Difference between revisions of "Hierarchical Reinforcement Learning (HRL)"
| Line 9: | Line 9: | ||
* [[HIerarchical Reinforcement learning with Off-policy correction (HIRO)]] | * [[HIerarchical Reinforcement learning with Off-policy correction (HIRO)]] | ||
| + | * [http://thegradient.pub/the-promise-of-hierarchical-reinforcement-learning The Promise of Hierarchical Reinforcement Learning | Yannis Flet-Berliac - The Gradient] | ||
* [http://www.slideshare.net/DavidJardim/hierarchical-reinforcement-learning Hierarchical Reinforcement Learning | David Jardim] | * [http://www.slideshare.net/DavidJardim/hierarchical-reinforcement-learning Hierarchical Reinforcement Learning | David Jardim] | ||
* [[Reinforcement Learning (RL)]]: | * [[Reinforcement Learning (RL)]]: | ||
| Line 31: | Line 32: | ||
<youtube>ARfpQzRCWT4</youtube> | <youtube>ARfpQzRCWT4</youtube> | ||
| − | http:// | + | http://thegradient.pub/content/images/2019/03/image44.png |
| + | |||
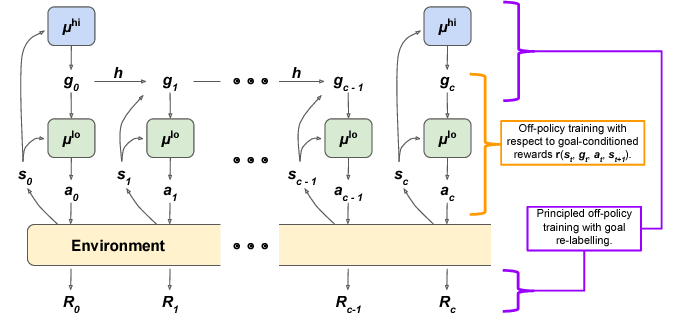
| + | == HIerarchical Reinforcement learning with Off-policy correction (HIRO) == | ||
| + | |||
| + | |||
| + | http://miro.medium.com/max/678/1*Fq-TQ7Mu2XDOIZ6R7dkRjw.png | ||
Revision as of 16:32, 1 September 2019
Youtube search... ...Google search
- HIerarchical Reinforcement learning with Off-policy correction (HIRO)
- The Promise of Hierarchical Reinforcement Learning | Yannis Flet-Berliac - The Gradient
- Hierarchical Reinforcement Learning | David Jardim
- Reinforcement Learning (RL):
- Monte Carlo (MC) Method - Model Free Reinforcement Learning
- Markov Decision Process (MDP)
- Q Learning
- State-Action-Reward-State-Action (SARSA)
- Deep Reinforcement Learning (DRL) DeepRL
- Distributed Deep Reinforcement Learning (DDRL)
- Deep Q Network (DQN)
- Evolutionary Computation / Genetic Algorithms
- Asynchronous Advantage Actor Critic (A3C)
- MERLIN
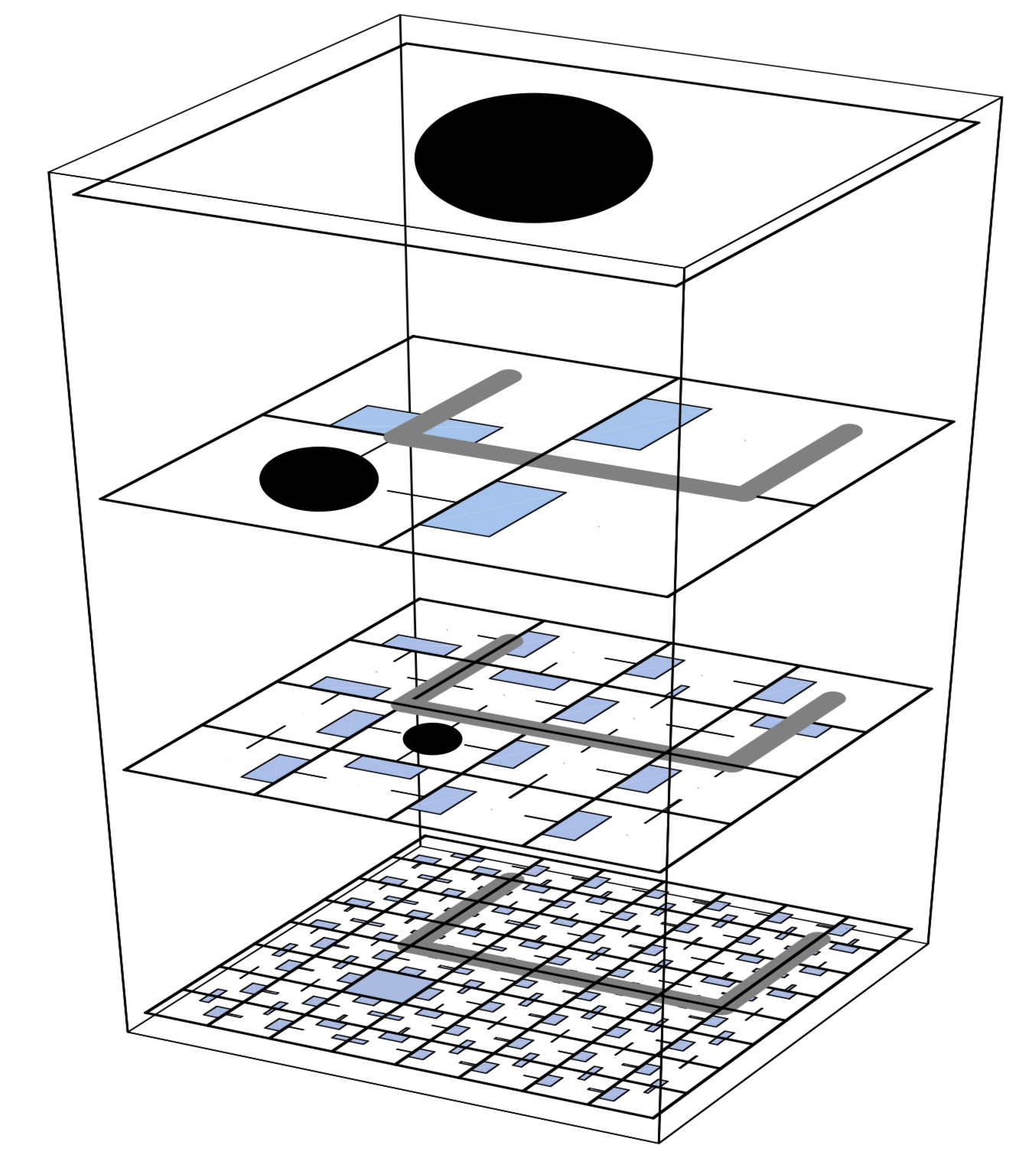
HIerarchical Reinforcement learning with Off-policy correction (HIRO)