Difference between revisions of "Algorithm Administration"
m |
m |
||
| Line 48: | Line 48: | ||
* [http://medium.com/georgian-impact-blog/automatic-machine-learning-aml-landscape-survey-f75c3ae3bbf2 Automatic Machine Learning (AutoML) Landscape Survey | Alexander Allen & Adithya Balaji - Georgian Partners]... | * [http://medium.com/georgian-impact-blog/automatic-machine-learning-aml-landscape-survey-f75c3ae3bbf2 Automatic Machine Learning (AutoML) Landscape Survey | Alexander Allen & Adithya Balaji - Georgian Partners]... | ||
| + | |||
| + | |||
| + | |||
| + | |||
| + | * [http://getmanta.com/?gclid=CjwKCAjwsfreBRB9EiwAikSUHSSOxld0nZNyLNXmiPM43x7jEAgeTxkXRH_s5XPJlfTekPdO8N1Y1xoCKwwQAvD_BwE Automate your data lineage] | ||
| + | * [http://www.information-age.com/benefiting-ai-data-management-123471564/ Benefiting from AI: A different approach to data management is needed] | ||
| + | * [[Git - GitHub and GitLab]] ...[[Publishing#Model Publishing|publishing your model]] | ||
| + | * [http://github.com/JonTupitza/Data-Science-Process/blob/master/10-Modeling-Pipeline.ipynb Use a Pipeline to Chain PCA with a RandomForest Classifier Jupyter Notebook |] [http://github.com/jontupitza Jon Tupitza] | ||
| + | * [http://devblogs.microsoft.com/cesardelatorre/ml-net-model-lifecycle-with-azure-devops-ci-cd-pipelines/ ML.NET Model Lifecycle with Azure DevOps CI/CD pipelines | Cesar de la Torre - Microsoft] | ||
| + | * [http://medium.com/data-ops/a-great-model-is-not-enough-deploying-ai-without-technical-debt-70e3d5fecfd3 A Great Model is Not Enough: Deploying AI Without Technical Debt | DataKitchen - Medium] | ||
| + | * [http://towardsdatascience.com/ml-infrastructure-tools-for-production-part-2-model-deployment-and-serving-fcfc75c4a362ML Infrastructure Tools for Production | Aparna Dhinakaran - Towards Data Science] ...Model Deployment and Serving | ||
| + | * [http://www.camelot-mc.com/en/client-services/information-data-management/global-community-for-artificial-intelligence-in-mdm/ Global Community for Artificial Intelligence (AI) in Master Data Management (MDM) | Camelot Management Consultants] | ||
| + | |||
| + | = Tools = | ||
** [[Google AutoML]] automatically build and deploy state-of-the-art machine learning models | ** [[Google AutoML]] automatically build and deploy state-of-the-art machine learning models | ||
** [[SageMaker]] | [[Amazon]] | ** [[SageMaker]] | [[Amazon]] | ||
** [http://docs.microsoft.com/en-us/azure/machine-learning/concept-model-management-and-deployment MLOps] | [[Microsoft]] ...model management, deployment, and monitoring with Azure | ** [http://docs.microsoft.com/en-us/azure/machine-learning/concept-model-management-and-deployment MLOps] | [[Microsoft]] ...model management, deployment, and monitoring with Azure | ||
| + | *** [http://feedback.azure.com/forums/906052-data-catalog How can we improve Azure Data Catalog?] | ||
*** [http://docs.microsoft.com/en-us/azure/machine-learning/concept-automated-ml AutoML] | *** [http://docs.microsoft.com/en-us/azure/machine-learning/concept-automated-ml AutoML] | ||
** [[Ludwig]] - a [[Python]] toolbox from Uber that allows to train and test deep learning models | ** [[Ludwig]] - a [[Python]] toolbox from Uber that allows to train and test deep learning models | ||
| Line 70: | Line 85: | ||
** [[MLflow]] | [http://databricks.com/product/managed-mlflow Databrinks] ...manage the ML lifecycle, including experimentation, reproducibility and deployment | ** [[MLflow]] | [http://databricks.com/product/managed-mlflow Databrinks] ...manage the ML lifecycle, including experimentation, reproducibility and deployment | ||
** [http://www.dominodatalab.com/product/domino-model-monitor/ Domino Model Monitor (DMM) | Domino] ...monitor the performance of all models across your entire organization | ** [http://www.dominodatalab.com/product/domino-model-monitor/ Domino Model Monitor (DMM) | Domino] ...monitor the performance of all models across your entire organization | ||
| − | |||
