Difference between revisions of "Long Short-Term Memory (LSTM)"
m |
m |
||
| Line 17: | Line 17: | ||
** [[Hopfield Network (HN)]] | ** [[Hopfield Network (HN)]] | ||
* [https://www.technologyreview.com/2023/02/08/1068068/chatgpt-is-everywhere-heres-where-it-came-from/ ChatGPT is everywhere. Here’s where it came from | Will Douglas Heaven - MIT Technology Review] | * [https://www.technologyreview.com/2023/02/08/1068068/chatgpt-is-everywhere-heres-where-it-came-from/ ChatGPT is everywhere. Here’s where it came from | Will Douglas Heaven - MIT Technology Review] | ||
| − | + | ** [[ChatGPT]] | [[OpenAI]] | |
| − | |||
| − | |||
| − | |||
| − | ** [[ChatGPT]] | [[OpenAI | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
* [http://karpathy.github.io/2015/05/21/rnn-effectiveness/ Andrej Karpathy blog] | * [http://karpathy.github.io/2015/05/21/rnn-effectiveness/ Andrej Karpathy blog] | ||
* [http://colah.github.io/posts/2015-08-Understanding-LSTMs/ Understanding LSTM Networks | Christopher Olah] | * [http://colah.github.io/posts/2015-08-Understanding-LSTMs/ Understanding LSTM Networks | Christopher Olah] | ||
Revision as of 23:44, 25 February 2023
YouTube Search ...Google search
- Neural Network Zoo | Fjodor Van Veen
- A Beginner's Guide to LSTMs
- Recurrent Neural Network (RNN) Variants:
- ChatGPT is everywhere. Here’s where it came from | Will Douglas Heaven - MIT Technology Review
- Andrej Karpathy blog
- Understanding LSTM Networks | Christopher Olah
- Animated RNN, LSTM and GRU | Raimi Karim - Towards Data Science
- Predicting Stock Price with LSTM | Asutosh Nayak - Towards Data Science ...Code
- Essentials of Deep Learning : Introduction to Long Short Term Memory | Pranjal Srivastava 10 Dec 2017
- Illustrated Guide to LSTM’s and GRU’s: A step by step explanation | Michael Nguyen - Towards Data Science
- Step-by-step understanding LSTM Autoencoder layers | Chitta Ranjan - Towards Data Science
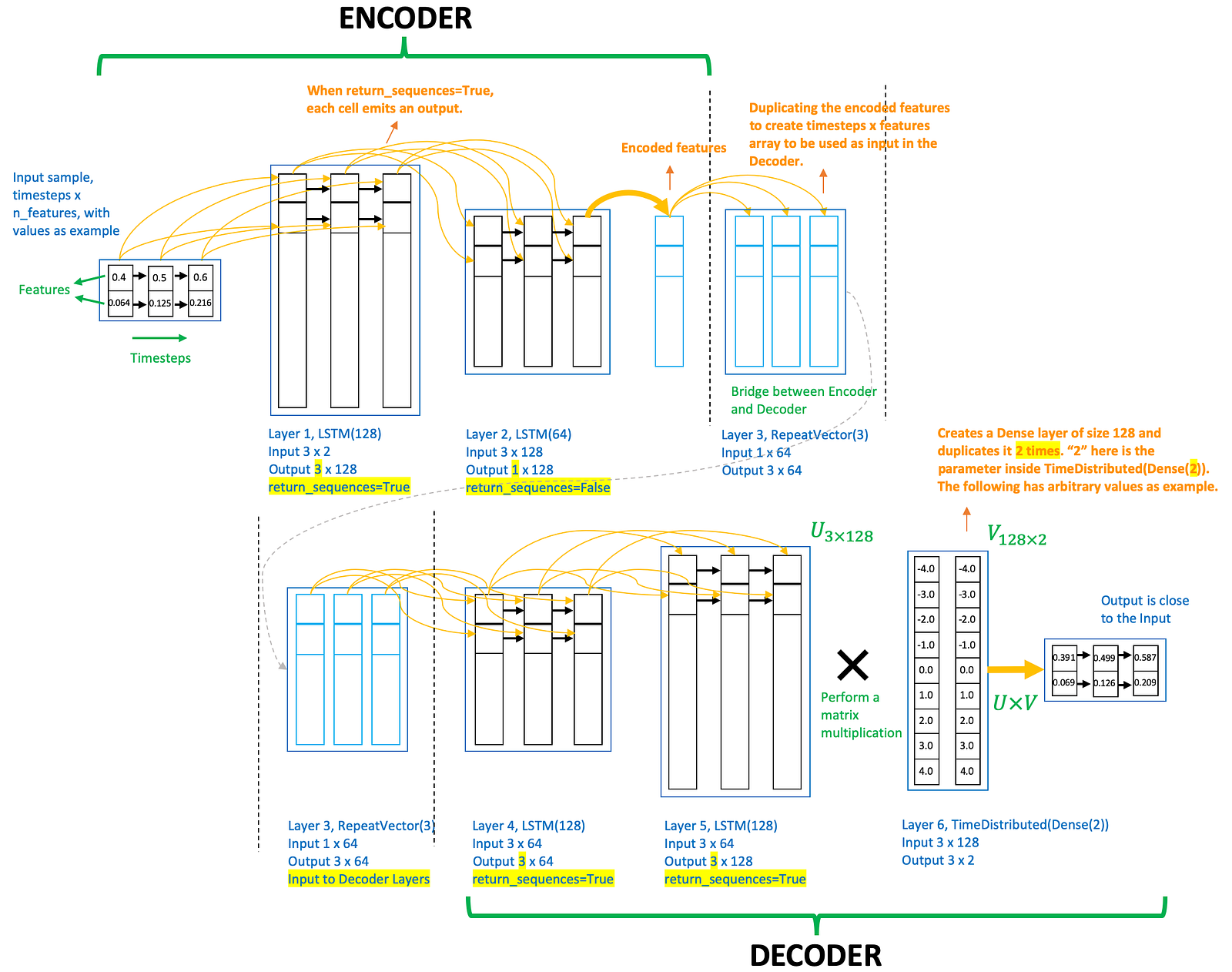
