Constitutional AI
YouTube ... Quora ...Google search ...Google News ...Bing News
- Reinforcement Learning (RL)
- Assistants ... Hybrid Assistants ... Agents ... Negotiation ... HuggingGPT ... LangChain
- Generative AI ... Conversational AI ... OpenAI's ChatGPT ... Perplexity ... Microsoft's Bing ... You ...Google's Bard ... Baidu's Ernie
- Reinforcement Learning (RL) from Human Feedback (RLHF)
- Paper Review: Constitutional AI, Training LLMs using Principles
Constitutional AI is a method for training AI systems using a set of rules or principles that act as a “constitution” for the AI system. This approach allows the AI system to operate within a societally accepted framework and aligns it with human intentions1.
Some benefits of using Constitutional AI include allowing a model to explain why it is refusing to provide an answer, improving transparency of AI decision making, and controlling AI behavior more precisely with fewer human labels.
The Constitutional AI methodology has two phases, similar to Reinforcement Learning (RL) from Human Feedback (RLHF).
1. The Supervised Learning Phase.
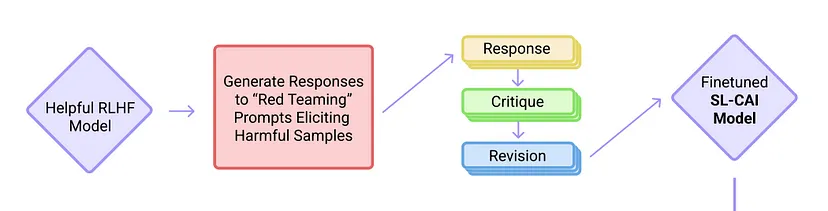
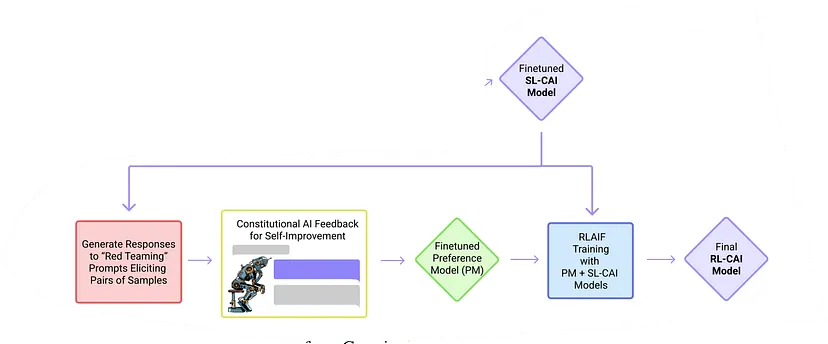
2. The Reinforcement Learning Phase.
Claude | Anthropic
- Claude | Anthropic
- Meet Claude: Anthropic’s Rival to ChatGPT | Riley Goodside - Scale
- Anthropic introduces Claude, a “more steerable” AI competitor to ChatGPT | Benj Edwards - ARS Technica ... Anthropic aims for "safer" and "less harmful" AI, but at a higher price.
As AI systems become more capable, we would like to enlist their help to supervise other AIs. We experiment with methods for training a harmless AI assistant through self-improvement, without any human labels identifying harmful outputs. The only human oversight is provided through a list of rules or principles, and so we refer to the method as 'Constitutional AI'. The process involves both a Supervised Learning and a Reinforcement Learning (RL) phase. In the supervised phase we sample from an initial model, then generate self-critiques and revisions, and then finetune the original model on revised responses. In the RL phase, we sample from the finetuned model, use a model to evaluate which of the two samples is better, and then train a preference model from this dataset of AI preferences. We then train with RL using the preference model as the reward signal, i.e. we use 'RL from AI Feedback' (RLAIF). As a result we are able to train a harmless but non-evasive AI assistant that engages with harmful queries by explaining its objections to them. Both the SL and RL methods can leverage chain-of-thought style reasoning to improve the human-judged performance and transparency of AI decision making. These methods make it possible to control AI behavior more precisely and with far fewer human labels. - Anthropic