Bayes
YouTube ... Quora ...Google search ...Google News ...Bing News
- Analytics ... Visualization ... Graphical Tools ... Diagrams & Business Analysis ... Requirements ... Loop ... Bayes ... Network Pattern
- AI Solver ... Algorithms ... Administration ... Model Search ... Discriminative vs. Generative ... Train, Validate, and Test
- Math for Intelligence ... Finding Paul Revere ... Social Network Analysis (SNA) ... Dot Product ... Kernel Trick
- Monte Carlo
- Strategy & Tactics ... Project Management ... Best Practices ... Checklists ... Project Check-in ... Evaluation ... Measures
- Bayesian Probability | Wikipedia
- Bayesian Inference | Wikipedia
- Feature Engineering and Selection: A Practical Approach for Predictive Models - 12.1 Naive Bayes Models | Max Kuhn and Kjell Johnson
Contents
Bayes' Theorem
YouTube ... Quora ...Google search ...Google News ...Bing News
- Bayes' theorem | Wikipedia
- Evidence Under Bayes' Theorem | Wikipedia
- Bayes' Theorem - Math is Fun
- Bayes Theorem | Definition & Example | Britannica
Bayes' theorem describes how to update the probabilities of hypotheses when given evidence. It follows simply from the axioms of conditional probability, but can be used to powerfully reason about a wide range of problems involving belief updates.
The probability of an event, based on prior knowledge of conditions that might be related to the event. Bayes' Theorem | Wikipedia
To expand on Bayes' theorem, we can think of it as a way of combining prior knowledge or belief with new evidence or data. The prior probability represents what we already know about the hypothesis before seeing the evidence. The likelihood represents how consistent the evidence is with the hypothesis. The marginal likelihood represents how probable the evidence is under any hypothesis. The posterior probability represents how probable the hypothesis is after seeing the evidence.
Bayes' theorem can be used for a variety of applications, such as:
- Testing medical diagnoses based on symptoms and test results - Filtering spam emails based on word frequencies - Finding the most likely cause of a system failure based on error messages - Estimating the parameters of a statistical model based on observed data - Updating beliefs about the state of the world based on new information

Bayesian Hypothesis Testing
Youtube search... ...Google search
- The Design of Experiments | Wikipedia ...a 1935 book by the English statistician Ronald Fisher is considered a foundational work in experimental design
Statistical Hypothesis is a hypothesis that is testable on the basis of observed data modeled as the realized values taken by a collection of random variables. A set of data (or several sets of data, taken together) are modelled as being realized values of a collection of random variables having a joint probability distribution in some set of possible joint distributions. The hypothesis being tested is exactly that set of possible probability distributions. A statistical hypothesis test is a method of statistical inference. An alternative hypothesis is proposed for the probability distribution of the data, either explicitly or only informally. The comparison of the two models is deemed statistically significant if, according to a threshold probability -- the significance level -- the data is very unlikely to have occurred under the null hypothesis. A hypothesis test specifies which outcomes of a study may lead to a rejection of the null hypothesis at a pre-specified level of significance, while using a pre-chosen measure of deviation from that hypothesis (the test statistic, or goodness-of-fit measure). The pre-chosen level of significance is the maximal allowed "false positive rate". One wants to control the risk of incorrectly rejecting a true null hypothesis. Statistical hypothesis testing | Wikipedia
Null Hypothesis in inferential statistics is a general statement or default position that there is no difference between two measured phenomena or that two samples derive from the same general population. Testing (rejecting or not rejecting) the null hypothesis—and thus concluding that there are (or there are not) grounds for believing that there is a relationship between two phenomena (e.g., that a potential treatment has a measurable effect)—is a central task in the modern practice of science; the field of statistics, more specifically hypothesis testing, gives precise criteria for rejecting or not rejecting a null hypothesis within a confidence level. The null hypothesis is generally assumed to be true until evidence indicates otherwise (similar to the case that a defendant of a jury trial is presumed innocent until proven guilty). Null hypothesis | Wikipedia
Naive Bayes
