|
|
| Line 360: |
Line 360: |
| | Reinforcement learning is a powerful framework in which agents learn from experience collected through trial-and-error. We use model-free RL, in which agents do not use any prior world knowledge or modeling assumptions. Another benefit of RL is that agents can optimize for any objective. In our setting, this means that a tax policy can be learned that optimizes any social objective, and without knowledge of workers’ utility functions or skills. [http://blog.einstein.ai/the-ai-economist/ The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies | S. Zheng, A. Trott, S. Srinivasa, N. Naik, M. Gruesbeck, D. Parkes, and R. Socher - Einstein.ai]] | | Reinforcement learning is a powerful framework in which agents learn from experience collected through trial-and-error. We use model-free RL, in which agents do not use any prior world knowledge or modeling assumptions. Another benefit of RL is that agents can optimize for any objective. In our setting, this means that a tax policy can be learned that optimizes any social objective, and without knowledge of workers’ utility functions or skills. [http://blog.einstein.ai/the-ai-economist/ The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies | S. Zheng, A. Trott, S. Srinivasa, N. Naik, M. Gruesbeck, D. Parkes, and R. Socher - Einstein.ai]] |
| | | | |
| − | <img src="http://blog.einstein.ai/content/images/2020/03/1a-2.png" width="800"> | + | <img src="http://blog.einstein.ai/content/images/2020/03/1a-2.png" width="1000"> |
| | | | |
| | {|<!-- T --> | | {|<!-- T --> |
YouTube search...
...Google search
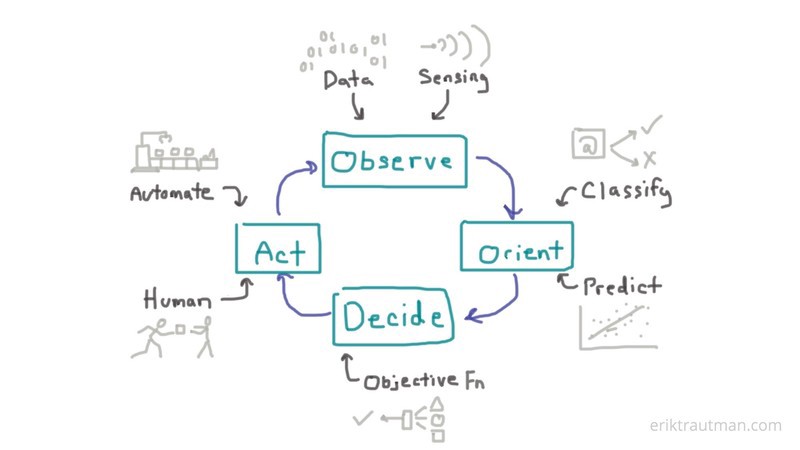
Observe–Orient–Decide–Act (OODA) Loop
YouTube search...
...Google search
The OODA loop is the cycle: Observe–Orient–Decide–Act ...emphasized that "the loop" is actually a set of interacting loops that are to be kept in continuous operation... developed by military strategist and United States Air Force Colonel John Boyd. Boyd applied the concept to the combat operations process, often at the operational level during military campaigns. It is now also often applied to understand commercial operations and learning processes. The approach explains how agility can overcome raw power in dealing with human opponents. It is especially applicable to cyber security and cyberwarfare. Wikipedia ... A Discourse On Winning and Losing | John R. Boyd - Air University Press
We’ve historically focused automation efforts on the “Act” portion but the real potential for new technologies is to address the prior 3 steps: Improving Observation: Improve the data itself with better sensing accuracy, timeliness, relevance, etc or improve our ability to use the data with higher throughput learning processes Improving Orientation: Improve the classification of the current state and the prediction of future states
Improving Decision: Improve the ability to choose between paths via better objective functions. How Artificial Intelligence is Closing the Loop with Better Predictions | Erik Trautman - HackerNoon]
|
Mindset: OODA Loop by John Boyd
OODA Loop is an acronym which stands for Observe, Orient, Decide and Act. In this video I provide a historical, academic, and practical perspective to help shed some light on the topic. John Boyd is one of the greatest military strategist to have lived, and to understand OODA Loop it's import to put it into context. If you have any questions or have something to add, please comment down below. Like this content? Consider supporting me on Patreon where you will get exclusive access to unpublished videos, behind the scenes, coupons, and the satisfaction of supporting pro-freedom content. https://www.patreon.com/WeRunGuns Please LIKE, SHARE, and SUBSCRIBE if you enjoyed!
