Difference between revisions of "Bidirectional Encoder Representations from Transformers (BERT)"
| Line 10: | Line 10: | ||
* [http://www.theverge.com/2019/10/25/20931657/google-bert-search-context-algorithm-change-10-percent-langauge Google is improving 10 percent of searches by understanding language context - Say hello to BERT | Dieter Bohn - The Verge] ...the old [[Google]] search algorithm treated that sentence as a “[[Bag-of-Words (BoW)]]” | * [http://www.theverge.com/2019/10/25/20931657/google-bert-search-context-algorithm-change-10-percent-langauge Google is improving 10 percent of searches by understanding language context - Say hello to BERT | Dieter Bohn - The Verge] ...the old [[Google]] search algorithm treated that sentence as a “[[Bag-of-Words (BoW)]]” | ||
* [http://venturebeat.com/2019/09/26/google-ais-albert-claims-top-spot-in-multiple-nlp-performance-benchmarks/ Google AI’s ALBERT claims top spot in multiple NLP performance benchmarks | Khari Johnson - VentureBeat] | * [http://venturebeat.com/2019/09/26/google-ais-albert-claims-top-spot-in-multiple-nlp-performance-benchmarks/ Google AI’s ALBERT claims top spot in multiple NLP performance benchmarks | Khari Johnson - VentureBeat] | ||
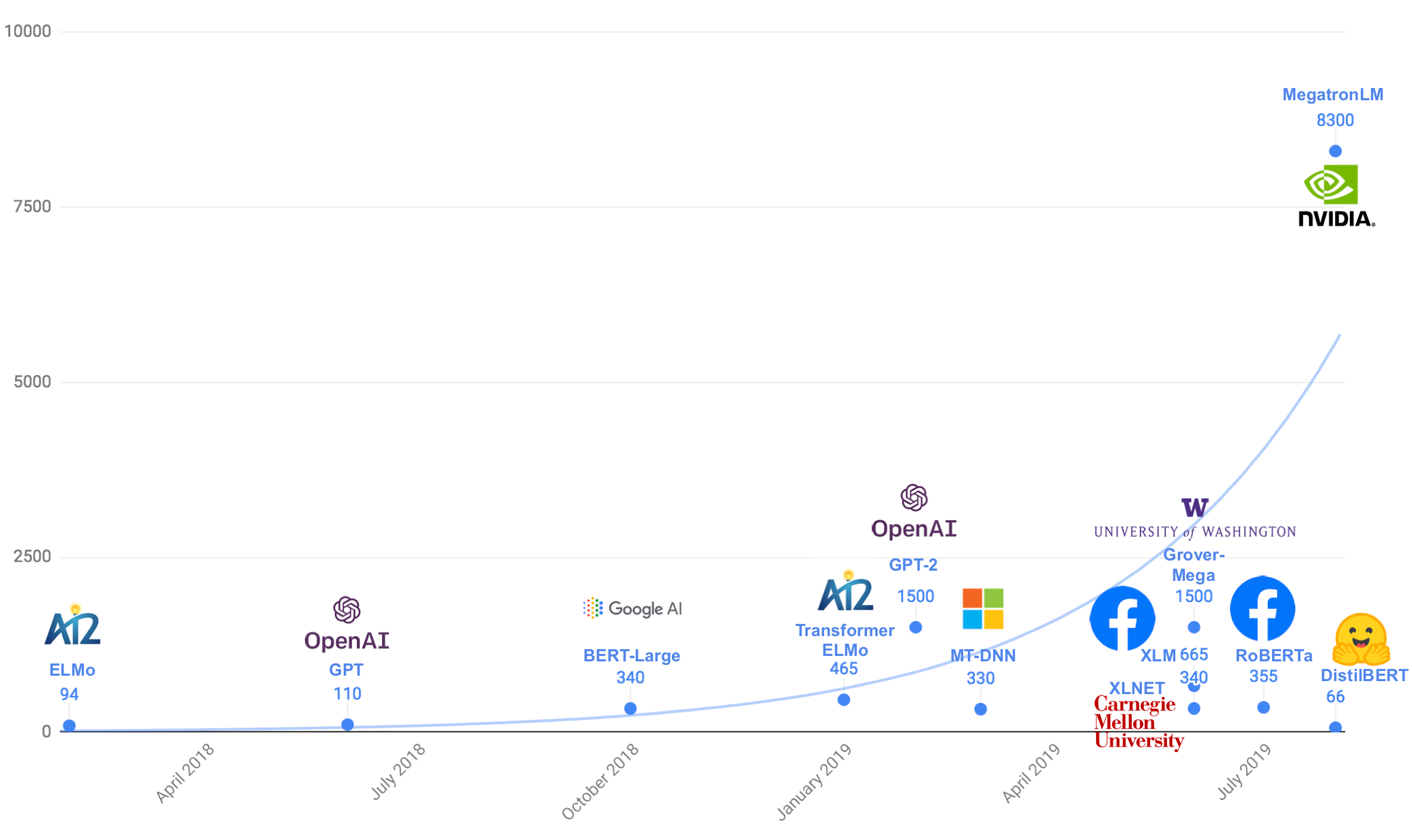
| + | * [http://github.com/pytorch/fairseq/tree/master/examples/roberta RoBERTa: A Robustly Optimized BERT Pretraining Approach | GitHub] - iterates on BERT's pretraining procedure, including training the model longer, with bigger batches over more data; removing the next sentence prediction objective; training on longer sequences; and dynamically changing the masking pattern applied to the training data. | ||
* [http://venturebeat.com/2019/07/29/facebook-ais-roberta-improves-googles-bert-pretraining-methods/ Facebook AI’s RoBERTa improves Google’s BERT pretraining methods | Khari Johnson - VentureBeat] | * [http://venturebeat.com/2019/07/29/facebook-ais-roberta-improves-googles-bert-pretraining-methods/ Facebook AI’s RoBERTa improves Google’s BERT pretraining methods | Khari Johnson - VentureBeat] | ||
* Google's BERT - built on ideas from [[ULMFiT]], [[ELMo]], and [http://openai.com/ OpenAI] | * Google's BERT - built on ideas from [[ULMFiT]], [[ELMo]], and [http://openai.com/ OpenAI] | ||
| Line 21: | Line 22: | ||
* [http://towardsdatascience.com/understanding-bert-is-it-a-game-changer-in-nlp-7cca943cf3ad Understanding BERT: Is it a Game Changer in NLP? | Bharat S Raj - Towards Data Science] | * [http://towardsdatascience.com/understanding-bert-is-it-a-game-changer-in-nlp-7cca943cf3ad Understanding BERT: Is it a Game Changer in NLP? | Bharat S Raj - Towards Data Science] | ||
