Natural Language Processing (NLP)
Youtube search... | Quora search... ...Google search
Speech recognition, (speech) translation, understanding (semantic parsing) complete sentences, understanding synonyms of matching words, sentiment analysis, and writing/generating complete grammatically correct sentences and paragraphs.
- NLP News | Sebastian Ruder
- Natural Language Tools & Services
- NLP Models:
- XLNet - unsupervised language representation learning method based on Transformer-XL and a novel generalized permutation language modeling objective
- Bidirectional Encoder Representations from Transformers (BERT) | Google - built on ideas from ULMFiT, ELMo, and OpenAI
- Transformer-XL - state-of-the-art autoregressive model
- GPT-2 OpenAI… GPT-2 - Too powerful NLP model (GPT-2) | Edward Ma - Towards Data Science
- Attention Mechanism/Transformer Model
- Recurrent Neural Network (RNN)
- NLP Techniques: A Preliminary Cornerstone List | Martin Messier
- Text Transfer Learning
- Outline of natural language processing | Wikipedia
- Natural Language Processing | Wikipedia
- Grammar Induction | Wikipedia
- Problem-solving with ML: automatic document classification | Ahmed Kachkach
- How do I learn Natural Language Processing? | Sanket Gupta
- Natural Language | Chris Umbel
- Language services | Cognitive Services | Microsoft Azure
- Natural Language Processing - Quick Guide | TutorialsPoint
- End-to-End Speech
- Courses & Certifications:
- Natural Language Processing with Deep Learning | Stanford
- CS 124: From Languages to Information | Dan Jurafsky - Stanford
- Natural Language Processing | Higher School of Economics
- Deep Learning for Natural Language Processing | Oxford - Phil Blunsom
- Getting Started with Natural Language Processing with Python | Swetha Kolalapudi
- Natural Language Processing (NLP) Microsoft | Lei Ma, Roland Fernandez, Xiaodong He
- NVIDIA Deep Learning Institute
- A Code-First Intro to Natural Language Processing | fast,ai
- Natural Language Processing | Yejin Choi - University of Washington
- YSDA Natural Language Processing | Yandex Data School
- Natural Language Processing | National Research University Higher School of Economics
- Applied Natural Language Processing | David Bamman - UC Berkeley
- Advanced Methods in Natural Language Processing | Tel Aviv University
- Advanced NLP with spaCy | Ines Montani (of Explosion AI)
Contents
- 1 Text Preprocessing
- 2 Relating Text
- 3 Natural Language Understanding (NLU)
- 4 Managed Vocabularies
- 5 Natural Language Inference (NLI) and Recognizing Textual Entailment (RTE)
- 6 Deep Learning Algorithms
- 7 Capabilities
Text Preprocessing
Cleaning and preparation the information for use, such as punctuation removal, spelling correction, lowercasing, stripping markup tags (HTML,XML)
Regular Expressions (Regex)
Youtube search... ...Google search
Search for text patterns, validate emails and URLs, capture information, and use patterns to save development time.

Soundex
Youtube search... ...Google search
a phonetic algorithm for indexing names by sound, as pronounced in English. The goal is for homophones to be encoded to the same representation so that they can be matched despite minor differences in spelling. The Soundex code for a name consists of a letter followed by three numerical digits: the letter is the first letter of the name, and the digits encode the remaining consonants. Consonants at a similar place of articulation share the same digit so, for example, the labial consonants B, F, P, and V are each encoded as the number 1. Wikipedia
The correct value can be found as follows:
- Retain the first letter of the name and drop all other occurrences of a, e, i, o, u, y, h, w.
- Replace consonants with digits as follows (after the first letter):
- b, f, p, v → 1
- c, g, j, k, q, s, x, z → 2
- d, t → 3
- l → 4
- m, n → 5
- r → 6
- If two or more letters with the same number are adjacent in the original name (before step 1), only retain the first letter; also two letters with the same number separated by 'h' or 'w' are coded as a single number, whereas such letters separated by a vowel are coded twice. This rule also applies to the first letter.
- If you have too few letters in your word that you can't assign three numbers, append with zeros until there are three numbers. If you have more than 3 letters, just retain the first 3 numbers.