|
|
|
|
Balan Ayyar, CEO of Percipient AI, Discusses the OODA Loop Model and Artificial Intelligence
Balan Ayyar is the Founder and CEO of Percipient.ai, a Silicon Valley based artificial intelligence firm focused on delivering products and solutions for the most pressing intelligence and national security challenges. We have been tracking this leader for years and have watched him inspire many to achieve great things. His leadership in senior officer roles in the US Air Force (he is a retired Brigadier General) included tours in combat zones and commands back in the US, including at one point leading the entire Air Force recruiting system. His visionary leadership in the corporate world resulted in the creation of a new firm providing new AI capabilities that are already serving some of the most critical missions in the nation. He is a disciplined visionary with an incredible thurst for learning and a knack for connecting with others. We loved the fact that we recorded him while he was at his desk and when we started asking about what he is reading he could quickly grab his favorite books and give his his insights. It is also always great to talk to a real Air Force leader about the OODA Loop and the model of continuous action and how it applies to not just military ops but business. Topics we covered included: - How the national security establishment needs to change to get ready for the new world - Views on the struggle between open societies and closed/dictatorship/communist societies and how that relationship is changing now. - Role that AI can play to accelerate the return of our economy - Concepts for getting classified information to users where ever they are, including at their homes. Seems technically feasible, and seems like the risk/reward equation may have shifted a bit recently. - Ideas on how US tech firms can better support the nation in the new economy. - Lessons learned from leadership of Percipient that could be helpful to other CEOs or other leaders in government. - Topics that can inform your technology due diligence
|
|
Feedback Loop
YouTube search...
...Google search
any process where the outputs of a system are plugged back in and used as iterative inputs. Feedback loops exist just about everywhere. In nature, the evolutionary "arms race" between predators and prey is a classic example. In business, the practice of taking customer feedback (the output of a product or service) and using it to improve future processes is another commonly used feedback loop. Today, rapid advances in artificial intelligence (AI) and machine learning are helping businesses do more with data. These systems — and their ability to analyze an inhuman amount of data — allow businesses to adjust algorithms, workflows and processes on the fly. Get More Out Of Feedback Loops With AI | Arka Dhar - Forbes
|
Feedback loops: How nature gets its rhythms - Anje-Margriet Neutel
While feedback loops are a bummer at band practice, they are essential in nature. What does nature’s feedback look like, and how does it build the resilience of our world? Anje-Margriet Neutel describes some common positive and negative feedback loops, examining how an ecosystem’s many loops come together to make its ‘trademark sound.’ Lesson by Anje-Margriet Neutel, animation by Brad Purnell.
|
|
|
|
How Games Use Feedback Loops | Game Maker’s Toolkit
Playing Pyre over Christmas got me thinking about feedback loops: the reward structures in games that can reinforce or balance out winners and losers. In this episode I’ll explain what this all means, and talk about the design of Pyre’s positive and negative loops.
|
|
Multi-Loop Learning
YouTube search...
...Google search

|
SINGLE & DOUBLE LOOP LEARNING
Made by: Hannah Munshi 2016
|
|
|
|
Managing for Quality Lecture Series - #6 Organizational Learning – Triple Loop Experience
American Society for Quality, Quality Management Division With Dr. Gregory Watson The concept of “Triple-Loop Learning” grew out of the work of Harvard psychologist Chris Argyris and Donald Schön as a “reflective management practice.” The first loop occurs as the outcome of work is examined when is nonconforming to its performance expectations. This cycle of learns about problem-solving, standardization, and process control. The second learning loop occurs reviews the methods used in the first loop to improve efficiency and effectiveness of work management methods. The third learning loop occurs as management examines its business assumptions for driving operational excellence. This webinar describes this process and illustrates it in a case study.
|
|
|
François Chollet: Limits of Deep Learning | AI Podcast Clips
Lex Fridman from Sep 2019. François Chollet is the creator of Keras, which is an open source deep learning library that is designed to enable fast, user-friendly experimentation with deep neural networks. It serves as an interface to several deep learning libraries, most popular of which is TensorFlow, and it was integrated into TensorFlow main codebase a while back. Aside from creating an exceptionally useful and popular library, François is also a world-class AI researcher and software engineer at Google, and is definitely an outspoken, if not controversial, personality in the AI world, especially in the realm of ideas around the future of artificial intelligence.
|
|
|
|
Understanding Triple Loop Learning and it's impact on the Coaching Process
The results that people achieve in life come from the actions that they take both at conscious and unconscious levels. Often a client will express a desire for change, and seek actionable steps from his coach to create that change. Taking positive actions can lead to positive changes and results, but may still fall short of being transformational. Coaches can help clients achieve real breakthrough when they understand how Triple Loop Learning occurs. For more, please visit us at http://www.coachmastersacademy.com/
|
|
|
How to use double loop learning
pfc Social Impact Advisors
|
|
|
|
Double-loop learning: a case study from the front-line | Roderic Yapp | TEDxWandsworth
Roderic Yapp is a former Royal Marines Officer, he led marines on operations around the world including the front-line in Afghanistan in 2007, and evacuated civilians from Libya during the Arab Spring. Roderic delves into his experience as a Royal Marine explaining why we must challenge our own behaviour. He uses examples of changes made by UK Military and the Taliban to explain why we must challenge how we think if we are to solve tomorrow's problems effectively. This talk was given at a TEDx event using the TED conference format but independently organized by a local community. Learn more at http://ted.com/tedx
|
|
Triple Golden OODA
YouTube search...
