Attention
YouTube search... ...Google search
- Attention in...
- Computer Vision is used to highlight important parts of an image that contribute to a desired output
- Transformers as language modeling and machine translation; predicting the next word or recover a missing word
- Sequence to Sequence (Seq2Seq) ----> Recurrent Neural Networks (RNN) ----> Transformer
- Memory Networks
- Autoencoder (AE) / Encoder-Decoder
- Natural Language Processing (NLP)
- Feature Exploration/Learning
- Attention? Attention! | Lilian Weng
- The Illustrated Transformer | Jay Alammar
- Attention in NLP | Kate Loginova - Medium
- Attention Mechanism | Gabriel Loye - FloydHub
Attention mechanisms in neural networks are about memory access. That’s the first thing to remember about attention: it’s something of a misnomer.
Attention networks are a kind of short-term memory that allocates attention over input features they have recently seen. Attention mechanisms are components of memory networks, which focus their attention on external memory storage rather than a sequence of hidden states in a Recurrent Neural Networks (RNN). Memory networks are a little different, but not too. They work with external data storage, and they are useful for, say, mapping questions as input to answers stored in that external memory. That external data storage acts as an embedding that the attention mechanism can alter, writing to the memory what it learns, and reading from it to make a prediction. While the hidden states of a recurrent neural network are a sequence of embeddings, memory is an accumulation of those embeddings (imagine performing max pooling on all your hidden states – that would be like memory). A Beginner's Guide to Attention Mechanisms and Memory Networks | Skymind
In the Transformer, the Attention module repeats its computations multiple times in parallel. Each of these is called an Attention Head. The Attention module splits its Query, Key, and Value parameters N-ways and passes each split independently through a separate Head. All of these similar Attention calculations are then combined together to produce a final Attention score. This is called Multi-head attention and gives the Transformer greater power to encode multiple relationships and nuances for each word. Transformers Explained Visually (Part 3): Multi-head Attention, deep dive | Ketan Doshi - Towards Data Science
The context vector turned out to be a bottleneck for these types of models. It made it challenging for the models to deal with long sentences. A solution was proposed in Bahdanau et al., 2014 and Luong et al., 2015. These papers introduced and refined a technique called “Attention”, which highly improved the quality of machine translation systems. Attention allows the model to focus on the relevant parts of the input sequence as needed. Let’s continue looking at attention models at this high level of abstraction. An attention model differs from a classic sequence-to-sequence model in two main ways: Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) | Jay Alammar
- First, the encoder passes a lot more data to the decoder. Instead of passing the last hidden state of the encoding stage, the encoder passes all the hidden states to the decoder
- Second, an attention decoder does an extra step before producing its output. In order to focus on the parts of the input that are relevant to this decoding time step

![]()
Contents
Attention Is All You Need
The dominant sequence transduction models are based on complex Recurrent Neural Network (RNN)) or (Deep) Convolutional Neural Network (DCNN/CNN) in an encoder-decoder (Autoencoder (AE) / Encoder-Decoder} configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Attention Is All You Need | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser, and I. Polosukhin - Google
“Attention Is All You Need” without a doubt, is one of the most impactful and interesting paper in 2017. It presented a lot of improvements to the soft attention and make it possible to do Sequence to Sequence (Seq2Seq) modeling without Recurrent Neural Network (RNN) units. The proposed “transformer” model is entirely built on the Self-Attention mechanisms without using sequence-aligned recurrent architecture.
Key, Value, and Query
Given a query q and a set of key-value pairs (K, V), attention can be generalized to compute a weighted sum of the values dependent on the query and the corresponding keys. The query determines which values to focus on; we can say that the query 'attends' to the values. Attention and its Different Forms | Anusha Lihala - Towards Data Science
The secret recipe is carried in its model architecture
The major component in the transformer is the unit of multi-head Self-Attention mechanism. The transformer views the encoded representation of the input as a set of key-value pairs, (K,V), both of dimension n (input sequence length); in the context of NMT, both the keys and values are the encoder hidden states. In the decoder, the previous output is compressed into a query (Q of dimension m) and the next output is produced by mapping this query and the set of keys and values.
