Difference between revisions of "Video/Image"
m (→Video Synthesis) |
m |
||
| (146 intermediate revisions by the same user not shown) | |||
| Line 2: | Line 2: | ||
|title=PRIMO.ai | |title=PRIMO.ai | ||
|titlemode=append | |titlemode=append | ||
| − | |keywords=artificial, intelligence, machine, learning, models | + | |keywords=ChatGPT, artificial, intelligence, machine, learning, GPT-4, GPT-5, NLP, NLG, NLC, NLU, models, data, singularity, moonshot, Sentience, AGI, Emergence, Moonshot, Explainable, TensorFlow, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Hugging Face, OpenAI, Tensorflow, OpenAI, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Meta, LLM, metaverse, assistants, agents, digital twin, IoT, Transhumanism, Immersive Reality, Generative AI, Conversational AI, Perplexity, Bing, You, Bard, Ernie, prompt Engineering LangChain, Video/Image, Vision, End-to-End Speech, Synthesize Speech, Speech Recognition, Stanford, MIT |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools |
| − | |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | + | |
| + | <!-- Google tag (gtag.js) --> | ||
| + | <script async src="https://www.googletagmanager.com/gtag/js?id=G-4GCWLBVJ7T"></script> | ||
| + | <script> | ||
| + | window.dataLayer = window.dataLayer || []; | ||
| + | function gtag(){dataLayer.push(arguments);} | ||
| + | gtag('js', new Date()); | ||
| + | |||
| + | gtag('config', 'G-4GCWLBVJ7T'); | ||
| + | </script> | ||
}} | }} | ||
| − | [https://www.youtube.com/results?search_query= | + | [https://www.youtube.com/results?search_query=ai+video+~movie YouTube] |
| − | [https://www.google.com/search?q= | + | [https://www.quora.com/search?q=ai%20video%20~movie ... Quora] |
| + | [https://www.google.com/search?q=ai+video+~movie ...Google search] | ||
| + | [https://news.google.com/search?q=ai+video+~movie ...Google News] | ||
| + | [https://www.bing.com/news/search?q=ai+video+~movie&qft=interval%3d%228%22 ...Bing News] | ||
| − | * [[ | + | * [[Video/Image]] ... [[Vision]] ... [[Enhancement]] ... [[Fake]] ... [[Reconstruction]] ... [[Colorize]] ... [[Occlusions]] ... [[Predict image]] ... [[Image/Video Transfer Learning]] ... [[Art]] ... [[Photography]] |
| − | + | * [[End-to-End Speech]] ... [[Synthesize Speech]] ... [[Speech Recognition]] ... [[Music]] | |
| − | + | * [[Humor]] ... [[Writing/Publishing]] ... [[Storytelling]] ... [[AI Generated Broadcast Content|Broadcast]] ... [[Journalism|Journalism/News]] ... [[Podcasts]] ... [[Books, Radio & Movies - Exploring Possibilities]] | |
| − | * | + | * [[What is Artificial Intelligence (AI)? | Artificial Intelligence (AI)]] ... [[Generative AI]] ... [[Machine Learning (ML)]] ... [[Deep Learning]] ... [[Neural Network]] ... [[Reinforcement Learning (RL)|Reinforcement]] ... [[Learning Techniques]] |
| − | * | + | * [[Conversational AI]] ... [[ChatGPT]] | [[OpenAI]] ... [[Bing/Copilot]] | [[Microsoft]] ... [[Gemini]] | [[Google]] ... [[Claude]] | [[Anthropic]] ... [[Perplexity]] ... [[You]] ... [[phind]] ... [[Ernie]] | [[Baidu]] |
| − | * | + | * [[Immersive Reality]] ... [[Metaverse]] ... [[Omniverse]] ... [[Transhumanism]] ... [[Religion]] |
| − | * [[ | + | * [[Prompt Engineering (PE)]] ... [[Prompt Engineering (PE)#PromptBase|PromptBase]] ... [[Prompt Injection Attack]] |
| − | * [ | + | ** [[Prompt Engineering (PE)#Image Generation Prompting | Image Generation Prompting]] |
| − | * [[ | + | * [[How do I leverage Artificial Intelligence (AI)?]] ... [[Reading Material & Glossary|Reading/Glossary]] ... [[Courses & Certifications|Courses/Certs]] ... [[Education]] ... [[Help Wanted]] |
| − | * [[ | + | * [[Embedding]] ... [[Fine-tuning]] ... [[Retrieval-Augmented Generation (RAG)|RAG]] ... [[Agents#AI-Powered Search|Search]] ... [[Clustering]] ... [[Recommendation]] ... [[Anomaly Detection]] ... [[Classification]] ... [[Dimensional Reduction]]. [[...find outliers]] |
| − | * [[ | ||
| − | * [[ | ||
| − | |||
* [[Rekognition]] Video | * [[Rekognition]] Video | ||
* [[DeepLens - deep learning enabled video camera]] | * [[DeepLens - deep learning enabled video camera]] | ||
| − | * [[Gaming]] | + | * [[Gaming]] ... [[Game-Based Learning (GBL)]] ... [[Games - Security|Security]] ... [[Game Development with Generative AI|Generative AI]] ... [[Metaverse#Games - Metaverse|Games - Metaverse]] ... [[Games - Quantum Theme|Quantum]] ... [[Game Theory]] ... [[Game Design | Design]] |
| + | * [[Recurrent Neural Network (RNN)]] | ||
| + | * [[Long Short-Term Memory (LSTM)]] | ||
| + | * [[ImageBind]] | [[Meta]] | ||
| + | * [https://www.papercup.com/ Papercup]; go global with your existing video content using AI dubbing | ||
* [https://medium.com/dataart-media/is-artificial-intelligence-poised-to-revolutionize-hollywood-e088257705a3 Is Artificial Intelligence Poised to Revolutionize Hollywood?] | * [https://medium.com/dataart-media/is-artificial-intelligence-poised-to-revolutionize-hollywood-e088257705a3 Is Artificial Intelligence Poised to Revolutionize Hollywood?] | ||
* [https://www.digitalinformationworld.com/2019/05/google-trashy-video-algorithm-cleans-up-youtube-homepage.html "Trashy Video Classifier" An Artificial Intelligence System by Google That Cleans up YouTube Homepage | Chris Apostle - Digital Information World] | * [https://www.digitalinformationworld.com/2019/05/google-trashy-video-algorithm-cleans-up-youtube-homepage.html "Trashy Video Classifier" An Artificial Intelligence System by Google That Cleans up YouTube Homepage | Chris Apostle - Digital Information World] | ||
* [https://cognitivemill.com/blog/netflix-ai-to-optimize-content-production/ Hey Netflix, Here’s How You Can Use AI To Optimize Content Production | Pavel Saskovec - Cognitive Mill] | * [https://cognitivemill.com/blog/netflix-ai-to-optimize-content-production/ Hey Netflix, Here’s How You Can Use AI To Optimize Content Production | Pavel Saskovec - Cognitive Mill] | ||
* [https://www.cartoonbrew.com/tech/netflix-japan-ai-dog-and-boy-225631.html Netflix Faces Backlash After Using AI Software To Create Backgrounds For An Animated Short | Jamie Lang - Cartoon Brew] | * [https://www.cartoonbrew.com/tech/netflix-japan-ai-dog-and-boy-225631.html Netflix Faces Backlash After Using AI Software To Create Backgrounds For An Animated Short | Jamie Lang - Cartoon Brew] | ||
| + | * [https://www.pcgamer.com/researchers-translate-brain-waves-into-scarily-accurate-images-using-stable-diffusion-ai/ Researchers translate brain waves into scarily accurate images using Stable Diffusion AI | Katie Wickens - PC Gamer] ... Researchers have been able to use Stable Diffusion models to reconstruct images from human brain waves. | ||
| + | * [https://www.craiyon.com/ Craiyon] | ||
| + | * [https://www.themix.net/2023/05/tom-hanks-reveals-hell-star-in-movies-after-his-death-using-ai/ Tom Hanks says with AI he could appear in movies after death; star’s projects that have already used the tech | Caroline Thayer - Yahoo News] | ||
| + | * [https://sites.research.google/videopoet/ VideoPoet] | [[Google]] ... A large language model for zero-shot video generation | ||
| + | * [https://www.theverge.com/news/653504/oscars-film-award-rule-change-ai The Oscars officially don’t care if films use AI | Wes Davis - The Verge] ... using AI doesn’t, on its own, hurt a movie’s chances | ||
| + | = <span id="Look here"></span>Look here = | ||
| + | <youtube>QuWlcWiIkmI</youtube> | ||
<youtube>1QqhD3Boq_Y</youtube> | <youtube>1QqhD3Boq_Y</youtube> | ||
<youtube>8XO3q6MA668</youtube> | <youtube>8XO3q6MA668</youtube> | ||
| Line 36: | Line 56: | ||
<youtube>VCiuqUfE9QM</youtube> | <youtube>VCiuqUfE9QM</youtube> | ||
<youtube>KZ7BnJb30Cc</youtube> | <youtube>KZ7BnJb30Cc</youtube> | ||
| + | <youtube>YV4UEqcMWH4</youtube> | ||
| + | <youtube>3-UDwk1U77s</youtube> | ||
| + | <youtube>20zIzdmuRcE</youtube> | ||
| + | |||
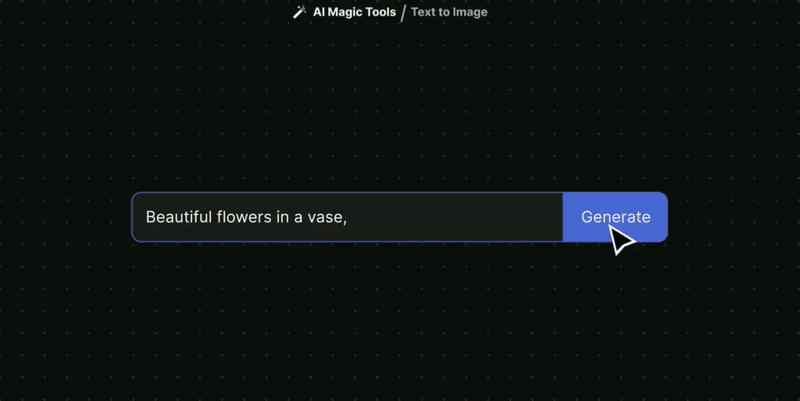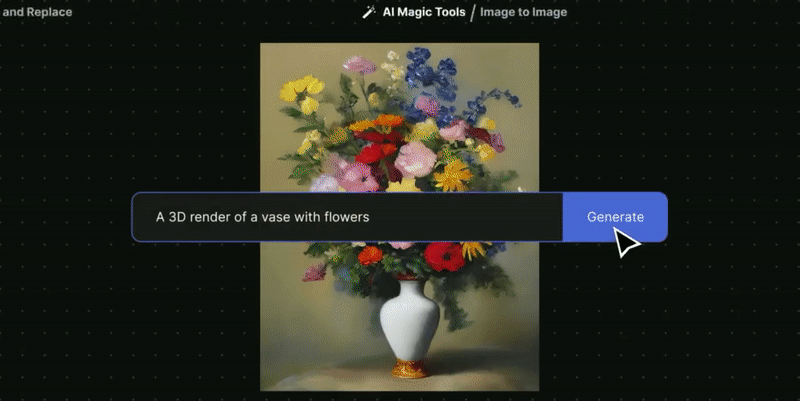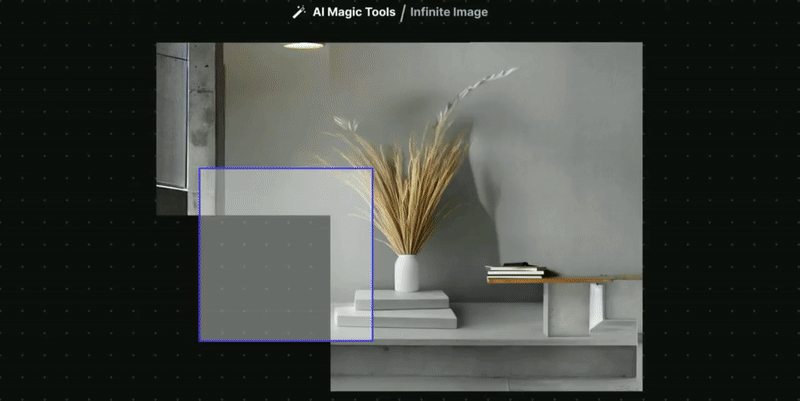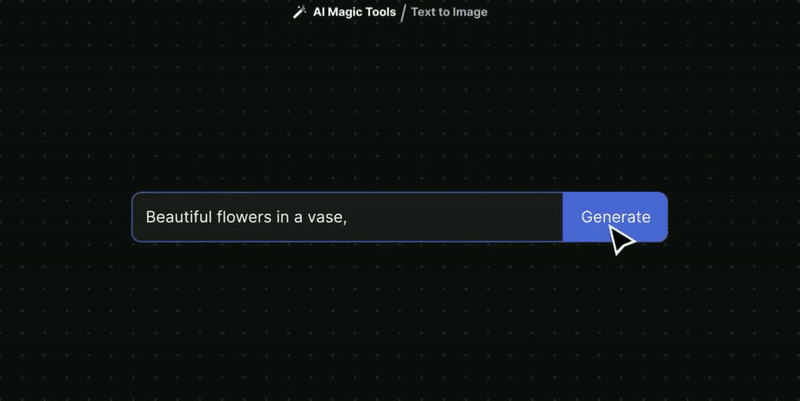
| + | = <span id="Text to Image"></span>Text to Image = | ||
| + | * [https://www.bing.com/create Bing Create] | [[Microsoft]] ... create images from words with AI | ||
| + | * [https://designer.microsoft.com/ Designer] | [[Microsoft]] ... focusing on designs; including posters, illustrations, and campaign artwork | ||
| + | |||
| + | <youtube>f7QOhIUfI8Q</youtube> | ||
| + | <youtube>rAbhypxs1qQ</youtube> | ||
| + | <youtube>9bcbh2hC7Hw</youtube> | ||
| + | <youtube>gmvRStL_Dag</youtube> | ||
| + | |||
| + | == <span id="Ideogram AI"></span>Ideogram AI == | ||
| + | [https://www.youtube.com/results?search_query=ai+Ideogram YouTube] | ||
