Difference between revisions of "Hierarchical Reinforcement Learning (HRL)"
(→HIerarchical Reinforcement learning with Off-policy correction (HIRO)) |
|||
| Line 8: | Line 8: | ||
[http://www.google.com/search?q=Hierarchical+Reinforcement+machine+learning+ML+artificial+intelligence ...Google search] | [http://www.google.com/search?q=Hierarchical+Reinforcement+machine+learning+ML+artificial+intelligence ...Google search] | ||
| − | |||
* [http://thegradient.pub/the-promise-of-hierarchical-reinforcement-learning The Promise of Hierarchical Reinforcement Learning | Yannis Flet-Berliac - The Gradient] | * [http://thegradient.pub/the-promise-of-hierarchical-reinforcement-learning The Promise of Hierarchical Reinforcement Learning | Yannis Flet-Berliac - The Gradient] | ||
* [http://www.slideshare.net/DavidJardim/hierarchical-reinforcement-learning Hierarchical Reinforcement Learning | David Jardim] | * [http://www.slideshare.net/DavidJardim/hierarchical-reinforcement-learning Hierarchical Reinforcement Learning | David Jardim] | ||
| Line 24: | Line 23: | ||
** [[MERLIN]] | ** [[MERLIN]] | ||
| + | Hierarchical reinforcement learning (HRL) is a promising approach to extend | ||
| + | traditional [[Reinforcement Learning (RL)]] methods to solve more complex tasks. | ||
<youtube>x_QjJry0hTc</youtube> | <youtube>x_QjJry0hTc</youtube> | ||
| Line 40: | Line 41: | ||
HIRO can be used to learn highly complex behaviors for simulated robots, such | HIRO can be used to learn highly complex behaviors for simulated robots, such | ||
as pushing objects and utilizing them to reach target locations, learning from only a few million samples, equivalent to a few days of real-time interaction. In comparisons with a number of prior HRL methods. | as pushing objects and utilizing them to reach target locations, learning from only a few million samples, equivalent to a few days of real-time interaction. In comparisons with a number of prior HRL methods. | ||
| + | |||
| + | <youtube>yLHzDky2ApI</youtube> | ||
http://miro.medium.com/max/678/1*Fq-TQ7Mu2XDOIZ6R7dkRjw.png | http://miro.medium.com/max/678/1*Fq-TQ7Mu2XDOIZ6R7dkRjw.png | ||
Revision as of 15:44, 1 September 2019
Youtube search... ...Google search
- The Promise of Hierarchical Reinforcement Learning | Yannis Flet-Berliac - The Gradient
- Hierarchical Reinforcement Learning | David Jardim
- Reinforcement Learning (RL):
- Monte Carlo (MC) Method - Model Free Reinforcement Learning
- Markov Decision Process (MDP)
- Q Learning
- State-Action-Reward-State-Action (SARSA)
- Deep Reinforcement Learning (DRL) DeepRL
- Distributed Deep Reinforcement Learning (DDRL)
- Deep Q Network (DQN)
- Evolutionary Computation / Genetic Algorithms
- Asynchronous Advantage Actor Critic (A3C)
- MERLIN
Hierarchical reinforcement learning (HRL) is a promising approach to extend traditional Reinforcement Learning (RL) methods to solve more complex tasks.