** [http://www.wandb.com/ Weights and Biases] ...experiment tracking, model optimization, and dataset versioning | ** [http://www.wandb.com/ Weights and Biases] ...experiment tracking, model optimization, and dataset versioning | ||
| − | |||
** [http://sigopt.com/ SigOpt] ...optimization platform and API designed to unlock the potential of modeling pipelines. This fully agnostic software solution accelerates, amplifies, and scales the model development process | ** [http://sigopt.com/ SigOpt] ...optimization platform and API designed to unlock the potential of modeling pipelines. This fully agnostic software solution accelerates, amplifies, and scales the model development process | ||
** [http://dvc.org/ DVC] ...Open-source Version Control System for Machine Learning Projects | ** [http://dvc.org/ DVC] ...Open-source Version Control System for Machine Learning Projects | ||
| Line 82: | Line 95: | ||
** [http://www.datarobot.com/platform/mlops/ Machine Learning Operations (MLOps) | DataRobot] ...build highly accurate predictive models with full transparency | ** [http://www.datarobot.com/platform/mlops/ Machine Learning Operations (MLOps) | DataRobot] ...build highly accurate predictive models with full transparency | ||
** [http://metaflow.org/ Metaflow], Netflix and AWS open source [[Python]] library | ** [http://metaflow.org/ Metaflow], Netflix and AWS open source [[Python]] library | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
= Master Data Management (MDM) = | = Master Data Management (MDM) = | ||
Revision as of 19:15, 27 September 2020
YouTube search... Quora search... ...Google search
- AI Governance / Algorithm Administration
- Visualization
- Graphical Tools for Modeling AI Components
- Hyperparameters
- Evaluation
- Train, Validate, and Test
- NLP Workbench / Pipeline
- Development
- Building Your Environment
- Service Capabilities
- AI Marketplace & Toolkit/Model Interoperability
- Directed Acyclic Graph (DAG) - programming pipelines
- Containers; Docker, Kubernetes & Microservices
- Platforms: Machine Learning as a Service (MLaaS)
- Automate your data lineage
- Benefiting from AI: A different approach to data management is needed
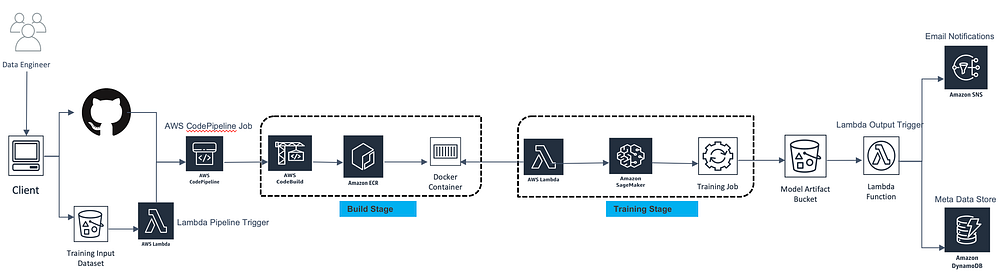
- Git - GitHub and GitLab ...publishing your model
- Use a Pipeline to Chain PCA with a RandomForest Classifier Jupyter Notebook | Jon Tupitza
- ML.NET Model Lifecycle with Azure DevOps CI/CD pipelines | Cesar de la Torre - Microsoft
- A Great Model is Not Enough: Deploying AI Without Technical Debt | DataKitchen - Medium
- Infrastructure Tools for Production | Aparna Dhinakaran - Towards Data Science ...Model Deployment and Serving
- Global Community for Artificial Intelligence (AI) in Master Data Management (MDM) | Camelot Management Consultants
Contents
Tools
- Google AutoML automatically build and deploy state-of-the-art machine learning models
- SageMaker | Amazon
- MLOps | Microsoft ...model management, deployment, and monitoring with Azure
- Ludwig - a Python toolbox from Uber that allows to train and test deep learning models
- TPOT a Python library that automatically creates and optimizes full machine learning pipelines using genetic programming. Not for NLP, strings need to be coded to numerics.
- H2O Driverless AI for automated Visualization, feature engineering, model training, hyperparameter optimization, and explainability.
