Difference between revisions of "End-to-End Speech"
m |
m |
||
| Line 10: | Line 10: | ||
[https://news.google.com/search?q=ai+End-to-End+speech+nlp ...Google News] | [https://news.google.com/search?q=ai+End-to-End+speech+nlp ...Google News] | ||
[https://www.bing.com/news/search?q=ai+End-to-End+speech+nlp&qft=interval%3d%228%22 ...Bing News] | [https://www.bing.com/news/search?q=ai+End-to-End+speech+nlp&qft=interval%3d%228%22 ...Bing News] | ||
| − | |||
* [[Capabilities]] | * [[Capabilities]] | ||
| Line 17: | Line 16: | ||
* [[Sequence to Sequence (Seq2Seq)]] | * [[Sequence to Sequence (Seq2Seq)]] | ||
* [[Natural Language Processing (NLP)]] | * [[Natural Language Processing (NLP)]] | ||
| − | * [[Assistants]] | + | * [[Assistants]] ... [[Agents]] ... [[Negotiation]] ... [[Hugging_Face#HuggingGPT|HuggingGPT]] ... [[LangChain]] |
* [[Language Translation]] | * [[Language Translation]] | ||
Revision as of 17:01, 20 April 2023
YouTube ... Quora ...Google search ...Google News ...Bing News
- Capabilities
- Autoencoder (AE) / Encoder-Decoder
- Sequence to Sequence (Seq2Seq)
- Natural Language Processing (NLP)
- Assistants ... Agents ... Negotiation ... HuggingGPT ... LangChain
- Language Translation
Translatotron
YouTube search... ...Google search
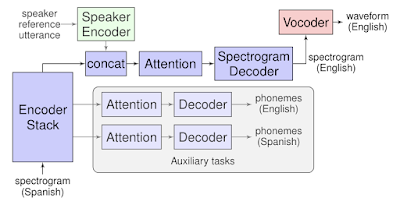
Translatotron is the first end-to-end model that can directly translate speech from one language into speech in another language. It is also able to retain the source speaker’s voice in the translated speech. We hope that this work can serve as a starting point for future research on end-to-end speech-to-speech translation systems. ... demonstrating that a single sequence-to-sequence model can directly translate speech from one language into speech in another language, without relying on an intermediate text representation in either language, as is required in cascaded systems.... Translatotron is based on a sequence-to-sequence network which takes source spectrograms as input and generates spectrograms of the translated content in the target language. It also makes use of two other separately trained components: a neural vocoder that converts output spectrograms to time-domain waveforms, and, optionally, a speaker encoder that can be used to maintain the character of the source speaker’s voice in the synthesized translated speech. During training, the sequence-to-sequence model uses a multitask objective to predict source and target transcripts at the same time as generating target spectrograms. However, no transcripts or other intermediate text representations are used during inference. Translatotron | Ye Jia and Ron Weiss - Google AI