...Google search
The Triple Golden OODA loop diagram depicts a hybrid of concepts from the Triple Loop concept inspired by Chris Argyris & Donald Schön's work on the Double Loop, Simon Sinek's Golden Circle in 'Start with Why', and Colonel John Boyd's Observe, Orient, Decide and Act (OODA) Loop from his ‘A Discourse On Winning and Losing'.

|
Start with WHY - Simon Sinek In Vegas
IDLife NYC Those who lead inspire us. We follow those who lead because we want to and for selfish reasons. Those who start with "why" that have the ability to inspire those around them or find others who inspire them.
1. You have to know WHY you do what you do.
2. You have to have DISCIPLINE of how.
3. You have to have consistency of WHAT.
|
|
|
|
Lucy and the Chocolate Factory
CBS All Access -- How best can Triple Golden OODA loop be applied? What would be the Single loop in this situation? The Double loop? The Triple loop? The Why?
|
|
Feedback Loop - Peer Learning
YouTube search...
...Google search

|
Future of feedback: Automated Feedback with AI
Speaker: Jan-Hein Gooszen (Technology Enhanced Learning at FeedbackFruits)
|
|
|
|
FeedbackFruits Official Video: The Reason Behind Our Journey
FeedbackFruits mission: Improve Learning. Find out more about our initiative to nurture innovation in higher education on a global scale on http://edtech-consortium.com or check out our official homepage at http://feedbackfruits.com !
|
|
|
Google AI's Take on How To Fix Peer Review
The paper "Avoiding a Tragedy of the Commons in the Peer Review Process" is available here: http://arxiv.org/abs/1901.06246
|
|
|
|
Scientific publications and scientific peer review - Can AI be a solution to current Issues
Dan L. Clinciu a researcher with CMU, and an assistant professor with NCUT, both in Taichung Taiwan and Brian D. Oscar discuss various issues in current scientific peer review and publications and how AI might be a solution to these various issues in the near future. They also discuss how significant scientific discoveries could have disastrous outcomes if they are misinterpreted. www.het-forum.net
|
|
Feedback Loop - Creating Consciousness
YouTube search...
...Google search
|
Michio Kaku: Feedback loops are creating consciousness | Big Think
One of the great questions in all of science is where consciousness comes from. When it comes to consciousness, Kaku believes different species have different levels of consciousness, based on their feedback loops needed to survive in space, society, and time. According to the theoretical physicist, human beings' ability to use past experiences, memories, to predict the future makes us distinct among animals — and even robots (they're currently unable to understand, or operate within, a social hierarchy). Dr. Michio Kaku is the co-founder of string field theory, and is one of the most widely recognized scientists in the world today. He has written 4 New York Times Best Sellers, is the science correspondent for CBS This Morning and has hosted numerous science specials for BBC-TV, the Discovery/Science Channel. His radio show broadcasts to 100 radio stations every week. Dr. Kaku holds the Henry Semat Chair and Professorship in theoretical physics at the City College of New York (CUNY), where he has taught for over 25 years. He has also been a visiting professor at the Institute for Advanced Study at Princeton, as well as New York University (NYU).
|
|
|
|
Investigating Consciousness with Closed-Loop Neural Reinforcement
Neuroscience Virtual Event 2018 Aurelio Cortese, PhD Researcher, ATR Institute International Aurelio received his MSc degree from the Life Sciences and Technologies faculty at EPFL in Switzerland (2012), while spending one year at the Max-Planck Institute of Psychiatry in Munich working on mice models of Alzheimer's disease and depression. He is now a researcher at ATR working with Mitsuo Kawato, with ongoing collaborations with Hakwan Lau's Lab at UCLA and Hong Kong University, and with Benedetto de Martino at UCL/Wellcome Trust (London, UK). Webinar: Investigating Consciousness with Closed-Loop Neural Reinforcement Abstract:
In consciousness studies, a longstanding controversy concerns whether activity in the prefrontal cortical (PFC) region of the brain is necessary to evoke conscious experiences. Similarly, there is contrasting evidence on whether subjective confidence directly reflects sensory evidence or may depend on a late-stage estimation, related to consciousness but dissociable from sensory processes. As of yet, in humans, experimental tools have lacked the power to resolve these issues convincingly. We overcome this difficulty by capitalizing on the recently developed method of decoded neurofeedback (DecNef), where the occurrence of distinct neural events (e.g., spatial activation patterns) is selectively rewarded. This closed-loop training thus has the power of reinforcing purely content-specific processes that typically lie below consciousness. In a series of recent studies, we employed DecNef to directly reinforce neural activation patterns in areas related to representations at different levels of complexity, from simpler (e.g. orientation in visual cortex) to more composite (e.g. confidence in PFC). In all cases, the manipulations resulted in clear behavioral or physiological changes. Nevertheless, during the training sessions, participants were never conscious about the content of these localized recurring activation patterns.
