Difference between revisions of "Backpropagation"
m |
m |
||
| Line 19: | Line 19: | ||
* [[Backpropagation]] ... [[Feed Forward Neural Network (FF or FFNN)|FFNN]] ... [[Forward-Forward]] ... [[Activation Functions]] ...[[Softmax]] ... [[Loss]] ... [[Boosting]] ... [[Gradient Descent Optimization & Challenges|Gradient Descent]] ... [[Algorithm Administration#Hyperparameter|Hyperparameter]] ... [[Manifold Hypothesis]] ... [[Principal Component Analysis (PCA)|PCA]] | * [[Backpropagation]] ... [[Feed Forward Neural Network (FF or FFNN)|FFNN]] ... [[Forward-Forward]] ... [[Activation Functions]] ...[[Softmax]] ... [[Loss]] ... [[Boosting]] ... [[Gradient Descent Optimization & Challenges|Gradient Descent]] ... [[Algorithm Administration#Hyperparameter|Hyperparameter]] ... [[Manifold Hypothesis]] ... [[Principal Component Analysis (PCA)|PCA]] | ||
* [[Objective vs. Cost vs. Loss vs. Error Function]] | * [[Objective vs. Cost vs. Loss vs. Error Function]] | ||
| + | * [[Optimization Methods]] | ||
* [https://en.wikipedia.org/wiki/Backpropagation Wikipedia] | * [https://en.wikipedia.org/wiki/Backpropagation Wikipedia] | ||
* [https://neuralnetworksanddeeplearning.com/chap2.html How the backpropagation algorithm works] | * [https://neuralnetworksanddeeplearning.com/chap2.html How the backpropagation algorithm works] | ||
Latest revision as of 10:30, 6 August 2023
Youtube search... ...Google search
- Backpropagation ... FFNN ... Forward-Forward ... Activation Functions ...Softmax ... Loss ... Boosting ... Gradient Descent ... Hyperparameter ... Manifold Hypothesis ... PCA
- Objective vs. Cost vs. Loss vs. Error Function
- Optimization Methods
- Wikipedia
- How the backpropagation algorithm works
- Backpropagation Step by Step
- What is Backpropagation? | Daniel Nelson - Unite.ai
- Other Challenges in Artificial Intelligence
- A Beginner's Guide to Backpropagation in Neural Networks | Chris Nicholson - A.I. Wiki pathmind
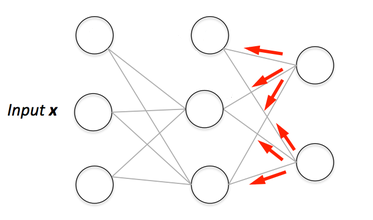
The primary algorithm for performing gradient descent on neural networks. First, the output values of each node are calculated (and cached) in a forward pass. Then, the partial derivative of the error with respect to each parameter is calculated in a backward pass through the graph. Machine Learning Glossary | Google