Difference between revisions of "Hierarchical Clustering; Agglomerative (HAC) & Divisive (HDC)"
m |
m (Text replacement - "http:" to "https:") |
||
| Line 5: | Line 5: | ||
|description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | ||
}} | }} | ||
| − | [ | + | [https://www.youtube.com/results?search_query=Hierarchical+Agglomerative+Clustering+HAC Youtube search...] |
| − | [ | + | [https://www.google.com/search?q=Hierarchical+Cluster+Agglomerative+Divisive+HDC+Clustering+HAC+learning+ML ...Google search] |
* [[AI Solver]] | * [[AI Solver]] | ||
| Line 16: | Line 16: | ||
* [[Hierarchical Temporal Memory (HTM)]] | * [[Hierarchical Temporal Memory (HTM)]] | ||
* [[K-Means]] | * [[K-Means]] | ||
| − | * [ | + | * [https://www.r-bloggers.com/how-to-perform-hierarchical-clustering-using-r/ How to Perform Hierarchical Clustering using R | Perceptive Analytics] |
| − | * [ | + | * [https://www.researchgate.net/publication/315966848_Exploreing_K-Means_with_Internal_Validity_Indexes_for_Data_Clustering_in_Traffic_Management_System Exploreing K-Means with Internal Validity Indexes for Data Clustering in Traffic Management System | S. Nawrin, S. Akhter and M. Rahatur] |
| Line 24: | Line 24: | ||
# Divisive (HDC - DIANA); top-down, first groups all examples into one cluster and then iteratively divides the cluster into a hierarchical tree. | # Divisive (HDC - DIANA); top-down, first groups all examples into one cluster and then iteratively divides the cluster into a hierarchical tree. | ||
| − | + | https://i1.wp.com/r-posts.com/wp-content/uploads/2017/12/Agnes.png | |
{|<!-- T --> | {|<!-- T --> | ||
| Line 36: | Line 36: | ||
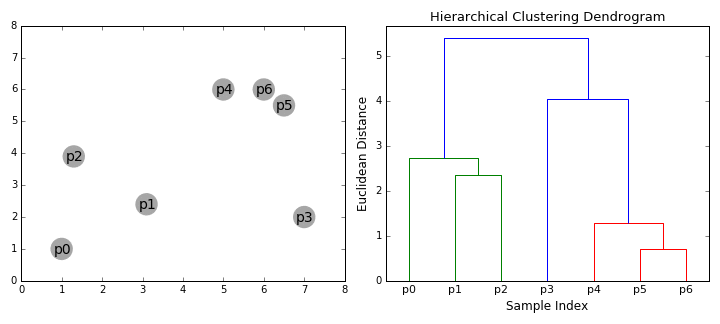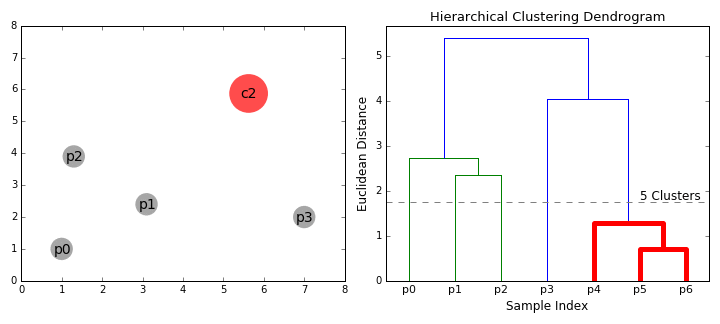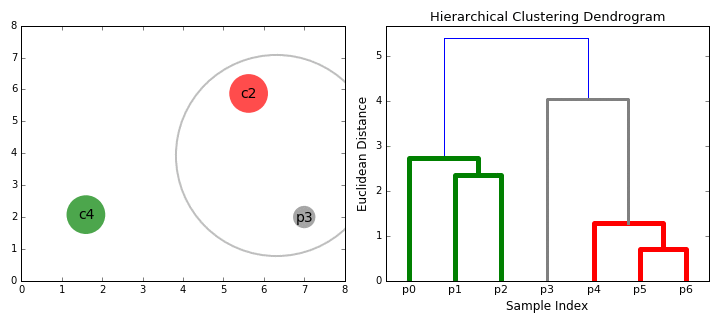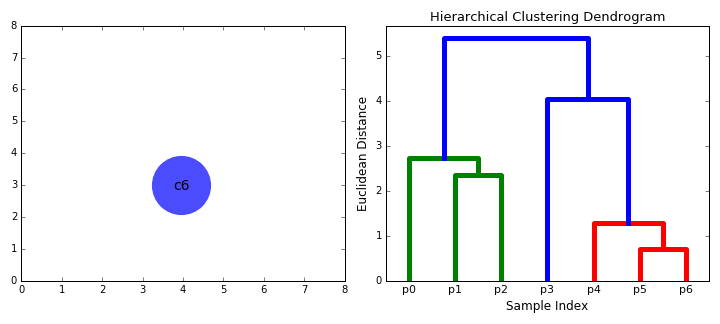
== Agglomerative Clustering - Bottom Up == | == Agglomerative Clustering - Bottom Up == | ||
| − | Bottom-up algorithms treat each data point as a single cluster at the outset and then successively merge (or agglomerate) pairs of clusters until all clusters have been merged into a single cluster that contains all data points. Bottom-up hierarchical clustering is therefore called hierarchical agglomerative clustering or HAC. This hierarchy of clusters is represented as a tree (or dendrogram). The root of the tree is the unique cluster that gathers all the samples, the leaves being the clusters with only one sample. [ | + | Bottom-up algorithms treat each data point as a single cluster at the outset and then successively merge (or agglomerate) pairs of clusters until all clusters have been merged into a single cluster that contains all data points. Bottom-up hierarchical clustering is therefore called hierarchical agglomerative clustering or HAC. This hierarchy of clusters is represented as a tree (or dendrogram). The root of the tree is the unique cluster that gathers all the samples, the leaves being the clusters with only one sample. [https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68 The 5 Clustering Algorithms Data Scientists Need to Know | Towards Data Science] |