This raises a very interesting point: it is likely that consciousness requires more than just a local representation, however well defined. As already proposed, consciousness may rely on concomitant activations across frontoparietal networks. Frontal cortices could thus play a crucial role in bringing content to consciousness, by virtue of being also implicated in higher order representations. Approaches combining machine learning techniques with brain imaging and closed-loop training such as DecNef may offer a strong paradigm to further explore and understand consciousness and its real neural basis.
|
|
|
MIT Godel Escher Bach Lecture 1
jasonofthel33t
|
|
|
|
Introduction to Brain and Consciousness 2.2 - Feedforward and Feedback Connections
Synergos Narrated by Julia Donnell Written by Hakwan Lau Now, onto more details about the pathways. Again, getting the basic concepts is much more important than remembering all the specifics. When we say there’s a pathway, we imply there is a direction of information flow. And in fact there is. From the eyeball towards the brain, that is how perception happens. We call this direction feedforward, or bottom up. But interestingly, information also flows from the other direction. And we call these feedback, or top down signals. Directed/Edited by Justine Suh Cinematography/Sound Editing by Emily Kalish Key Grip and Sound by Santiago Rodriguez Herran Graphics & Subtitles by Peter Keating & Charmaine Wong FAIR USE NOTICE: This video contains copyrighted material the use of which has not always been specifically authorized by the copyright owner.
|
|
Feedback Loop - Scientific Discovery
YouTube search...
...Google search
The paradigm shift will be from AI used for analysing the data which has already been obtained, to AI deciding what to measure next.
Why Artificial Intelligence Will Enable New Scientific Discoveries - Andrew Briggs - Graphcore
Quantum Computing and AI to Enable Our Sustainable Future | Katia Moskvitch - IBM

Toward Robot Scientist for autonomous scientific discovery | A. Sparkes, W. Aubrey, E. Byrne, and A. Clare - ResearchGate

|
Machine Learning Accelerating Scientific Discovery
Phil Nelson, Google Research
|
|
|
|
Hypothesis Generation with AGATHA : Accelerate Scientific Discovery with Deep Learning | AISC
ML Explained - Aggregate Intellect - AISC For slides and more information on the paper, visit http://ai.science/e/hypothesis-generation-with-agatha-accelerate-scientific-discovery-with-deep-learning--2020-04-01
Discussion lead: Justin Sybrandt Discussion facilitator(s): Rouzbeh Afrasiabi Medical research is risky and expensive. Drug discovery, as an example, requires that researchers efficiently winnow thousands of potential targets to a small candidate set for more thorough evaluation. However, research groups spend significant time and money to perform the experiments necessary to determine this candidate set long before seeing intermediate results. Hypothesis generation systems address this challenge by mining the wealth of publicly available scientific information to predict plausible research directions. We present AGATHA, a deep-learning hypothesis generation system that can introduce data-driven insights earlier in the discovery process. Through a learned ranking criteria, this system quickly prioritizes plausible term-pairs among entity sets, allowing us to recommend new research directions. We massively validate our system with a temporal holdout wherein we predict connections first introduced after 2015 using data published beforehand. We additionally explore biomedical sub-domains, and demonstrate AGATHA's predictive capacity across the twenty most popular relationship types. This system achieves best-in-class performance on an established benchmark, and demonstrates high recommendation scores across subdomains. Reproducibility: All code, experimental data, and pre-trained models are available online:
|
|
Feedback Loop - Stock Market Predictions
YouTube search...
...Google search
Why you can beat the market, even when it does not seem so. The importance of loops, patterns, and predictable events. Random events are don’t measure risks, and should not affect your decision making.
Some traders follow the trend, and some go against it. At I Know First we work on algorithmic strategies which are neither, we simply try an assess where the next opportunity is and provide stock market predictions. If this means to do what everyone else does, than why not. If it means going against when everyone else does, this is also fine. The tricky part is determining where this opportunities are, this article will discuss how to find opportunities in what can seem as total randomness. Markets are Complex, but not Unpredictable! There are two major misconceptions about the stock market. The first one is connected to the classical economic theory which claims markets to be efficient, and as such unpredictable. In this case trying to select one stock over another becomes useless, as no opportunity is ever better than the other. Both stocks are perfectly priced according to their opportunity and risk, with everyone having all information. However, the truth of the matter is that some people profit trading stocks while others lose – this by itself proves the market to be inefficient, and thus exploitable. While US markets are very efficient, and most information is available, not everyone interprets this information the same. Stock Market Predictions: Where In The Feedback Loop Is Your Portfolio? | I Know First

|
How Do Stock Trading Algorithms Work?
