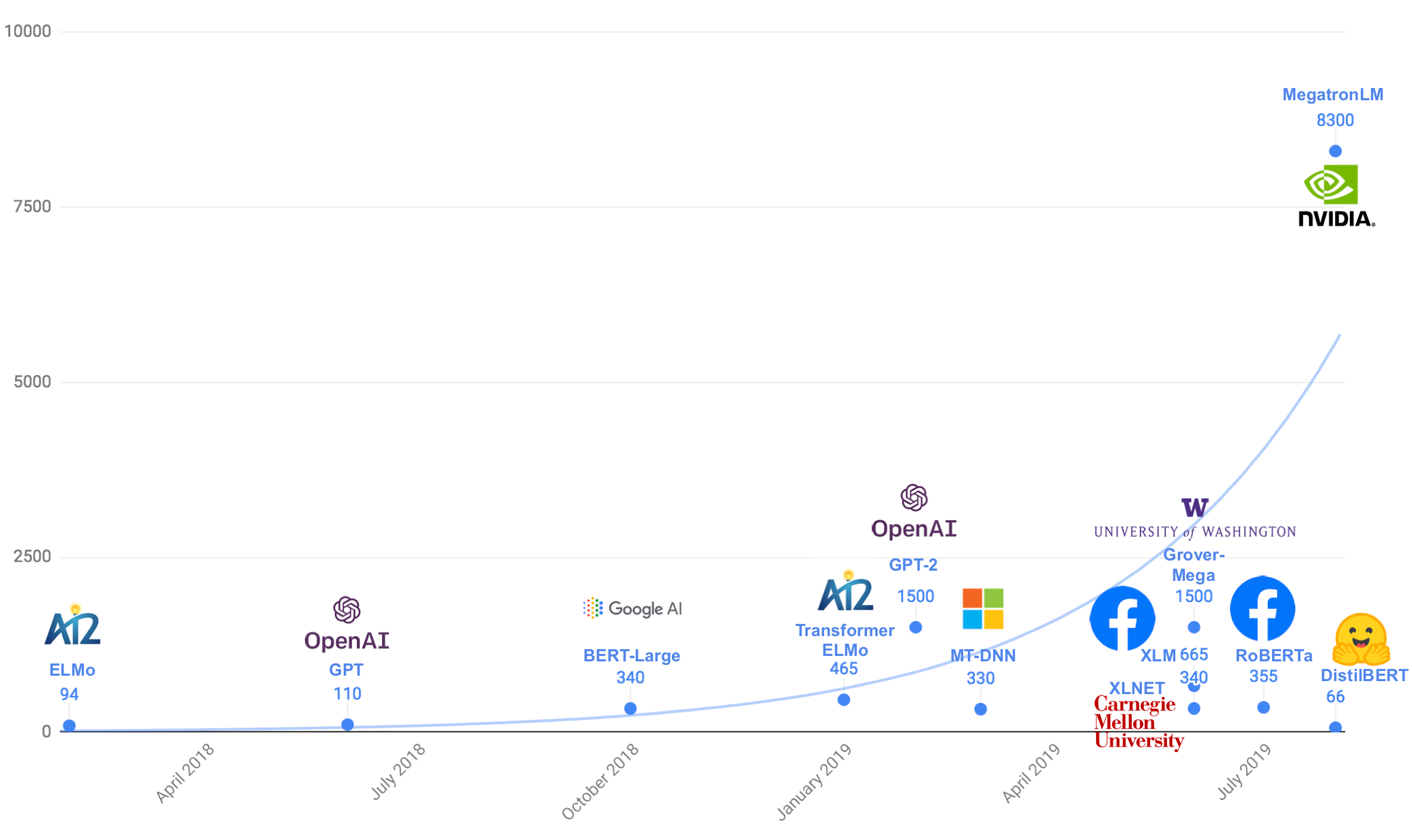
BERT Research | Chris McCormick
- BERT Research | Chris McCormick
- ChrisMcCormickAI online education