* [http://allenai.org/ Allen Institute for Artificial Intelligence, or AI2’s] [http://allenai.org/aristo/ Aristo] [http://www.geekwire.com/2019/allen-institutes-aristo-ai-program-finally-passes-8th-grade-science-test/ AI system finally passes an eighth-grade science test | Alan Boyle - GeekWire] | * [http://allenai.org/ Allen Institute for Artificial Intelligence, or AI2’s] [http://allenai.org/aristo/ Aristo] [http://www.geekwire.com/2019/allen-institutes-aristo-ai-program-finally-passes-8th-grade-science-test/ AI system finally passes an eighth-grade science test | Alan Boyle - GeekWire] | ||
| + | * [[MT-DNN-SMART]] | ||
* [[Google]] | * [[Google]] | ||
Revision as of 22:22, 21 December 2019
Youtube search... ...Google search
- Google is improving 10 percent of searches by understanding language context - Say hello to BERT | Dieter Bohn - The Verge ...the old Google search algorithm treated that sentence as a “Bag-of-Words (BoW)”
- Google AI’s ALBERT claims top spot in multiple NLP performance benchmarks | Khari Johnson - VentureBeat
- RoBERTa: A Robustly Optimized BERT Pretraining Approach | GitHub - iterates on BERT's pretraining procedure, including training the model longer, with bigger batches over more data; removing the next sentence prediction objective; training on longer sequences; and dynamically changing the masking pattern applied to the training data.
- Facebook AI’s RoBERTa improves Google’s BERT pretraining methods | Khari Johnson - VentureBeat
- Google's BERT - built on ideas from ULMFiT, ELMo, and OpenAI
- Attention Mechanism/Transformer Model
- Natural Language Processing (NLP)
- Microsoft makes Google’s BERT NLP model better | Khari Johnson - VentureBeat
- Watch me Build a Finance Startup | Siraj Raval
- Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT | Victor Sanh - Medium
- TinyBERT: Distilling BERT for Natural Language Understanding | X. Jiao, Y. Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, and Q. Liu researchers at Huawei produces a model called TinyBERT that is 7.5 times smaller and nearly 10 times faster than the original. It also reaches nearly the same language understanding performance as the original.
- Understanding BERT: Is it a Game Changer in NLP? | Bharat S Raj - Towards Data Science
- Allen Institute for Artificial Intelligence, or AI2’s Aristo AI system finally passes an eighth-grade science test | Alan Boyle - GeekWire
- MT-DNN-SMART