Youtube search... ...Google search
- How to Develop a Naive Bayes Classifier from Scratch in Python | Jason Brownlee - Machine Learning Mastery
- A Beginner's Guide to Bayes' Theorem, Naive Bayes Classifiers and Bayesian Networks | Chris Nicholson - A.I. Wiki pathmind
- Random Naive Bayes | Wikipedia
This algorithm is based on the “Bayes’ Theorem” in probability. Due to that Naive Bayes can be applied only if the features are independent of each other since it is a requirement in Bayes’ Theorem. If we try to predict a flower type by its petal length and width, we can use Naive Bayes approach since both those features are independent. 10 Machine Learning Algorithms You need to Know | Sidath Asir @ Medium
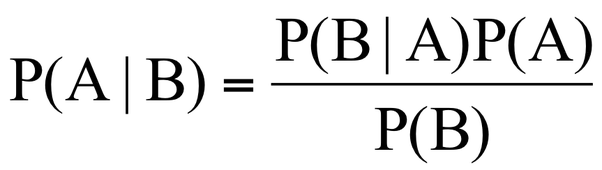
Naive Bayes classifiers are a family of simple "probabilistic classifiers" based on applying Bayes' theorem with strong (naïve) independence assumptions between the features. They are among the simplest Bayesian network models. But they could be coupled with Kernel density estimation and achieve higher accuracy levels. Naïve Bayes classifiers are highly scalable, requiring a number of parameters linear in the number of variables (features/predictors) in a learning problem. Maximum-likelihood training can be done by evaluating a closed-form expression,[4]:718 which takes linear time, rather than by expensive iterative approximation as used for many other types of classifiers. In the statistics and computer science literature, Naive Bayes models are known under a variety of names, including simple Bayes and independence Bayes. Naive Bayes Classifier | Wikipedia
Two-Class Bayes Point Machine
Youtube search... ...Google search
This algorithm efficiently approximates the theoretically optimal Bayesian average of linear classifiers (in terms of generalization performance) by choosing one "average" classifier, the Bayes Point. Because the Bayes Point Machine is a Bayesian classification model, it is not prone to overfitting to the training data. - Microsoft
Naive Bayes Spam Filtering
Youtube search... ...Google search
Naive Bayes classifiers are a popular statistical technique of e-mail filtering. They typically use bag of words features to identify spam e-mail, an approach commonly used in text classification. Naive Bayes classifiers work by correlating the use of tokens (typically words, or sometimes other things), with spam and non-spam e-mails and then using Bayes' theorem to calculate a probability that an email is or is not spam. Naive Bayes spam filtering is a baseline technique for dealing with spam that can tailor itself to the email needs of individual users and give low false positive spam detection rates that are generally acceptable to users. It is one of the oldest ways of doing spam filtering, with roots in the 1990s.Naive Bayes Spam Filtering | Wikipedia
Bayesian Poisoning
Youtube search... ...Google search
Bayesian poisoning is a technique used by e-mail spammers to attempt to degrade the effectiveness of spam filters that rely on Bayesian spam filtering. Bayesian filtering relies on Bayesian probability to determine whether an incoming mail is spam or is not spam. The spammer hopes that the addition of random (or even carefully selected) words that are unlikely to appear in a spam message will cause the spam filter to believe the message to be legitimate—a statistical type II error. Spammers also hope to cause the spam filter to have a higher false positive rate by turning previously innocent words into spammy words in the Bayesian database (statistical type I errors) because a user who trains their spam filter on a poisoned message will be indicating to the filter that the words added by the spammer are a good indication of spam. Bayesian Poisoning | Wikipedia
Bayesian Statistics
Prior
Youtube search... ...Google search
Prior probability distribution in Bayesian statistical inference often simply called the prior, of an uncertain quantity is the probability distribution that would express one's beliefs about this quantity before some evidence is taken into account. For example, the prior could be the probability distribution representing the relative proportions of voters who will vote for a particular politician in a future election. The unknown quantity may be a parameter of the model or a latent variable rather than an observable variable. Bayes' theorem calculates the renormalized pointwise product of the prior and the likelihood function, to produce the posterior probability distribution, which is the conditional distribution of the uncertain quantity given the data. Similarly, the prior probability of a random event or an uncertain proposition is the unconditional probability that is assigned before any relevant evidence is taken into account. Priors can be created using a number of methods.Prior Probability | Wikipedia