| + | [https://www.quora.com/search?q=ai%20Ideogram ... Quora] | ||
| + | [https://www.google.com/search?q=ai+Ideogram ...Google search] | ||
| + | [https://news.google.com/search?q=ai+Ideogram ...Google News] | ||
| + | [https://www.bing.com/news/search?q=ai+Ideogramn&qft=interval%3d%228%22 ...Bing News] | ||
| + | |||
| + | * [https://ideogram.ai/ Ideogram AI] | ||
| + | Ideogram AI is a generative AI tool that creates photorealistic images and artworks using AI with reliable typography within images. It is a free-to-use tool that was launched in August 2023 by a team of former Google Brain researchers. Ideogram AI works by combining a pre-trained language model with a denoising diffusion model. The language model is responsible for generating the text, while the denoising diffusion model is responsible for generating the image. The two models work together to create images that are both realistic and meaningful. One of the key features of Ideogram AI is its ability to generate text within images. This is something that other generative AI tools, such as DALL-E 2 and Midjourney, have not been able to do as reliably. Ideogram AI can generate text in a variety of fonts, sizes, and styles, and it can also combine text with other visual elements, such as icons and illustrations. | ||
| + | |||
| + | <youtube>8FSRkR6xB8A</youtube> | ||
| + | |||
| + | == <span id="Firefly"></span>Firefly == | ||
| + | [https://www.youtube.com/results?search_query=ai+Firefly+Adobe YouTube] | ||
| + | [https://www.quora.com/search?q=ai%20Firefly%20Adobe ... Quora] | ||
| + | [https://www.google.com/search?q=ai+Firefly+Adobe ...Google search] | ||
| + | [https://news.google.com/search?q=ai+Firefly+Adobe ...Google News] | ||
| + | [https://www.bing.com/news/search?q=ai+Firefly+Adoben&qft=interval%3d%228%22 ...Bing News] | ||
| + | |||
| + | * [https://firefly.adobe.com/ Firefly | Adobe.com] | ||
| + | Adobe Firefly is a creative generative AI engine that is part of Adobe Sensei’s Generative AI services. It is available in Photoshop (beta), Illustrator, Adobe Express, and on the web. With Firefly, you can dream it, type it, and see it. You can use text prompts to generate custom vectors, brushes, textures, images, videos, and 3D objectsFirefly includes various image modification tools such as content type, color, tone, lighting, and composition. | ||
| + | |||
| + | * [https://firefly.adobe.com/generate/images <b>Generate Images</b>] ... Generate images from a detailed text description | ||
| + | |||
| + | <img src="https://firefly.adobe.com/92e0dbbdc00eab4ce77c.jpg" width="200"> | ||
| + | |||
| + | * [https://firefly.adobe.com/upload/inpaint <b>Generate Fill</b>] ... Use a brush to remove objects, or paint in new ones from text descriptions | ||
| + | |||
| + | <img src="https://firefly.adobe.com/6ce4f8a4d51bbe9c4916.jpg" width="200"> | ||
| + | |||
| + | * [https://firefly.adobe.com/generate/font-styles <b>Text Effects</b>] ... Apply styles or textures to text with a text prompt. | ||
| + | |||
| + | <img src="https://firefly.adobe.com/cd9ed1360bb945c299b4.jpg" width="200"> | ||
| + | |||
| + | * [https://firefly.adobe.com/generate/recolor <b>Generative recolor</b>] ... Generate color variations of your vector artwork from a detailed text description. | ||
| + | |||
| + | <img src="https://firefly.adobe.com/7cd5ae44e8ad05034be4.jpg" width="200"> | ||
| + | |||
| + | == <span id="Stable Diffusion"></span>Stable Diffusion == | ||
| + | [https://www.youtube.com/results?search_query=ai+stable+diffusion YouTube] | ||
| + | [https://www.quora.com/search?q=ai%20stable%20diffusion ... Quora] | ||
| + | [https://www.google.com/search?q=ai+stable+diffusion ...Google search] | ||
| + | [https://news.google.com/search?q=ai+stable+diffusion ...Google News] | ||
| + | [https://www.bing.com/news/search?q=ai+stable+diffusion&qft=interval%3d%228%22 ...Bing News] | ||
| + | |||
| + | * Try [https://stablediffusionweb.com/#demo Stable Diffusion here] | ||
| + | ** [https://stablediffusionweb.com/prompts Prompts] | ||
| + | * [[Stability AI]] | ||
| + | * [[Art#Stable Diffusion with ControlNet|Stable Diffusion with ControlNet]] | ||
| + | * [https://beta.dreamstudio.ai/dream Stable Diffusion | DreamStudio Lite beta] | ||
| + | ** [[Video/Image#Runway | Runway]] ... can edit videos in real-time, collaborate, and use more than 30 AI magic tools. | ||
| + | ** [https://laion.ai/ LAION]... Large-scale Artificial Intelligence Open Network | ||
| + | ** [https://www.eleuther.ai/ EleutherAI] | ||
| + | ** Heidelberg University | ||
| + | |||
| + | A [[latent]] text-to-image [[diffusion]] model capable of generating photo-realistic images given any text input. Designing and implementing solutions using collective intelligence and augmented technology. | ||
| + | |||
| + | <youtube>MXmacOUJUaw</youtube> | ||
| + | <youtube>DHaL56P6f5M</youtube> | ||
| + | <youtube>vUTV85D51yk</youtube> | ||
| + | <youtube>H6mmNxynlZw</youtube> | ||
| + | |||
| + | == <span id="DALL-E"></span>DALL-E == | ||
| + | [https://www.youtube.com/results?search_query=ai+DALL-E YouTube] | ||
| + | [https://www.quora.com/search?q=ai%20DALL-E ... Quora] | ||
| + | [https://www.google.com/search?q=ai+DALL-E ...Google search] | ||
| + | [https://news.google.com/search?q=ai+DALL-E ...Google News] | ||
| + | [https://www.bing.com/news/search?q=ai+DALL-E&qft=interval%3d%228%22 ...Bing News] | ||
| + | |||
| + | * [[Generative Pre-trained Transformer (GPT)#OpenAI GPT Builder|OpenAI GPT Builder]] | ||
| + | * [https://www.bing.com/images/create DALL·E 3 on Bing] | ||
| + | * [https://openai.com/dall-e-2/ DALL·E 2 | ] [[OpenAI]] ...[https://www.theverge.com/2022/4/6/23012123/openai-clip-dalle-2-ai-text-to-image-generator-testing OpenAI’s DALL-E 2 AI image generator can now edit pictures, too | Adi Robertson - The Verge] | ||
| + | * [https://valle-demo.github.io/ VALL-E] ... Zero-Shot Text to Speech Synthesizer | ||
| + | |||
| + | DALL·E is a AI system that can create realistic images and art from a description in natural language. We currently support the ability, given a prommpt, to create a new image with a certain size, edit an existing image, or create variations of a user provided image. | ||
| + | |||
| + | The current DALL·E model available through our API is the 2nd iteration of DALL·E with more realistic, accurate, and 4x greater resolution images than the original model. You can try it through the our Labs interface or via the API. | ||
| + | |||
| + | |||
| + | <youtube>Q1GvaTx00K4</youtube> | ||
| + | <youtube>zAd9lxTQdsk</youtube> | ||
| + | |||
| + | == <span id="MidJourney"></span>MidJourney == | ||
| + | [https://www.youtube.com/results?search_query=ai+MidJourney YouTube] | ||
| + | [https://www.quora.com/search?q=ai%20MidJourney ... Quora] | ||
| + | [https://www.google.com/search?q=ai+MidJourney ...Google search] | ||
| + | [https://news.google.com/search?q=ai+MidJourney ...Google News] | ||
| + | [https://www.bing.com/news/search?q=ai+MidJourney&qft=interval%3d%228%22 ...Bing News] | ||
| + | |||
| + | * [https://midjourney.com/home MidJourney] | ||
| + | * [https://nftnow.com/ai/inpainting-in-midjourney-a-comprehensive-guide/ Inpainting in Midjourney: A Comprehensive Guide | Keisha Oleaga - NFT Now] | ||
| + | |||
| + | Runway Now Turns Midjourney Images into Videos: Generative video darling Runway has released a Gen 2 update with a feature that has really captured AI Twitter’s attention: the ability to automatically animate Midjourney images. This was a feature Pika Labs had also previously released, showing how competition is driving things forward. | ||
| + | |||
| + | <youtube>Sj88fbBg3IA</youtube> | ||
| + | <youtube>FcRFQTMW_bo</youtube> | ||
| + | |||
| + | == <span id="Image GPT"></span>Image GPT == | ||
| + | [https://www.youtube.com/results?search_query=ai+Image+GPT YouTube] | ||
| + | [https://www.quora.com/search?q=ai%20Image%20GPT ... Quora] | ||
| + | [https://www.google.com/search?q=ai+Image+GPT ...Google search] | ||
| + | [https://news.google.com/search?q=ai+Image+GPT ...Google News] | ||
| + | [https://www.bing.com/news/search?q=ai+Image+GPT&qft=interval%3d%228%22 ...Bing News] | ||
| + | |||
| + | Image GPT is a generative AI model developed by [[OpenAI]] that uses a transformer architecture, similar to that of the GPT models for text, but adapted to handle images. Instead of generating text, Image GPT predicts pixel values in an autoregressive manner, allowing it to create, complete, or modify images. | ||
| + | |||
| + | Features: | ||
| + | *<b>Pixel Autoregression: </b> Image GPT generates images pixel-by-pixel, predicting each pixel's value based on previously generated ones, similar to how GPT models predict the next word in a sequence. | ||