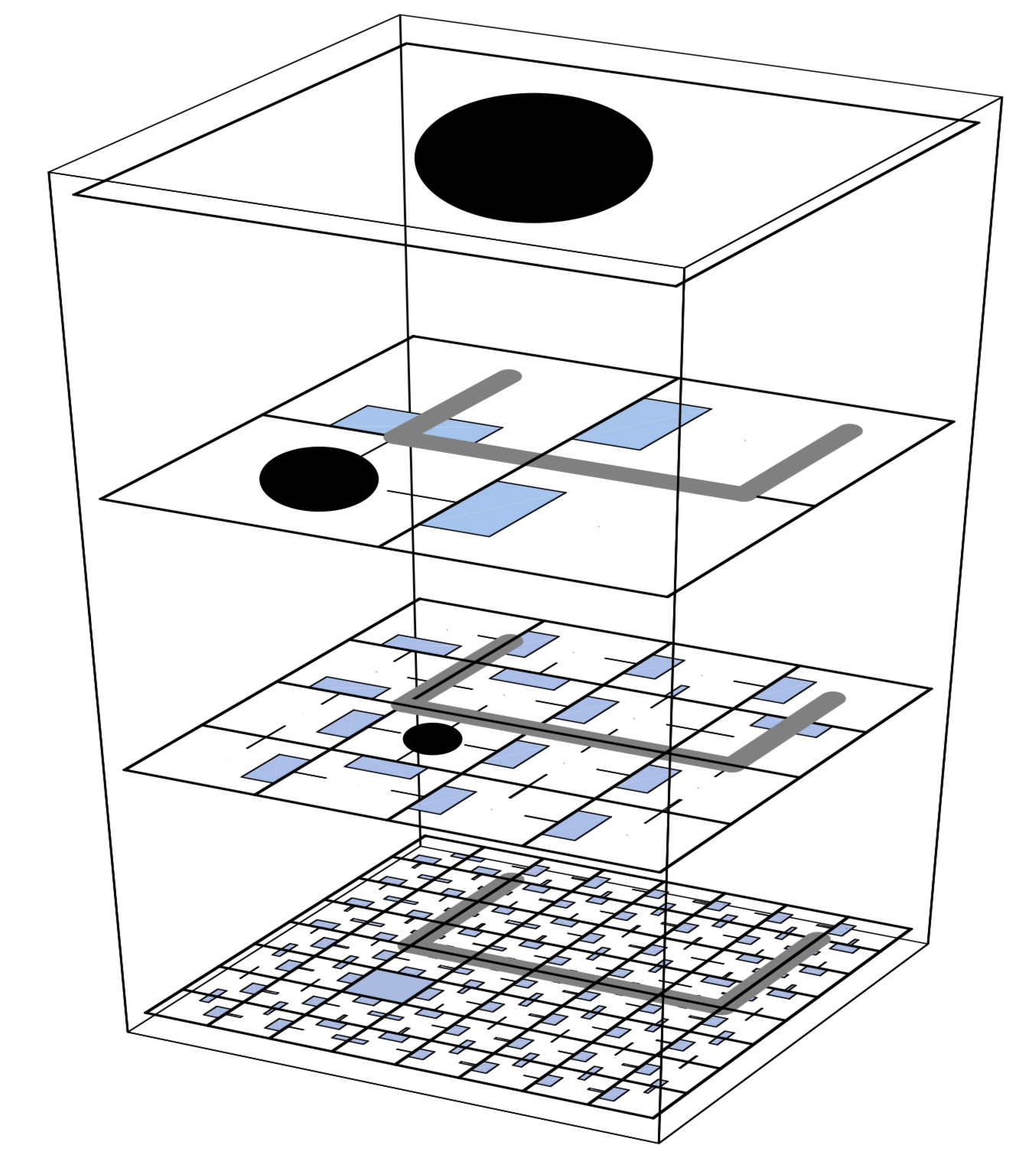
HIerarchical Reinforcement learning with Off-policy correction (HIRO)
- Beyond DQN/A3C: A Survey in Advanced Reinforcement Learning | Joyce Xu - Towards Data Science
- Data-Efficient Hierarchical Reinforcement Learning | O. Nachum, S. Gu, H. Lee, and S. Levine - Google Brain
HIRO can be used to learn highly complex behaviors for simulated robots, such as pushing objects and utilizing them to reach target locations, learning from only a few million samples, equivalent to a few days of real-time interaction. In comparisons with a number of prior HRL methods.