Likelihood
Youtube search... ...Google search
Likelihood principle is the proposition that, given a statistical model, all the evidence in a sample relevant to model parameters is contained in the likelihood function. A likelihood function arises from a probability density function considered as a function of its distributional parameterization argument.Prior Probability | Wikipedia
Bayesian Data Analysis
Youtube search... ...Google search
|
|
|
|
Bayes Error Rate
Youtube search... ...Google search
In statistical classification, Bayes error rate is the lowest possible error rate for any classifier of a random outcome (into, for example, one of two categories) and is analogous to the irreducible error. A number of approaches to the estimation of the Bayes error rate exist. One method seeks to obtain analytical bounds which are inherently dependent on distribution parameters, and hence difficult to estimate. Another approach focuses on class densities, while yet another method combines and compares various classifiers. The Bayes error rate finds important use in the study of patterns and machine learning techniques. Bayes Error Rate |Wikipedia
Bayes Linear Statistics
YouTube search... ...Google search
Bayes linear statistics is a subjectivist statistical methodology and framework. Traditional subjective Bayesian analysis is based upon fully specified probability distributions, which are very difficult to specify at the necessary level of detail. Bayes linear analysis attempts to solve this problem by developing theory and practise for using partially specified probability models. Bayes linear in its current form has been primarily developed by Michael Goldstein. Bayes Linear Statistics | Wikipedia
Bayesian Linear Regression
YouTube search... ...Google search
- Regression Analysis
- Bayesian Linear Regression | Microsoft
- 10 types of regressions. Which one to use? | Vincent Granville
- Bayesian Vector Autoregression | Wikipedia
- Bayesian Multivariate Linear Regression | Wikipedia
The aim of Bayesian Linear Regression is not to find the single “best” value of the model parameters, but rather to determine the posterior distribution for the model parameters. Not only is the response generated from a probability distribution, but the model parameters are assumed to come from a distribution as well. Introduction to Bayesian Linear Regression | Towards Data Science
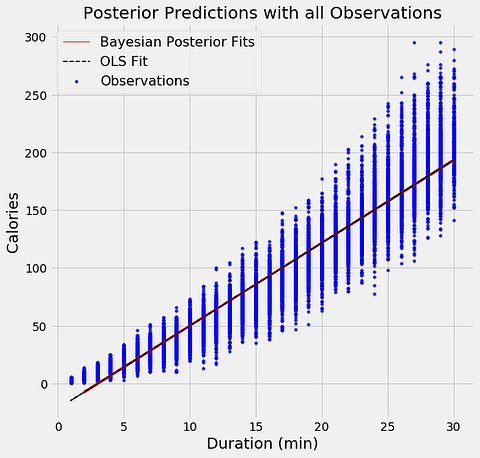
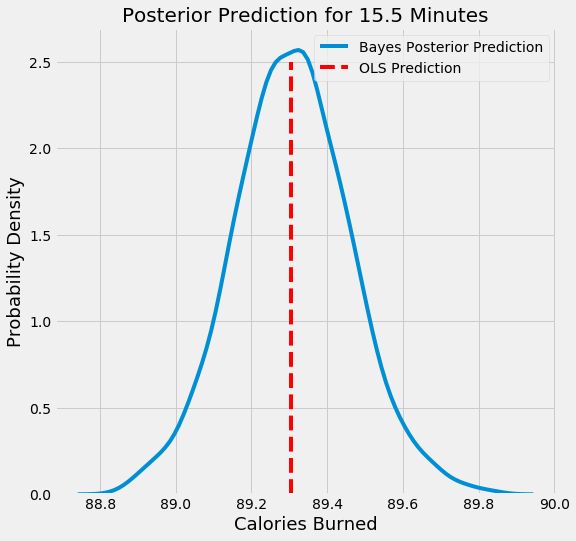
In the Bayesian viewpoint, we formulate linear regression using probability distributions rather than point estimates. The response, y, is not estimated as a single value, but is assumed to be drawn from a probability distribution. The output, y is generated from a normal (Gaussian) Distribution characterized by a mean and variance. The mean for linear regression is the transpose of the weight matrix multiplied by the predictor matrix. The variance is the square of the standard deviation σ (multiplied by the Identity matrix because this is a multi-dimensional formulation of the model).
Bayesian methods have a highly desirable quality: they avoid overfitting. They do this by making some assumptions beforehand about the likely distribution of the answer. Another byproduct of this approach is that they have very few parameters. Machine Learning has both Bayesian algorithms for both classification (Two-class Bayes' point machine) and regression (Bayesian linear regression). Note that these assume that the data can be split or fit with a straight line. - Dinesh Chandrasekar
Stan - modeling language and statistical algorithms
Youtube search... ...Google search
a state-of-the-art platform for statistical modeling and high-performance statistical computation. Thousands of users rely on Stan for statistical modeling, data analysis, and prediction in the social, biological, and physical sciences, engineering, and business. Users specify log density functions in Stan’s probabilistic programming language and get:
- full Bayesian statistical inference with MCMC sampling (NUTS, HMC)
- approximate Bayesian inference with variational inference (ADVI)
- penalized maximum likelihood estimation with optimization (L-BFGS)
Stan’s math library provides differentiable probability functions & linear algebra (C++ autodiff). Additional R packages provide expression-based linear modeling, posterior visualization, and leave-one-out cross-validation. Stan interfaces with the most popular data analysis languages (R, Python, shell, MATLAB, Julia, Stata) and runs on all major platforms (Linux, Mac, Windows).
