Difference between revisions of "Transformer"
| Line 9: | Line 9: | ||
* [[Attention]] | * [[Attention]] | ||
| + | * [http://medium.com/inside-machine-learning/what-is-a-transformer-d07dd1fbec04 What is a Transformer? | Maxime Allard - Medium] | ||
* [[Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and Recurrent Neural Network (RNN)]] | * [[Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and Recurrent Neural Network (RNN)]] | ||
* [[Bidirectional Encoder Representations from Transformers (BERT)]] | * [[Bidirectional Encoder Representations from Transformers (BERT)]] | ||
| Line 23: | Line 24: | ||
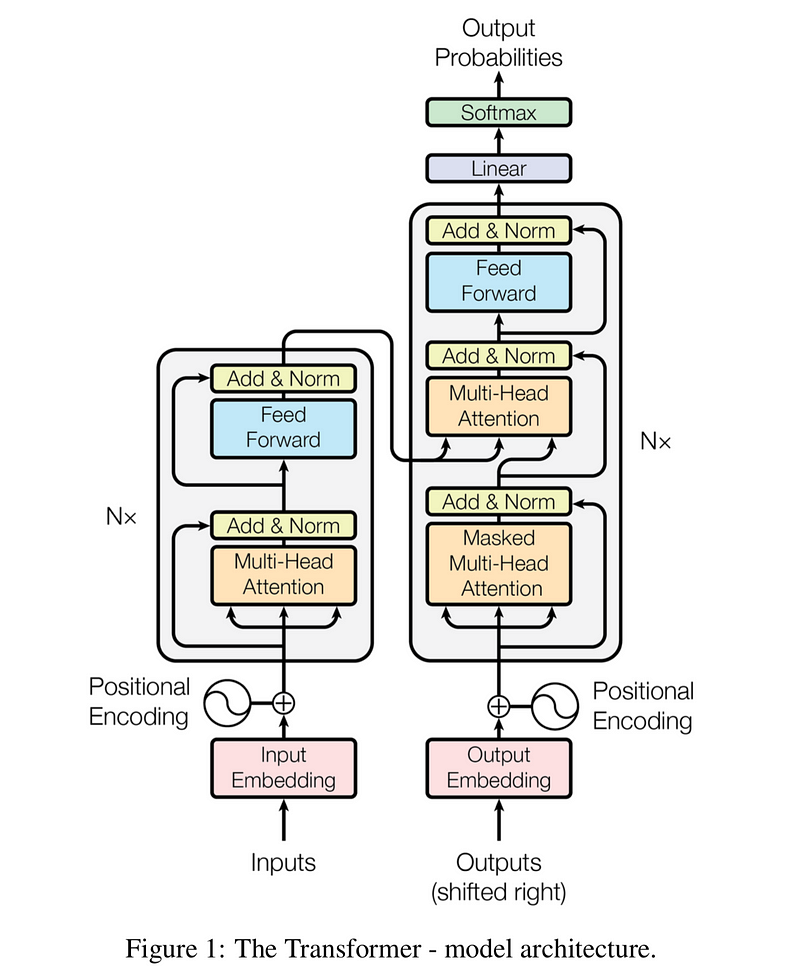
Transformer Model - The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an [[Autoencoder (AE) / Encoder-Decoder]] configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. [http://arxiv.org/abs/1706.03762 Attention Is All You Need | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser, and I. Polosukhin] | Transformer Model - The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an [[Autoencoder (AE) / Encoder-Decoder]] configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. [http://arxiv.org/abs/1706.03762 Attention Is All You Need | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser, and I. Polosukhin] | ||
| − | http:// | + | http://cdn-images-1.medium.com/max/800/1*BHzGVskWGS_3jEcYYi6miQ.png |
<youtube>IxQtK2SjWWM</youtube> | <youtube>IxQtK2SjWWM</youtube> | ||
Revision as of 06:46, 30 June 2019
YouTube search... ...Google search
- Attention
- What is a Transformer? | Maxime Allard - Medium
- Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and Recurrent Neural Network (RNN)
- Bidirectional Encoder Representations from Transformers (BERT)
- Natural Language Processing (NLP)
- Memory Networks
- Transformer-XL
- Tensor2Tensor (T2T) | Google Brain
- The Illustrated Transformer | Jay Alammar
- Sequence to Sequence (Seq2Seq)
Transformer Model - The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an Autoencoder (AE) / Encoder-Decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Attention Is All You Need | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser, and I. Polosukhin