The stock market can be a foracious beast to those that don't understand it, but nowadays, you don't even need to understand it to make money. The rise of the digital information age and AI has brought about a new way of stock trading called algorithmic trading. Sometimes referred to as automated trading or black-box trading, this is essentially a program that can trade stocks at high speeds and frequencies perfectly in line with the market. These programs are given constraints and instructions like timing, price, amount, etc. and a user can fine tune how they exactly work. So how does this all work then... let's take a look. All images courtesy of Creative Commons or protected under Fair Use. For questions or concerns about the use of any media, please contact the page directly.
|
|
Feedback Loop - The AI Economist
YouTube search...
...Google search
Optimal Tax Design as Learned Reward Design Using Reinforcement Learning
Reinforcement learning is a powerful framework in which agents learn from experience collected through trial-and-error. We use model-free RL, in which agents do not use any prior world knowledge or modeling assumptions. Another benefit of RL is that agents can optimize for any objective. In our setting, this means that a tax policy can be learned that optimizes any social objective, and without knowledge of workers’ utility functions or skills. The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies | S. Zheng, A. Trott, S. Srinivasa, N. Naik, M. Gruesbeck, D. Parkes, and R. Socher - Einstein.ai]

|
AI Economist: How can AI FIX taxes? (Deep Reinforcement Learning, Machine Learning, Economics)
Review and in depth analysis of very interesting paper out of Harvard and Salesforce Research.
OUTLINE:
0:10 - Economic background, equality vs productivity tradeoff, tax schedule
2:18 - Deep Reinforcement Learning Network Overview
3:45 - Multi-agent Markov Games
4:22 - Figure 1: Game map, explanation
5:21 - Results, No taxes (division of labor)
6:58 - Notation table
7:56 - Objective, individual taxpayer
9:22 - Defining utility function
11:22 - Taxes Tax Brackets, Social Welfare Functions
12:50 - Objective for policy planner
14:00 - Two-level reinforcement learning training scheme
15:26 - U.S. Policy vs AI Economist vs Saez
Paper: https://arxiv.org/abs/2004.13332
|
|
Feedback Loop - Synthetic
YouTube search...
...Google search
|
The Wandering Dreamer: An Synthetic Feedback Loop
This experiment uses four machine learning models to create a feedback loop between synthesized images and text. All of the images you see here are fabricated, as is the text that describes each image. Made by Brannon Dorsey using Runway. Source code
1. The first row of images are produced from a class label using BigGAN.
2. The text below is an auto-generated caption of the BigGAN image using Im2Text.
3. The next set of images are synthesized by an Attentional GAN using the auto-generated captions.
4. The text at the bottom classifies the image above it using MobileNet. This class label is then sent back to BigGAN as input to create an infinite loop.
|
|
Recursion
YouTube search...
...Google search

|
Recursion for Beginners: A Beginner's Guide to Recursion
Recursion has an intimidating reputation for being the advanced skill of coding sorcerers. But in this tutorial we look behind the curtain of this formidable technique to discover the simple ideas under it. Through live coding demos in the interactive shell, we'll answer the following questions:
- What is recursion, and when is it a good idea and bad idea to use it?
- What's a stack, the call stack, and a stack overflow?
- What are all the confusing ways that recursion is commonly taught?
- Do some problems require recursion? Can recursion do anything a loop can't?
- What is memoization, and how does functools.lru_cache work?
- How do I draw that cool-looking recursive fractal artwork with Python's turtle module?
Beginners will be able to follow this talk. All that is required is a willingness to learn, and a willingness to have the willingness to learn, and a willingness to have the willingness to have the willingness to learn, and... so on. A Python conference north of the Golden Gate
|
|
|
|
Thinking Recursively | Microsoft Interview Question | Software Engineer UI/Frontend
Thinking Recursively is very important if you're a Software Engineer. Be it Microsoft Interview, or even while in day to day job, Recursion plays a very important role in Software Engineer's life. In this video, I'll solve a Microsoft Interview Question, just like how candidates do in the interview. Will also tell you how to create a mental model of solution and think while approaching such questions. It's not necessary that you solve the question in the first attempt. Most of the time we have to think step by step and gradually come up to the final solution.
|
|
|
Can you solve the Towers of Hanoi problem in Python using recursion? SOLUTION INCLUDED
This is a complete explanation of recursion. Recursion is a very useful tool in computer science and data science. Here I show you what recursion is and how to use recursion to solve the Towers of Hanoi problem using Python. I also use recursion to calculate factorial. Want to learn Python? You can buy my course here: http://bit.ly/2OwUA09 Want to ace the Data Science Interview? Over 1000 Data Science Practice Questions with model solutions: http://bit.ly/30ul0nX
|
|
|
|
Unintended Feedback Loop
YouTube search...
