Difference between revisions of "Deep Reinforcement Learning (DRL)"
(→IMPALA (Importance Weighted Actor-Learner Architecture)) |
|||
| Line 46: | Line 46: | ||
<youtube>eYlJsDH7ggE</youtube> | <youtube>eYlJsDH7ggE</youtube> | ||
| − | == | + | == Importance Weighted Actor-Learner Architecture (IMPALA) == |
[http://www.youtube.com/results?search_query=Impala+AGI+machine+artificial+intelligence+deep+learning+simple YouTube search...] | [http://www.youtube.com/results?search_query=Impala+AGI+machine+artificial+intelligence+deep+learning+simple YouTube search...] | ||
[http://www.google.com/search?q=Impala+AGIb+deep+machine+learning+ML ...Google search] | [http://www.google.com/search?q=Impala+AGIb+deep+machine+learning+ML ...Google search] | ||
Revision as of 17:53, 1 September 2019
Youtube search... ...Google search
- OpenAI Gym
- Reinforcement Learning (RL)
- Monte Carlo (MC) Method - Model Free Reinforcement Learning
- Markov Decision Process (MDP)
- Q Learning
- State-Action-Reward-State-Action (SARSA)
- Distributed Deep Reinforcement Learning (DDRL)
- Deep Q Network (DQN)
- Evolutionary Computation / Genetic Algorithms
- Actor Critic
- Hierarchical Reinforcement Learning (HRL)
- MERLIN
OTHER: Policy Gradient Methods
_______________________________________________________________________________________
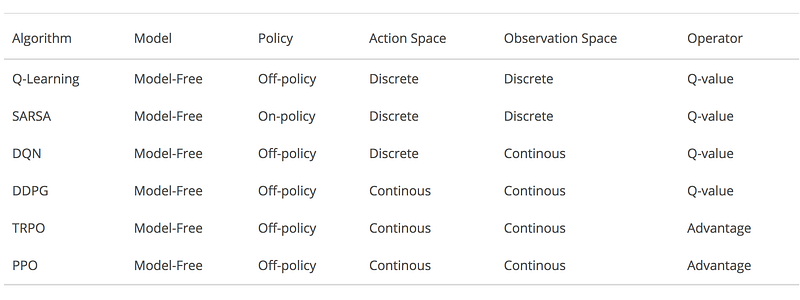
- Introduction to Various Reinforcement Learning Algorithms. Part I (Q-Learning, SARSA, DQN, DDPG) | Steeve Huang
- Introduction to Various Reinforcement Learning Algorithms. Part II (TRPO, PPO) | Steeve Huang
- Guide

Goal-oriented algorithms, which learn how to attain a complex objective (goal) or maximize along a particular dimension over many steps; for example, maximize the points won in a game over many moves. Reinforcement learning solves the difficult problem of correlating immediate actions with the delayed returns they produce. Like humans, reinforcement learning algorithms sometimes have to wait a while to see the fruit of their decisions. They operate in a delayed return environment, where it can be difficult to understand which action leads to which outcome over many time steps.
Importance Weighted Actor-Learner Architecture (IMPALA)
YouTube search... ...Google search
- Artificial General Intelligence Is Here, and Impala Is Its Name | Aaron Krumins
- DeepMind Lab
- IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
- Importance Weighted Actor-Learner Architectures: Scalable Distributed DeepRL in DMLab-30
uses resources more efficiently in single-machine training but also scales to thousands of machines without sacrificing data efficiency or resource utilisation. We achieve stable learning at high throughput by combining decoupled acting and learning with a novel off-policy correction method called V-trace. IMPALA is able to achieve better performance than previous agents with less data, and crucially exhibits positive transfer between tasks as a result of its multi-task approach.