The transformer adopts the scaled Dot Product Attention: the output is a weighted sum of the values, where the weight assigned to each value is determined by the Dot Product of the query with all the keys:
Attention(Q,K,V)=softmax(QK⊤n−−√)V
Multi-Head Self-Attention
Multi-head scaled Dot Product Attention
Rather than only computing the Attention once, the multi-head mechanism runs through the scaled Dot Product Attention multiple times in parallel. The independent Attention outputs are simply concatenated and linearly transformed into the expected dimensions. I assume the motivation is because ensembling always helps? ;) According to the paper, “multi-head Attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single Attention head, averaging inhibits this.” Attention? Attention! | Lilian Weng
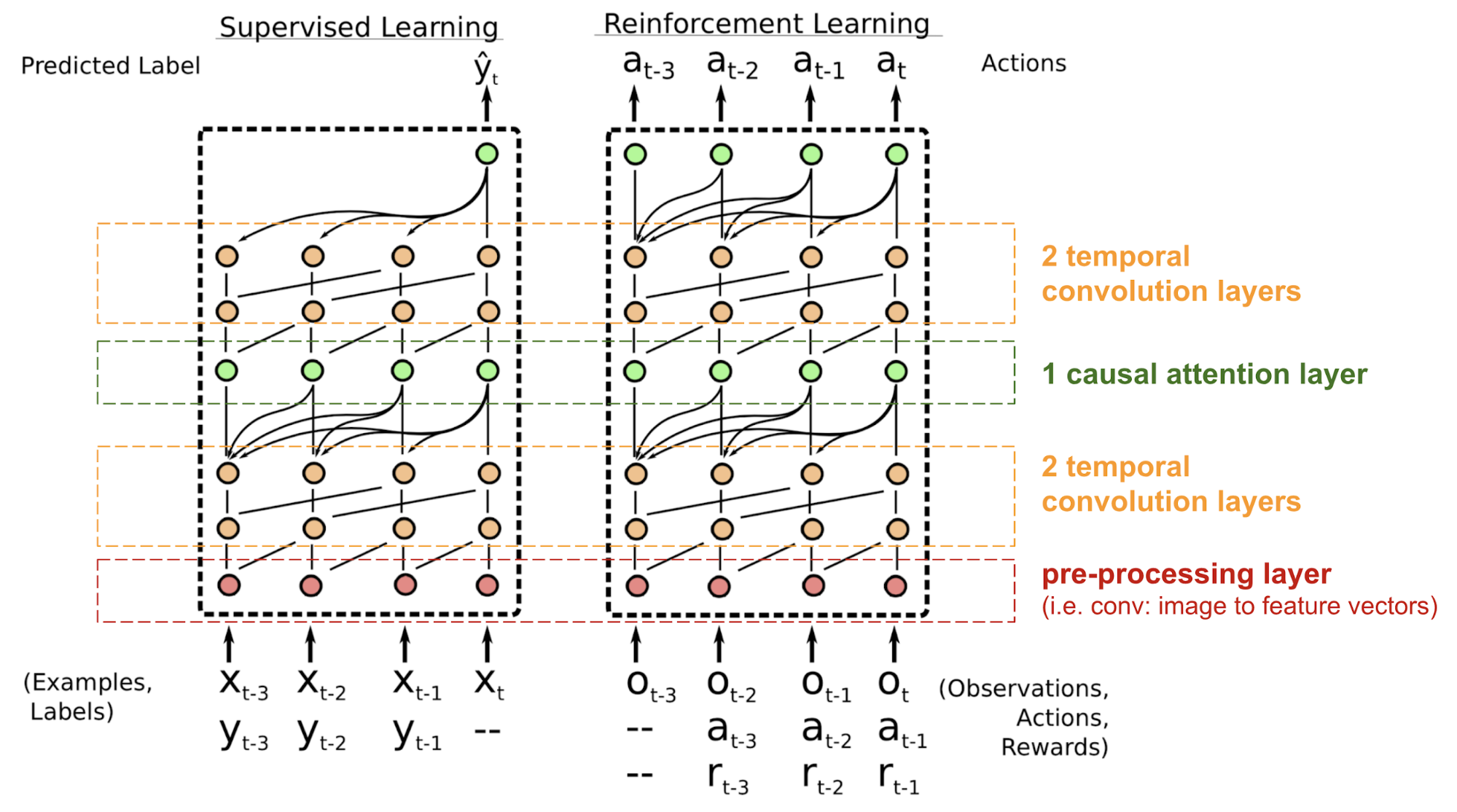
SNAIL
The transformer has no Recurrent Neural Network (RNN) or (Deep) Convolutional Neural Network (DCNN/CNN) structure, even with the positional encoding added to the embedding vector, the sequential order is only weakly incorporated. For problems sensitive to the positional dependency like Reinforcement Learning (RL), this can be a big problem.
The Simple Neural Attention Meta-Learner (SNAIL) (Mishra et al., 2017) was developed partially to resolve the problem with positioning in the transformer model by combining the self-attention Attention in transformer with temporal convolutions. It has been demonstrated to be good at both Supervised learning and Reinforcement Learning (RL) tasks. Attention? Attention! | Lilian Weng