Difference between revisions of "Attention"
| Line 42: | Line 42: | ||
<youtube>6l1fv0dSIg4</youtube> | <youtube>6l1fv0dSIg4</youtube> | ||
| + | <youtube>omHLeV1aicw</youtube> | ||
<youtube>q7QP_lfqnQM</youtube> | <youtube>q7QP_lfqnQM</youtube> | ||
<youtube>-_2AF9Lhweo</youtube> | <youtube>-_2AF9Lhweo</youtube> | ||
<youtube>50jHdK0zQgo</youtube> | <youtube>50jHdK0zQgo</youtube> | ||
| − | |||
<youtube>Q57rzaHHO0k</youtube> | <youtube>Q57rzaHHO0k</youtube> | ||
<youtube>W2rWgXJBZhU</youtube> | <youtube>W2rWgXJBZhU</youtube> | ||
Revision as of 06:29, 13 June 2020
YouTube search... ...Google search
- Memory Networks
- Transformers
- Sequence to Sequence (Seq2Seq)
- Recurrent Neural Networks (RNN)
- Autoencoder (AE) / Encoder-Decoder
- Bidirectional Long Short-Term Memory (BI-LSTM) with Attention Mechanism
- Natural Language Processing (NLP)
- Feature Exploration/Learning
- Attention? Attention! | Lilian Weng
- The Illustrated Transformer | Jay Alammar
- Attention in NLP | Kate Loginova - Medium
- Attention Mechanism | Gabriel Loye - FloydHub
Attention mechanisms in neural networks are about memory access. That’s the first thing to remember about attention: it’s something of a misnomer.
Attention networks are a kind of short-term memory that allocates attention over input features they have recently seen. Attention mechanisms are components of memory networks, which focus their attention on external memory storage rather than a sequence of hidden states in a Recurrent Neural Networks (RNN). Memory networks are a little different, but not too. They work with external data storage, and they are useful for, say, mapping questions as input to answers stored in that external memory. That external data storage acts as an embedding that the attention mechanism can alter, writing to the memory what it learns, and reading from it to make a prediction. While the hidden states of a recurrent neural network are a sequence of embeddings, memory is an accumulation of those embeddings (imagine performing max pooling on all your hidden states – that would be like memory). A Beginner's Guide to Attention Mechanisms and Memory Networks | Skymind
The context vector turned out to be a bottleneck for these types of models. It made it challenging for the models to deal with long sentences. A solution was proposed in Bahdanau et al., 2014 and Luong et al., 2015. These papers introduced and refined a technique called “Attention”, which highly improved the quality of machine translation systems. Attention allows the model to focus on the relevant parts of the input sequence as needed. Let’s continue looking at attention models at this high level of abstraction. An attention model differs from a classic sequence-to-sequence model in two main ways: Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) | Jay Alammar
- First, the encoder passes a lot more data to the decoder. Instead of passing the last hidden state of the encoding stage, the encoder passes all the hidden states to the decoder
- Second, an attention decoder does an extra step before producing its output. In order to focus on the parts of the input that are relevant to this decoding time step

![]()
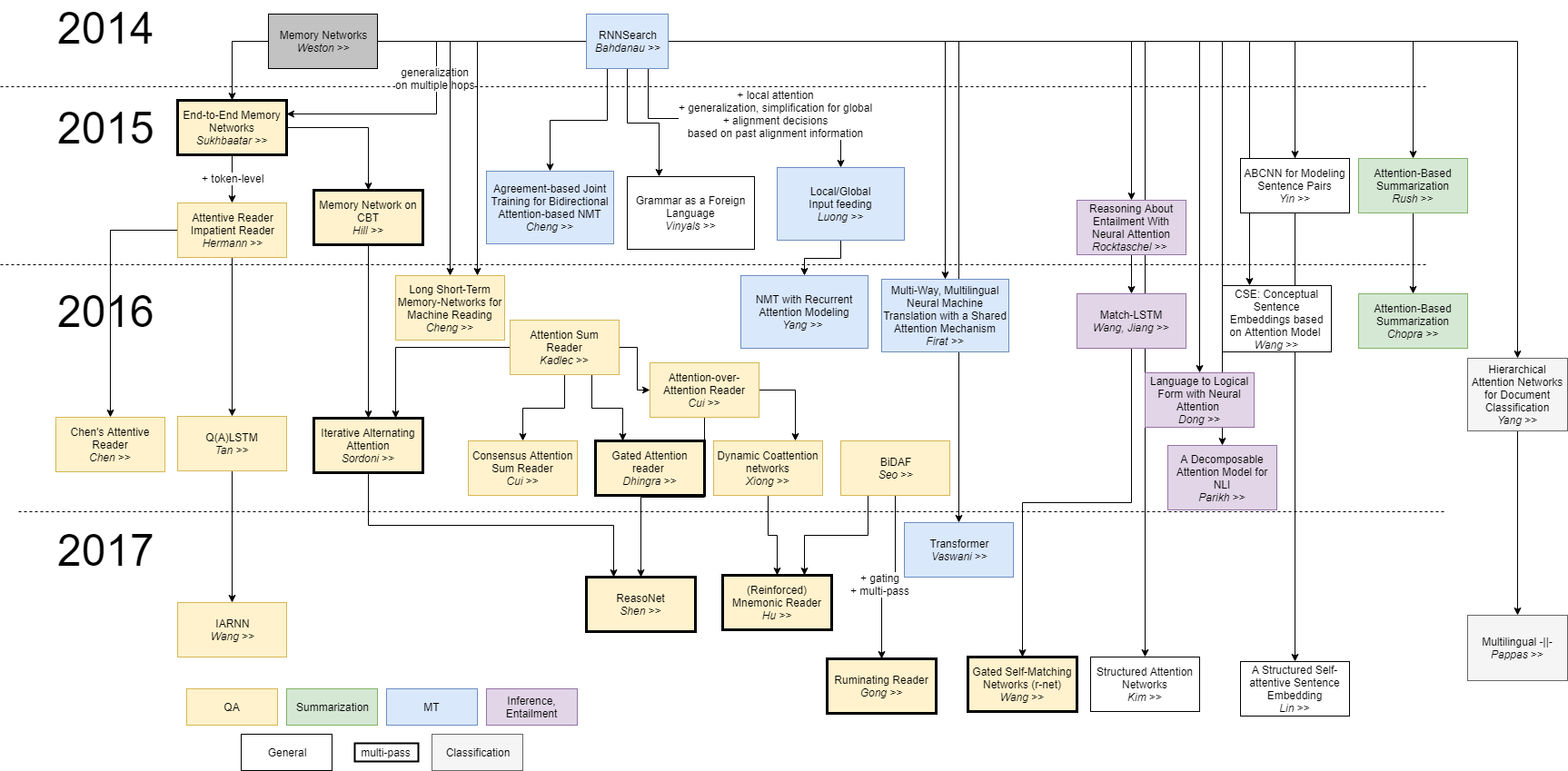
Attention Is All You Need
The dominant sequence transduction models are based on complex Recurrent Neural Network (RNN)) or (Deep) Convolutional Neural Network (DCNN/CNN) in an encoder-decoder (Autoencoder (AE) / Encoder-Decoder} configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Attention Is All You Need | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser, and I. Polosukhin - Google
Making decisions about where to send information
Making decisions about where to send information. An AI Pioneer Explains The Evolution Of Neural Networks | Nichokas Thompson - Wired