Difference between revisions of "Google Facets"
m |
m (Text replacement - "http:" to "https:") |
||
| (One intermediate revision by the same user not shown) | |||
| Line 5: | Line 5: | ||
|description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | ||
}} | }} | ||
| − | [ | + | [https://www.youtube.com/results?search_query=training+datasets YouTube search...] |
| − | [ | + | [https://www.google.com/search?q=datasets+training+deep+machine+learning+artificial+intelligence+ML+AI ...Google search] |
| − | * [ | + | * [https://pair-code.github.io/facets/ Facets] | [[Google]] |
| − | ** [ | + | ** [https://goo.gle/38ZUlTD Hands-on labs] |
| − | ** [ | + | ** [https://github.com/PAIR-code/facets Facets - GitHub] |
* [[Data Science]] | * [[Data Science]] | ||
** [[Data Governance]] | ** [[Data Governance]] | ||
*** [[Benchmarks]] | *** [[Benchmarks]] | ||
*** [[Data Preprocessing]] | *** [[Data Preprocessing]] | ||
| − | **** [[Feature Exploration/Learning]] | + | **** [[Feature Exploration/Learning]] |
**** [[Data Quality]] ...[[AI Verification and Validation|validity]], [[Evaluation - Measures#Accuracy|accuracy]], [[Data Quality#Data Cleaning|cleaning]], [[Data Quality#Data Completeness|completeness]], [[Data Quality#Data Consistency|consistency]], [[Data Quality#Data Encoding|encoding]], [[Data Quality#Zero Padding|padding]], [[Data Quality#Data Augmentation, Data Labeling, and Auto-Tagging|augmentation, labeling, auto-tagging]], [[Data Quality#Batch Norm(alization) & Standardization| normalization, standardization]], and [[Data Quality#Imbalanced Data|imbalanced data]] | **** [[Data Quality]] ...[[AI Verification and Validation|validity]], [[Evaluation - Measures#Accuracy|accuracy]], [[Data Quality#Data Cleaning|cleaning]], [[Data Quality#Data Completeness|completeness]], [[Data Quality#Data Consistency|consistency]], [[Data Quality#Data Encoding|encoding]], [[Data Quality#Zero Padding|padding]], [[Data Quality#Data Augmentation, Data Labeling, and Auto-Tagging|augmentation, labeling, auto-tagging]], [[Data Quality#Batch Norm(alization) & Standardization| normalization, standardization]], and [[Data Quality#Imbalanced Data|imbalanced data]] | ||
| − | * [ | + | * [https://towardsdatascience.com/visualize-your-data-with-facets-d11b085409bc Visualize your data with Facets | Yufeng G - Towards Data Science] |
Facets contains two robust visualizations to aid in understanding and analyzing machine learning datasets. | Facets contains two robust visualizations to aid in understanding and analyzing machine learning datasets. | ||
| Line 26: | Line 26: | ||
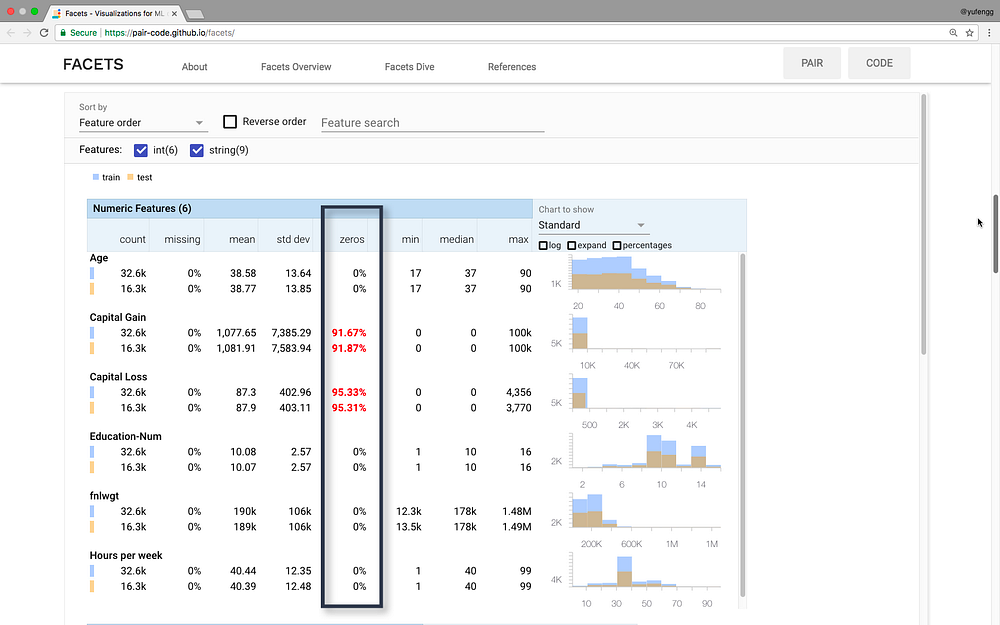
Overview takes input feature data from any number of datasets, analyzes them feature by feature and visualizes the analysis. Overview gives users a quick understanding of the distribution of values across the features of their dataset(s). Uncover several uncommon and common issues such as unexpected feature values, missing feature values for a large number of observation, training/serving skew and train/test/validation set skew. | Overview takes input feature data from any number of datasets, analyzes them feature by feature and visualizes the analysis. Overview gives users a quick understanding of the distribution of values across the features of their dataset(s). Uncover several uncommon and common issues such as unexpected feature values, missing feature values for a large number of observation, training/serving skew and train/test/validation set skew. | ||