Bayesian Deep Learning (BDL)
Youtube search... ...Google search
BDL provides a deep learning framework which can also model uncertainty. BDL can achieve state-of-the-art results, while also understanding uncertainty. Deep Learning Is Not Good Enough, We Need Bayesian Deep Learning for Safe AI | Alex Kendall
Bayes Estimator
Youtube search... ...Google search
- Laplace–Bayes estimator | Wikipedia
- Approximate Bayesian computation | Wikipedia
- Recursive Bayesian estimation | Wikipedia
In estimation theory and decision theory, a Bayes estimator or a Bayes action is an estimator or decision rule that minimizes the posterior expected value of a loss function (i.e., the posterior expected loss). Equivalently, it maximizes the posterior expectation of a utility function. An alternative way of formulating an estimator within Bayesian statistics is maximum a posteriori estimation. Bayes Estimator | Wikipedia
Bayesian Parameter Estimation
Youtube search... ...Google search
- Laplace–Bayes estimator | Wikipedia
- Approximate Bayesian computation | Wikipedia
- Recursive Bayesian estimation | Wikipedia
Bayesian Game
Youtube search... ...Google search
In game theory, a Bayesian game is a game in which players have incomplete information about the other players. For example, a player may not know the exact payoff functions of the other players, but instead have beliefs about these payoff functions. These beliefs are represented by a probability distribution over the possible payoff functions. John C. Harsanyi describes a Bayesian game in the following way. Each player in the game is associated with a set of types, with each type in the set corresponding to a possible payoff function for that player. In addition to the actual players in the game, there is a special player called Nature. Nature randomly chooses a type for each player according to a probability distribution across the players' type spaces. This probability distribution is known by all players (the "common prior assumption"). This modeling approach transforms games of incomplete information into games of imperfect information (in which the history of play within the game is not known to all players). Incompleteness of information means that at least one player is unsure of the type (and therefore the payoff function) of another player. Such games are called Bayesian because players are typically assumed to update their beliefs according to Bayes' rule. In particular, the belief a player holds about another player's type might change according to his own type.Bayesian Game | Wikipedia
Bayesian Search Theory
Youtube search... ...Google search
Bayesian Search Theory is the application of Bayesian statistics to the search for lost objects. It has been used several times to find lost sea vessels, for example the USS Scorpion, and has played a key role in the recovery of the flight recorders in the Air France Flight 447 disaster of 2009. It has also been used in the attempts to locate the remains of Malaysia Airlines Flight 370. ... first search where it most probably will be found, then search where finding it is less probable, then search where the probability is even less (but still possible due to limitations on fuel, range, water currents, etc.), until insufficient hope of locating the object at acceptable cost remains. | Wikipedia
Probability Density Function (PDF), or density of a continuous random variable in probability theory is a function whose value at any given sample (or point) in the sample space (the set of possible values taken by the random variable) can be interpreted as providing a relative likelihood that the value of the random variable would equal that sample. Probability density function

Bayesian Network
Youtube search... ...Google search
A Bayesian network (also known as a Bayes network, belief network, or decision network) is a probabilistic graphical model that represents a set of variables and their conditional dependencies via a directed acyclic graph (DAG). Bayesian networks are ideal for taking an event that occurred and predicting the likelihood that any one of several possible known causes was the contributing factor. For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases. Efficient algorithms can perform inference and learning in Bayesian networks. Bayesian networks that model sequences of variables (e.g. speech signals or protein sequences) are called dynamic Bayesian networks. Generalizations of Bayesian networks that can represent and solve decision problems under uncertainty are called influence diagrams. Bayesian Network | Wikipedia
Dynamic Bayesian Network (DBN)
Youtube search... ...Google search
A Dynamic Bayesian Network (DBN) is a Bayesian network (BN) which relates variables to each other over adjacent time steps. This is often called a Two-Timeslice BN (2TBN) because it says that at any point in time T, the value of a variable can be calculated from the internal regressors and the immediate prior value (time T-1). DBNs were developed by Paul Dagum in the early 1990s at Stanford University's Section on Medical Informatics. Dagum developed DBNs to unify and extend traditional linear state-space models such as Kalman filters, linear and normal forecasting models such as ARMA and simple dependency models such as hidden Markov models into a general probabilistic representation and inference mechanism for arbitrary nonlinear and non-normal time-dependent domains. Today, DBNs are common in robotics, and have shown potential for a wide range of data mining applications. For example, they have been used in [[Speech Recognition| speech recognition], digital forensics, protein sequencing, and bioinformatics. DBN is a generalization of hidden Markov models and Kalman filters. Dynamic Bayesian Network (DBN) | Wikipedia