| + | *<b>Unsupervised Pretraining: </b>The model is trained on a large dataset of images without specific labels, learning general representations of visual data. This unsupervised approach allows it to understand a wide variety of image types and patterns. | ||
| + | *<b>Creative Image Generation: </b>Image GPT can produce new and creative images by sampling from its learned distribution of pixel patterns. | ||
| + | *<b>Image Completion: </b>The model can fill in missing parts of an image or extend an existing image based on the learned patterns. | ||
| + | *<b>Generalization Across Domains: </b> Despite being trained without explicit supervision, Image GPT can generalize to tasks like image classification when fine-tuned or combined with labeled data. | ||
| + | *<b>Compatibility with Transformer Architecture: </b> Built on the transformer architecture, Image GPT benefits from its scalability and ability to model long-range dependencies effectively, even in images. | ||
| + | |||
| + | <youtube>YBlNQK0Ao6g</youtube> | ||
| + | <youtube>oVAzdgLUqvQ</youtube> | ||
| + | |||
| + | == [[NVIDIA]] Canvas == | ||
| + | [https://www.youtube.com/results?search_query=ai+NVIDIA+Canvas YouTube] | ||
| + | [https://www.quora.com/search?q=ai%20NVIDIA%20Canvas ... Quora] | ||
| + | [https://www.google.com/search?q=ai+NVIDIA+Canvas ...Google search] | ||
| + | [https://news.google.com/search?q=ai+NVIDIA+Canvas ...Google News] | ||
| + | [https://www.bing.com/news/search?q=ai+NVIDIA+Canvas&qft=interval%3d%228%22 ...Bing News] | ||
| + | |||
| + | * [https://www.nvidia.com/en-us/studio/canvas/ NVIDIA Canvas] | ||
| + | |||
| + | AI-powered tool designed to help artists and creators quickly generate realistic landscape images. It uses artificial intelligence to turn simple brushstrokes into photorealistic landscapes, making it a valuable resource for concept artists, designers | ||
| + | |||
| + | <youtube>wQMTMGonf9Q</youtube> | ||
| + | <youtube>b8HX-qqdASU</youtube> | ||
| + | |||
| + | == <span id="Imagen"></span>Imagen == | ||
| + | [https://www.youtube.com/results?search_query=ai+Imagen YouTube] | ||
| + | [https://www.quora.com/search?q=ai%20Imagen ... Quora] | ||
| + | [https://www.google.com/search?q=ai+Imagen ...Google search] | ||
| + | [https://news.google.com/search?q=ai+Imagen ...Google News] | ||
| + | [https://www.bing.com/news/search?q=ai+Imagen&qft=interval%3d%228%22 ...Bing News] | ||
| + | |||
| + | * [[Google]] | ||
| + | * [https://imagen.research.google/ Imagen] | ||
| + | |||
| + | Imagen is an AI system developed by Google AI that can create photorealistic images from text descriptions. It is still under development, but it has already surpassed other text-to-image models in terms of image quality and diversity. Imagen works by first encoding the text description into a sequence of numbers. This sequence is then used to generate a low-resolution image. The image is then gradually refined until it reaches the desired resolution. Imagen is trained on a massive dataset of text and images. This dataset includes text descriptions of images, as well as the actual images themselves. This allows Imagen to learn the relationship between text and images, and to generate images that are consistent with the text descriptions. Imagen is still under development, but it has the potential to revolutionize the way we create and interact with images. It could be used to create new forms of art, to generate realistic images for use in movies and video games, and to help people with visual impairments see the world around them. | ||
| + | |||
| + | <youtube>b2P5315ACrY</youtube> | ||
| + | <youtube>PHhQSHkgSx4</youtube> | ||
| + | |||
| + | == <span id="Recraft"></span>Recraft == | ||
| + | [https://www.youtube.com/results?search_query=ai+Recraft YouTube] | ||
| + | [https://www.quora.com/search?q=ai%20Recraft ... Quora] | ||
| + | [https://www.google.com/search?q=ai+Recraft ...Google search] | ||
| + | [https://news.google.com/search?q=ai+Recraft ...Google News] | ||
| + | [https://www.bing.com/news/search?q=ai+Recraft&qft=interval%3d%228%22 ...Bing News] | ||
| + | * [https://www.recraft.ai/ Recraft] | ||
| + | Recraft is a generative AI tool that allows users to create customized images or graphics with ease. It is designed to provide intuitive visual content creation for tasks like making social media graphics, custom illustrations, product mockups, and other creative assets. Recraft V3, also known as Red Panda AI, is a state-of-the-art text-to-image generation model developed by Recraft, a London-based AI company specializing in high-quality graphic design tools. This model has gained significant attention for its ability to produce detailed and photorealistic images from textual descriptions, making it a valuable tool for designers, artists, and creatives. | ||
| + | <youtube>-yhUORe7Zjs</youtube> | ||
| + | <youtube>tVHFSMAnoJI</youtube> | ||
| + | |||
| + | = <span id="Text to Presentation"></span>Text to Presentation = | ||
| + | |||
| + | These tools use AI to automate the process of creating presentations, making it easier for users to focus on their content and ideas. They typically offer a variety of features, such as: | ||
| + | |||
| + | * A library of pre-designed templates | ||
| + | * An AI-powered content assistant that can help with formatting, design, and style | ||
| + | * The ability to embed images, videos, and other media | ||
| + | * Real-time collaboration tools | ||
| + | * Analytics to track presentation views and engagement | ||
| + | |||
| + | |||
| + | These tools can be a valuable resource for anyone who needs to create presentations, but they are particularly useful for professionals who need to create polished and professional presentations on a regular basis. Here is a brief overview of each tool: | ||
| + | |||
| + | * [https://gamma.app/ Gamma AI] is a cloud-based tool that uses AI to create presentations that are both visually appealing and engaging. It offers a variety of templates and features, and it can be used to create presentations for a variety of purposes. | ||
| + | * [https://tome.app/ Tome] is a web-based tool that allows users to create presentations in a more traditional way, but it also offers some AI-powered features, such as the ability to generate content ideas and suggestions for design. | ||
| + | * [https://www.beautiful.ai/ Beautiful.ai] is a popular AI presentation tool that offers a wide range of features, including a large library of templates, an AI-powered content assistant, and the ability to collaborate with others on presentations. | ||
| + | * [https://simplified.com/ Simplified] is a more general-purpose productivity tool that can be used to create presentations, documents, and other types of content. It offers a variety of features, including a drag-and-drop editor, a library of templates, and the ability to collaborate with others. | ||
| + | |||
| + | These presentation tools that helps you create presentations, documents, and webpages quickly and easily. It uses a variety of machine learning algorithms to understand your content and generate visually appealing and engaging presentations. The tools work by first asking you to provide a brief description of your presentation. This can be a few sentences or a few paragraphs. The tool will then use this description to generate a presentation outline. The outline will include the main points of your presentation, as well as the supporting evidence. Once the outline is generated, the tool will then begin to create the presentation slides. It will use its machine learning algorithms to select the appropriate images, graphics, and fonts for each slide. It will also automatically format the text and arrange the elements on the slide in a visually appealing way. The tool can also be used to create documents and webpages. The process is similar to creating a presentation, but you will need to provide more detailed instructions for the tool. For example, you will need to specify the document or webpage layout, the font styles, and the colors. | ||
| + | |||
| + | <youtube>KTQXl_vKI3Y</youtube> | ||
| + | <youtube>2YN-jnKKFtU</youtube> | ||
| + | |||
| + | = <span id="Image to Content Analysis: Vision-based Web Scraping"></span>Image to Content Analysis: Vision-based Web Scraping = | ||
| + | |||
| + | Vision-based web scraping with GPT-4o in Make.com is a new approach that leverages the power of AI to extract data from websites. Overall, vision-based web scraping with GPT-4o in Make.com is a promising new technique that simplifies data extraction and adds an analysis layer. It's worth exploring if you're looking for a more user-friendly and adaptable approach to web scraping. Here's a breakdown of how it works: | ||