A LSTM (Long Short-term Memory) Neural Network is just another kind of Artificial Neural Network, which falls in the category of Recurrent Neural Network (RNN). What makes LSTM Neural Networks different from regular Neural Networks is, they have LSTM cells as neurons in some of their layers. Much like Convolutional Layers help a (Deep) Convolutional Neural Network (DCNN/CNN) learn about image features, LSTM cells help the Network learn about temporal data, something which other Machine Learning models traditionally struggled with. ... Each LSTM cell in our Neural Network will only look at a single column of its inputs, and also at the previous column’s LSTM cell’s output. Normally, we feed our LSTM Neural Network a whole matrix as its input, where each column corresponds to something that “comes before” the next column. This way, each LSTM cell will have two different input vectors: the previous LSTM cell’s output (which gives it some information about the previous input column) and its own input column. LSTM: How To Train Neural Networks To Write Like Lovecraft | Strikingloo
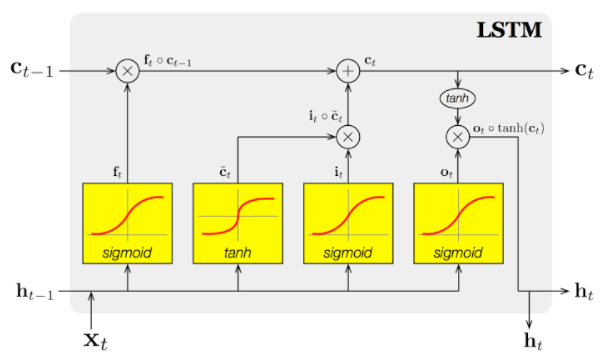
To combat the vanishing / exploding gradient problem by introducing gates and an explicitly defined memory cell. These are inspired mostly by circuitry, not so much biology. Each neuron has a memory cell and three gates: input, output and forget. The function of these gates is to safeguard the information by stopping or allowing the flow of it. The input gate determines how much of the information from the previous layer gets stored in the cell. The output layer takes the job on the other end and determines how much of the next layer gets to know about the state of this cell. The forget gate seems like an odd inclusion at first but sometimes it’s good to forget: if it’s learning a book and a new chapter begins, it may be necessary for the network to forget some characters from the previous chapter. LSTMs have been shown to be able to learn complex sequences, such as writing like Shakespeare or composing primitive music. Note that each of these gates has a weight to a cell in the previous neuron, so they typically require more resources to run. Hochreiter, Sepp, and Jürgen Schmidhuber. “Long short-term memory.” Neural computation 9.8 (1997): 1735-1780.