Bayes Factor
Youtube search... ...Google search
In statistics, the use of Bayes factors is a Bayesian alternative to classical hypothesis testing. Bayesian model comparison is a method of model selection based on Bayes factors. The models under consideration are statistical models. The aim of the Bayes factor is to quantify the support for a model over another, regardless of whether these models are correct. The Bayes factor is a likelihood ratio of the marginal likelihood of two competing hypotheses, usually a null and an alternative. Bayes Factor | Wikipedia
Ensemble Learning
Bayes Optimal Classifier (BOC)
Youtube search... ...Google search
The Bayes optimal classifier is a classification technique. It is an ensemble of all the hypotheses in the hypothesis space. On average, no other ensemble can outperform it.[13] The naive Bayes optimal classifier is a version of this that assumes that the data is conditionally independent on the class and makes the computation more feasible. Each hypothesis is given a vote proportional to the likelihood that the training dataset would be sampled from a system if that hypothesis were true. To facilitate training data of finite size, the vote of each hypothesis is also multiplied by the prior probability of that hypothesis. Bayes Optimal Classifier (BOC) | Wikipedia
Bayesian Model Averaging (BMA)
Youtube search... ...Google search
Bayesian model averaging (BMA) makes predictions using an average over several models with weights given by the posterior probability of each model given the data.[15] BMA is known to generally give better answers than a single model, obtained, e.g., via stepwise regression, especially where very different models have nearly identical performance in the training set but may otherwise perform quite differently. The most obvious question with any technique that uses Bayes' theorem is the prior, i.e., a specification of the probability (subjective, perhaps) that each model is the best to use for a given purpose. Conceptually, BMA can be used with any prior. Bayesian Model Averaging (BMA) | Wikipedia
Bayesian Model Combination (BMC)
Youtube search... ...Google search
Bayesian model combination (BMC) is an algorithmic correction to Bayesian model averaging (BMA). Instead of sampling each model in the ensemble individually, it samples from the space of possible ensembles (with model weightings drawn randomly from a Dirichlet distribution having uniform parameters). This modification overcomes the tendency of BMA to converge toward giving all of the weight to a single model. Although BMC is somewhat more computationally expensive than BMA, it tends to yield dramatically better results. The results from BMC have been shown to be better on average (with statistical significance) than BMA, and bagging. The use of Bayes' law to compute model weights necessitates computing the probability of the data given each model. Typically, none of the models in the ensemble are exactly the distribution from which the training data were generated, so all of them correctly receive a value close to zero for this term. This would work well if the ensemble were big enough to sample the entire model-space, but such is rarely possible. Consequently, each pattern in the training data will cause the ensemble weight to shift toward the model in the ensemble that is closest to the distribution of the training data. It essentially reduces to an unnecessarily complex method for doing model selection. The possible weightings for an ensemble can be visualized as lying on a simplex. At each vertex of the simplex, all of the weight is given to a single model in the ensemble. BMA converges toward the vertex that is closest to the distribution of the training data. By contrast, BMC converges toward the point where this distribution projects onto the simplex. In other words, instead of selecting the one model that is closest to the generating distribution, it seeks the combination of models that is closest to the generating distribution. The results from BMA can often be approximated by using cross-validation to select the best model from a bucket of models. Likewise, the results from BMC may be approximated by using cross-validation to select the best ensemble combination from a random sampling of possible weightings. Bayesian Model Combination (BMC) | Wikipedia
Quantum Bayesianism
Youtube search... ...Google search
In physics and the philosophy of physics, quantum Bayesianism (abbreviated QBism, pronounced "cubism") is an interpretation of quantum mechanics that takes an agent's actions and experiences as the central concerns of the theory. QBism deals with common questions in the interpretation of quantum theory about the nature of wavefunction superposition, quantum measurement, and entanglement. According to QBism, many, but not all, aspects of the quantum formalism are subjective in nature. For example, in this interpretation, a quantum state is not an element of reality—instead it represents the degrees of belief an agent has about the possible outcomes of measurements. Other uses of Bayesian probability in quantum physics QBism should be distinguished from other applications of Bayesian inference in quantum physics, and from quantum analogues of Bayesian inference. For example, some in the field of computer science have introduced a kind of quantum Bayesian network, which they argue could have applications in "medical diagnosis, monitoring of processes, and genetics". Bayesian inference has also been applied in quantum theory for updating probability densities over quantum states, and MaxEnt methods have been used in similar ways. Bayesian methods for quantum state and process tomography are an active area of research. Quantum Bayesianism | Wikipedia