- alteryx: Feature Labs, Featuretools
- MLBox Fast reading and distributed data preprocessing/cleaning/formatting. Highly robust feature selection and leak detection. Accurate hyper-parameter optimization in high-dimensional space. State-of-the art predictive models for classification and regression (Deep Learning, Stacking, LightGBM,…). Prediction with models interpretation. Primarily Linux.
- auto-sklearn algorithm selection and hyperparameter tuning. It leverages recent advantages in Bayesian optimization, meta-learning and ensemble construction.is a Bayesian hyperparameter optimization layer on top of scikit-learn. Not for large datasets.
- Auto Keras is an open-source Python package for neural architecture search.
- ATM -auto tune models - a multi-tenant, multi-data system for automated machine learning (model selection and tuning). ATM is an open source software library under the Human Data Interaction project (HDI) at MIT.
- Auto-WEKA is a Bayesian hyperparameter optimization layer on top of Weka. Weka is a collection of machine learning algorithms for data mining tasks. The algorithms can either be applied directly to a dataset or called from your own Java code. Weka contains tools for data pre-processing, classification, regression, clustering, association rules, and visualization.
- TransmogrifAI - an AutoML library for building modular, reusable, strongly typed machine learning workflows. A Scala/SparkML library created by Salesforce for automated data cleansing, feature engineering, model selection, and hyperparameter optimization
- RECIPE - a framework based on grammar-based genetic programming that builds customized scikit-learn classification pipelines.
- AutoMLC Automated Multi-Label Classification. GA-Auto-MLC and Auto-MEKAGGP are freely-available methods that perform automated multi-label classification on the MEKA software.
- Databricks MLflow an open source framework to manage the complete Machine Learning lifecycle using Managed MLflow as an integrated service with the Databricks Unified Analytics Platform.
- SAS Viya automates the process of data cleansing, data transformations, feature engineering, algorithm matching, model training and ongoing governance.
- TensorBoard
- Comet ML ...self-hosted and cloud-based meta machine learning platform allowing data scientists and teams to track, compare, explain and optimize experiments and models
- MLflow | Databrinks ...manage the ML lifecycle, including experimentation, reproducibility and deployment
- Domino Model Monitor (DMM) | Domino ...monitor the performance of all models across your entire organization
- Weights and Biases ...experiment tracking, model optimization, and dataset versioning
- SigOpt ...optimization platform and API designed to unlock the potential of modeling pipelines. This fully agnostic software solution accelerates, amplifies, and scales the model development process
- DVC ...Open-source Version Control System for Machine Learning Projects
- ModelOp Center | ModelOp
- Google Kubeflow Pipelines - a platform for building and deploying portable, scalable machine learning (ML) workflows based on Docker containers. Introducing AI Hub and Kubeflow Pipelines: Making AI simpler, faster, and more useful for businesses
- Moogsoft and Red Hat Ansible Tower
- DSS | Dataiku
- Model Manager | SAS
- Machine Learning Operations (MLOps) | DataRobot ...build highly accurate predictive models with full transparency
- Metaflow, Netflix and AWS open source Python library
Master Data Management (MDM)
Feature Store / Data Lineage / Data Catalog
|
|
|
|
|
|
|
|
Versioning
- DVC | DVC.org
- Pachyderm …Pachyderm for data scientists | Gerben Oostra - bigdata - Medium
- Dataiku
- Continuous Machine Learning (CML)
|
|
|
|
|
|
Model Versioning - ModelDB
- ModelDB: An open-source system for Machine Learning model versioning, metadata, and experiment management
Hyperparameter
YouTube search... ...Google search
- Gradient Descent Optimization & Challenges
- Using TensorFlow Tuning
- Understanding Hyperparameters and its Optimisation techniques | Prabhu - Towards Data Science
