Few Shot Learning
YouTube ... Quora ...Google search ...Google News ...Bing News
- Learning Techniques
- Perspective ... Context ... In-Context Learning (ICL) ... Transfer Learning ... Out-of-Distribution (OOD) Generalization
- Causation vs. Correlation ... Autocorrelation ...Convolution vs. Cross-Correlation (Autocorrelation)
- Prompt Engineering (PE) ...PromptBase ... Prompt Injection Attack
- Embedding ... Fine-tuning ... RAG ... Search ... Clustering ... Recommendation ... Anomaly Detection ... Classification ... Dimensional Reduction. ...find outliers
- Understanding few-shot learning in machine learning | Michael J. Garbade
- On First-Order Meta-Learning Algorithms | A. Nichol, J. Achiam, and J. Schulman - OpenAI
- Learning to Learn | Chelsea Finn
- 'Less Than One'-Shot Learning: Learning N Classes From M<N Samples | Ilia Sucholutsky and Matthias Schonlau ...uses a soft-label generalization of the k-Nearest Neighbors classifier to explore the intricate decision landscapes
- ChatGPT Prompt Engineering, “Let’s Think Step by Step”, and other Magic Phrases - Mr Newq - Medium
Most of the time, computer vision systems need to see hundreds or thousands (or even millions) of examples to figure out how to do something. Zero-shot learning, one-shot learning, and few-shot learning are all methods of machine learning that are used when there is limited data available for training a model. They differ in the amount of data used for training. One-shot and few-shot learning try to create a system that can be taught to do something with far less training. It’s similar to how toddlers might learn a new concept or task.
Contents
Zero-Shot Learning
A model is trained without using any labeled data. Instead of giving training examples, zero-shot learning gives a high-level description of new categories so that the machine can relate it to existing categories that the machine has learned about. For example, Hugging Face transformers use zero-shot classification for more than 60 per cent of its transformers.
Zero-Shot Prompting
Zero-Shot Chain of Thought (CoT) prompting is a technique for enabling Large Language Model (LLM)s to perform multi-step reasoning without any training on task-specific examples through Fine-tuning. This is in contrast to traditional CoT prompting, which requires a few hand-crafted step-by-step reasoning demonstrations for each task. Zero-shot CoT prompting is possible because LLMs are trained on massive datasets of text and code, which gives them a broad understanding of the world and the ability to perform many different kinds of tasks. When prompted with a zero-shot CoT prompt, an LLM can use its knowledge and reasoning abilities to solve the task, even if it has never seen a similar task before.
Here are some of the benefits of using zero-shot CoT prompting:
- Convenience: Zero-shot CoT prompting is much more convenient than traditional CoT prompting, because it does not require any hand-crafted training examples. This makes it possible to use CoT prompting on a wider range of tasks, and to use it more quickly and easily.
- Data efficiency: Zero-shot CoT prompting is also more data-efficient than traditional CoT prompting. This is because zero-shot CoT prompting does not require any task-specific training data. This is especially important for tasks where it is difficult or expensive to obtain labeled training data.
- Generalization ability: Zero-shot CoT prompting has been shown to improve the generalization ability of LLMs to new tasks and datasets. This is because zero-shot CoT prompting teaches LLMs to solve tasks in a more generalizable way, rather than learning to solve specific examples.
One-Shot Learning
Only one instance or example is used for each category to train the model. This method is helpful in deep learning models such as computer vision images and facial recognition.
Few-Shot Learning
Feeding models with very minimal data, usually between two and five examples. Few-shot learning is a test base where computers are expected to learn from a few examples like humans. For example, machines can learn rare diseases by using few-shot learning. They use computer vision models to classify the anomalies with few-shot learning by using a very small amount of data.
- Firstly, few-shot learning can be used as a test base for learning like a human. Humans can spot the difference between handwritten characters after seeing a few examples, while computers need large amounts of data to classify what they “see” and spot the difference between handwritten characters. Few-shot learning is a test base where computers are expected to learn from few examples like humans.
- Secondly, few-shot learning can be used for learning for rare cases. By using few-shot learning, machines can learn rare cases. For example, when classifying images of animals, a machine learning model trained with few-shot learning techniques can classify an image of a rare species correctly after being exposed to small amount of prior information.
