Difference between revisions of "Bidirectional Encoder Representations from Transformers (BERT)"
| Line 18: | Line 18: | ||
* [http://medium.com/huggingface/distilbert-8cf3380435b5 Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT | Victor Sanh - Medium] | * [http://medium.com/huggingface/distilbert-8cf3380435b5 Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT | Victor Sanh - Medium] | ||
* [http://arxiv.org/abs/1909.10351 TinyBERT: Distilling BERT for Natural Language Understanding | X. Jiao, Y. Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, and Q. Liu] researchers at Huawei produces a model called TinyBERT that is 7.5 times smaller and nearly 10 times faster than the original. It also reaches nearly the same language understanding performance as the original. | * [http://arxiv.org/abs/1909.10351 TinyBERT: Distilling BERT for Natural Language Understanding | X. Jiao, Y. Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, and Q. Liu] researchers at Huawei produces a model called TinyBERT that is 7.5 times smaller and nearly 10 times faster than the original. It also reaches nearly the same language understanding performance as the original. | ||
| + | * [http://towardsdatascience.com/understanding-bert-is-it-a-game-changer-in-nlp-7cca943cf3ad Understanding BERT: Is it a Game Changer in NLP? | Bharat S Raj - Towards Data Science] | ||
* [[Google]] | * [[Google]] | ||
| + | |||
| + | |||
| + | <img src="http://miro.medium.com/max/916/1*8416XWqbuR2SDgCY61gFHw.png" width="500" height="200"> | ||
| + | |||
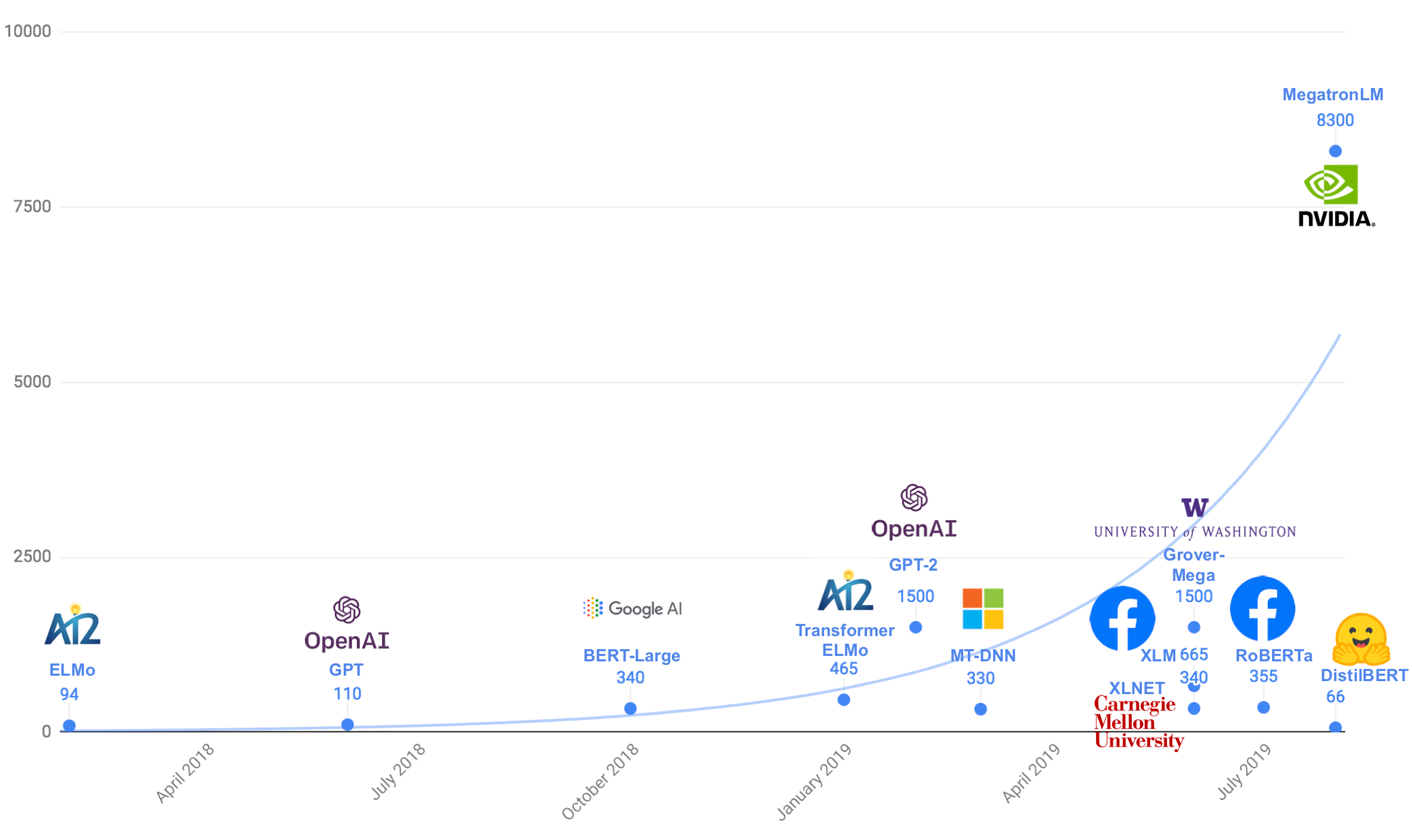
<img src="http://miro.medium.com/max/2070/1*IFVX74cEe8U5D1GveL1uZA.png" width="800" height="500"> | <img src="http://miro.medium.com/max/2070/1*IFVX74cEe8U5D1GveL1uZA.png" width="800" height="500"> | ||
Revision as of 22:27, 13 October 2019
Youtube search... ...Google search
- Google AI’s ALBERT claims top spot in multiple NLP performance benchmarks | Khari Johnson - VentureBeat
- Facebook AI’s RoBERTa improves Google’s BERT pretraining methods | Khari Johnson - VentureBeat
- Google's BERT - built on ideas from ULMFiT, ELMo, and OpenAI
- Attention Mechanism/Transformer Model
- Natural Language Processing (NLP)
- Microsoft makes Google’s BERT NLP model better | Khari Johnson - VentureBeat
- Watch me Build a Finance Startup | Siraj Raval
- Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT | Victor Sanh - Medium
- TinyBERT: Distilling BERT for Natural Language Understanding | X. Jiao, Y. Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, and Q. Liu researchers at Huawei produces a model called TinyBERT that is 7.5 times smaller and nearly 10 times faster than the original. It also reaches nearly the same language understanding performance as the original.
- Understanding BERT: Is it a Game Changer in NLP? | Bharat S Raj - Towards Data Science