...Google search

Models that are an integrated part of a product experience, or what we referred to as data products, often involve feedback loops. When done right, feedback loops can help us to create better experiences. However, feedback loops can also create unintended negative consequences, such as bias or inaccurate model performance measurements... Getting Better at Machine Learning | Robert Chang - Medium
Leaders hoping to shift their posture from hindsight to foresight need to better understand the types of risks they are taking on, their interdependencies, and their underlying causes... Confronting the risks of artificial intelligence | B. Cheatham, K. Javanmardian, and H. Samandari - Mckinsey & Company
One of the key features of live ML systems is that they often end up influencing their own behavior if they update over time. This leads to a form of analysis debt, in which it is difficult to predict the behavior of a given model before it is released. These feedback loops can take different forms, but they are all more difficult to detect and address if they occur gradually over time, as may be the case when models are updated infrequently.
- Direct Feedback Loops. A model may directly influence the selection of its own future training data. It is common practice to use standard supervised algorithms, although the theoretically correct solution would be to use bandit algorithms. The problem here is that bandit algorithms (such as contextual bandits) do not necessarily scale well to the size of action spaces typically required for real-world problems. It is possible to mitigate these effects by using some amount of randomization, or by isolating certain parts of data from being influenced by a given model.
- Hidden Feedback Loops. Direct feedback loops are costly to analyze, but at least they pose a statistical challenge that ML researchers may find natural to investigate. A more difficult case is hidden feedback loops, in which two systems influence each other indirectly through the world. One example of this may be if two systems independently determine facets of a web page, such as
one selecting products to show and another selecting related reviews. Improving one system may lead to changes in behavior in the other, as users begin clicking more or less on the other components
in reaction to the changes. Note that these hidden loops may exist between completely disjoint systems. Consider the case of two stock-market prediction models from two different investment
companies. Improvements (or, more scarily, bugs) in one may influence the bidding and buying behavior of the other. Hidden Technical Debt in Machine Learning Systems | D. Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, J. Crespo, and D. Dennison - Google
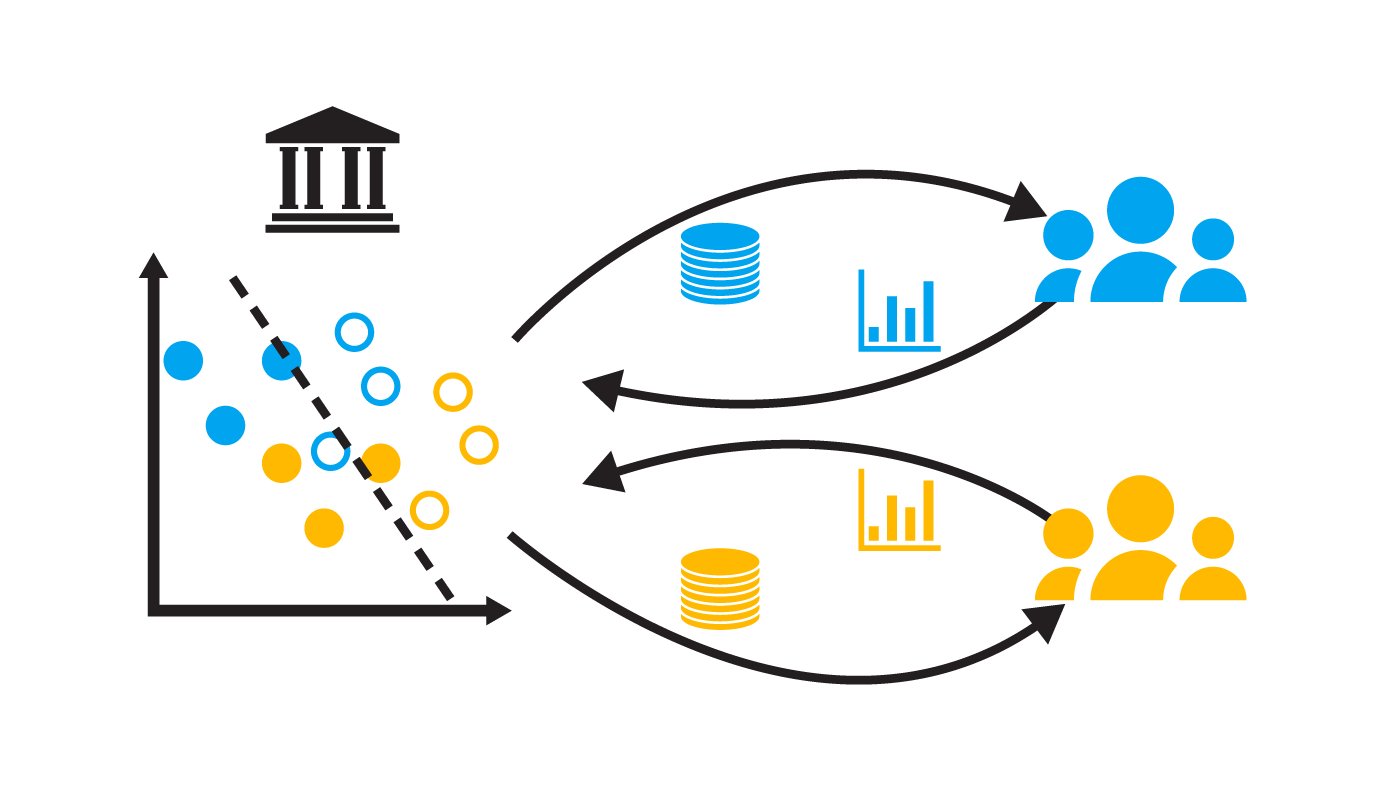
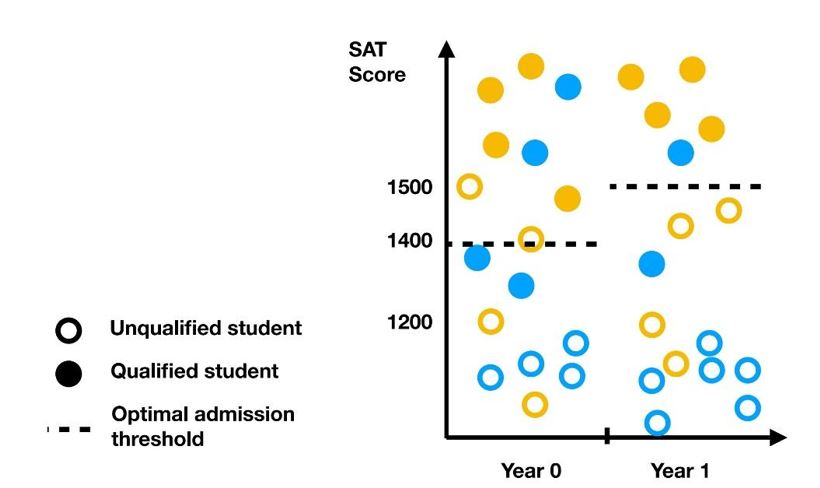