Tokenization / Sentence Splitting
Youtube search... ...Google search
- Bag-of-Words (BoW)
- Continuous Bag-of-Words (CBoW)
- Ngram Viewer | Google Books
- Language Squad The Greatest Language Identifying & Guessing Game
Tokenization is the process of demarcating (breaking text into individual words) and possibly classifying sections of a string of input characters. The resulting tokens are then passed on to some other form of processing. The process can be considered a sub-task of parsing input. A token (or n-gram) is a contiguous sequence of n items from a given sample of text or speech. The items can be phonemes, syllables, letters, words or base pairs according to the application.

Word Embeddings
Youtube search... ...Google search
- Word2Vec
- Sense2Vec | Matthew Honnibal
- Global Vectors for Word Representation (GloVe)
- Word Embeddings Demo
- Representation Learning
- On the Dimensionality of Word Embedding | Zi Yin and Yuanyyuan Shen
- Introduction to Word Embedding and Word2Vec | Dhruvil Karani - Towards Data Science
- Unsupervised Cross-Modal Alignment of Speech and Text Embedding Spaces | Yu-An Chung, Wei-Hung Weng, Schrasing Tong, and James Glass
- Diffusion Maps for Textual Network Embedding | Xinyuan Zhang, Yitong Li, Dinghan Shen, and Lawrence Carin
- A Retrieve-and-Edit Framework for Predicting Structured Outputs | Tatsunori B. Hashimoto, Kelvin Guu, Yonatan Oren, and Percy Liang
The collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers.

Normalization
Youtube search... ...Google search
Process that converts a list of words to a more uniform sequence. .
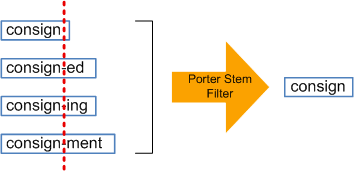
Stemming (Morphological Similarity)
Youtube search... ...Google search
Stemmers remove morphological affixes from words, leaving only the word stem. Refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes.
Lemmatization
Youtube search... ...Google search
Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma . If confronted with the token saw, stemming might return just s, whereas lemmatization would attempt to return either see or saw depending on whether the use of the token was as a verb or a noun. The two may also differ in that stemming most commonly collapses derivationally related words, whereas lemmatization commonly only collapses the different inflectional forms of a lemma. Stemming and lemmatization | Stanford.edu NLTK's lemmatizer knows "am" and "are" are related to "be."
Similarity
Youtube search... ...Google search
Word Similarity
Youtube search... ...Google search
- Mapping Word Embeddings with Word2vec | Sam Liebman - Towards Data Science
- Word2Vec
- WordNet - One of the most important uses is to find out the similarity among words

Text Clustering
Youtube search... ...Google search
Sentence/Document Similarity
Youtube search... ...Google search
- Term Frequency–Inverse Document Frequency (TF-IDF)
- Doc2Vec
- Text2Vec
- Applying the four-step "Embed, Encode, Attend, Predict" framework to predict document similarity | Sujit Pal
- Sentence Similarity in Python using Doc2Vec | Kanoki As a next step you can use the Bag of Words or TF-IDF model to covert these texts into numerical feature and check the accuracy score using cosine similarity.
Word embeddings have become widespread in Natural Language Processing. They allow us to easily compute the semantic similarity between two words, or to find the words most similar to a target word. However, often we're more interested in the similarity between two sentences or short texts. Comparing Sentence Similarity Methods | Yves Peirsman - NLPtown

Text Classification
Youtube search... ...Google search
- A Survey of Hierarchical Classification Across Different Application Domains | Carlos N. Silla Jr. and Alex A. Freitas
- Hierarchical Classification – a useful approach for predicting thousands of possible categories | Pedro Chaves - KDnuggets
Text Classification approaches:
- Flat - there is no inherent hierarchy between the possible categories the data can belong to (or we chose to ignore it). Train either a single classifier to predict all of the available classes or one classifier per category (1 vs All)
- Hierarchically - organizing the classes, creating a tree or DAG (Directed Acyclic Graph) of categories, exploiting the information on relationships among them. Although there are different types of hierarchical classification approaches, the difference between both modes of reasoning and analysing are particularly easy to understand in these illustrations, taken from a great review on the subject by Silla and Freitas (2011). Taking a top-down approach, training a classifier per level (or node) of the tree (again, although this is not the only hierarchical approach, it is definitely the most widely used and the one we’ve selected for our problem at hands), where a given decision will lead us down a different classification path.
