XLNet
Youtube search... | ...Google search
- Large Language Model (LLM) ... Natural Language Processing (NLP) ...Generation ... Classification ... Understanding ... Translation ... Tools & Services
- XLNet: Generalized Autoregressive Pretraining for Language Understanding, Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. Salakhutdinov, and Q. Le, June 2019
- What is XLNet and why It outperforms BERT | BrambleXu - Towards Data Science
- Paper Dissected: “XLNet: Generalized Autoregressive Pretraining for Language Understanding” Explained | Machine Learning Explained
- Large Language Model (LLM) ... Natural Language Processing (NLP) ... Generation ... Classification ... Understanding ... Translation ... Tools & Services
- XLNet combines the best of:
- Autoregressive; such as Bidirectional Long Short-Term Memory (BI-LSTM), but XLNet uses Self-Attention instead of Long Short-Term Memory (LSTM) and 'permutations' on both sides of the bidirectional scan
- Attention Mechanism ...Transformer Model ...Generative Pre-trained Transformer (GPT)
- Autoencoder (AE) / Encoder-Decoder such as autoencoding denoiser of Bidirectional Encoder Representations from Transformers (BERT) by integrating methods from Transformer-XL
- 7 Leading Language Models for NLP in 2020 | Mariya Yao - Topbots
XLNet is a new unsupervised language representation learning method based on a novel generalized permutation language modeling objective. Additionally, XLNet employs Transformer-XL as the backbone model, exhibiting excellent performance for language tasks involving long context. Overall, XLNet achieves state-of-the-art (SOTA) results on various downstream language tasks including question answering, natural language inference, Sentiment Analysis, and document ranking. XLNet | zihangdai - GitHub
With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like Bidirectional Encoder Representations from Transformers (BERT) achieves better performance than pretraining approaches based on autoregressive language modeling. However, relying on corrupting the input with masks, Bidirectional Encoder Representations from Transformers (BERT) neglects dependency between the masked positions and suffers from a pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization order and (2) overcomes the limitations of Bidirectional Encoder Representations from Transformers (BERT) thanks to its autoregressive formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into pretraining. Empirically, XLNet outperforms Bidirectional Encoder Representations from Transformers (BERT) on 20 tasks, often by a large margin, and achieves state-of-the-art results on 18 tasks including question answering, natural language inference, Sentiment Analysis, and document ranking. : Generalized Autoregressive Pretraining for Language Understanding | Z. Yang, Z. Dai, Y Yang, J. Carbonell, R. Salakhutdinov, and Q Le
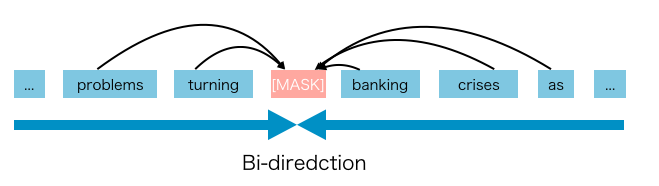
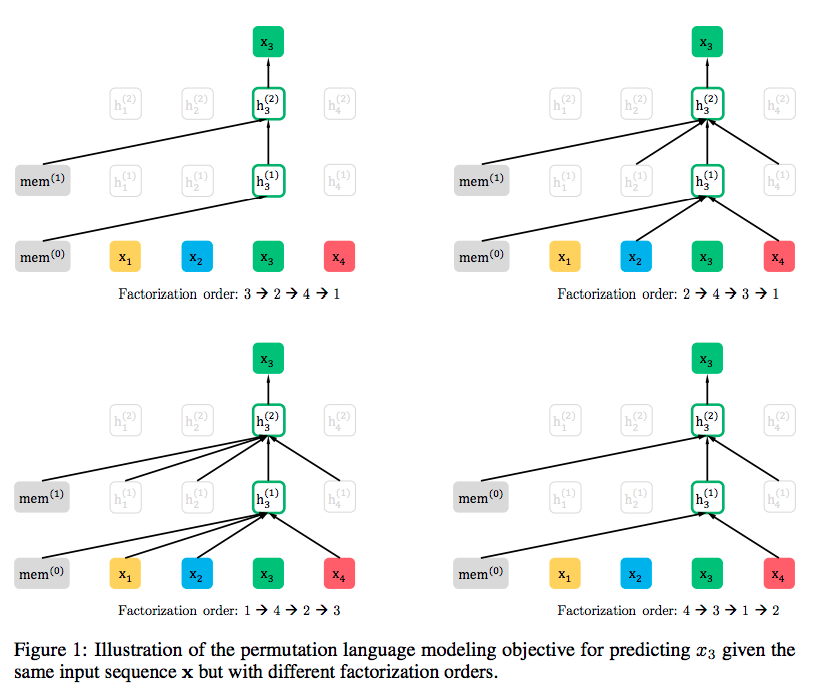
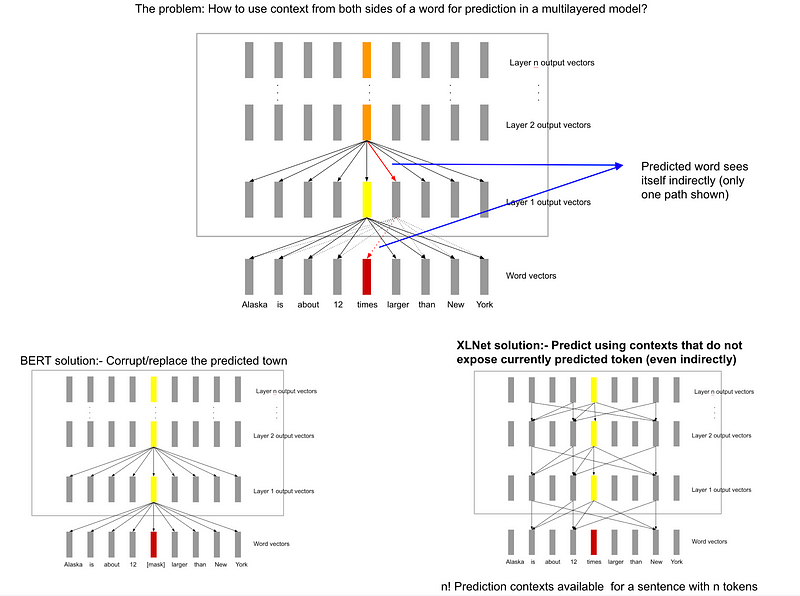
... in order for us to capture the entire bidirectional context in the prediction of the word “times” we need more subsets of the bidirectional context to train the model on, where the word does not see itself.. addresses this by cleverly choosing such subset contexts like the handcrafted one above such that a word does not “see itself” when it is being predicted. ...In summary, by predicting a word at a position in a sentence by using a subset of its bidirectional context, and taking into account the word is itself not seen using the permutation scan rule above, we can avoid a word from seeing itself in a multilayered context. This scheme, however requires that we sample enough permutations so that we make full use of the bidirectional context. XLNet — a clever language modeling solution | Ajit Rajasekharan - Medium