| + | |||
| + | 1. <b>Taking a Screenshot: </b>Make.com itself can't capture screenshots directly. You'll need a third-party service like Dumpling.ai to grab an image of the target webpage. | ||
| + | |||
| + | 2. <b>GPT-4o Analysis: </b>This is where Make.com comes in. You can use a module like "Chat GPT" (assuming it offers GPT-4o access) and feed the screenshot into the system. | ||
| + | |||
| + | 3. <b>Extracting Data with Prompts: </b>Here's the cool part. You provide GPT-4o with instructions phrased as prompts. These prompts tell the model what kind of data to extract from the screenshot. | ||
| + | |||
| + | For instance, you could prompt GPT-4o to "extract all cryptocurrency prices and the fear and greed index" from a screenshot of CoinMarketCap. | ||
| + | |||
| + | 4. <b>Structured Output: </b>GPT-4o doesn't just provide raw text; it can interpret the webpage structure and return the data in a structured format, like JSON. This makes it easier to use the extracted data in other parts of your Make.com automation. | ||
| + | |||
| + | Benefits of Vision-based Scraping: | ||
| + | |||
| + | * <b>Reduced Coding: </b>Compared to traditional scraping methods that rely on parsing HTML, this approach is more user-friendly and requires minimal coding. | ||
| + | * <b>Adaptability: </b>GPT-4o can handle complex website layouts that might be challenging for traditional methods. | ||
| + | * <b>Data Analysis: </b>GPT-4o goes beyond just extracting data. It can also analyze the information and provide insights based on your prompts. | ||
| + | |||
| + | Things to Consider: | ||
| + | |||
| + | * <b>Limited Availability: </b>GPT-4o access might be limited or require specific subscriptions depending on the platform you use (e.g., Chat GPT). | ||
| + | * <b>Accuracy: </b> While powerful, GPT-4o might still require some fine-tuning of prompts to ensure accurate data extraction, especially for intricate websites. | ||
| + | |||
| + | <youtube>sO95nlo9MoA</youtube> | ||
| + | <youtube>Wr-K6M-MM_U</youtube> | ||
| + | |||
| + | = <span id="Image to Image"></span>Image to Image = | ||
| + | * [https://extrapolate.app/ <b>Extrapolate</b>] ... See how well you age with AI, curious how you'll look in 10 years? 20 years? When you're 90? Upload a photo and find out! | ||
| + | |||
| + | <youtube>mqXhFcioY8E</youtube> | ||
| + | |||
| + | |||
| + | * [https://scribblediffusion.com/ <b>Scribble Diffusion</b>] ... turns any hand sketches into images; sketch anything you want, provide a small description | ||
| + | |||
| + | <youtube>KjhNupwi3Z4</youtube> | ||
= <span id="Video Synthesis"></span>Video Synthesis = | = <span id="Video Synthesis"></span>Video Synthesis = | ||
| − | + | ||
* [https://arstechnica.com/gaming/2016/06/an-ai-wrote-this-movie-and-its-strangely-moving/ Sunspring - Movie written by algorithm] | * [https://arstechnica.com/gaming/2016/06/an-ai-wrote-this-movie-and-its-strangely-moving/ Sunspring - Movie written by algorithm] | ||
| − | * [https://techcrunch.com/2022/12/30/quickvid-uses-ai-to-generate-short-form-videos-complete-with-voiceovers/?guccounter=1&guce_referrer=aHR0cHM6Ly9uZXdzLmdvb2dsZS5jb20v&guce_referrer_sig=AQAAAEwE0tqGxIcqK_DfHJooUReUtIUuaCdMlS6Y8FbkJKEwEU-PEDX2x13YNK9eTo-oWPCoNVkdeWNZz2QgNkwgecGDR_QVbcsienUZO2eXBbpi8cnM4-e7iJowxRqVV7b96rjMgeY1GtDz7d_0gpXCKdOJFuH1FIvN-3B3u4oBE2vl QuickVid uses AI to generate short-form videos, complete with voiceovers | Kyle Wiggers - TechCrunch] - It's a demonstration of what's possible with today's AI -- and the outstanding challenges.... QuickVid chooses a background video from a library, writes a script and keywords, overlays images generated by [https://openai.com/dall-e-2/ DALL·E] 2 and adds a synthetic voiceover and background music from YouTube’s royalty-free music library. | + | * [https://www.npr.org/2024/05/08/1250073041/chatgpt-openai-ai-erotica-porn-nsfw ChatGPT maker OpenAI exploring how to 'responsibly' make AI erotica | Bobby Allyn - NPR]... [https://cdn.openai.com/spec/model-spec-2024-05-08.html#dont-respond-with-nsfw-content Document] intended to gather feedback on the rules for its products |
| + | * Tools | ||
| + | ** [https://techcrunch.com/2022/12/30/quickvid-uses-ai-to-generate-short-form-videos-complete-with-voiceovers/?guccounter=1&guce_referrer=aHR0cHM6Ly9uZXdzLmdvb2dsZS5jb20v&guce_referrer_sig=AQAAAEwE0tqGxIcqK_DfHJooUReUtIUuaCdMlS6Y8FbkJKEwEU-PEDX2x13YNK9eTo-oWPCoNVkdeWNZz2QgNkwgecGDR_QVbcsienUZO2eXBbpi8cnM4-e7iJowxRqVV7b96rjMgeY1GtDz7d_0gpXCKdOJFuH1FIvN-3B3u4oBE2vl QuickVid uses AI to generate short-form videos, complete with voiceovers | Kyle Wiggers - TechCrunch] - It's a demonstration of what's possible with today's AI -- and the outstanding challenges.... QuickVid chooses a background video from a library, writes a script and keywords, overlays images generated by [https://openai.com/dall-e-2/ DALL·E] 2 and adds a synthetic voiceover and background music from YouTube’s royalty-free music library. | ||
| + | ** [https://mashable.com/article/ai-music-videos Watch the first major music video generated by OpenAI’s Sora | Elizabeth de Luna - Mashable] | ||
| + | ** [https://www.synthesia.io/ Synthesia] ... Create professional videos without mics, cameras, or actors, turn your text into high-quality videos with AI avatars and voiceovers — in over 120 languages. | ||
| + | ** [https://www.papercup.com/ Papercup] ... go global with your existing video content using AI dubbing. | ||
| + | ** [https://www.viggle.ai/ Viggle] | ||
| + | ** [https://runwayml.com/ RunwayML] | ||
| + | ** [https://www.capcut.com/ CapCut] | ||
| + | ** [https://noisee.ai/ Noisee] | ||
| + | ** [https://app.pixverse.ai/ PixVerse] | ||
| + | ** [https://app.haiper.ai/ Haiper] | ||
| + | ** [https://pika.art/ Pika] | ||
| + | <youtube>mKcfo4zbcUA</youtube> | ||
<youtube>Wf1UFz2jAJU</youtube> | <youtube>Wf1UFz2jAJU</youtube> | ||
| − | + | ||
== <span id="Text-to-Video"></span>Text-to-Video == | == <span id="Text-to-Video"></span>Text-to-Video == | ||
* [https://www.digitaltrends.com/computing/chatgpt-4-launching-next-week-ai-videos/ Microsoft will launch ChatGPT 4 with AI videos next week | Alex Blake - Digital Trends] ... will have multimodal models | * [https://www.digitaltrends.com/computing/chatgpt-4-launching-next-week-ai-videos/ Microsoft will launch ChatGPT 4 with AI videos next week | Alex Blake - Digital Trends] ... will have multimodal models | ||
| + | * [https://www.heygen.com/ HeyGen] ... includes voice cloning and text-to-speech | ||
* [https://www.d-id.com/ D-ID] ... Digital People - Create and interact with talking avatars at the touch of a button, to increase engagement and reduce costs. | * [https://www.d-id.com/ D-ID] ... Digital People - Create and interact with talking avatars at the touch of a button, to increase engagement and reduce costs. | ||
| + | * [https://makeavideo.studio/ Make-A-Video |] [[Meta]] ... generates videos from text, add motion to a single image or fill-in the in-between motion to two images. | ||
| + | * [https://imagen.research.google/ Imagen |] [[Google]] ... pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis | ||
| + | * [https://runwayml.com/ runwayML] ... workflows, including video editing, image generation, and machine learning model training | ||
| + | |||
| + | <youtube>qpQfad-B9-0</youtube> | ||
| + | |||
| + | |||
| + | === <span id="Veo"></span>Veo === | ||
| + | * [https://arstechnica.com/information-technology/2024/05/google-unveils-veo-a-high-definition-ai-video-generator-that-may-rival-sora/ Google unveils Veo, a high-definition AI video generator that may rival Sora | Ben Edwards - ARS Technica]... [[Google]]'s video-synthesis model creates minute-long 1080p videos from written prompts. | ||
| + | |||
| + | Veo is a powerful AI video generator developed by Google DeepMind. It can create high-quality, 1080p resolution videos in various cinematic styles based on text descriptions and even image or video prompts you provide. Imagine describing a fast-paced journey through a neon-lit futuristic cityscape, and Veo can bring that vision to life in a video exceeding a minute long. It can also understand and follow up on additional prompts to refine your video further | ||
| + | |||
| + | <youtube>ZMuA2uyIcqM</youtube> | ||
| + | |||
| + | === <span id="Pika"></span>Pika === | ||
| + | * [https://pika.art/ Pika] | ||
| + | * [https://elevenlabs.io/ Eleven Labs] ... brings lifelike voices for storytelling | ||