- Lastly, few-shot learning can help in reducing data collection effort and computational costs. As few-shot learning requires less data to train a model, high costs related to data collection and labeling are eliminated. Low amount of training data means low dimensionality in the training dataset, which can significantly reduce the computational costs.
Advances in few-shot learning: a guided tour | Oscar Knagg
- Advances in few-shot learning: reproducing results in PyTorch | Oscar Knagg- Towards Data Science
- Building a Speaker Identification System from Scratch with Deep Learning | Oscar Knagg- Medium
N-shot, k-way classification tasks
The ability of a algorithm to perform few-shot learning is typically measured by its performance on n-shot, k-way tasks. These are run as follows:
- A model is given a query sample belonging to a new, previously unseen class
- It is also given a support set, S, consisting of n examples each from k different unseen classes
- The algorithm then has to determine which of the support set classes the query sample belongs to
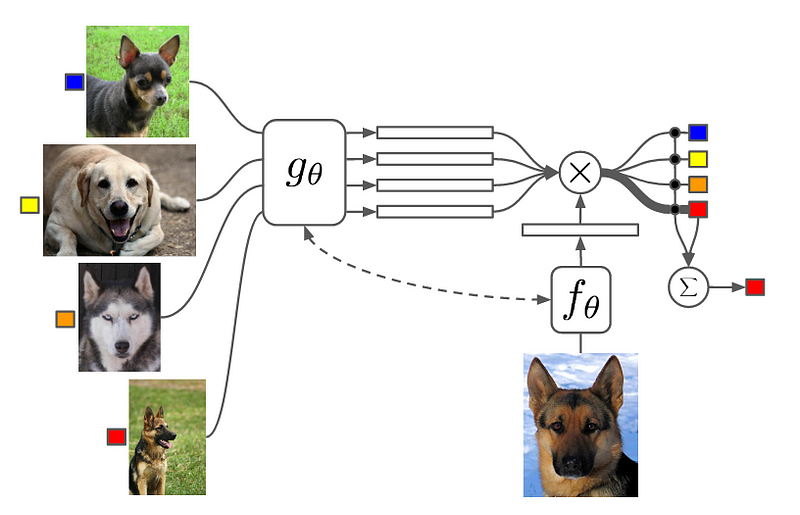
Matching Networks
combine both embedding and classification to form an end-to-end differentiable nearest neighbors classifier.
- Embed a high dimensional sample into a low dimensional space
- Perform a generalized form of nearest-neighbors classification
The meaning of this is that the prediction of the model, y^, is the weighted sum of the labels, y_i, of the support set, where the weights are a pairwise similarity function, a(x^, x_i), between the query example, x^, and a support set samples, x_i. The labels y_i in this equation are one-hot encoded label vectors.
Matching Networks are end-to-end differentiable provided the attention function a(x^, x_i) is differentiable.
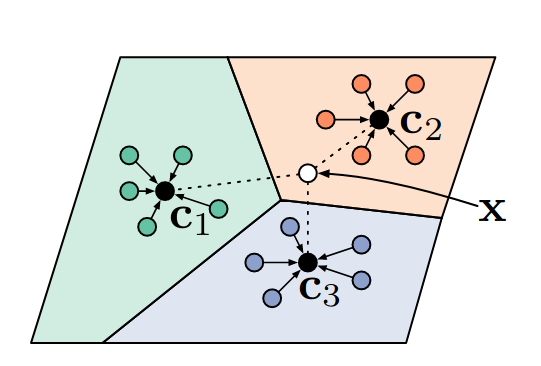
Prototypical Networks
learn class prototypes directly from a high level description of a class such as labelled attributes or a natural language description. Once you’ve done this it’s possible to classify new images as a particular class without having seen an image of that class.
- apply a compelling inductive bias in the form of class prototypes to achieve impressive few-shot performance — exceeding Matching Networks without the complication of FCE. The key assumption is made is that there exists an embedding in which samples from each class cluster around a single prototypical representation which is simply the mean of the individual samples.
- use euclidean distance over cosine distance in metric learning that also justifies the use of class means as prototypical representations. The key is to recognise that squared euclidean distance (but not cosine distance) is a member of a particular class of distance functions known as Bregman divergences.