Hierarchical clustering does not require us to specify the number of clusters and we can even select which number of clusters looks best since we are building a tree. Additionally, the algorithm is not sensitive to the choice of distance metric; all of them tend to work equally well whereas with other clustering algorithms, the choice of distance metric is critical. A particularly good use case of hierarchical clustering methods is when the underlying data has a hierarchical structure and you want to recover the hierarchy; other clustering algorithms can’t do this. These advantages of hierarchical clustering come at the cost of lower efficiency, as it has a time complexity of O(n³), unlike the linear complexity of K-Means and GMM. | Hierarchical clustering does not require us to specify the number of clusters and we can even select which number of clusters looks best since we are building a tree. Additionally, the algorithm is not sensitive to the choice of distance metric; all of them tend to work equally well whereas with other clustering algorithms, the choice of distance metric is critical. A particularly good use case of hierarchical clustering methods is when the underlying data has a hierarchical structure and you want to recover the hierarchy; other clustering algorithms can’t do this. These advantages of hierarchical clustering come at the cost of lower efficiency, as it has a time complexity of O(n³), unlike the linear complexity of K-Means and GMM. | ||
Revision as of 18:02, 28 March 2023
Youtube search... ...Google search
- AI Solver
- Capabilities
- Clustering
- Hierarchical Cluster Analysis (HCA)
- Hierarchical Temporal Memory (HTM)
- K-Means
- How to Perform Hierarchical Clustering using R | Perceptive Analytics
- Exploreing K-Means with Internal Validity Indexes for Data Clustering in Traffic Management System | S. Nawrin, S. Akhter and M. Rahatur
Hierarchical clustering algorithms actually fall into 2 categories:
- Agglomerative (HAC - AGNES); bottom-up, first assigns every example to its own cluster, and iteratively merges the closest clusters to create a hierarchical tree.
- Divisive (HDC - DIANA); top-down, first groups all examples into one cluster and then iteratively divides the cluster into a hierarchical tree.

Agglomerative Clustering - Bottom UpBottom-up algorithms treat each data point as a single cluster at the outset and then successively merge (or agglomerate) pairs of clusters until all clusters have been merged into a single cluster that contains all data points. Bottom-up hierarchical clustering is therefore called hierarchical agglomerative clustering or HAC. This hierarchy of clusters is represented as a tree (or dendrogram). The root of the tree is the unique cluster that gathers all the samples, the leaves being the clusters with only one sample. The 5 Clustering Algorithms Data Scientists Need to Know | Towards Data Science Hierarchical clustering does not require us to specify the number of clusters and we can even select which number of clusters looks best since we are building a tree. Additionally, the algorithm is not sensitive to the choice of distance metric; all of them tend to work equally well whereas with other clustering algorithms, the choice of distance metric is critical. A particularly good use case of hierarchical clustering methods is when the underlying data has a hierarchical structure and you want to recover the hierarchy; other clustering algorithms can’t do this. These advantages of hierarchical clustering come at the cost of lower efficiency, as it has a time complexity of O(n³), unlike the linear complexity of K-Means and GMM.
Divisive Clustering = Top Down
|