| + | |||
| + | AI video wars heat up as Pika adds Lip Sync powered by [https://elevenlabs.io/ Eleven Labs] | ||
| + | |||
| + | <youtube>hjGYM38jFI8</youtube> | ||
| + | |||
| + | === <span id="Krea"></span>Krea === | ||
| + | * [https://www.krea.ai/ Krea] | ||
| + | |||
| + | <youtube>-wGb1WvyfrQ</youtube> | ||
| + | |||
| + | === <span id="Pika"></span>Pika === | ||
| + | * [https://pika.art/ Pika] | ||
| + | * [https://elevenlabs.io/ Eleven Labs] ... brings lifelike voices for storytelling | ||
| + | |||
| + | AI video wars heat up as Pika adds Lip Sync powered by [https://elevenlabs.io/ Eleven Labs] | ||
| + | |||
| + | <youtube>hjGYM38jFI8</youtube> | ||
| + | |||
| + | |||
| + | === <span id="Picasso"></span>Picasso === | ||
| + | [https://www.nvidia.com/en-us/gpu-cloud/picasso/ Picasso |] [[NVIDIA]] a cloud service that allows you to build generative AI-powered visual apps, is available. Software creators, service providers, and enterprises can run inference on models, train NVIDIA Edify foundation model models on proprietary data, and start from pre-trained models to create image, video, or 3D content from text prompts. | ||
| + | |||
| + | <youtube>F_dSq1IT6ws</youtube> | ||
| + | |||
| + | <img src="https://miro.medium.com/v2/resize:fit:828/0*PZLmtmKRFdVdAc5M.gif" width="600"> | ||
| + | |||
| + | |||
| + | === Watch Me Forever === | ||
| + | * [https://www.twitch.tv/watchmeforever Watch Me Forever Show | Twitch] | ||
| + | * [https://www.polygon.com/23582937/ai-seinfeld-twitch-stream AI generated Seinfeld is taking over Twitch | Polygon] | ||
| + | |||
| + | <b>“Watch Me Forever”</b> is a channel on Twitch that streams AI-generated content. One of their streams is an AI-generated version of Seinfeld. The Twitch channel uses generative artificial intelligence to create an infinite stream of content. For example, their AI-generated version of Seinfeld called “Nothing, Forever” uses text generation from [[OpenAI]]’s GPT-3 models and speech from Azure Cognitive Services. They also have proprietary generative algorithms that they collectively call the ‘director,’ which is responsible for making sure all the individual pieces come together into a whole. | ||
| + | |||
| + | |||
| + | <youtube>yn0iVOtr6FE</youtube> | ||
== <span id="Image-to-Video"></span>Image-to-Video == | == <span id="Image-to-Video"></span>Image-to-Video == | ||
| Line 61: | Line 377: | ||
* [https://www.myheritage.com/deep-nostalgia Deep Nostalgia™] | * [https://www.myheritage.com/deep-nostalgia Deep Nostalgia™] | ||
| − | + | "The draw here is that visual imagery is visceral and compelling and we respond to it," says Hany Farid, associate dean and head of the School of Information at UC Berkeley. "We are visual beings. When you see your grandmother or Mark Twain come alive, there's something fascinating about it." [https://www.cnn.com/2021/03/02/business/deep-nostalgia-myhertiage-ai-learning-trnd/index.html A new program can animate old photos. But there's nothing human about artificial intelligence | AJ Willingham - CNN] | |
| + | |||
| + | [https://www.myheritage.com/deep-nostalgia Deep Nostalgia™] allows you to animate the faces in your old family photos. Utilizing state-of-the-art deep learning technology licensed by MyHeritage from D-ID, [https://www.myheritage.com/deep-nostalgia Deep Nostalgia™] creates high-quality, realistic video footage from still photos. | ||
| + | |||
| − | <img src="https://education.myheritage.com/wp-content/uploads/2021/03/603bcfc1a6126557354991.gif" width=" | + | <img src="https://education.myheritage.com/wp-content/uploads/2021/03/603bcfc1a6126557354991.gif" width="400"> |
| − | |||
== Video-to-Video == | == Video-to-Video == | ||
[https://www.youtube.com/results?search_query=Video+Synthesis+artificial+intelligence+deep+learning Youtube search...] | [https://www.youtube.com/results?search_query=Video+Synthesis+artificial+intelligence+deep+learning Youtube search...] | ||
[https://www.google.com/search?q=Video+Synthesis+artificial+intelligence+deep+learning ...Google search] | [https://www.google.com/search?q=Video+Synthesis+artificial+intelligence+deep+learning ...Google search] | ||
| + | |||
<youtube>dVa1xRaHTA0</youtube> | <youtube>dVa1xRaHTA0</youtube> | ||
| Line 76: | Line 395: | ||
<youtube>8AZBuyEuDqc</youtube> | <youtube>8AZBuyEuDqc</youtube> | ||
| − | = Video Editing = | + | = <span id="Video Editing"></span>Video Editing = |
| + | |||
[https://www.youtube.com/results?search_query=video+editing+artificial+intelligence+deep+learning+ML Youtube search...] | [https://www.youtube.com/results?search_query=video+editing+artificial+intelligence+deep+learning+ML Youtube search...] | ||
[https://www.google.com/search?q=video+editing+artificial+intelligence+deep+learning+ML ...Google search] | [https://www.google.com/search?q=video+editing+artificial+intelligence+deep+learning+ML ...Google search] | ||
| Line 94: | Line 414: | ||
* [https://www.jumpdatadriven.com/ Jumptvs] | * [https://www.jumpdatadriven.com/ Jumptvs] | ||
* [https://www.adobe.com/products/premiere.html Adobe Premiere] | * [https://www.adobe.com/products/premiere.html Adobe Premiere] | ||
| − | * [ | + | * [[Video/Image#Runway | Runway]] ... can edit videos in real-time, collaborate, and use more than 30 AI magic tools. |
* [https://levatas.com/ Levatas] | * [https://levatas.com/ Levatas] | ||
* [https://www.banuba.com/ Banuba] | * [https://www.banuba.com/ Banuba] | ||
| Line 102: | Line 422: | ||
<youtube>fmzwcKvj_Wc</youtube> | <youtube>fmzwcKvj_Wc</youtube> | ||
<youtube>4vp36q9z_I4</youtube> | <youtube>4vp36q9z_I4</youtube> | ||
| + | <youtube>oKzAuJRPaIY</youtube> | ||
| + | <youtube>kKlzZW4o5OE</youtube> | ||
| + | |||
| + | |||
| + | |||
| + | = <span id="Captioning"></span>Captioning = | ||
| + | |||
| + | [http://www.youtube.com/results?search_query=Image+Video+to+Text+Captioning+deep+machine+learning+ML Youtube search...] | ||
| + | [http://www.google.com/search?q=Image+Video+to+Text+Captioning+deep+machine+learning+ML ...Google search] | ||
| + | |||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>f2waevH1b6I</youtube> | ||
| + | <b>Image Captioning Through Neural Networks | ||
| + | </b><br>An image captioning model using VGG16 feature extraction (CNN) and LSTM (RNN) neural networks. With [[Python]], [TensorFlow]] and [[Keras]] | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>xKt21ucdBY0</youtube> | ||
| + | <b>Automated Image Captioning with ConvNets and Recurrent Nets | ||
| + | </b><br> [[Creatives#Andrej Karpathy|Andrej Karpathy]] and [[Creatives#Fei-Fei Li| Fei-Fei Li]] ...http://cs.stanford.edu/people/karpathy/sfmltalk.pdf | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>erx9czQsY2Q</youtube> | ||
| + | <b>A Simple Way to Automatically Transcribe Video/Audio to Text | ||
| + | </b><br>Here is how to auto generate subtitles from any video with Google docs. It also works if you want to convert audio to text. Useful for creating subtitles and closed Captions for all your Youtube videos. The trick here is to make the recording and playback devices same. This will give good quality and help you automatically transcribe video to text. | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>2a0OP_8vyXs</youtube> | ||
| + | <b>I compared 3 AI Image Caption Models - GIT vs BLIP vs ViT+GPT2 - Image-to-Text Models | ||
| + | </b><br>I took10 different images to compare GIT, BLIP and ViT+GPT2, 3 state-of-the-art vision+language models. | ||
| + | |||
| + | * GIT: A Generative Image-to-text Transformer for Vision and Language | ||
| + | |||
| + | * BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation | ||
| + | |||
| + | * ViT+GPT2 - Image Captioning using transformers | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>uBzp5xGSZ6o</youtube> | ||
| + | <b>Level Up - Automated Subtitles with AI | ||
| + | </b><br>Welcome to Level Up! the show where we show you how to build solutions hands-on with [[Google]] Cloud Platform. In this episode, Solutions Architect Markku Lepistö will show you how to create subtitles for videos using Cloud AI services. And then how to translate the subtitles to quickly add support for multiple languages! | ||
| + | |||
| + | 00:35 - Example of extracting the dialog as an audio track | ||
| + | 01:15 - Enable Google Cloud AI services | ||
| + | 02:37 - Coding the client app in Python | ||
| + | 09:20 - Reviewing the results | ||
| + | 09:48 - Uploading subtitles to YouTube Studio | ||
| + | 10:44 - Testing the results | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>dJW8JXrrqFU</youtube> | ||
| + | <b>AI-Driven Image Captioning For Inclusive Productivity | ||