When the system is retrained on future data, it may become not less but more detrimental to historically disadvantaged groups. In order to build AI systems that are aligned with desirable long-term societal outcomes, we need to understand when and why such negative feedback loops occur, and we need to learn how to prevent them. When bias begets bias: A source of negative feedback loops in AI systems | Lydia T. Liu - University of California, Berkeley - Microsoft Research Blog
|
Weapons of Math Destruction | Cathy O'Neil | Talks at Google
Cathy O'Neil is a data scientist and author of the blog mathbabe.org. She earned a Ph.D. in mathematics from Harvard and taught at Barnard College before moving to the private sector and working for the hedge fund D. E. Shaw. O'Neil started the Lede Program in Data Journalism at Columbia and is the author of "Doing Data Science." She appears weekly on the "Slate Money" podcast. In this talk, O'Neil sounds an alarm on the mathematical models that pervade modern life and threaten to rip apart our social fabric. Get the book ... mathbabe
|
|
|
|
Building Trust in Your AI | Veritone
AI can deliver compelling business results, but do you know for a fact you are using the best available AI model for your data? Do you know what to expect after deploying? Is there risk of performance degradation or bias? Many AI projects fall short of expectations due to poor model performance or the unintended consequences of inaccurate AI decisions. What if there was a universal way for ML Ops / AI Ops to evaluate and monitor the performance and behavior of AI models, both pre-deployment and ongoing, no matter the vendor or features used? In this session we will review the pitfalls of opaque AI models, and discover how to evaluate, compare, and monitor performance and behavior across AI models, for better AI model trust and explainability. We will also demonstrate the Veritone Clarity product, showing how you can easily select the best AI model for the job, detect drift and correct it to achieve better business outcomes. For more details, visit us at
http://Veritone.com
|
|
Unintended Feedback Loop - Filter Bubbles
YouTube search...
...Google search
In December 2009, Google began customizing its search results for all users, and we entered a new era of personalization. With little notice or fanfare, our online experience is changing, as the websites we visit are increasingly tailoring themselves to us. In this engaging and visionary book, MoveOn.org board president Eli Pariser lays bare the personalization that is already taking place on every major website, from Facebook to AOL to ABC News. As Pariser reveals, this new trend is nothing short of an invisible revolution in how we consume information, one that will shape how we learn, what we know, and even how our democracy works. The Filter Bubble | Eli Pariser
In news media, echo chamber is a metaphorical description of a situation in which beliefs are amplified or reinforced by communication and repetition inside a closed system. Filter Bubble | Wikipedia
|
How Filter Bubbles Isolate You
In this video, you’ll learn more about how filter bubbles work to automatically curate content for you when you're online. Our text-based lesson We hope you enjoy!