- How To Make Deep Learning Models That Don’t Suck | Ajay Uppili Arasanipalai
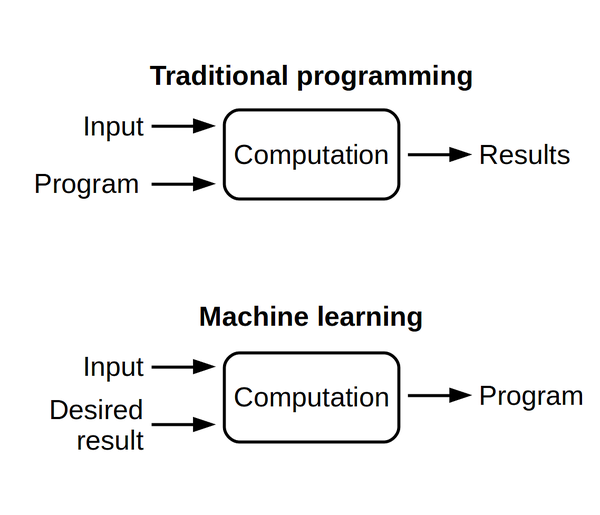
In machine learning, a hyperparameter is a parameter whose value is set before the learning process begins. By contrast, the values of other parameters are derived via training. Different model training algorithms require different hyperparameters, some simple algorithms (such as ordinary least squares regression) require none. Given these hyperparameters, the training algorithm learns the parameters from the data. Hyperparameter (machine learning) | Wikipedia
Machine learning algorithms train on data to find the best set of weights for each independent variable that affects the predicted value or class. The algorithms themselves have variables, called hyperparameters. They’re called hyperparameters, as opposed to parameters, because they control the operation of the algorithm rather than the weights being determined. The most important hyperparameter is often the learning rate, which determines the step size used when finding the next set of weights to try when optimizing. If the learning rate is too high, the gradient descent may quickly converge on a plateau or suboptimal point. If the learning rate is too low, the gradient descent may stall and never completely converge. Many other common hyperparameters depend on the algorithms used. Most algorithms have stopping parameters, such as the maximum number of epochs, or the maximum time to run, or the minimum improvement from epoch to epoch. Specific algorithms have hyperparameters that control the shape of their search. For example, a Random Forest (or) Random Decision Forest Classifier has hyperparameters for minimum samples per leaf, max depth, minimum samples at a split, minimum weight fraction for a leaf, and about 8 more. Machine learning algorithms explained | Martin Heller - InfoWorld
Hyperparameter Tuning
Hyperparameters are the variables that govern the training process. Your model parameters are optimized (you could say "tuned") by the training process: you run data through the operations of the model, compare the resulting prediction with the actual value for each data instance, evaluate the accuracy, and adjust until you find the best combination to handle the problem.
These algorithms automatically adjust (learn) their internal parameters based on data. However, there is a subset of parameters that is not learned and that have to be configured by an expert. Such parameters are often referred to as “hyperparameters” — and they have a big impact ...For example, the tree depth in a decision tree model and the number of layers in an artificial neural network are typical hyperparameters. The performance of a model can drastically depend on the choice of its hyperparameters. Machine learning algorithms and the art of hyperparameter selection - A review of four optimization strategies | Mischa Lisovyi and Rosaria Silipo - TNW
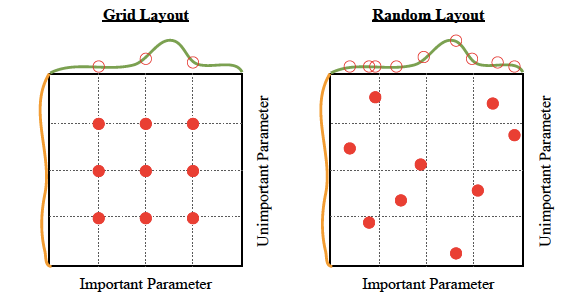
There are four commonly used optimization strategies for hyperparameters:
- Bayesian optimization
- Grid search
- Random search
- Hill climbing
Bayesian optimization tends to be the most efficient. You would think that tuning as many hyperparameters as possible would give you the best answer. However, unless you are running on your own personal hardware, that could be very expensive. There are diminishing returns, in any case. With experience, you’ll discover which hyperparameters matter the most for your data and choice of algorithms. Machine learning algorithms explained | Martin Heller - InfoWorld
Hyperparameter Optimization libraries:
- hyper-engine - Gaussian Process Bayesian optimization and some other techniques, like learning curve prediction
- Ray Tune: Hyperparameter Optimization Framework
- SigOpt’s API tunes your model’s parameters through state-of-the-art Bayesian optimization
- hyperopt; Distributed Asynchronous Hyperparameter Optimization in Python - random search and tree of parzen estimators optimization.