| + | </b><br>Advances in hybrid intelligence, deep learning, and related artificial intelligence techniques have provided us with a remarkable opportunity to ensure the future of work will be even more inclusive to more people than ever before. Because the communication and products of work increasingly comprise images—photos, charts, maps, and the like—that are often not accessible, people who are blind or low vision face unique challenges. One promising technology is the automated understanding and captioning of images. [[Microsoft]] Office 365 applications, for example, can use APIs from [[Microsoft]] Azure Cognitive Services to automatically add alt text to images. But there remain many hurdles to making these captions truly useful and usable. In this breakout session, we will explore the state of the art and potential for advancement in automated image captioning, including data capture and curation for training, caption presentation and interactivity, and computer vision. | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| + | {|<!-- T --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>ubpEUksa3v0</youtube> | ||
| + | <b>[[Microsoft]] AI breakthrough in automatic image captioning | ||
| + | </b><br>[[Microsoft]] researchers have built an artificial intelligence system that can generate captions for images that are, in many cases, more accurate than what was previously possible. The breakthrough is a milestone in Microsoft’s push to make its products and services inclusive and accessible to all users. | ||
| + | |} | ||
| + | |<!-- M --> | ||
| + | | valign="top" | | ||
| + | {| class="wikitable" style="width: 550px;" | ||
| + | || | ||
| + | <youtube>y2BaTt1fxJU</youtube> | ||
| + | <b>[[Pytorch]] Image Captioning Tutorial | ||
| + | </b><br>In this tutorial we go through how an image captioning system works and implement one from scratch. Specifically we're looking at the caption dataset Flickr8k. There are multiple ways to improve the model: train a larger model (the one used is relatively small), train for longer and improve the model by adding attention similar to this paper: http://arxiv.org/abs/1502.03044. Video of dataset (link in that video description to download the dataset yourself): http://youtu.be/9sHcLvVXsns Support My Channel Through Patreon: http://www.patreon.com/aladdinpersson | ||
| + | |} | ||
| + | |}<!-- B --> | ||
| + | |||
| + | = Style-Based Generator Architecture = | ||
| + | * [https://arxiv.org/abs/1812.04948 A Style-Based Generator Architecture for Generative Adversarial Networks | T. Karras, S. Laine, and T. Aila] | ||
| + | |||
| + | <youtube>kSLJriaOumA</youtube> | ||
| + | |||
| + | = <span id="Runway"></span>Runway = | ||
| + | [https://runwayml.com/ Runway] ... can edit videos in real-time, collaborate, and use more than 30 AI magic tools. | ||
| + | |||
| + | <img src="https://miro.medium.com/v2/resize:fit:828/0*Z4oVtJPSjFyxTUoK.gif" width="400"> | ||
| + | |||
| + | <img src="https://miro.medium.com/v2/resize:fit:750/0*fd4szwOsT26KXxxp.gif" width="400"> | ||
| + | |||
<youtube>ARnf4ilr9Hc</youtube> | <youtube>ARnf4ilr9Hc</youtube> | ||
<youtube>97aRnMU3Cgs</youtube> | <youtube>97aRnMU3Cgs</youtube> | ||
| − | |||
| − | |||
| + | == Tool-related == | ||
| + | [https://www.youtube.com/results?search_query=app+software+face+fake+image+video+artificial+intelligence+deep+learning Youtube search...] | ||
| + | [https://www.google.com/search?q=app+software+face+fake+image+video+deep+machine+learning+ML ...Google search] | ||
| + | |||
| + | * [https://www.reddit.com/r/GifFakes/comments/7xv91x/fakeapp_download_links_and_howto_guide/ FakeApp] | ||
| + | * [https://github.com/iperov/DeepFaceLab DeepFaceLab] | ||
| + | * [https://mrdeepfakes.com/forums/thread-openfaceswap-installation-and-use OpenFaceSwap] | ||
| + | |||
| + | <youtube>XcRgA9DDB14</youtube> | ||
| + | <youtube>yZRuSsyxvos</youtube> | ||
| + | == Image or Video Forgeries == | ||
| + | [https://www.youtube.com/results?search_query=face+fake+FaceForensics+image+video+artificial+intelligence+deep+learning Youtube search...] | ||
| + | [https://www.google.com/search?q=face+fake+FaceForensics+image+video+deep+machine+learning+ML ...Google search] | ||
| + | * [https://niessnerlab.org/projects/roessler2018faceforensics.html FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces | A. Rössler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies & M. Nießner] ...[https://arxiv.org/abs/1803.09179 paper] | ||
| + | <youtube>Tle7YaPkO_k</youtube> | ||
= I built a Secret AI Youtube Channel = | = I built a Secret AI Youtube Channel = | ||
| Line 120: | Line 557: | ||
<youtube>4r-_iW8fmWU</youtube> | <youtube>4r-_iW8fmWU</youtube> | ||
| − | <youtube> | + | <youtube>f2nMIlOAPvs</youtube> |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
Latest revision as of 21:56, 22 April 2025
YouTube ... Quora ...Google search ...Google News ...Bing News
- Video/Image ... Vision ... Enhancement ... Fake ... Reconstruction ... Colorize ... Occlusions ... Predict image ... Image/Video Transfer Learning ... Art ... Photography
- End-to-End Speech ... Synthesize Speech ... Speech Recognition ... Music
- Humor ... Writing/Publishing ... Storytelling ... Broadcast ... Journalism/News ... Podcasts ... Books, Radio & Movies - Exploring Possibilities
- Artificial Intelligence (AI) ... Generative AI ... Machine Learning (ML) ... Deep Learning ... Neural Network ... Reinforcement ... Learning Techniques
- Conversational AI ... ChatGPT | OpenAI ... Bing/Copilot | Microsoft ... Gemini | Google ... Claude | Anthropic ... Perplexity ... You ... phind ... Ernie | Baidu
- Immersive Reality ... Metaverse ... Omniverse ... Transhumanism ... Religion
- Prompt Engineering (PE) ... PromptBase ... Prompt Injection Attack
- How do I leverage Artificial Intelligence (AI)? ... Reading/Glossary ... Courses/Certs ... Education ... Help Wanted
- Embedding ... Fine-tuning ... RAG ... Search ... Clustering ... Recommendation ... Anomaly Detection ... Classification ... Dimensional Reduction. ...find outliers
- Rekognition Video
- DeepLens - deep learning enabled video camera
- Gaming ... Game-Based Learning (GBL) ... Security ... Generative AI ... Games - Metaverse ... Quantum ... Game Theory ... Design
- Recurrent Neural Network (RNN)
- Long Short-Term Memory (LSTM)
- ImageBind | Meta
- Papercup; go global with your existing video content using AI dubbing
- Is Artificial Intelligence Poised to Revolutionize Hollywood?
- "Trashy Video Classifier" An Artificial Intelligence System by Google That Cleans up YouTube Homepage | Chris Apostle - Digital Information World
- Hey Netflix, Here’s How You Can Use AI To Optimize Content Production | Pavel Saskovec - Cognitive Mill
- Netflix Faces Backlash After Using AI Software To Create Backgrounds For An Animated Short | Jamie Lang - Cartoon Brew
- Researchers translate brain waves into scarily accurate images using Stable Diffusion AI | Katie Wickens - PC Gamer ... Researchers have been able to use Stable Diffusion models to reconstruct images from human brain waves.
- Craiyon
- Tom Hanks says with AI he could appear in movies after death; star’s projects that have already used the tech | Caroline Thayer - Yahoo News
- VideoPoet | Google ... A large language model for zero-shot video generation
- The Oscars officially don’t care if films use AI | Wes Davis - The Verge ... using AI doesn’t, on its own, hurt a movie’s chances
Contents
Look here
Text to Image
- Bing Create | Microsoft ... create images from words with AI
- Designer | Microsoft ... focusing on designs; including posters, illustrations, and campaign artwork
Ideogram AI
YouTube ... Quora ...Google search ...Google News ...Bing News
Ideogram AI is a generative AI tool that creates photorealistic images and artworks using AI with reliable typography within images. It is a free-to-use tool that was launched in August 2023 by a team of former Google Brain researchers. Ideogram AI works by combining a pre-trained language model with a denoising diffusion model. The language model is responsible for generating the text, while the denoising diffusion model is responsible for generating the image. The two models work together to create images that are both realistic and meaningful. One of the key features of Ideogram AI is its ability to generate text within images. This is something that other generative AI tools, such as DALL-E 2 and Midjourney, have not been able to do as reliably. Ideogram AI can generate text in a variety of fonts, sizes, and styles, and it can also combine text with other visual elements, such as icons and illustrations.