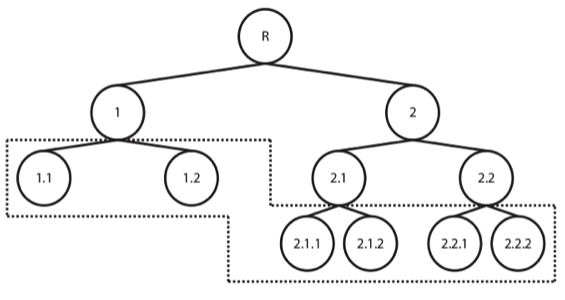
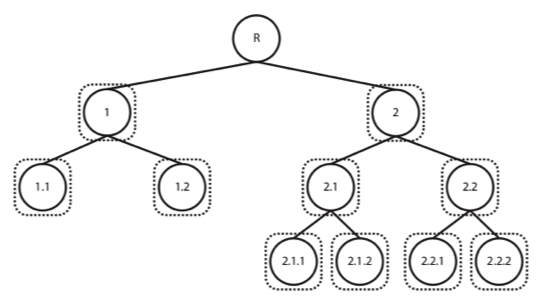
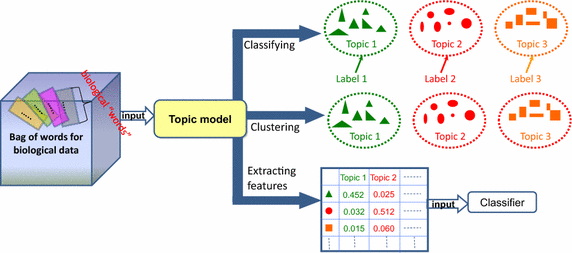
Topic Modeling
Youtube search... ...Google search
A type of statistical modeling for discovering the abstract “topics” that occur in a collection of documents. Latent Dirichlet Allocation (LDA) is an example of topic model and is used to classify text in a document to a particular topic
Whole Word Masking
Youtube search... ...Google search
Training the language model in BERT is done by predicting 15% of the tokens in the input, that were randomly picked. These tokens are pre-processed as follows — 80% are replaced with a “[MASK]” token, 10% with a random word, and 10% use the original word. The intuition that led the authors to pick this approach is as follows (Thanks to Jacob Devlin from Google for the insight):
- If we used [MASK] 100% of the time the model wouldn’t necessarily produce good token representations for non-masked words. The non-masked tokens were still used for context, but the model was optimized for predicting masked words.
- If we used [MASK] 90% of the time and random words 10% of the time, this would teach the model that the observed word is never correct.
- If we used [MASK] 90% of the time and kept the same word 10% of the time, then the model could just trivially copy the non-contextual embedding.
Identity Scrubbing
Youtube search... ...Google search
- MITRE Identification Scrubber Toolkit (MIST) ...suite of tools for identifying and redacting personally identifiable information (PII) in free-text. For example, MIST can help you convert this document:
Patient ID: P89474
Mary Phillips is a 45-year-old woman with a history of diabetes. She arrived at New Hope Medical Center on August 5 complaining of abdominal pain. Dr. Gertrude Philippoussis diagnosed her with appendicitis and admitted her at 10 PM.
into this:
Patient ID: [ID]
[NAME] is a [AGE]-year-old woman with a history of diabetes. She arrived at [HOSPITAL] on [DATE] complaining of abdominal pain. Dr. [PHYSICIAN] diagnosed her with appendicitis and admitted her at 10 PM.
or this:
Patient ID: ID586
Sandy Parkinson is a 34-year-old woman with a history of diabetes. She arrived at Mercy Hospital on July 10 complaining of abdominal pain. Dr. Myron Prendergast diagnosed her with appendicitis and admitted her at 10 PM.