- Scikit-Optimize, or skopt - Gaussian process Bayesian optimization
- polyaxon
- GPyOpt; Gaussian Process Optimization
Tuning:
- Optimizer type
- Learning rate (fixed or not)
- Epochs
- Regularization rate (or not)
- Type of Regularization - L1, L2, ElasticNet
- Search type for local minima
- Gradient descent
- Simulated
- Annealing
- Evolutionary
- Decay rate (or not)
- Momentum (fixed or not)
- Nesterov Accelerated Gradient momentum (or not)
- Batch size
- Fitness measurement type
- MSE, accuracy, MAE, Cross-Entropy Loss
- Precision, recall
- Stop criteria
Automatic Hyperparameter Tuning
Several production machine-learning platforms now offer automatic hyperparameter tuning. Essentially, you tell the system what hyperparameters you want to vary, and possibly what metric you want to optimize, and the system sweeps those hyperparameters across as many runs as you allow. (Google Cloud hyperparameter tuning extracts the appropriate metric from the TensorFlow model, so you don’t have to specify it.)
|
|
AIOps / MLOps
Youtube search... ...Google search
- A Silver Bullet For CIOs; Three ways AIOps can help IT leaders get strategic - Lisa Wolfe - Forbes
- MLOps: What You Need To Know | Tom Taulli - Forbes
- What is so Special About AIOps for Mission Critical Workloads? | Rebecca James - DevOps
- What is AIOps? Artificial Intelligence for IT Operations Explained | BMC
- AIOps: Artificial Intelligence for IT Operations, Modernize and transform IT Operations with solutions built on the only Data-to-Everything platform | splunk>
- How to Get Started With AIOps | Susan Moore - Gartner
- Why AI & ML Will Shake Software Testing up in 2019 | Oleksii Kharkovyna - Medium
- Continuous Delivery for Machine Learning D. Sato, A. Wider and C. Windheuser - MartinFowler
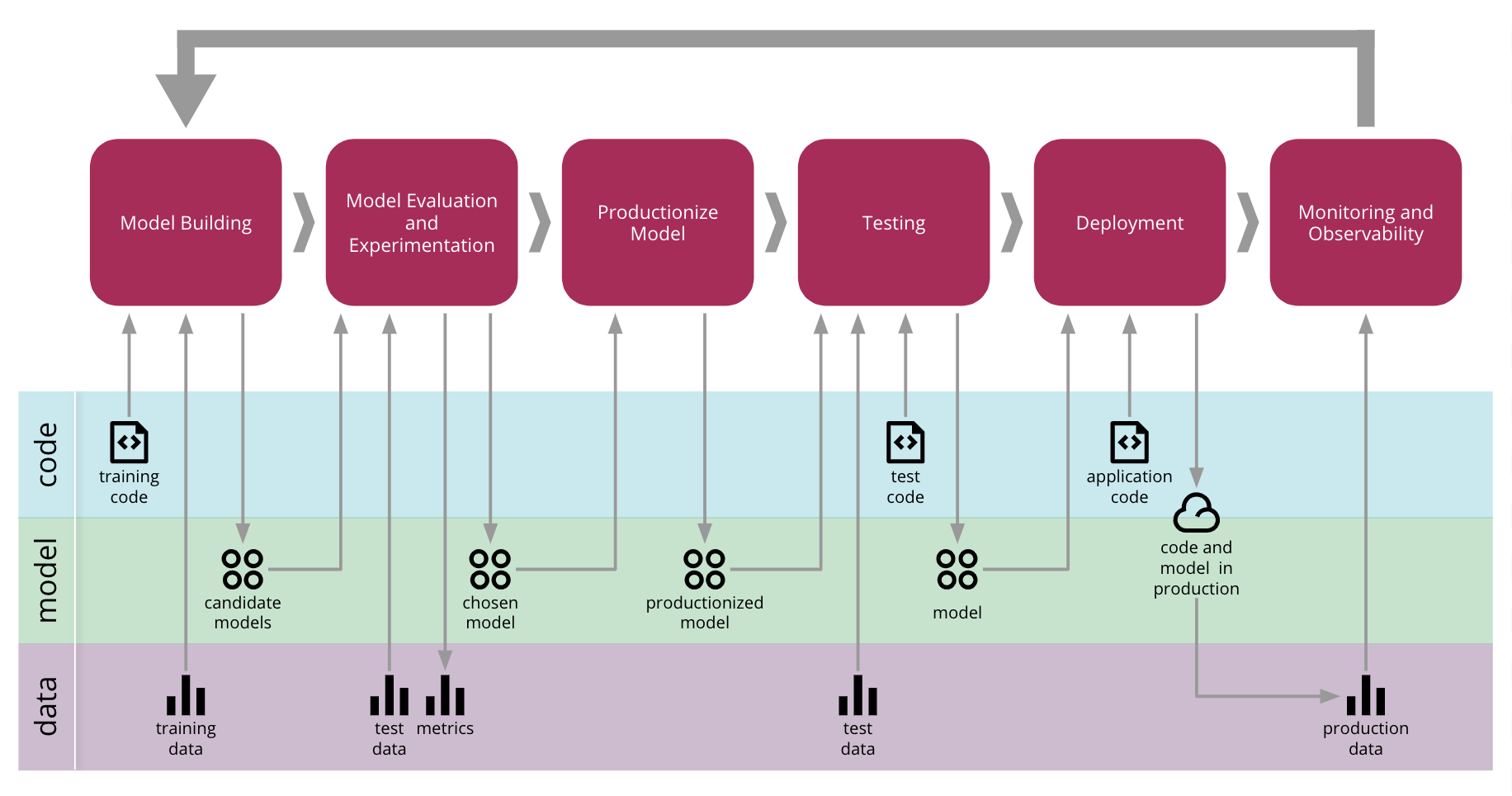
Machine learning capabilities give IT operations teams contextual, actionable insights to make better decisions on the job. More importantly, AIOps is an approach that transforms how systems are automated, detecting important signals from vast amounts of data and relieving the operator from the headaches of managing according to tired, outdated runbooks or policies. In the AIOps