Firefly
YouTube ... Quora ...Google search ...Google News ...Bing News
Adobe Firefly is a creative generative AI engine that is part of Adobe Sensei’s Generative AI services. It is available in Photoshop (beta), Illustrator, Adobe Express, and on the web. With Firefly, you can dream it, type it, and see it. You can use text prompts to generate custom vectors, brushes, textures, images, videos, and 3D objectsFirefly includes various image modification tools such as content type, color, tone, lighting, and composition.
- Generate Images ... Generate images from a detailed text description

- Generate Fill ... Use a brush to remove objects, or paint in new ones from text descriptions

- Text Effects ... Apply styles or textures to text with a text prompt.
- Generative recolor ... Generate color variations of your vector artwork from a detailed text description.

Stable Diffusion
YouTube ... Quora ...Google search ...Google News ...Bing News
- Try Stable Diffusion here
- Stability AI
- Stable Diffusion with ControlNet
- Stable Diffusion | DreamStudio Lite beta
- Runway ... can edit videos in real-time, collaborate, and use more than 30 AI magic tools.
- LAION... Large-scale Artificial Intelligence Open Network
- EleutherAI
- Heidelberg University
A latent text-to-image diffusion model capable of generating photo-realistic images given any text input. Designing and implementing solutions using collective intelligence and augmented technology.
DALL-E
YouTube ... Quora ...Google search ...Google News ...Bing News
- OpenAI GPT Builder
- DALL·E 3 on Bing
- DALL·E 2 | OpenAI ...OpenAI’s DALL-E 2 AI image generator can now edit pictures, too | Adi Robertson - The Verge
- VALL-E ... Zero-Shot Text to Speech Synthesizer
DALL·E is a AI system that can create realistic images and art from a description in natural language. We currently support the ability, given a prommpt, to create a new image with a certain size, edit an existing image, or create variations of a user provided image.
The current DALL·E model available through our API is the 2nd iteration of DALL·E with more realistic, accurate, and 4x greater resolution images than the original model. You can try it through the our Labs interface or via the API.
MidJourney
YouTube ... Quora ...Google search ...Google News ...Bing News
Runway Now Turns Midjourney Images into Videos: Generative video darling Runway has released a Gen 2 update with a feature that has really captured AI Twitter’s attention: the ability to automatically animate Midjourney images. This was a feature Pika Labs had also previously released, showing how competition is driving things forward.
Image GPT
YouTube ... Quora ...Google search ...Google News ...Bing News
Image GPT is a generative AI model developed by OpenAI that uses a transformer architecture, similar to that of the GPT models for text, but adapted to handle images. Instead of generating text, Image GPT predicts pixel values in an autoregressive manner, allowing it to create, complete, or modify images.
Features:
- Pixel Autoregression: Image GPT generates images pixel-by-pixel, predicting each pixel's value based on previously generated ones, similar to how GPT models predict the next word in a sequence.
- Unsupervised Pretraining: The model is trained on a large dataset of images without specific labels, learning general representations of visual data. This unsupervised approach allows it to understand a wide variety of image types and patterns.
- Creative Image Generation: Image GPT can produce new and creative images by sampling from its learned distribution of pixel patterns.
- Image Completion: The model can fill in missing parts of an image or extend an existing image based on the learned patterns.
- Generalization Across Domains: Despite being trained without explicit supervision, Image GPT can generalize to tasks like image classification when fine-tuned or combined with labeled data.
- Compatibility with Transformer Architecture: Built on the transformer architecture, Image GPT benefits from its scalability and ability to model long-range dependencies effectively, even in images.
NVIDIA Canvas
YouTube ... Quora ...Google search ...Google News ...Bing News
AI-powered tool designed to help artists and creators quickly generate realistic landscape images. It uses artificial intelligence to turn simple brushstrokes into photorealistic landscapes, making it a valuable resource for concept artists, designers
Imagen
YouTube ... Quora ...Google search ...Google News ...Bing News
Imagen is an AI system developed by Google AI that can create photorealistic images from text descriptions. It is still under development, but it has already surpassed other text-to-image models in terms of image quality and diversity. Imagen works by first encoding the text description into a sequence of numbers. This sequence is then used to generate a low-resolution image. The image is then gradually refined until it reaches the desired resolution. Imagen is trained on a massive dataset of text and images. This dataset includes text descriptions of images, as well as the actual images themselves. This allows Imagen to learn the relationship between text and images, and to generate images that are consistent with the text descriptions. Imagen is still under development, but it has the potential to revolutionize the way we create and interact with images. It could be used to create new forms of art, to generate realistic images for use in movies and video games, and to help people with visual impairments see the world around them.
Recraft
YouTube ... Quora ...Google search ...Google News ...Bing News
Recraft is a generative AI tool that allows users to create customized images or graphics with ease. It is designed to provide intuitive visual content creation for tasks like making social media graphics, custom illustrations, product mockups, and other creative assets. Recraft V3, also known as Red Panda AI, is a state-of-the-art text-to-image generation model developed by Recraft, a London-based AI company specializing in high-quality graphic design tools. This model has gained significant attention for its ability to produce detailed and photorealistic images from textual descriptions, making it a valuable tool for designers, artists, and creatives.
Text to Presentation
These tools use AI to automate the process of creating presentations, making it easier for users to focus on their content and ideas. They typically offer a variety of features, such as:
- A library of pre-designed templates
- An AI-powered content assistant that can help with formatting, design, and style
- The ability to embed images, videos, and other media
- Real-time collaboration tools
- Analytics to track presentation views and engagement
These tools can be a valuable resource for anyone who needs to create presentations, but they are particularly useful for professionals who need to create polished and professional presentations on a regular basis. Here is a brief overview of each tool:
- Gamma AI is a cloud-based tool that uses AI to create presentations that are both visually appealing and engaging. It offers a variety of templates and features, and it can be used to create presentations for a variety of purposes.
- Tome is a web-based tool that allows users to create presentations in a more traditional way, but it also offers some AI-powered features, such as the ability to generate content ideas and suggestions for design.
- Beautiful.ai is a popular AI presentation tool that offers a wide range of features, including a large library of templates, an AI-powered content assistant, and the ability to collaborate with others on presentations.
- Simplified is a more general-purpose productivity tool that can be used to create presentations, documents, and other types of content. It offers a variety of features, including a drag-and-drop editor, a library of templates, and the ability to collaborate with others.
These presentation tools that helps you create presentations, documents, and webpages quickly and easily. It uses a variety of machine learning algorithms to understand your content and generate visually appealing and engaging presentations. The tools work by first asking you to provide a brief description of your presentation. This can be a few sentences or a few paragraphs. The tool will then use this description to generate a presentation outline. The outline will include the main points of your presentation, as well as the supporting evidence. Once the outline is generated, the tool will then begin to create the presentation slides. It will use its machine learning algorithms to select the appropriate images, graphics, and fonts for each slide. It will also automatically format the text and arrange the elements on the slide in a visually appealing way. The tool can also be used to create documents and webpages. The process is similar to creating a presentation, but you will need to provide more detailed instructions for the tool. For example, you will need to specify the document or webpage layout, the font styles, and the colors.
Image to Content Analysis: Vision-based Web Scraping
Vision-based web scraping with GPT-4o in Make.com is a new approach that leverages the power of AI to extract data from websites. Overall, vision-based web scraping with GPT-4o in Make.com is a promising new technique that simplifies data extraction and adds an analysis layer. It's worth exploring if you're looking for a more user-friendly and adaptable approach to web scraping. Here's a breakdown of how it works:
1. Taking a Screenshot: Make.com itself can't capture screenshots directly. You'll need a third-party service like Dumpling.ai to grab an image of the target webpage.
2. GPT-4o Analysis: This is where Make.com comes in. You can use a module like "Chat GPT" (assuming it offers GPT-4o access) and feed the screenshot into the system.
3. Extracting Data with Prompts: Here's the cool part. You provide GPT-4o with instructions phrased as prompts. These prompts tell the model what kind of data to extract from the screenshot.
For instance, you could prompt GPT-4o to "extract all cryptocurrency prices and the fear and greed index" from a screenshot of CoinMarketCap.
4. Structured Output: GPT-4o doesn't just provide raw text; it can interpret the webpage structure and return the data in a structured format, like JSON. This makes it easier to use the extracted data in other parts of your Make.com automation.
Benefits of Vision-based Scraping:
- Reduced Coding: Compared to traditional scraping methods that rely on parsing HTML, this approach is more user-friendly and requires minimal coding.
- Adaptability: GPT-4o can handle complex website layouts that might be challenging for traditional methods.
- Data Analysis: GPT-4o goes beyond just extracting data. It can also analyze the information and provide insights based on your prompts.
Things to Consider:
- Limited Availability: GPT-4o access might be limited or require specific subscriptions depending on the platform you use (e.g., Chat GPT).
- Accuracy: While powerful, GPT-4o might still require some fine-tuning of prompts to ensure accurate data extraction, especially for intricate websites.
Image to Image
- Extrapolate ... See how well you age with AI, curious how you'll look in 10 years? 20 years? When you're 90? Upload a photo and find out!
- Scribble Diffusion ... turns any hand sketches into images; sketch anything you want, provide a small description
Video Synthesis
- Sunspring - Movie written by algorithm
- ChatGPT maker OpenAI exploring how to 'responsibly' make AI erotica | Bobby Allyn - NPR... Document intended to gather feedback on the rules for its products
- Tools
- QuickVid uses AI to generate short-form videos, complete with voiceovers | Kyle Wiggers - TechCrunch - It's a demonstration of what's possible with today's AI -- and the outstanding challenges.... QuickVid chooses a background video from a library, writes a script and keywords, overlays images generated by DALL·E 2 and adds a synthetic voiceover and background music from YouTube’s royalty-free music library.
- Watch the first major music video generated by OpenAI’s Sora | Elizabeth de Luna - Mashable
- Synthesia ... Create professional videos without mics, cameras, or actors, turn your text into high-quality videos with AI avatars and voiceovers — in over 120 languages.