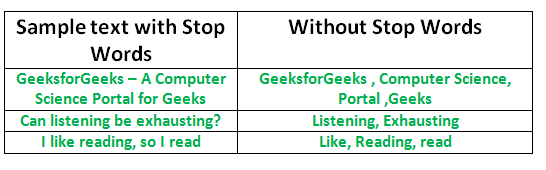
Stop Words
Youtube search... ...Google search
One of the major forms of pre-processing is to filter out useless data. In natural language processing, useless words (data), are referred to as stop words. A stop word is a commonly used word (such as “the”, “a”, “an”, “in”) that a search engine has been programmed to ignore, both when indexing entries for searching and when retrieving them as the result of a search query.
Relating Text
Understanding how the words relate to each other and the underlying grammar by segmenting the sentences syntax
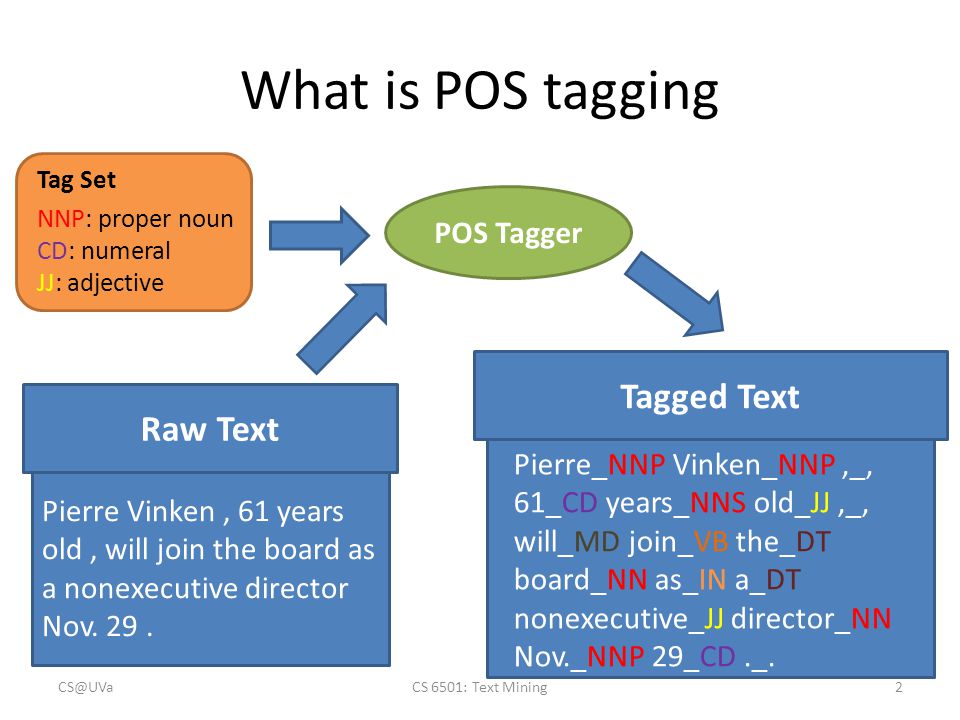
Part-of-Speech (POS) Tagging
Youtube search... ...Google search
(POST), also called grammatical tagging or word-category disambiguation, is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech,[1] based on both its definition and its context—i.e., its relationship with adjacent and related words in a phrase, sentence, or paragraph. A simplified form of this is commonly taught to school-age children, in the identification of words as nouns, verbs, adjectives, adverbs, etc.
