Explainable / Interpretable AI
Youtube search... ...Google search
- Tools:
- AI Verification and Validation
- Journey to Singularity
- Automated Machine Learning (AML) - AutoML
- Explanations based on the Missing: Towards Contrastive Explanations with Pertinent Negatives - IBM
- Why a right to explanation of automated decision-making does not exist in the General Data Protection Regulation | Wachter. S, Mittelstadt, B., Florida, L - University of Oxford, 28 Dec 2016
- This is What Happens When Deep Learning Neural Networks Hallucinate | Kimberley Mok
- H2O Machine Learning Interpretability with H2O Driverless AI
- A New Approach to Understanding How Machines Think | John Pavus
- Visualization
- DrWhy | GitHub collection of tools for Explainable AI (XAI)
AI system produces results with an account of the path the system took to derive the solution/prediction - transparency of interpretation, rationale and justification. 'If you have a good causal model of the world you are dealing with, you can generalize even in unfamiliar situations. That’s crucial. We humans are able to project ourselves into situations that are very different from our day-to-day experience. Machines are not, because they don’t have these causal models. We can hand-craft them but that’s not enough. We need machines that can discover causal models. To some extend it’s never going to be perfect. We don’t have a perfect causal model of the reality, that’s why we make a lot of mistakes. But we are much better off at doing this than other animals.' Yoshua Benjio
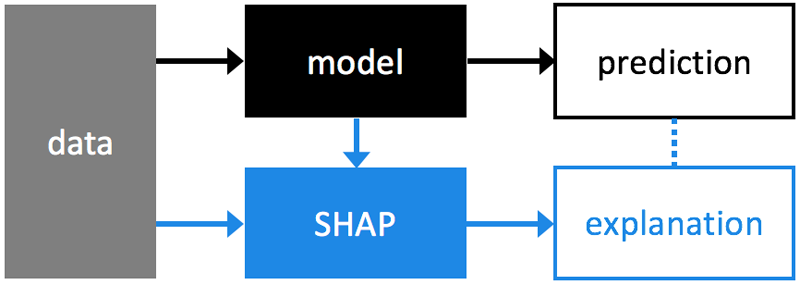
SHAP (SHapley Additive exPlanations)
a unified approach to explain the output of any machine learning model. SHAP connects game theory with local explanations, uniting several previous methods [1-7] and representing the only possible consistent and locally accurate additive feature attribution method based on expectations (see our papers for details).