|
|
|
|
Filter Bubbles and Echo Chambers
You've probably heard the term Filter Bubble and/or Echo Chamber at least once or twice in the past few months. It's a term that has been circling the media for some time about Facebook and the 2016 U.S. Presidential Election. But what do they mean exactly? How does it relate to the internet or more specifically Facebook and Google? How does it affect you? Watch the video to find out! Don't forget to leave us a comment about what you think and how Filter Bubble or Echo Chamber relates to you! Scene 1 “Filter Bubble” is a theory that the algorithms from companies like Facebook and Google bases the information given to you on data acquired from things like, your search history, your past click behavior, the type of your computer and your location. Therefore, limiting the topics that reach you to a bubble of only your own formulated interests and personalized search subjects. Scene 2 The term was coined by Eli Pariser who wrote a book on this subject explaining that these algorithms are “closing us off to new ideas, new subjects and important information ”. What he means is that you are not given information outside your own political views, religious views or even other data like for example updates on women's rights and animal rights.
|
|
|
Beware online "filter bubbles" | Eli Pariser
http://www.ted.com As web companies strive to tailor their services (including news and search results) to our personal tastes, there's a dangerous unintended consequence: We get trapped in a "filter bubble" and don't get exposed to information that could challenge or broaden our worldview. Eli Pariser argues powerfully that this will ultimately prove to be bad for us and bad for democracy. Read our community Q&A with Eli (featuring 10 ways to turn off the filter bubble): http://on.ted.com/PariserQA
|
|
|
|
Feedback loops in data systems - Matthieu Ranger
When 'filter bubbles' came to public attention, it became pressing that systems that consume their own recommendations as data can be subject to noxious feedback loops. In this talk, we go over several examples of feedback loops, then discuss the technical and management issues related. Montréal-Python 74: Virtual Echo http://montrealpython.org/2019/03/mp74/
|
|
Using the OODA Loop - Purple Team with Cybersecurity
YouTube search...
...Google search
Modern security organizations create new capabilities within an overall cyber defense team by organizing themselves around a fundamental concept of an “OODA loop” — enabling teams to quickly make necessary decisions as they are responding to live or simulated incidents. ... Handling incidents effectively requires this sort of cyclical and quick decision making. In this quick-decision cycle, the IR team becomes the Blue Team, the “attackers” comprise the Red Team and run attack scenarios, and an even more novel third team called the Purple Team proactively hunts the attackers. This structure allows organizations to “train like they fight,” enabling them to prepare for increasingly more advanced adversarial techniques....Purple Teams help optimize security detection processes within an organization by reproducing attacks, determining if successful detection of these attacks occurred, and exposing existing deficiencies within the organization’s IR plan. Improving Cyber Defense by Purple Team using OODA loop | Ozren (Oz) Bogovac - Medium

|
Red Team VS Blue Team: What’s The Difference? | PurpleSec
PurpleSec Cyber Security Red teams are offensive security professionals who are experts in attacking systems and breaking into defenses. Blue teams are defensive security professionals responsible for maintaining internal network defenses against all cyber attacks and threats. Red teams simulate attacks against blue teams to test the effectiveness of the network’s security. These red and blue team exercises provide a holistic security solution ensuring strong defenses while keeping in view evolving threats. Jason Firch, MBA What Is A Purple Team? A purple team isn’t necessarily a stand alone team, although it could be. The goal of a purple team is to bring both red and blue teams together while encouraging them to work as a team to share insights and create a strong feedback loop. Management should ensure that the red and blue teams work together and keep each other informed. Enhanced cooperation between both teams through proper resource sharing, reporting and knowledge share is essential for the continual improvement of the security program. If you need help securing your business from cyber attacks then feel free to check out: http://purplesec.us
|
|
|
|
Purple Teaming Explained
SANS Institute Learn more about SANS SEC599: https://www.sans.org/sec599 What is Purple Teaming? SANS instructor Erik Van Buggenhout explains the concept of purple teaming in this short video.
After seeing so many blue teamers take a penetration course, authors Stephen Sims and Erik Van Buggenhout created the first SANS Purple Team course SEC599: Defeating Advanced Adversaries: Purple Team Tactics and Kill Chain Defenses.
|
|
OODA Loop - Security Approaches
YouTube search...
...Google search
|
The OODA Loop: A Holistic Approach to Cyber Security
A holistic approach to cyber security is one that includes the threat actors, advance telemetry of the network and a defensive strategy that continuously adapts to the adversaries capability and threat landscape. By collecting and analyzing network data via technologies such as NetFlow, organizations can obtain the security intelligence needed to fill in the gaps left by conventional tools and more effectively feed their OODA loop - a cyclical process for Observation, Orientation, Decision and Action. By embracing the OODA loop, and turning the network into a sensor grid for delivering key security information, organizations can dramatically improve their situational awareness, incident response and forensics procedures.
|
|
|
|
Applying OODA and Feedback Loops to Security Processes
RSA Conference Winn Schwartau, Founder, The Security Awareness Company Learn how to apply security-enhancing ICS/SCADA/Heathcare feedback and OODA loops into applications and networking for greater operational stability.
|
|