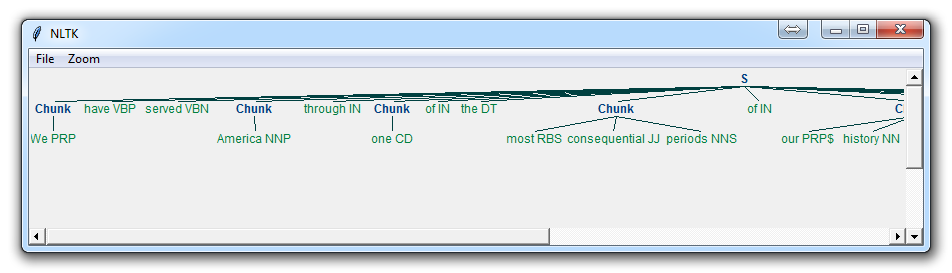
Chunking
Youtube search... ...Google search
The Hierarchy of Ideas (also known as chunking) is a linguistic tool used in NLP that allows the speaker to traverse the realms of abstract to specific easily and effortlessly. When we speak or think we use words that indicate how abstract, or how detailed we are in processing the information. In general, as human beings our brain is quite good at chunking information together in order to make it easier for us to process and simpler to understand. Thinking about the word “learning” for example is much simpler that thinking about all the different things that we could be learning about. When we memorise a telephone number or any other sequence of numbers we do not tend to memorise them as separate individual numbers, we group them together to make them easier to remember. Hierarchy of Ideas or Chunking in NLP | Excellence Assured

Chinking
Youtube search... ...Google search
The process of removing a sequence of tokens from a chunk. If the matching sequence of tokens spans an entire chunk, then the whole chunk is removed; if the sequence of tokens appears in the middle of the chunk, these tokens are removed, leaving two chunks where there was only one before. If the sequence is at the periphery of the chunk, these tokens are removed, and a smaller chunk remains.
Named Entity Recognition (NER)
Youtube search... ...Google search
- Introduction to Named Entity Recognition | Suvro Banerjee - Medium
- NERClassifierCombiner | Stanford CoreNLP
- NLP Keras model in browser with TensorFlow.js
(also known as entity identification, entity chunking, sequence tagging, part-of-speech tagging, and entity extraction) is a subtask of information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. Most research on NER systems has been structured as taking an unannotated block of text, and producing an annotated block of text that highlights the names of entities.
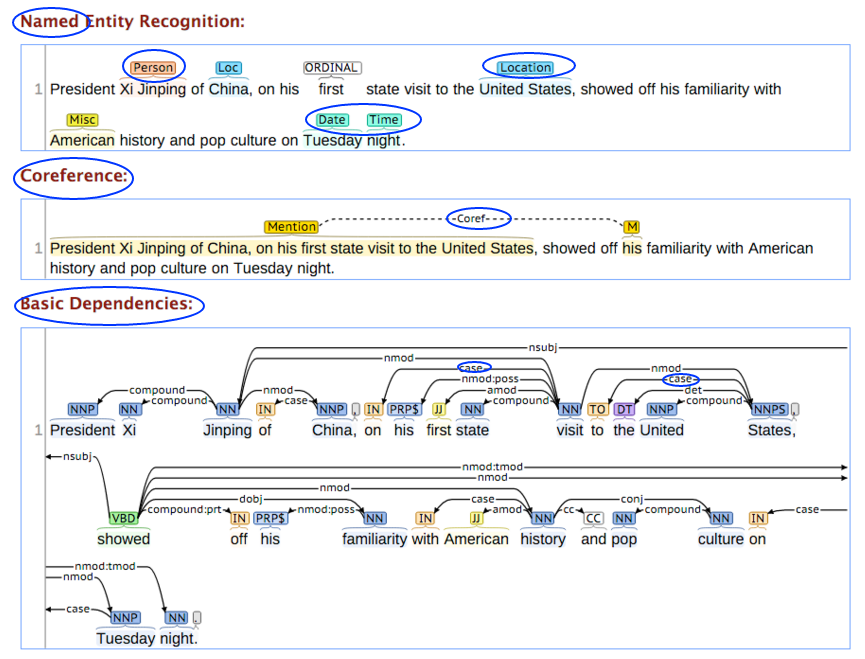
Relation Extraction
Youtube search... ...Google search
task of extracting semantic relationships from a text. Extracted relationships usually occur between two or more entities of a certain type (e.g. Person, Organisation, Location) and fall into a number of semantic categories (e.g. married to, employed by, lives in). Relationship Extraction
 Relation Extraction | Jun Tian
Relation Extraction | Jun Tian
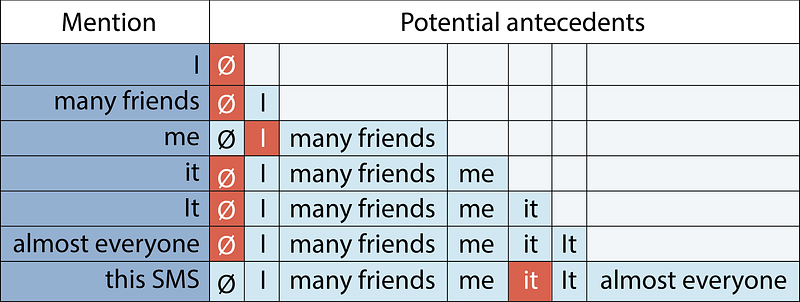
Neural Coreference
Youtube search... ...Google search
Coreference is the fact that two or more expressions in a text – like pronouns or nouns – link to the same person or thing. It is a classical Natural language processing task, that has seen a revival of interest in the past two years as several research groups applied cutting-edge deep-learning and reinforcement-learning techniques to it. It is also one of the key building blocks to building conversational Artificial intelligences.
