Quantization
YouTube search... ...Google search
- How to Quantize Neural Networks with TensorFlow | Pete Warden
- 8-Bit Quantization and TensorFlow Lite: Speeding up mobile inference with low precision | Manas Sahni
- TensorFlow Lite
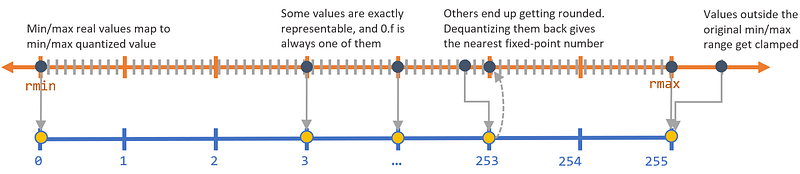
the process of constraining an input from a continuous or otherwise large set of values (such as the real numbers) to a discrete set (such as the integers). An umbrella term that covers a lot of different techniques to store numbers and perform calculations on them in more compact formats than 32-bit floating point.
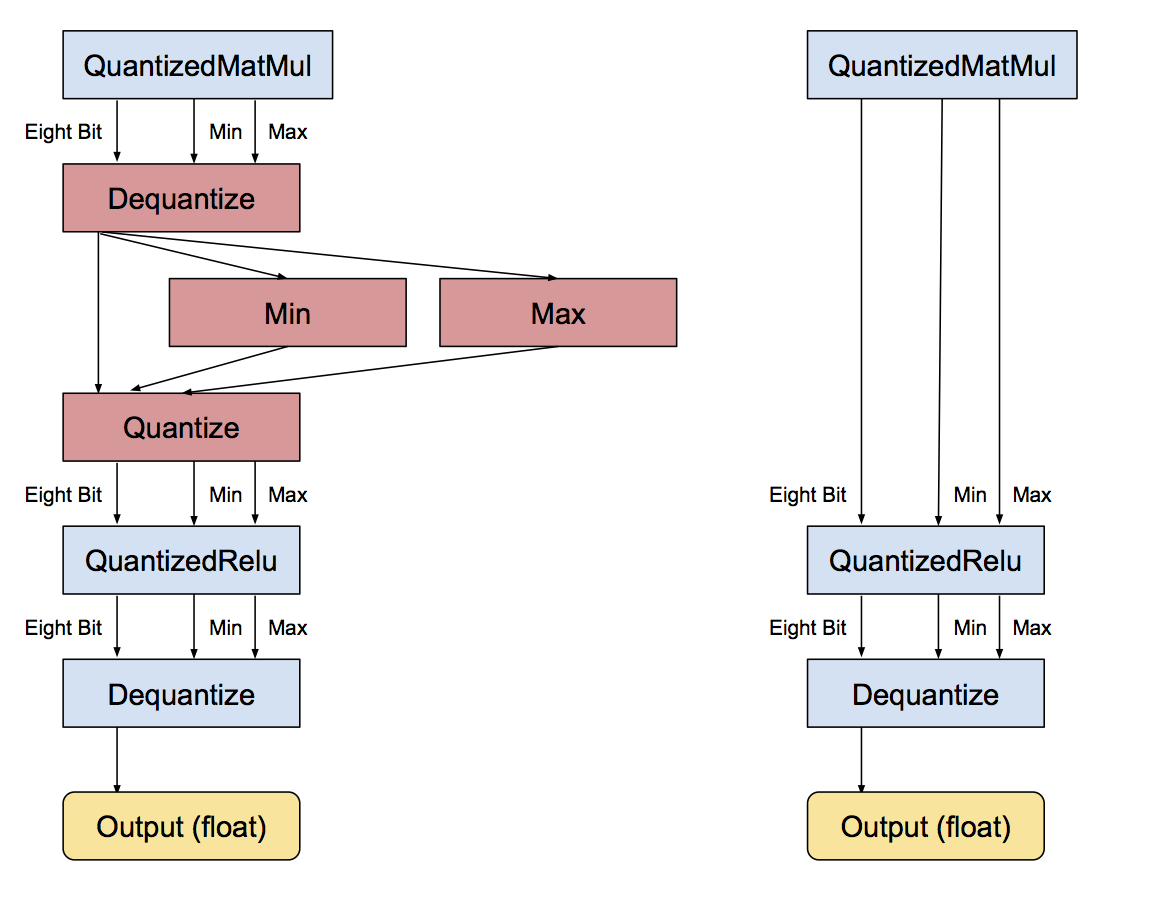
Quantization-aware model training
ensures that the forward pass matches precision for both training and inference. There are two aspects to this:
- Operator fusion at inference time are accurately modeled at training time.
- Quantization effects at inference are modeled at training time.
For efficient inference, TensorFlow combines batch normalization with the preceding convolutional and fully-connected layers prior to quantization by folding batch norm layers.
Post-training quantization
is a general technique to reduce the model size while also providing up to 3x lower latency with little degradation in model accuracy. Post-training quantization quantizes weights to 8-bits of precision from floating-point.