| − | <img src=" | + | <img src="https://miro.medium.com/max/1000/1*FoCXpeJA5kZr1bBVFmQCrg.png" width="600"> |
| Line 32: | Line 32: | ||
Dive is a tool for interactively exploring large numbers of data points at once. Dive provides an interactive interface for exploring the relationship between data points across all of the different features of a dataset. Each individual item in the visualization represents a data point. Position items by "faceting" or bucketing them in multiple dimensions by their feature values. Success stories of Dive include the detection of classifier failure, identification of systematic errors, evaluating ground truth and potential new signals for ranking. | Dive is a tool for interactively exploring large numbers of data points at once. Dive provides an interactive interface for exploring the relationship between data points across all of the different features of a dataset. Each individual item in the visualization represents a data point. Position items by "faceting" or bucketing them in multiple dimensions by their feature values. Success stories of Dive include the detection of classifier failure, identification of systematic errors, evaluating ground truth and potential new signals for ranking. | ||
| − | <img src=" | + | <img src="https://miro.medium.com/max/1000/1*bGQMgbCspRFqfcMJM63D_g.gif" width="600"> |
<youtube>WVclIFyCCOo</youtube> | <youtube>WVclIFyCCOo</youtube> | ||
<youtube>y7cem6PsDjg</youtube> | <youtube>y7cem6PsDjg</youtube> | ||
Latest revision as of 16:28, 28 March 2023
YouTube search... ...Google search
Facets contains two robust visualizations to aid in understanding and analyzing machine learning datasets.
- Facets Overview - get a sense of the shape of each feature of your dataset
- Facets Dive - explore individual observations
Facets Overview
Overview takes input feature data from any number of datasets, analyzes them feature by feature and visualizes the analysis. Overview gives users a quick understanding of the distribution of values across the features of their dataset(s). Uncover several uncommon and common issues such as unexpected feature values, missing feature values for a large number of observation, training/serving skew and train/test/validation set skew.
Facets Dive
Dive is a tool for interactively exploring large numbers of data points at once. Dive provides an interactive interface for exploring the relationship between data points across all of the different features of a dataset. Each individual item in the visualization represents a data point. Position items by "faceting" or bucketing them in multiple dimensions by their feature values. Success stories of Dive include the detection of classifier failure, identification of systematic errors, evaluating ground truth and potential new signals for ranking.