Natural Language Understanding (NLU)
Youtube search... | Quora search... ...Google search
- Speech and Language Processing | Dan Jurafsky and James H. Martin (3rd ed. draft)
- The Stanford Natural Language Inference (SNLI) Corpus
- Extracting Information from Text | NLTK.org
- Topic Model/Mapping
- Linguistic Correlation Analysis - Putting neural networks under the microscope | Rob Matheson
- Google Docs uses AI to catch your grammar mistakes | Jon Fingas - Engadget
- Document Understanding AI | Google
- Sequence to Sequence (Seq2Seq)
- NLP/NLU/NLI Benchmarks:
- Reading Comprehension
- Text Classification
- General Language Understanding Evaluation (GLUE)
- The Stanford Question Answering Dataset (SQuAD)
- ReAding Comprehension {RACE)
Natural-language understanding (NLU) or natural-language interpretation (NLI) is a subtopic of natural-language processing in artificial intelligence that deals with machine reading comprehension. There is considerable commercial interest in the field because of its application to automated reasoning, machine translation, question answering, news-gathering, text categorization, voice-activation, archiving, and large-scale content analysis.
NLU is the post-processing of text, after the use of NLP algorithms (identifying parts-of-speech, etc.), that utilizes context from recognition devices (automatic speech recognition [ASR], vision recognition, last conversation, misrecognized words from ASR, personalized profiles, microphone proximity etc.), in all of its forms, to discern meaning of fragmented and run-on sentences to execute an intent from typically voice commands. NLU has an ontology around the particular product vertical that is used to figure out the probability of some intent. An NLU has a defined list of known intents that derives the message payload from designated contextual information recognition sources. The NLU will provide back multiple message outputs to separate services (software) or resources (hardware) from a single derived intent (response to voice command initiator with visual sentence (shown or spoken) and transformed voice command message too different output messages to be consumed for M2M communications and actions) Natural-language understanding | Wikipedia
NLU uses algorithms to reduce human speech into a structured ontology. Then AI algorithms detect such things as intent, timing, locations, and sentiments. ... Natural language understanding is the first step in many processes, such as categorizing text, gathering news, archiving individual pieces of text, and, on a larger scale, analyzing content. Real-world examples of NLU range from small tasks like issuing short commands based on comprehending text to some small degree, like rerouting an email to the right person based on basic syntax and a decently-sized lexicon. Much more complex endeavors might be fully comprehending news articles or shades of meaning within poetry or novels. NLP vs. NLU: from Understanding a Language to Its Processing | Sciforce
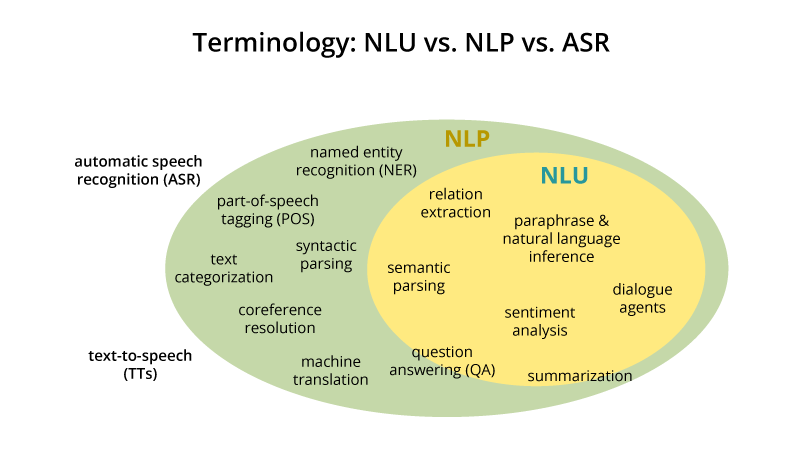 Image Source: Understanding Natural Language Understanding | Bill MacCartney
Image Source: Understanding Natural Language Understanding | Bill MacCartney
Managed Vocabularies
Corpora
Youtube search... ...Google search
A corpus (plural corpora) or text corpus is a large and structured set of texts (nowadays usually electronically stored and processed). In corpus linguistics, they are used to do statistical analysis and hypothesis testing, checking occurrences or validating linguistic rules within a specific language territory.