future, the environment is continually improving. The administrator can get out of the impossible business of refactoring rules and policies that are immediately outdated in today’s modern IT environment. Now that we have AI and machine learning technologies embedded into IT operations systems, the game changes drastically. AI and machine learning-enhanced automation will bridge the gap between DevOps and IT Ops teams: helping the latter solve issues faster and more accurately to keep pace with business goals and user needs. How AIOps Helps IT Operators on the Job | Ciaran Byrne - Toolbox
|
|
Continuous Machine Learning (CML)
- Continuous Machine Learning (CML) ...is Continuous Integration/Continuous Deployment (CI/CD) for Machine Learning Projects
- DVC | DVC.org
|
|
Model Monitoring
YouTube search... ...Google search
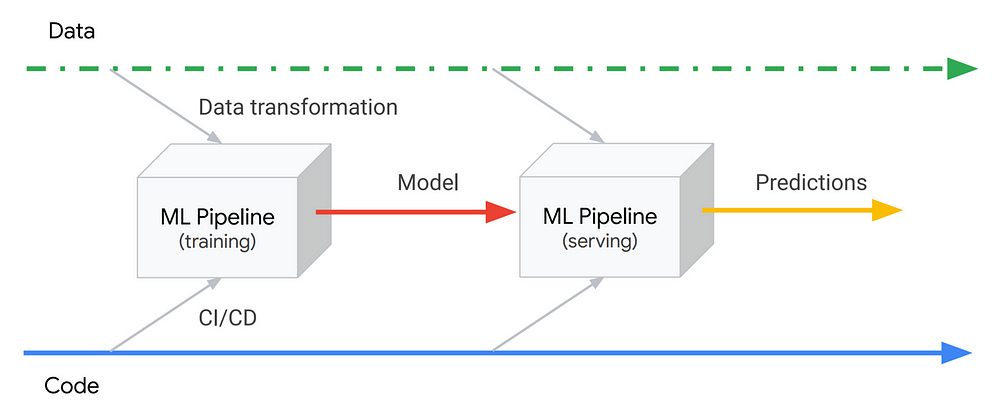
Monitoring production systems is essential to keeping them running well. For ML systems, monitoring becomes even more important, because their performance depends not just on factors that we have some control over, like infrastructure and our own software, but also on data, which we have much less control over. Therefore, in addition to monitoring standard metrics like latency, traffic, errors and saturation, we also need to monitor model prediction performance. An obvious challenge with monitoring model performance is that we usually don’t have a verified label to compare our model’s predictions to, since the model works on new data. In some cases we might have some indirect way of assessing the model’s effectiveness, for example by measuring click rate for a recommendation model. In other cases, we might have to rely on comparisons between time periods, for example by calculating a percentage of positive classifications hourly and alerting if it deviates by more than a few percent from the average for that time. Just like when validating the model, it’s also important to monitor metrics across slices, and not just globally, to be able to detect problems affecting specific segments. ML Ops: Machine Learning as an Engineering Discipline | Cristiano Breuel - Towards Data Science
|
|
|
|
Scoring Deployed Models
|
|