Model-agnostic Meta-learning (MAML)
YouTube search... ...Google search
- Model-agnostic Meta-Learning: Learning to fine-tune | C. Finn, P. Abbeel, and S. Levine
- Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks (MAML)
learning a network initialization that can quickly adapt to new tasks — this is a form of meta-learning or learning-to-learn. The end result of this meta-learning is a model that can reach high performance on a new task with as little as a single step of regular gradient descent. The brilliance of this approach is that it can not only work for supervised regression and classification problems but also for reinforcement learning using any differentiable model!
MAML does not learn on batches of samples like most deep learning algorithms but batches of tasks AKA meta-batches.
- For each task in a meta-batch we first initialize a new “fast model” using the weights of the base meta-learner.
- compute the gradient and hence a parameter update from samples drawn from that task
- update the weights of the fast model i.e. perform typical mini-batch stochastic gradient descent on the weights of the fast model.
- we sample some more, unseen, samples from the same task and calculate the loss on the task of the updated weights (AKA fast model) of the meta-learner.
- update the weights of the meta-learner by taking the gradient of the sum of losses from the post-update weights . This is in fact taking the gradient of a gradient and hence is a second-order update — the MAML algorithm differentiates through the unrolled training process... optimising for the performance of the base model after a gradient step i.e. we are optimising for quick and easy gradient descent. The result of this is that the meta-learner can be trained by gradient descent on datasets as small as a single example per class without overfitting.

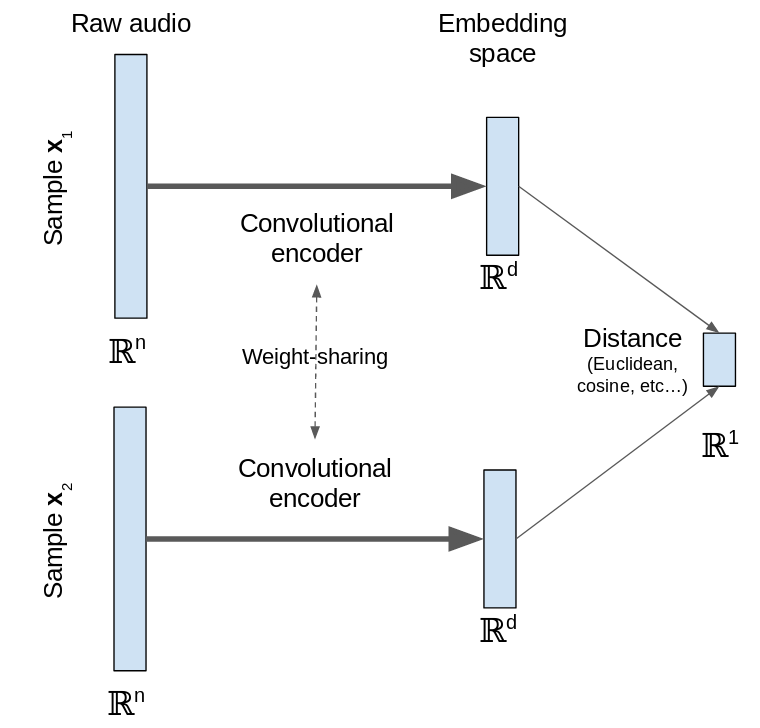
Siamese Networks
YouTube search... ...Google search
take two separate samples as inputs instead of just one. Each of these two samples is mapped from a high-dimensional input space into a low-dimensional space by an encoder network. The “siamese” nomenclature comes from the fact that the two encoder networks are “twins” as they share the same weights and learn the same function.
These two networks are then joined at the top by a layer that calculates a measure of distance (e.g. euclidean distance) between the two samples in the embedding space. The network is trained to make this distance small for similar samples and large for dissimilar samples. I leave the definition of similar and dissimilar open here but typically this is based on whether the samples are from the same class in a labelled dataset.
Hence when we train the siamese network it is learning to map samples from the input space (raw audio in this case) into a low-dimensional embedding space that is easier to work with. By including this distance layer we are trying to optimize the properties of the embedding directly instead of optimizing for classification accuracy.