Ontologies
Youtube search... ...Google search
(aka knowledge graph) can incorporate computable descriptions that can bring insight in a wide set of compelling applications including more precise knowledge capture, semantic data integration, sophisticated query answering, and powerful association mining - thereby delivering key value for health care and the life sciences.
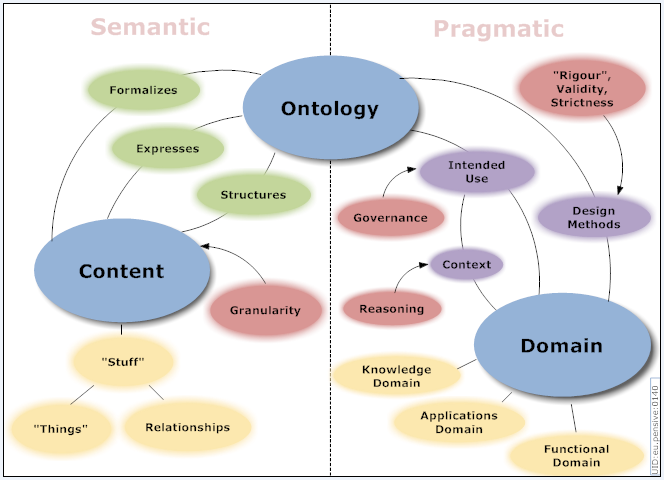
Taxonomies
Youtube search... ...Google search

Natural Language Inference (NLI) and Recognizing Textual Entailment (RTE)
Youtube search... ...Google search
Identifying whether one piece of text can be plausibly inferred from another - automatic acquisition of paraphrases, lexical semantic relationships, inference methods, knowledge representations for applications such as question answering, information extraction and summarization.
Semantic Role Labeling (SRL)
Youtube search... ...Google search
identifies shallow semantic information in a given sentence. The tool labels verb-argument structure, identifying who did what to whom by assigning roles that indicate the agent, patient, and theme of each verb to constituents of the sentence representing entities related by the verb.
Deep Learning Algorithms
Youtube search... ...Google search
- Deep Q Network (DQN)
- 7 types of Artificial Neural Networks for Natural Language Processing
- Combination of Convolutional and Recurrent Neural Network for Sentiment Analysis of Short Texts | Xingyou Wang, Weijie Jiang, Zhiyong Luo
- Autoencoders / Encoder-Decoders
- LSTM
- GRU

Capabilities
Summarization
Youtube search... ...Google search
- A neural network can read scientific papers and render a plain-English summary | David L. Chandler - TechExplore
- Auto-tagging
Sentiment Analysis
Youtube search... ...Google search
- Watch me Build a Finance Startup | Siraj Raval
- Auto-tagging
Wikifier
Youtube search... ...Google search
Sapir Whorf Hypothesis - How language shapes the way we think
Youtube search... ...Google search
Workbench / Pipeline
Youtube search... ...Google search
- Natural Language Tools & Services
- Outline of natural language processing | Wikipedia
- CogComp NLP Pipeline | Cognitive Computation Group, led by Prof. Dan Roth
- Building Custom Text Analytics solutions using Azure Machine Learning (AML)
- H2O Driverless AI
- GATE toolkit
- Google Kubeflow Pipelines
- Apache UIMA - Unstructured Information Management Applications