Difference between revisions of "Transformer-XL"
| Line 11: | Line 11: | ||
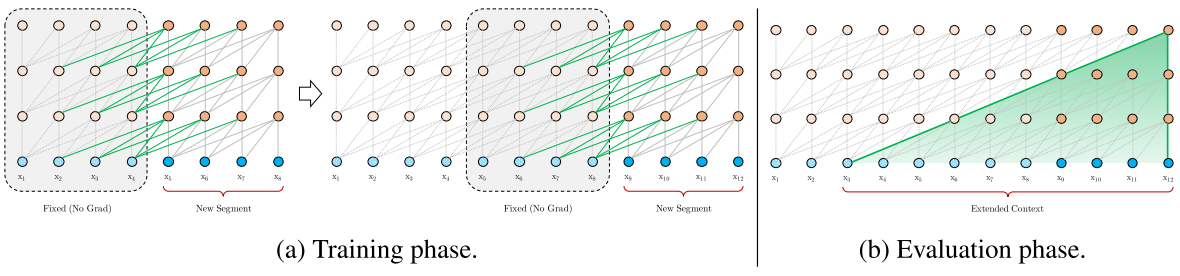
Combines the two leading architectures for language modeling: | Combines the two leading architectures for language modeling: | ||
| − | # | + | # [[Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and Recurrent Neural Network (RNN)]] to handles the input tokens — words or characters — one by one to learn the relationship between them |
| − | # | + | # [[Attention Mechanism/Model - Transformer Model]] to receive a segment of tokens and learns the dependencies between at once them using an attention mechanism. |
[http://towardsdatascience.com/transformer-xl-explained-combining-transformers-and-rnns-into-a-state-of-the-art-language-model-c0cfe9e5a924 Transformer-XL Explained: Combining Transformers and RNNs into a State-of-the-art Language Model; Summary of “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context” | Rani Horev - Towards Data Science] | [http://towardsdatascience.com/transformer-xl-explained-combining-transformers-and-rnns-into-a-state-of-the-art-language-model-c0cfe9e5a924 Transformer-XL Explained: Combining Transformers and RNNs into a State-of-the-art Language Model; Summary of “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context” | Rani Horev - Towards Data Science] | ||
Revision as of 17:13, 19 January 2019
YouTube search... ...Google search
- A Light Introduction to Transformer-XL | Elvis - Medium
- Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and Recurrent Neural Network (RNN)
- Natural Language Processing (NLP)
- Memory Networks
- Attention Mechanism/Model - Transformer Model
- Autoencoder (AE) / Encoder-Decoder
Combines the two leading architectures for language modeling:
- Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and Recurrent Neural Network (RNN) to handles the input tokens — words or characters — one by one to learn the relationship between them
- Attention Mechanism/Model - Transformer Model to receive a segment of tokens and learns the dependencies between at once them using an attention mechanism.