Claude
YouTube ... Quora ...Google search ...Google News ...Bing News
- Claude | Anthropic
- Getting started with Claude
- Generative AI ... Conversational AI ... OpenAI's ChatGPT ... Perplexity ... Microsoft's Bing ... You ...Google's Bard ... Baidu's Ernie
- Assistants ... Personal Companions ... Agents ... Negotiation ... LangChain
- Anthropic’s Claude AI can now digest an entire book like
- Meet Claude: Anthropic’s Rival to ChatGPT | Riley Goodside - Scale
- Anthropic introduces Claude, a “more steerable” AI competitor to ChatGPT | Benj Edwards - ARS Technica ... Anthropic aims for "safer" and "less harmful" AI, but at a higher price.
Claude is a next-generation AI assistant based on Anthropic’s research into training helpful, honest, and harmless AI systems. Claude is capable of a wide variety of conversational and text processing tasks while maintaining a high degree of reliability and predictability. Claude can help with use cases including summarization, search, creative and collaborative writing, Q&A, coding, and more.
One of the advantages of Claude is that it has a larger context window than other large language models, such as GPT-4. This means that Claude can process more input data at once, and can analyze an entire book's worth of material in under a minute. This also allows Claude to have longer and more coherent conversations with users, and to remember more details from previous interactions.
Another advantage of Claude is that it is more steerable and less likely to produce harmful outputs than other models. Claude can take direction on personality, tone, and behavior, and can adapt to different domains and tasks. Claude is also trained to avoid generating offensive, misleading, or harmful content, and to flag any potential issues or uncertainties in its responses.
Claude is accessible through chat interface and API in Anthropic's developer console. There are two versions of Claude available: Claude and Claude Instant. Claude is a state-of-the-art high-performance model, while Claude Instant is a lighter, less expensive, and much faster option.
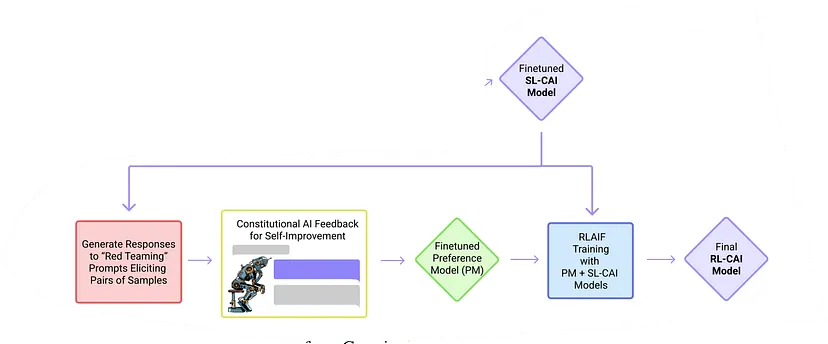
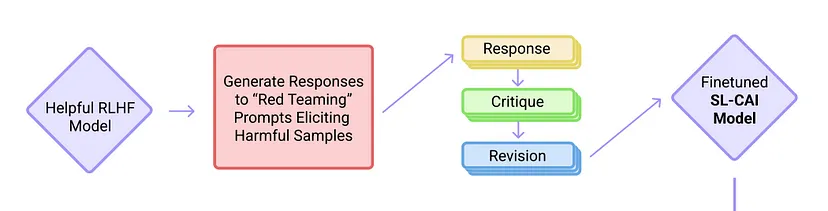
As AI systems become more capable, we would like to enlist their help to supervise other AIs. We experiment with methods for training a harmless AI assistant through self-improvement, without any human labels identifying harmful outputs. The only human oversight is provided through a list of rules or principles, and so we refer to the method as 'Constitutional AI'. The process involves both a Supervised Learning and a Reinforcement Learning (RL) phase. In the supervised phase we sample from an initial model, then generate self-critiques and revisions, and then finetune the original model on revised responses. In the RL phase, we sample from the finetuned model, use a model to evaluate which of the two samples is better, and then train a preference model from this dataset of AI preferences. We then train with RL using the preference model as the reward signal, i.e. we use 'RL from AI Feedback' (RLAIF). As a result we are able to train a harmless but non-evasive AI assistant that engages with harmful queries by explaining its objections to them. Both the SL and RL methods can leverage chain-of-thought style reasoning to improve the human-judged performance and transparency of AI decision making. These methods make it possible to control AI behavior more precisely and with far fewer human labels. - Anthropic
The Constitutional AI methodology has two phases, similar to Reinforcement Learning (RL) from Human Feedback (RLHF).
1. The Supervised Learning Phase.
2. The Reinforcement Learning Phase.