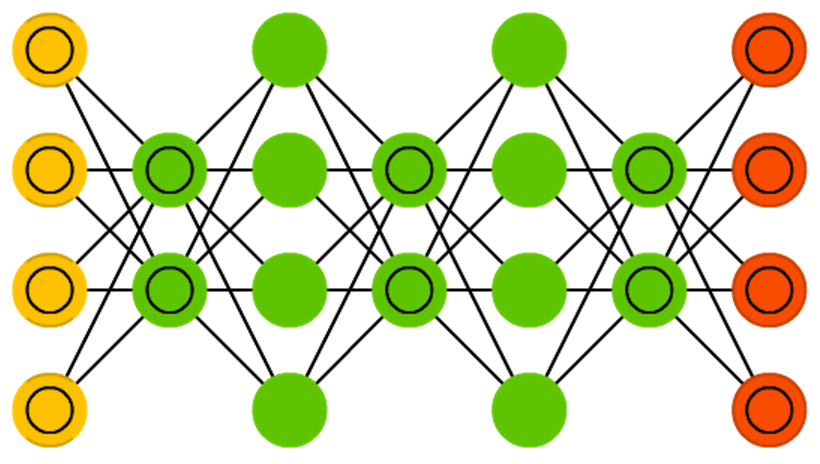
Deep Belief Network (DBN)
YouTube search... ...Google search
- Deep Learning
- Neural Network Zoo | Fjodor Van Veen
- Feature Exploration/Learning
- A Gentle Introduction to Bayesian Belief Networks | Jason Brownlee - Machine Learning Mastery
- Deep-Belief Networks | Chris Nicholson - A.I. Wiki pathmind
Stacked architectures of mostly Restricted Boltzmann Machine (RBM)s or Variational Autoencoder (VAE)s. These networks have been shown to be effectively trainable stack by stack, where each Autoencoder (AE) or Restricted Boltzmann Machine (RBM) only has to learn to encode the previous network. This technique is also known as greedy training, where greedy means making locally optimal solutions to get to a decent but possibly not optimal answer. DBNs can be trained through contrastive divergence or back-propagation and learn to represent the data as a probabilistic model, just like regular Restricted Boltzmann Machine (RBM)s or Variational Autoencoder (VAE)s. Once trained or converged to a (more) stable state through unsupervised learning, the model can be used to generate new data. If trained with contrastive divergence, it can even classify existing data because the neurons have been taught to look for different features. Bengio, Yoshua, et al. “Greedy layer-wise training of deep networks.” Advances in neural information processing systems 19 (2007): 153.