- Papercup ... go global with your existing video content using AI dubbing.
- Viggle
- RunwayML
- CapCut
- Noisee
- PixVerse
- Haiper
- Pika
Text-to-Video
- Microsoft will launch ChatGPT 4 with AI videos next week | Alex Blake - Digital Trends ... will have multimodal models
- HeyGen ... includes voice cloning and text-to-speech
- D-ID ... Digital People - Create and interact with talking avatars at the touch of a button, to increase engagement and reduce costs.
- Make-A-Video | Meta ... generates videos from text, add motion to a single image or fill-in the in-between motion to two images.
- Imagen | Google ... pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis
- runwayML ... workflows, including video editing, image generation, and machine learning model training
Veo
- Google unveils Veo, a high-definition AI video generator that may rival Sora | Ben Edwards - ARS Technica... Google's video-synthesis model creates minute-long 1080p videos from written prompts.
Veo is a powerful AI video generator developed by Google DeepMind. It can create high-quality, 1080p resolution videos in various cinematic styles based on text descriptions and even image or video prompts you provide. Imagine describing a fast-paced journey through a neon-lit futuristic cityscape, and Veo can bring that vision to life in a video exceeding a minute long. It can also understand and follow up on additional prompts to refine your video further
Pika
- Pika
- Eleven Labs ... brings lifelike voices for storytelling
AI video wars heat up as Pika adds Lip Sync powered by Eleven Labs
Krea
Pika
- Pika
- Eleven Labs ... brings lifelike voices for storytelling
AI video wars heat up as Pika adds Lip Sync powered by Eleven Labs
Picasso
Picasso | NVIDIA a cloud service that allows you to build generative AI-powered visual apps, is available. Software creators, service providers, and enterprises can run inference on models, train NVIDIA Edify foundation model models on proprietary data, and start from pre-trained models to create image, video, or 3D content from text prompts.

Watch Me Forever
“Watch Me Forever” is a channel on Twitch that streams AI-generated content. One of their streams is an AI-generated version of Seinfeld. The Twitch channel uses generative artificial intelligence to create an infinite stream of content. For example, their AI-generated version of Seinfeld called “Nothing, Forever” uses text generation from OpenAI’s GPT-3 models and speech from Azure Cognitive Services. They also have proprietary generative algorithms that they collectively call the ‘director,’ which is responsible for making sure all the individual pieces come together into a whole.
Image-to-Video
Youtube search... ...Google search
"The draw here is that visual imagery is visceral and compelling and we respond to it," says Hany Farid, associate dean and head of the School of Information at UC Berkeley. "We are visual beings. When you see your grandmother or Mark Twain come alive, there's something fascinating about it." A new program can animate old photos. But there's nothing human about artificial intelligence | AJ Willingham - CNN
Deep Nostalgia™ allows you to animate the faces in your old family photos. Utilizing state-of-the-art deep learning technology licensed by MyHeritage from D-ID, Deep Nostalgia™ creates high-quality, realistic video footage from still photos.
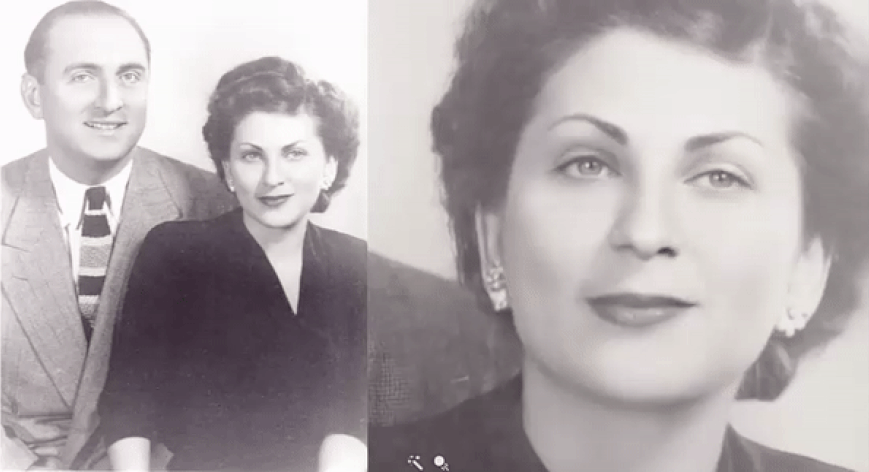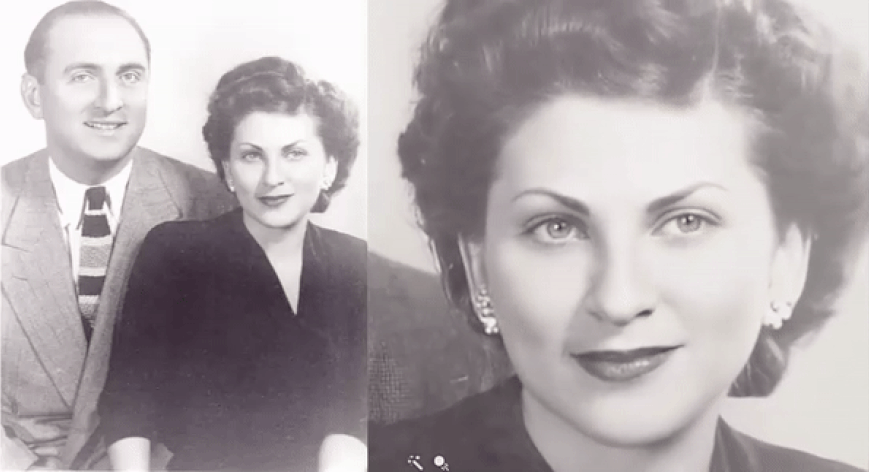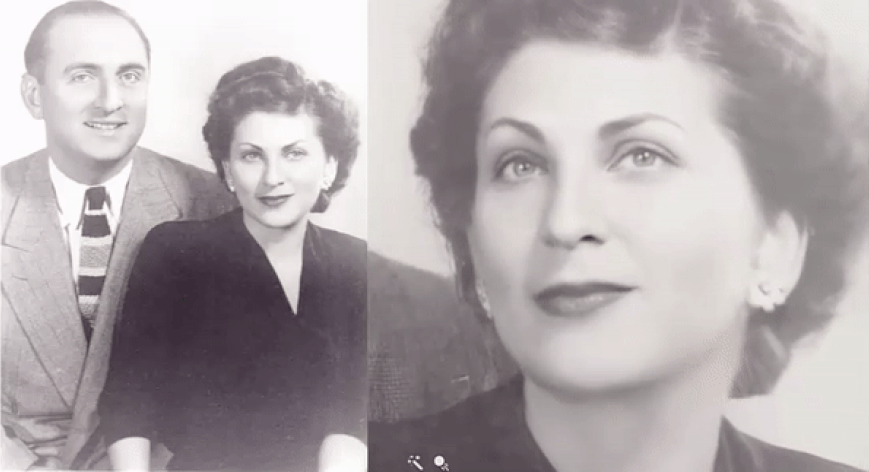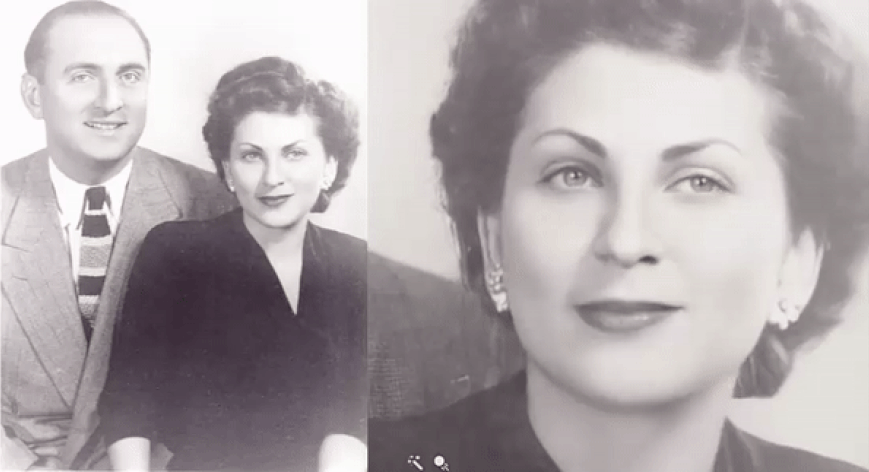
Video-to-Video
Youtube search... ...Google search
Video Editing
Youtube search... ...Google search
- Start podcasting with Descript | Descript
- The 10 Best AI Video Editor Tools: Create Better Videos | FindNewAI
- Jumptvs
- Adobe Premiere
- Runway ... can edit videos in real-time, collaborate, and use more than 30 AI magic tools.
- Levatas
- Banuba
In the last few years, artificial intelligence (AI) and machine learning (ML) have both started to feature more prominently in technology. That is especially the case in video editing, where artificial intelligence is being integrated with more and more ways. How Artificial Intelligence is Transforming Video Editing | TechnologyHQ
Captioning
Youtube search... ...Google search
|
|
|
|
|
|
|
|
Style-Based Generator Architecture
Runway
Runway ... can edit videos in real-time, collaborate, and use more than 30 AI magic tools.

Youtube search... ...Google search
Image or Video Forgeries
Youtube search... ...Google search
- FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces | A. Rössler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies & M. Nießner ...paper
I built a Secret AI Youtube Channel
- Katherine AI shorts
- SirajRaval
- Katherine AI - Colaboratory
- Katherine AI Automation Script - Colaboratory
I challenged myself to earn $100 in the first 3 days of starting a secret AI generated Youtube channel! I didn't use any of my existing connections to promote the channel and used AI tools like ChatGPT, MidJourney, and D-ID every step of the way to automate my own job as a Machine Learning Educator. I've open sourced all the code i used because I want more people to do this, AI avatars are going to be on social media alongside humans, building followers and influencing society. Was I successful in my goal? Find out in this video!