Transformer
YouTube search... ...Google search
- Attention
- What is a Transformer? | Maxime Allard - Medium
- Recurrent Neural Network (RNN)
- Bidirectional Encoder Representations from Transformers (BERT)
- Natural Language Processing (NLP)
- Memory Networks
- Transformer-XL
- Tensor2Tensor (T2T) | Google Brain
- The Illustrated Transformer | Jay Alammar
- Sequence to Sequence (Seq2Seq)
Transformer Model - The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an Autoencoder (AE) / Encoder-Decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Attention Is All You Need | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser, and I. Polosukhin
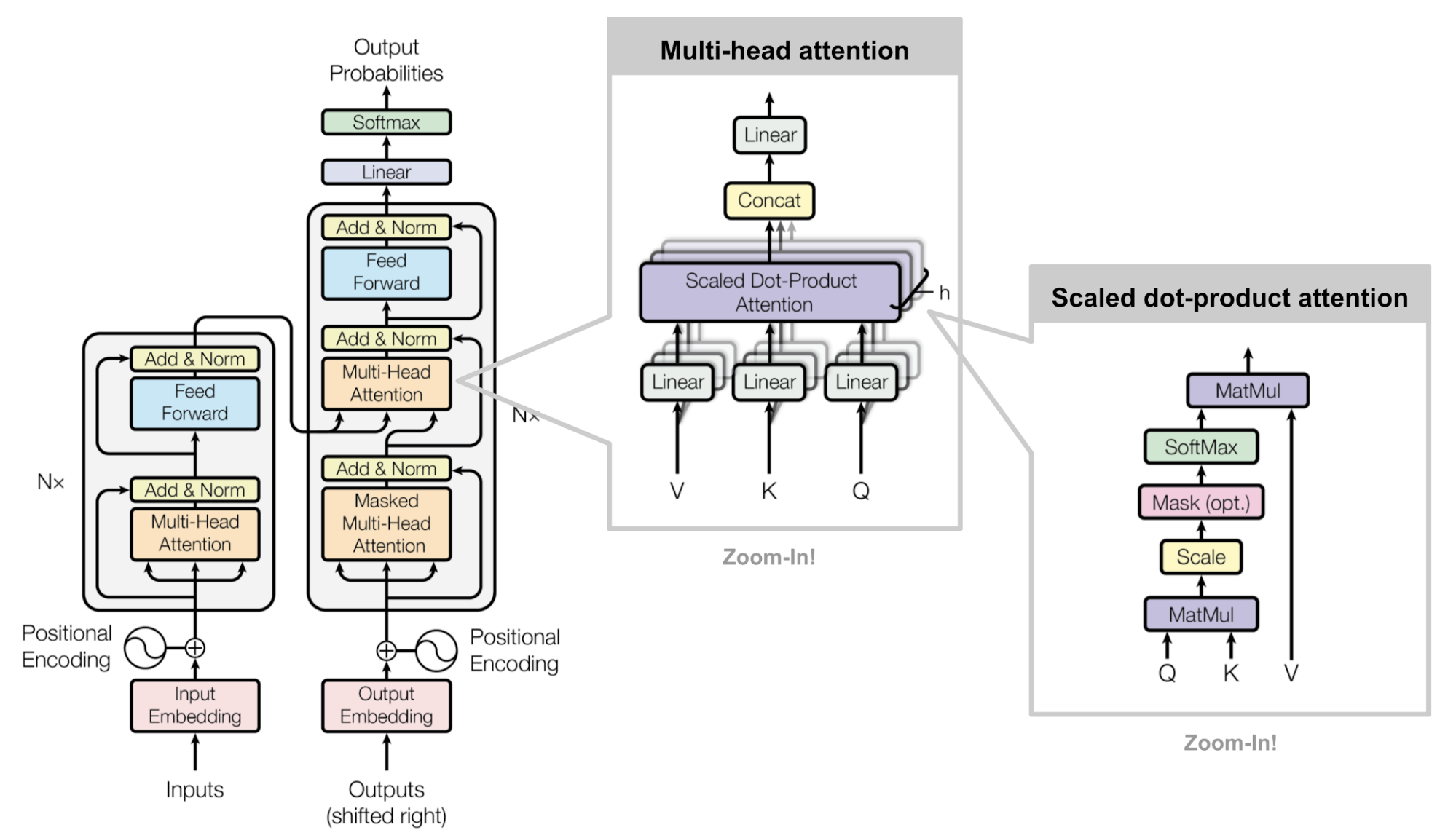
Multi-head scaled dot-product attention mechanism. (Image source: Fig 2 in Vaswani, et al., 2017)
Key, Value, and Query
“Attention is All you Need” (Vaswani, et al., 2017), without a doubt, is one of the most impactful and interesting paper in 2017. It presented a lot of improvements to the soft attention and make it possible to do Sequence to Sequence (Seq2Seq) modeling without Recurrent Neural Network (RNN) units. The proposed “transformer” model is entirely built on the Self-Attention mechanisms without using sequence-aligned recurrent architecture.
The secret recipe is carried in its model architecture
The major component in the transformer is the unit of multi-head Self-Attention mechanism. The transformer views the encoded representation of the input as a set of key-value pairs, (K,V), both of dimension n (input sequence length); in the context of NMT, both the keys and values are the encoder hidden states. In the decoder, the previous output is compressed into a query (Q of dimension m) and the next output is produced by mapping this query and the set of keys and values.
The transformer adopts the scaled Dot Product Attention: the output is a weighted sum of the values, where the weight assigned to each value is determined by the Dot Product of the query with all the keys:
Attention(Q,K,V)=softmax(QK⊤n−−√)V
Multi-Head Self-Attention
Multi-head scaled Dot Product Attention
Rather than only computing the Attention once, the multi-head mechanism runs through the scaled Dot Product Attention multiple times in parallel. The independent Attention outputs are simply concatenated and linearly transformed into the expected dimensions. I assume the motivation is because ensembling always helps? ;) According to the paper, “multi-head Attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single Attention head, averaging inhibits this.”Attention? Attention! | Lilian Weng