Difference between revisions of "Deep Reinforcement Learning (DRL)"
| Line 1: | Line 1: | ||
[http://www.youtube.com/results?search_query=deep+reinforcement+learning+ Youtube search...] | [http://www.youtube.com/results?search_query=deep+reinforcement+learning+ Youtube search...] | ||
| + | * [http://gym.openai.com/ Gym | OpenAI] | ||
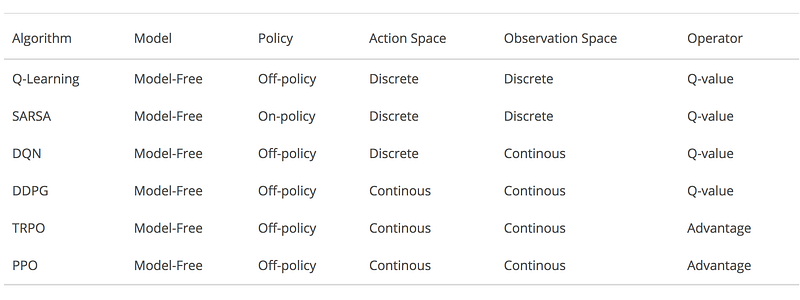
| + | * [https://towardsdatascience.com/introduction-to-various-reinforcement-learning-algorithms-i-q-learning-sarsa-dqn-ddpg-72a5e0cb6287 Introduction to Various Reinforcement Learning Algorithms. Part I (Q-Learning, SARSA, DQN, DDPG) | Steeve Huang] | ||
| + | * [https://towardsdatascience.com/introduction-to-various-reinforcement-learning-algorithms-part-ii-trpo-ppo-87f2c5919bb9 Introduction to Various Reinforcement Learning Algorithms. Part II (TRPO, PPO) | Steeve Huang] | ||
| + | * [http://deeplearning4j.org/deepreinforcementlearning.html Guide] | ||
| + | |||
| + | === Q=learning & SARSA === | ||
* [[Deep Q Learning (DQN)]] | * [[Deep Q Learning (DQN)]] | ||
* [[State-Action-Reward-State-Action (SARSA)]] | * [[State-Action-Reward-State-Action (SARSA)]] | ||
| + | * [[Neural Coreference]] | ||
| + | === Policy Gradient Methods === | ||
* [[Deep Deterministic Policy Gradient (DDPG)]] | * [[Deep Deterministic Policy Gradient (DDPG)]] | ||
* [[Trust Region Policy Optimization (TRPO)]] | * [[Trust Region Policy Optimization (TRPO)]] | ||
* [[Proximal Policy Optimization (PPO)]] | * [[Proximal Policy Optimization (PPO)]] | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
https://cdn-images-1.medium.com/max/640/1*NyWUkwz1QhrVJj9ygCQ5nA.png | https://cdn-images-1.medium.com/max/640/1*NyWUkwz1QhrVJj9ygCQ5nA.png | ||
Revision as of 22:35, 26 May 2018
- Gym | OpenAI
- Introduction to Various Reinforcement Learning Algorithms. Part I (Q-Learning, SARSA, DQN, DDPG) | Steeve Huang
- Introduction to Various Reinforcement Learning Algorithms. Part II (TRPO, PPO) | Steeve Huang
- Guide
Q=learning & SARSA
Policy Gradient Methods
- Deep Deterministic Policy Gradient (DDPG)
- Trust Region Policy Optimization (TRPO)
- Proximal Policy Optimization (PPO)

Goal-oriented algorithms, which learn how to attain a complex objective (goal) or maximize along a particular dimension over many steps; for example, maximize the points won in a game over many moves. Reinforcement learning solves the difficult problem of correlating immediate actions with the delayed returns they produce. Like humans, reinforcement learning algorithms sometimes have to wait a while to see the fruit of their decisions. They operate in a delayed return environment, where it can be difficult to understand which action leads to which outcome over many time steps.