Train Large Language Model (LLM) From Scratch
YouTube ... Quora ...Google search ...Google News ...Bing News
- Large Language Model (LLM) ... Multimodal ... Foundation Models (FM) ... Generative Pre-trained ... Transformer ... GPT-4 ... GPT-5 ... Attention ... GAN ... BERT
- Embedding ... Fine-tuning ... RAG ... Search ... Clustering ... Recommendation ... Anomaly Detection ... Classification ... Dimensional Reduction. ...find outliers
- Python ... GenAI w/ Python ... JavaScript ... GenAI w/ JavaScript ... TensorFlow ... PyTorch
- Prompting vs AI Model Fine-Tuning vs AI Embeddings
- Alpaca
- Training Your Own LLM using privateGPT | Wei-Meng Lee - Medium ... Learn how to train your own language model without exposing your private data to the provider
- How to Train Your Own Language Model: A Step-by-Step Guide | SoulPage
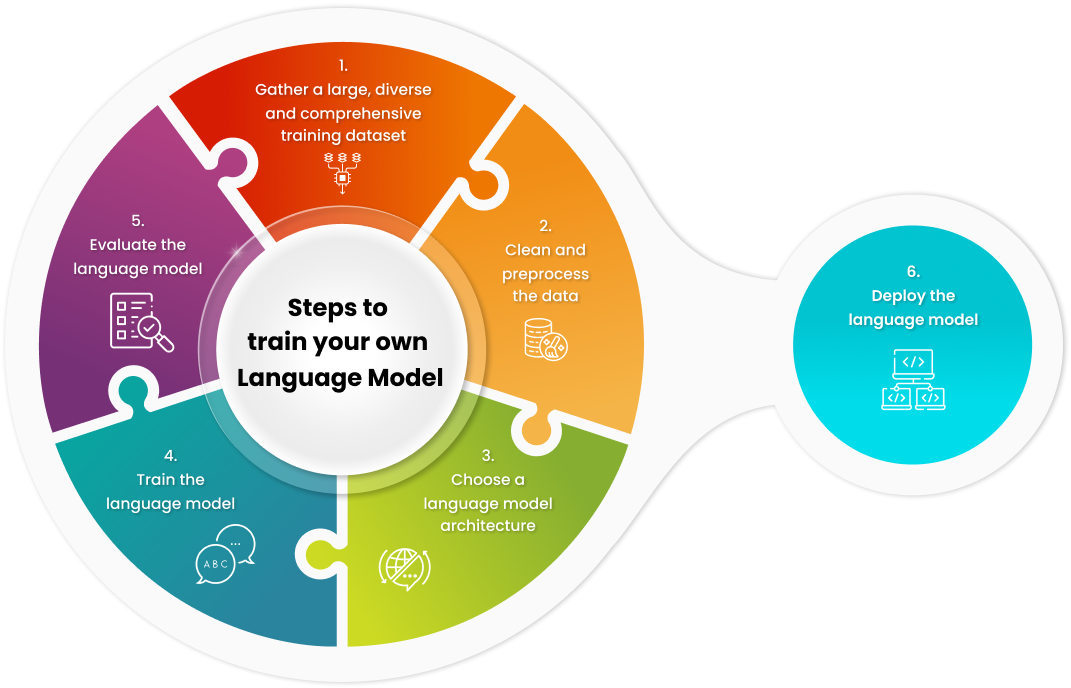
It is important to note that training an Large Language Model (LLM) from scratch is a challenging and resource-intensive task. It requires a large amount of data, a powerful computer, and expertise in deep learning. To train a LLM from scratch, you will need:
- A large and diverse text corpus to train the model on. This can be collected from the internet, books, or other sources.
- A powerful computer with a GPU. LLMs are very computationally expensive to train, so a GPU is essential.
- A deep learning framework such as PyTorch or TensorFlow.
Once you have collected your data and set up your hardware and software, you can follow these steps to train your LLM:
- Preprocess the data. This involves cleaning and formatting the data, including tokenization (breaking text into words or subword units) and handling special characters.
- Choose a model architecture. There are many different LLM architectures available, such as Transformers and Recurrent Neural Network (RNN)s. Choose an architecture that is appropriate for the size and complexity of your dataset.
- Initialize the model parameters. This involves setting the initial values for the weights and biases in the model.
- Train the model. This involves feeding the model the training data and letting it learn the patterns in the data. The training process can take a long time, depending on the size of the dataset and the complexity of the model architecture.
- Evaluate the model. Once the model is trained, you need to evaluate its performance on a held-out test set. This will give you an idea of how well the model will generalize to new data.
If you are new to training LLMs, there are many resources available to help you get started. Here are a few links:
- Hugging Face Transformers: is a popular Python library for training and using LLMs.
- A wide range of pre-trained models for a variety of tasks
- Flexibility to use different frameworks
- Easy to use and extend
- Well-documented and supported
- PyTorch Lightning: is a Python library that makes it easy to train and scale LLMs.
- Automatic model parallelization
- Automatic checkpointing and logging
- Easy to use and extend
- Well-documented and supported
- Google AI Blog: has many articles on training and using LLMs.
- How to train an LLM from scratch
- How to use pre-trained LLMs for different tasks
- How to evaluate the performance of LLMs
'https://soulpageit.com/wp-content/uploads/2023/05/Frame-8.png'